Qu'est-ce que le codage/page de code est cmd.exe à l'aide?
quand j'ouvre cmd.exe dans Windows, quel encodage utilise-t-il?
Comment puis-je vérifier quel encodage il utilise actuellement? Cela dépend-il de ma région ou il y a des variables d'environnement pour vérifier?
que se passe-t-il lorsque vous tapez un fichier avec un certain encodage? Parfois j'ai des caractères confus (codage incorrect utilisé) et parfois ça fonctionne. Cependant, je ne fais confiance à rien tant que je ne sais pas ce qui se passe. Peut quelqu'un m'expliquer?
5 réponses
Oui, c'est frustrant parfois type et d'autres programmes
imprimer charabia, et parfois ils ne le font pas.
tout d'abord, les caractères Unicode n'afficheront que si le la police de la console actuelle contient les caractères . Donc de l'utiliser une police TrueType comme Lucida Console au lieu de la police Raster par défaut.
mais si la police de la console ne contient pas le caractère que vous essayez d'afficher, vous verrez des points d'interrogation au lieu de charabia. Quand tu fais du charabia, il n'y a plus de choses que juste les paramètres de la police.
quand les programmes utilisent C-library standard I / O fonctions comme printf , le
le codage de sortie du programme doit correspondre au codage de sortie de la console , ou
vous obtiendrez charabia. chcp affiche et définit le codepage actuel. Tout
la sortie utilisant les fonctions d'E/S standard de la bibliothèque C est traitée comme si elle se trouvait dans
codepage affiché par chcp .
correspondant au codage de sortie du programme avec le codage de sortie de la console peut être accompli de deux façons différentes:
-
un programme peut obtenir le codepage actuel de la console en utilisant
chcpouGetConsoleOutputCP, et se configurer pour sortir dans cet encodage, ou -
vous ou un programme pouvez définir la page de code actuelle de la console en utilisant
chcpouSetConsoleOutputCPpour correspondre au codage de sortie par défaut du programme.
cependant, les programmes qui utilisent Win32 APIs peuvent écrire directement des chaînes UTF-16LE
à la console avec
WriteConsoleW .
C'est la seule façon d'obtenir une sortie correcte sans définir les codepages. Et
même en utilisant cette fonction, si une chaîne n'est pas dans L'encodage UTF-16LE
pour commencer, un programme Win32 doit passer la page de code correcte pour
MultiByteToWideChar .
Aussi, WriteConsoleW ne fonctionnera pas si la sortie du programme est redirigée;
de plus, la tripotent est nécessaire dans ce cas.
type fonctionne parfois parce qu'il vérifie le début de chaque fichier pour
UTF-16LE Marque d'Ordre d'Octet
(BOM) , i.e. les octets 0xFF 0xFE .
Si elle trouve un tel
mark, Il affiche les caractères Unicode dans le fichier en utilisant WriteConsoleW
quel que soit le page de codes actuelle. Mais quand type
UTF-16LE BOM, ou pour utiliser des caractères non ASCII avec n'importe quelle commande
cela ne s'appelle pas WriteConsoleW - vous aurez besoin de mettre le
le codepage de la console et l'encodage de la sortie du programme pour correspondre l'un à l'autre.
comment le savoir?
voici un fichier test contenant des caractères Unicode:
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
voici un programme Java pour imprimer le fichier de test dans un tas de différentes
Les codages Unicode. Il pourrait être dans n'importe quel langage de programmation; il imprime uniquement
Caractères ASCII ou octets codés en stdout .
import java.io.*;
public class Foo {
private static final String BOM = "\ufeff";
private static final String TEST_STRING
= "ASCII abcde xyz\n"
+ "German äöü ÄÖÜ ß\n"
+ "Polish ąęźżńł\n"
+ "Russian абвгдеж эюя\n"
+ "CJK 你好\n";
public static void main(String[] args)
throws Exception
{
String[] encodings = new String[] {
"UTF-8", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE" };
for (String encoding: encodings) {
System.out.println("== " + encoding);
for (boolean writeBom: new Boolean[] {false, true}) {
System.out.println(writeBom ? "= bom" : "= no bom");
String output = (writeBom ? BOM : "") + TEST_STRING;
byte[] bytes = output.getBytes(encoding);
System.out.write(bytes);
FileOutputStream out = new FileOutputStream("uc-test-"
+ encoding + (writeBom ? "-bom.txt" : "-nobom.txt"));
out.write(bytes);
out.close();
}
}
}
}
la sortie dans La page de codes par défaut? total ordures!
