Unicode / UTF-8 fichier texte: gibberish sur Windows console (essayer d'afficher l'Hébreu)
j'ai un fichier de caractères larges (avec du texte hébreu) qui a l'air bien dans le bloc-notes (enregistré dans" encodage UTF-8"), lit bien dans le bloc-notes++, et quand je copie-et-coller dans MS Word il a l'air bien aussi. Mais quand j'ouvre un " DOS box "(Windows console) et que je lance: "type file.txt", ça imprime du charabia.
et oui, j'ai fait toutes les recommandations pour Unicode sur Windows console: j'ai ouvert la console en utilisant "cmd /u", j'ai changé la police à Lucida, et j'ai entré: "chcp 65001".
Le problème est identique sur un PC tournant sous Windows 7, et sur un autre PC tournant sous Windows XP SP3.
5 réponses
la police Courier New supporte l'hébreu et peut être ajoutée à l'invite de commande. Les polices par défaut sont consolas, lucida, raster, aucune ne supporte l'Hébreu. Ainsi, ajoutez Courier New à l'invite de commande.
C'est un registre hack pour le faire
http://www.techrepublic.com/blog/windows-and-office/quick-tip-add-fonts-to-the-command-prompt /
ceci est un bon exemple de la façon d'installer des polices, mais je devrais supprimer beaucoup de ces entrées, parce que la plupart d'entre elles n'ont pas été ajoutées à cmd parce que cmd ne les supporte pas.
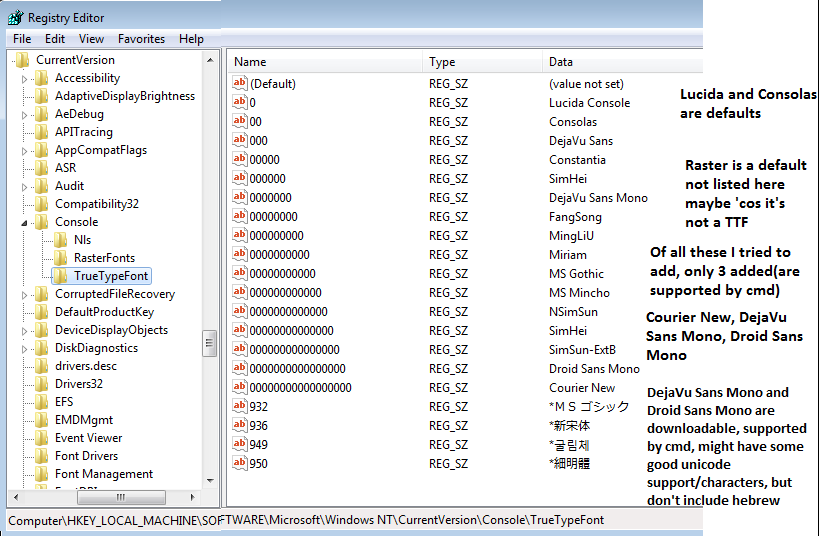
Lucida et Consolas sont par défaut.
Raster est un défaut qui n'est pas listée ici peut-être parce que c'est un TTF
De toutes ces choses, je essayé d'ajouter, seulement 3 Ajouté (sont pris en charge par cmd)
Courrier New, DejaVu Sans Mono, Droid Sans Mono
DejaVu Sans Mono et Droid Sans Mono sont téléchargeables, pris en charge par cmd, pourrait avoir de la bonne prise en charge d'unicode/caractères, mais ne comprennent pas l'hébreu
j'ai
Consolas <-- default
Courier New <--- added
DejaVu Sans Mono <-- added
Droid Sans Mono <-- added
Lucida Console <-- default
Raster Fonts <-- default
les polices hébraïques courantes sont Miriam et David, mais ils ne peuvent pas être ajoutés à l'invite de commande.
pour le record, Babelmap peut lister toutes les polices de votre système qui prennent en charge l'hébreu, par exemple dans babelmap - cliquez sur les polices..police coverage, puis entrer 05D0 (c'est aleph). Je pense que toutes ces polices existent sur une installation windows 7 par défaut
Aharoni, Arial, Courier New, David, FrankRuehl, Gisha, Levenim MT, Lucida Sans Unicode, Microsoft Sans Serif, Miriam, Miriam Fixed, Narkisim, Rod, Segoe WP, Tahoma, Times New Roman
mais la plupart ou toutes ces polices en hébreu ne sont pas supportées dans l'invite de commande, sauf Courier New. En fait, la plupart des polices full stop ne sont pas supportées dans la commande invite, pas même " times New roman "(parce que" times new roman " n'est pas mono-espacé / Largeur fixe, et c'est l'un des nombreux critères pour qu'il soit supporté, d'autres critères semblent plus obscurs).
ainsi Maintenant vous pouvez avoir Courier New ajouté et sélectionné pour l'utilisation dans l'invite de commande.
