Scikit-apprendre: comment obtenir le vrai positif, le vrai négatif, le faux positif et le faux négatif
je suis nouveau en apprentissage machine et en scikit-learn.
Mon problème:
(Merci de corriger tout type de missconception)
j'ai un ensemble de données qui est un grand JSON, je le récupère et le stocke dans un trainList variable.
je le pré-traite afin de pouvoir travailler avec lui.
une fois que j'ai fait cela, je commence la classification:
- j'utilise la méthode de validation kfold cross afin d'obtenir la signifier précision et je forme un classificateur.
- je fais les prédictions et j'obtiens la matrice d'exactitude et de confusion de ce pli.
- après cela, je voudrais obtenir les valeurs vrai positif(TP), vrai négatif(TN), faux positif(FP) et faux négatif(FN). Je voudrais utiliser ces paramètres pour obtenir la sensibilité et la spécificité et je voudrais eux et le total du TPs à un HTML afin de montrer un graphique avec le TPs de chaque étiquette.
Code:
Les variables que j'ai pour le moment:
trainList #It is a list with all the data of my dataset in JSON form
labelList #It is a list with all the labels of my data
la majeure partie de la méthode:
#I transform the data from JSON form to a numerical one
X=vec.fit_transform(trainList)
#I scale the matrix (don't know why but without it, it makes an error)
X=preprocessing.scale(X.toarray())
#I generate a KFold in order to make cross validation
kf = KFold(len(X), n_folds=10, indices=True, shuffle=True, random_state=1)
#I start the cross validation
for train_indices, test_indices in kf:
X_train=[X[ii] for ii in train_indices]
X_test=[X[ii] for ii in test_indices]
y_train=[listaLabels[ii] for ii in train_indices]
y_test=[listaLabels[ii] for ii in test_indices]
#I train the classifier
trained=qda.fit(X_train,y_train)
#I make the predictions
predicted=qda.predict(X_test)
#I obtain the accuracy of this fold
ac=accuracy_score(predicted,y_test)
#I obtain the confusion matrix
cm=confusion_matrix(y_test, predicted)
#I should calculate the TP,TN, FP and FN
#I don't know how to continue
10 réponses
si vous avez deux listes qui ont les valeurs prédites et réelles; comme il apparaît que vous le faites, vous pouvez les passer à une fonction qui calculera TP, FP, TN, FN avec quelque chose comme ceci:
def perf_measure(y_actual, y_hat):
TP = 0
FP = 0
TN = 0
FN = 0
for i in range(len(y_hat)):
if y_actual[i]==y_hat[i]==1:
TP += 1
if y_hat[i]==1 and y_actual[i]!=y_hat[i]:
FP += 1
if y_actual[i]==y_hat[i]==0:
TN += 1
if y_hat[i]==0 and y_actual[i]!=y_hat[i]:
FN += 1
return(TP, FP, TN, FN)
D'ici je pense que vous serez en mesure de calculer les taux d'intérêt pour vous, et d'autres mesures de performance comme la spécificité et la sensibilité.
pour le cas multi-classes, tout ce dont vous avez besoin peut être trouvé dans la matrice de confusion. Par exemple, si votre matrice de confusion ressemble à ceci:
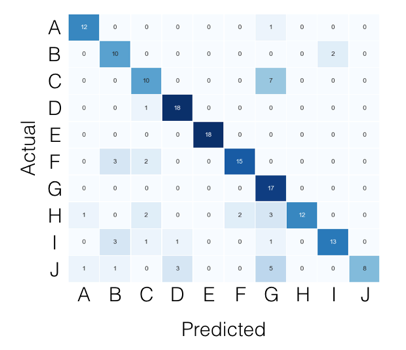
Ensuite, ce que vous cherchez, par classe, peut être trouvé comme ceci:
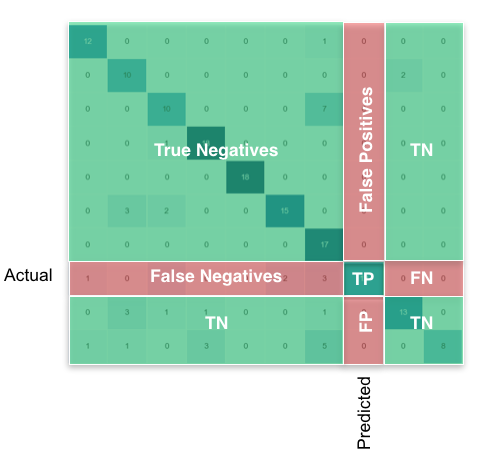
en utilisant pandas/ numpy, vous pouvez faire ceci pour toutes les classes à la fois comme ceci:
FP = confusion_matrix.sum(axis=0) - np.diag(confusion_matrix)
FN = confusion_matrix.sum(axis=1) - np.diag(confusion_matrix)
TP = np.diag(confusion_matrix)
TN = confusion_matrix.values.sum() - (FP + FN + TP)
# Sensitivity, hit rate, recall, or true positive rate
TPR = TP/(TP+FN)
# Specificity or true negative rate
TNR = TN/(TN+FP)
# Precision or positive predictive value
PPV = TP/(TP+FP)
# Negative predictive value
NPV = TN/(TN+FN)
# Fall out or false positive rate
FPR = FP/(FP+TN)
# False negative rate
FNR = FN/(TP+FN)
# False discovery rate
FDR = FP/(TP+FP)
# Overall accuracy
ACC = (TP+TN)/(TP+FP+FN+TN)
Vous pouvez obtenir tous les paramètres de la matrice de confusion. La structure de la matrice de confusion (qui est 2x2 matrice) est comme suit
TP|FP
FN|TN
TP = cm[0][0]
FP = cm[0][1]
FN = cm[1][0]
TN = cm[1][1]
plus de détails à https://en.wikipedia.org/wiki/Confusion_matrix
selon la documentation de scikit-learn,
par définition une matrice de confusion C est telle que C[i, j] est égal au nombre d'observations connues pour être dans le Groupe i mais prédites pour être dans le groupe J.