Z:\andrew\projects\sx59084>chcp
Active code page: 850
Z:\andrew\projects\sx59084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
= bom
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
== UTF-16LE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
= bom
■A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
== UTF-16BE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
== UTF-32LE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
== UTF-32BE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
cependant, que faire si nous type les fichiers qui ont été sauvegardés? Ils contiennent exactement
les mêmes octets qui ont été imprimés sur la console.
Z:\andrew\projects\sx59084>type *.txt
uc-test-UTF-16BE-bom.txt
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
uc-test-UTF-16BE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
uc-test-UTF-16LE-bom.txt
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
uc-test-UTF-16LE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
uc-test-UTF-32BE-bom.txt
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
uc-test-UTF-32BE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
uc-test-UTF-32LE-bom.txt
A S C I I a b c d e x y z
G e r m a n ä ö ü Ä Ö Ü ß
P o l i s h ą ę ź ż ń ł
R u s s i a n а б в г д е ж э ю я
C J K 你 好
uc-test-UTF-32LE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
uc-test-UTF-8-bom.txt
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
uc-test-UTF-8-nobom.txt
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
Le seulement chose qui fonctionne est de l'UTF-16LE fichier, avec une NOMENCLATURE, imprimé à l'
console via type .
si nous utilisons autre chose que type pour imprimer le fichier, nous obtenons des déchets:
Z:\andrew\projects\sx59084>copy uc-test-UTF-16LE-bom.txt CON
■A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
1 file(s) copied.
du fait que copy CON n'affiche pas Unicode correctement, nous pouvons
conclure que la commande type a une logique pour détecter un BOM UTF-16LE à la
démarrer le fichier, et utiliser les API Windows spéciales pour l'imprimer.
nous pouvons le voir en ouvrant cmd.exe dans un débogueur quand il va à type
sortie d'un fichier:
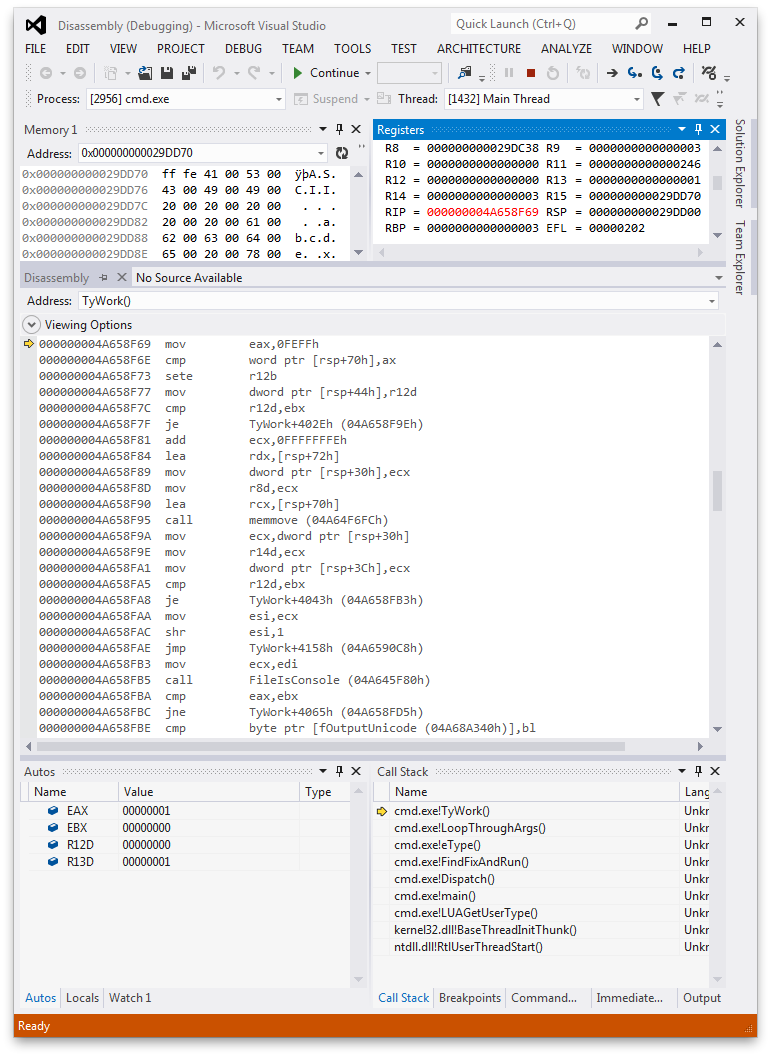
après type ouvre un fichier, il vérifie pour un BOM de 0xFEFF -i.e., les octets
0xFF 0xFE à little-endian-et s'il y a un tel BOM, type fixe
drapeau interne fOutputUnicode . Ce drapeau est vérifié plus tard pour décider
s'il faut appeler WriteConsoleW .