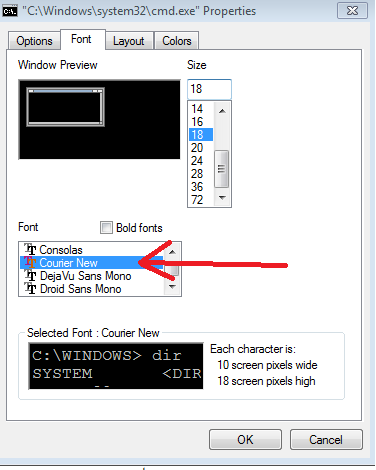
et ainsi vous pouvez coller des caractères unicode sur cmd pourvu que le police sélectionnée prend en charge.
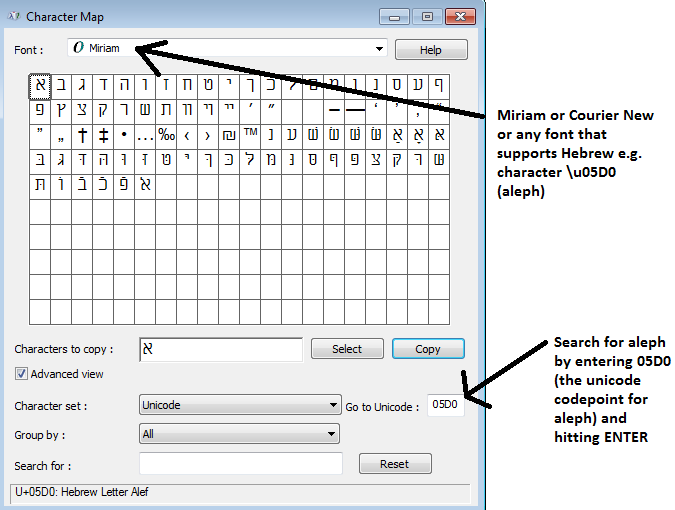
pour copier / coller, cliquez sur le bouton Copier dans charmap
maintenant c'est dans le bloc-notes
pour le coller dans l'invite de commande, dans win7 coller dans l'invite de commande n'est pas Ctrl-v. vous faites un clic droit et choisissez Coller. (ou si dans sur mode d'édition rapide puis il suffit de faire un clic droit)
c'est l'essentiel.
en plus
souvent dans windows on peut utiliser le bloc-notes et la carte de caractères.. mais il faut être conscient de certaines limites.
La table de caractèresaffiche les 65536 premiers caractères unicode lorsque la police que vous avez sélectionnée la Supporte, et la table de caractères vous montre le code UTF-16. C'est bon, vous pouvez toujours coller de carte de caractères dans un cmd.fenêtre exe, mais vous devez savoir que les commandes s'exécutent dans cmd.exe et pipes ne supportent pas l'utf-16. Donc vous pouvez utiliser la carte de caractères, trouver un caractère par exemple aleph 05d0, mais il vaut la peine de chercher le caractère sur http://www.fileformat.info/info/unicode/char/05d0/index.htm et vu que le code utf-16 est 05d0, le code utf-8 est d790. La commande xxd et la commande file sont utiles pour voir le contenu réel d'un fichier et déterminer le type.
Notepad est un bit limité quand il s'agit d'unicode ou de n'importe quel caractère dans le jeu de caractères unicode dont le code UTF16 est > FF. Et cmd est un peu limité en ce qui concerne certaines commandes comme 'type', et en ce qui concerne les pipes et la redirection.
si on utilise cmd.exe tu as vraiment besoin de pipes pour travailler parce que les pipes sont importantes..
Les Pipessont limitées aux encodages qui peuvent être spécifiés par la commande CHCP.