ainsi dans la classification binaire, le compte des vrais négatifs est C[0,0], les faux négatifs est C[1,0], les vrais positifs est C[1,1] et les faux positifs est C[0,1].
CM = confusion_matrix(y_true, y_pred)
TN = CM[0][0]
FN = CM[1][0]
TP = CM[1][1]
FP = CM[0][1]
dans la bibliothèque scikit-learn 'metrics' il y a une méthode confusion_matrix qui vous donne la sortie désirée.
Vous pouvez utiliser un classificateur que vous voulez. Ici, j'ai utilisé les genouillères comme exemple.
from sklearn import metrics, neighbors
clf = neighbors.KNeighborsClassifier()
X_test = ...
y_test = ...
expected = y_test
predicted = clf.predict(X_test)
conf_matrix = metrics.confusion_matrix(expected, predicted)
>>> print conf_matrix
>>> [[1403 87]
[ 56 3159]]
vous pouvez essayer sklearn.metrics.classification_report comme ci-dessous:
import sklearn
y_true = [1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0]
y_pred = [1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0]
print sklearn.metrics.classification_report(y_true, y_pred)
sortie:
precision recall f1-score support
0 0.80 0.57 0.67 7
1 0.50 0.75 0.60 4
avg / total 0.69 0.64 0.64 11
je pense que les deux réponses ne sont pas entièrement correct. Par exemple, supposons que nous avons les tableaux suivants;
y_actual = [1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0]
y_predic = [1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0]
si nous calculons les valeurs FP, FN, TP et TN manuellement, elles devraient être comme suit:
FP: 3 FN: 1 TP: 3 TN: 4
par contre, si nous utilisons la première réponse, les résultats sont donnés comme suit:
FP: 1 FN: 3 TP: Trois TN: 4
ils ne sont pas corrects, parce que dans la première réponse, faux positif devrait être où réel est 0, mais le prédit est 1, pas le contraire. C'est aussi le même pour de Faux Négatifs.
Et, si nous utilisons la deuxième réponse, les résultats sont calculés comme suit:
FP: 3 FN: 1 TP: 4 TN: 3
les nombres vrai positif et vrai négatif ne sont pas corrects, ils devraient être opposés.
Suis-je correct avec mes calculs? S'il vous plaît laissez-moi savoir si je suis absent quelque chose.