(Notez que si CHCP vous dit que vous êtes sur une page de code particulière, par exemple 850, il vous dit le codage d'entrée. Si vous lancez la commande chcp 850, cela changera à la fois les encodages d'entrée et de sortie. Habituellement, ils sont les mêmes. C'est plus simple quand ils sont pareils. Mais si vous avez utilisé un autre programme pour changer l'encodage de cmd par exemple le compilateur c# a un commutateur qui le change, alors il est préférable de le changer avec chcp pour que vous sachiez que les deux encodages sont définis ).
il y a un CHCP 1200 (UTF-16LE) et 1201(UTF-16BE), mais ni l'un ni l'autre ne sont supportés, si vous l'essayez, il sera dit codepage invalide (testé dans win7). CHCP ne supporte pas UTF-16(Il ne supporte pas UTF16LE ou UTF16BE). Il y a CHCP 65001 (C'est UTF-8 sans BOM). Et il y a CHCP 862 (la manière à l'ancienne comme dans MSDOS days way, d'encoder l'hébreu, que j'ai mentionnée)
la commande type supporte UTF16LE comme notepad(ce que notepad appelle Unicode, est UTF-16 LE), mais les pipes et la redirection ne le font pas. l'appui que. La commande type supporte également tout codepage spécifié / supporté par CHCP. So type supporte 862 ou 65001.
pour que vous puissiez utiliser le bloc-notes enregistrer comme UTF8 (qui est avec BOM), puis bricoler autour pour enlever le BOM. (C'est un peu exagéré).. Ou vous pouvez utiliser le bloc-notes, enregistrez - le comme Unicode UTF 16LE.. Mais tu ne peux pas poursuivre pipes.. (c'est mauvais).. La chose la plus facile à faire est d'utiliser un éditeur de texte comme notepad2 ou notepad++, qui supporte UTF8 sans BOM.
ou si vous faites tout depuis cmd vous pouvez utiliser 862 ou 65001. Bien que de nombreux éditeurs de texte pourraient ne pas donner un bon soutien de 862. Vous préférez peut-être 65001.
si vous voulez écrire n'importe quel fichier dans notepad et qu'il a un caractère plus grand que ce que dans UTF16 est appelé \uFF, et que vous voulez exécuter des commandes dans cmd.exe sur ce fichier, alors certaines commandes (par exemple la commande type), auront des problèmes si vous ne tenez pas compte de ce qui est supporté par quoi.
Notepad prend en charge UTF-16BE, UTF-16LE et UTF-8 avec BOM. Ce n'est pas bon. Et pas besoin de tripoter avec xxd et sed ou d'autres commandes pour supprimer le BOM. Si vous avez n'importe quel fichier avec un caractère dit unicode, un caractère en dehors de la gamme régulière ascii. Un caractère > UTF-16's \uFF, comme indiqué par la carte de caractères comme étant > \uFF, puis utiliser Notepad2 ou notepad++
Le typesupporte UTF16LE, et tout codepage réglé par CHCP p.ex. 65001 ou 862.
Pipes et redirection vont par tout ce qui est défini par CHCP.
Codepage 862 est vieux donc Codepage 65001 est une bonne façon d'aller.
xxd et fichier sont utiles pour voir comment un fichier est encodé ce qui peut être utile si vous avez des problèmes. Mais pas absolument nécessaire.
donc si vous voulez écrire un fichier à utiliser dans CMD, et il a quelques caractères unicode, alors que vous êtes quelques commandes comme xxd et sed qui pourraient être utilisés pour supprimer un BOM, et d'autres commandes pour le faire. La façon la plus simple de créer un tel fichier dans un éditeur de texte est d'utiliser un éditeur de texte comme notepad2 ou notepad++ qui supporte UTF8 sans BOM.
obtenir l'affichage Hébreu pourrait être la chose la plus importante à faire d'abord, comme décrit ci-dessus. Et la chose suivante est d'être en mesure de sauvegarder des fichiers dans un éditeur de texte que vous pouvez afficher avec par exemple 'type'.
et si vous voulez copier depuis l'invite de commande, si ce n'est en mode quickedit, puis cliquez avec le bouton droit de la souris, choisissez mark, puis sélectionnez-le, puis appuyez sur Entrée. Et pour coller le clic droit et choisir coller.
un autre point supplémentaire est
apparemment, il y a des bogues dans chcp 65001 où certains fichiers par lots ne fonctionneront pas et peut-être que certains programmes C ne fonctionneront pas non plus. comment utiliser les caractères unicode dans la ligne de commande Windows? et j'ai même vu le crash du compilateur C sharp quand cmd est en codepage 65001 (bien que l'on puisse blâmer le c sharp compilateur, on peut aussi blâmer 65001) Pourquoi le scc.exe s'écrase quand j'ai quitté la sortie encodant comme UTF8?
Note - une révision antérieure de cette réponse comportait des exemples en ligne de commande, mais ils étaient inutilement complexes. Je pourrais à un certain point ajouter quelques commandes qui montrent ce que j'ai décrit mais c'est assez trivial.
/u est pour l'UTF-16LE, pas en UTF-8. C'est pourquoi sauvegarder le fichier en tant qu'UTF-16LE (ce que Windows/Noetpad appelle "Unicode" de manière erronée) et exécuter avec /u fonctionne, autant qu'il le fait.
UTF-8 devrait être réalisable avec chcp 65001 , mais il y a une méchante faible niveau de bugs dans le Microsoft C Runtime pour cette page de code, ce qui rend certaines applications peu fiables, et d'autres pas du tout.
donc oui, je suis désolé, mais UTF-8 est un citoyen de seconde classe sous Windows. Tout ce qui utilise les interfaces 'ANSI' pour IO, y compris tout ce qui utilise la bibliothèque C standard IO, y compris L'invite de commande, ne pourra pas s'en charger correctement.
le seul moyen fiable d'obtenir la sortie Unicode dans L'invite de commande est d'utiliser L'interface WriteConsoleW spécifique à Windows pour pousser les chaînes Unicode directement. Malheureusement, comme ce n'est pas disponible sur toutes les plateformes, de nombreux outils ne l'utiliseront pas.
dans tous les cas, même si vous avez le bon encodage, vous devez toujours avoir une police dans l'invite de commande qui contient les caractères que vous voulez. Je crois que c'est la raison pour laquelle vous n'êtes toujours pas obtenir l'hébreu dans le /u +UTF-16LE route.
Résumé: l'Invite de Commande + non-ASCII == presque certain d'échouer. Abandonnez et trouvez une autre interface que vous pouvez utiliser qui supporte mieux Unicode.
vous devez convertir file.txt en UTF-16 (Little Endian) avant type file.txt
je suppose que vous voulez dire" Lucida Console "quand vous dites"Lucida".
à l'aide de l'application charmap , je n'ai pas trouvé de caractères hébreux dans la police. Je ne sais pas si la police était plus capable dans les versions précédentes de Windows, mais dans Windows 7 Il semble n'y avoir rien en dehors des caractères européens.
mon système a aussi Lucida Sans Machine à écrire qui inclut les caractères hébreux. Malheureusement la fenêtre Cmd ne le montre pas comme un choix. Vous devez modifier le Registre pour ouvrir plus de choix, comme indiqué dans cette question sur SuperUser: https://superuser.com/questions/5035/how-to-change-the-windows-console-font
P. S. j'ai été incapable de vérifier cette solution parce que Windows est difficile. Voir https://superuser.com/questions/390933/how-to-add-a-font-to-the-cmd-window-choices-in-windows-7-64-bit
comment obtenir une installation XP activée en hébreu?
tout d'Abord, il s'agit d'un XP home SP3, l'hébreu est activé. Je veux dire par là qu'il s'agit d'une installation XP US standard, ou du moins je crois, avec l'ajout de capacités en hébreu pour le clavier et l'affichage. Je crois que chaque CD XP peut installer un tel système. En particulier, je crois que ce qui suit est tout ce qui est nécessaire pour un tel système:
- Panneau de contrôle - > Date, Heure, langue et Options régionales -> options linguistiques et Options régionales - > dans l'onglet Langue: 1) Cliquez sur Détails et ajoutez un clavier hébreu. 2) marquer avec un V les fichiers D'installation pour le script complexe et les langues de droite à gauche (y compris le Thaï) option.
- panneau de contrôle - > Date, Heure, langue et Options régionales -> langue et Options régionales - > dans l'onglet Avancé: Accepter, marquer avec un V, 10004 (MAC - arabe) et 10005 (Mac - hébreu). Je ne suis pas sûr que l'arabe soit un must.
maintenant à la console cmd
il faut ajouter explicitement les nouvelles polices de messagerie au Registre des polices de la console, comme décrit plus haut. Sinon, les polices de caractères hébreux explicites ne seront pas affichées.
maintenant que la console cmd est ouverte, tout ce qu'il y a à faire pour entrer des caractères hébreux est d'activer les nouvelles polices de caractères Courier, et de changer le clavier en mode Hébreu. Avoir Windows scroll les langues qu'il a pour le clavier est facile. Soit répétitif appuyer sur Alt gauche combiné avec les touches majuscules, ou avec la souris.
de côté, une commande dir affichera les noms de fichiers qui ont des caractères hébreux. Cependant, on ne peut pas seulement émettre un
dir file_name
et voir la sortie habituelle si le fichier commence par une lettre hébraïque. Il doit être
dir *file_name
je suppose que le caractère astérisque ajoute le caractère unicode BOM.
on peut aussi ouvrir le bloc-notes, entrer Les caractères hébreux, sauvegardez le fichier comme UTF8, et exécutez les commandes suivantes dans la console:
chcp 65001
type that_Notepad_file_I_saved
sauvegarder le fichier comme UTF8 se fait sur L'écran de sauvegarde de bloc-notes.