si vous avez plus d'une classe dans votre Classificateur, vous pouvez utiliser pandas-ml à cette partie. La matrice de Confusion de pandas-ml donne des informations plus détaillées. vérifiez que
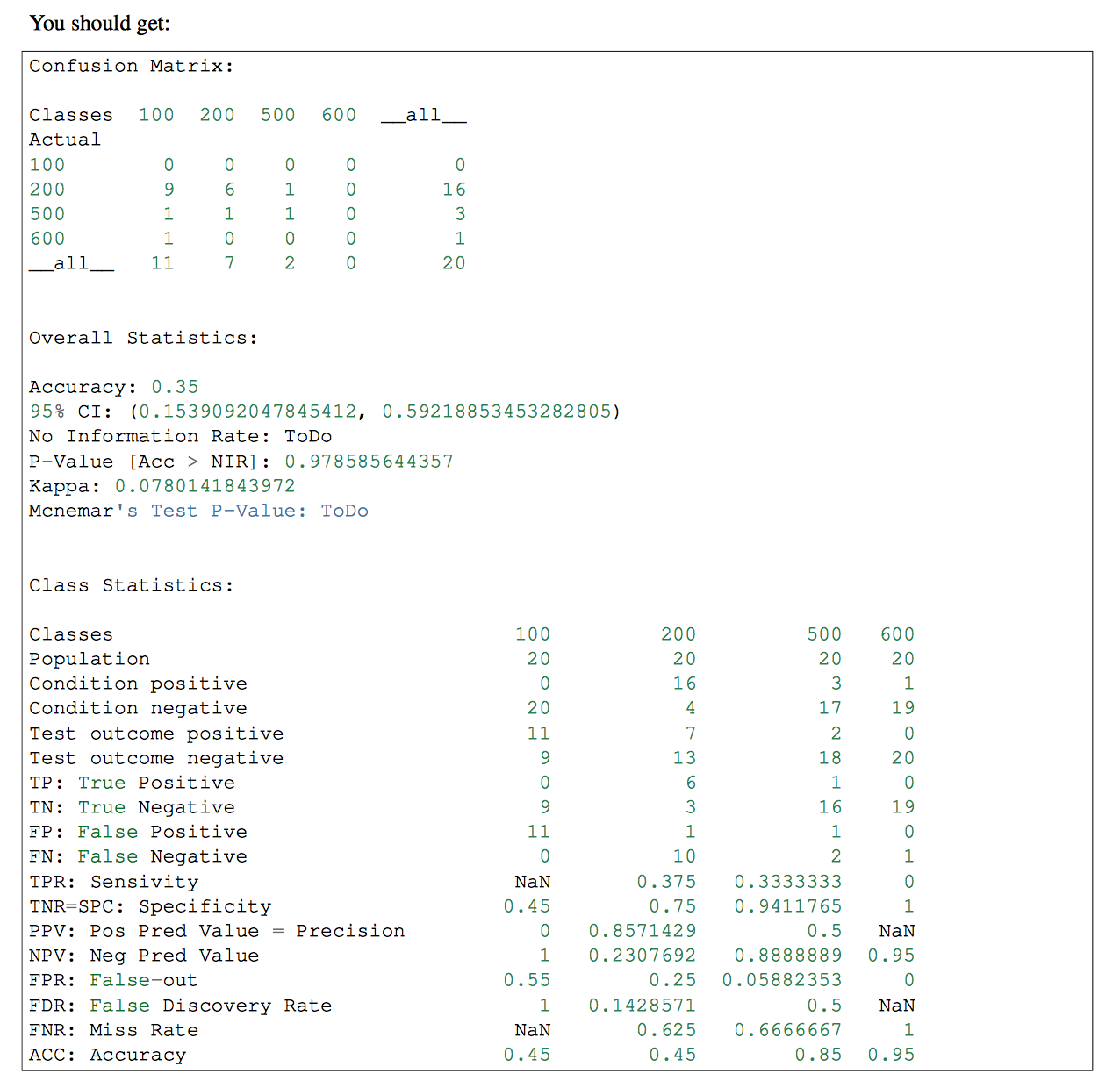
j'ai écrit une version qui fonctionne en utilisant seulement num PY. J'espère que cela vous aide.
import numpy as np
def perf_metrics_2X2(yobs, yhat):
"""
Returns the specificity, sensitivity, positive predictive value, and
negative predictive value
of a 2X2 table.
where:
0 = negative case
1 = positive case
Parameters
----------
yobs : array of positive and negative ``observed`` cases
yhat : array of positive and negative ``predicted`` cases
Returns
-------
sensitivity = TP / (TP+FN)
specificity = TN / (TN+FP)
pos_pred_val = TP/ (TP+FP)
neg_pred_val = TN/ (TN+FN)
Author: Julio Cardenas-Rodriguez
"""
TP = np.sum( yobs[yobs==1] == yhat[yobs==1] )
TN = np.sum( yobs[yobs==0] == yhat[yobs==0] )
FP = np.sum( yobs[yobs==1] == yhat[yobs==0] )
FN = np.sum( yobs[yobs==0] == yhat[yobs==1] )
sensitivity = TP / (TP+FN)
specificity = TN / (TN+FP)
pos_pred_val = TP/ (TP+FP)
neg_pred_val = TN/ (TN+FN)
return sensitivity, specificity, pos_pred_val, neg_pred_val
Voici une correction au Code buggy invoketheshell (qui apparaît actuellement comme la réponse acceptée):
def performance_measure(y_actual, y_hat):
TP = 0
FP = 0
TN = 0
FN = 0
for i in range(len(y_hat)):
if y_actual[i] == y_hat[i]==1:
TP += 1
if y_hat[i] == 1 and y_actual[i] == 0:
FP += 1
if y_hat[i] == y_actual[i] == 0:
TN +=1
if y_hat[i] == 0 and y_actual[i] == 1:
FN +=1
return(TP, FP, TN, FN)