mais c'est la seule façon d'obtenir type pour la sortie Unicode, et seulement pour les fichiers
qui ont des mamans et sont en UTF-16LE. Pour tous les autres fichiers, et pour les programmes
qui n'ont pas de code spécial pour gérer la sortie de la console, vos fichiers seront
interprété selon le codepage actuel, et apparaîtra probablement comme
charabia.
vous pouvez émuler comment type produit Unicode à la console dans vos propres programmes comme cela:
#include <stdio.h>
#define UNICODE
#include <windows.h>
static LPCSTR lpcsTest =
"ASCII abcde xyz\n"
"German äöü ÄÖÜ ß\n"
"Polish ąęźżńł\n"
"Russian абвгдеж эюя\n"
"CJK 你好\n";
int main() {
int n;
wchar_t buf[1024];
HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDLE);
n = MultiByteToWideChar(CP_UTF8, 0,
lpcsTest, strlen(lpcsTest),
buf, sizeof(buf));
WriteConsole(hConsole, buf, n, &n, NULL);
return 0;
}
ce programme fonctionne pour imprimer Unicode sur la console Windows en utilisant le page de codes par défaut.
pour l'exemple de programme Java, nous pouvons obtenir un peu de sortie correcte par configurer le codepage manuellement, bien que la sortie se dégrade de manière étrange:
Z:\andrew\projects\sx59084>chcp 65001
Active code page: 65001
Z:\andrew\projects\sx59084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
ж эюя
CJK 你好
你好
好
�
= bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
еж эюя
CJK 你好
你好
好
�
== UTF-16LE
= no bom
A S C I I a b c d e x y z
…
Toutefois, un programme C qui définit un format Unicode UTF-8 code:
#include <stdio.h>
#include <windows.h>
int main() {
int c, n;
UINT oldCodePage;
char buf[1024];
oldCodePage = GetConsoleOutputCP();
if (!SetConsoleOutputCP(65001)) {
printf("error\n");
}
freopen("uc-test-UTF-8-nobom.txt", "rb", stdin);
n = fread(buf, sizeof(buf[0]), sizeof(buf), stdin);
fwrite(buf, sizeof(buf[0]), n, stdout);
SetConsoleOutputCP(oldCodePage);
return 0;
}
a une sortie correcte:
Z:\andrew\projects\sx59084>.\test
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
La morale de l'histoire?
-
typepeut imprimer des fichiers UTF-16LE avec un BOM indépendamment de votre codepage actuel - les programmes Win32 peuvent être programmés pour produire Unicode à la console, en utilisant
WriteConsoleW. - D'autres programmes qui réglent la page de code et ajustent leur encodage de sortie en conséquence peuvent imprimer Unicode sur la console indépendamment de ce que le codepage était lorsque le programme a commencé
- pour tout le reste , vous aurez à déconner avec
chcp, et obtiendrez probablement toujours une sortie bizarre.
Type
chcp
pour voir votre page de code actuelle (comme Dewfy l'a déjà dit).
Utiliser
nlsinfo
pour voir toutes les pages de code installées et savoir ce que votre numéro de page de code signifie.
vous devez avoir Windows Server 2003 Resource kit installé (fonctionne sur Windows XP) pour utiliser nlsinfo .
pour répondre À votre deuxième question. comment l'encodage fonctionne, Joel Spolsky a écrit un grand article d'introduction sur ce . Fortement recommandé.
CHCP affiche le codepage actuel. Il a trois chiffres: 8xx et est différent de Windows 12xx. Si vous tapez un texte en anglais seulement, vous ne verrez aucune différence, mais une page codée étendue (comme en Cyrillique) sera imprimée à tort.
j'ai été frustré pendant longtemps par les problèmes de page de Code Windows, et les problèmes de portabilité et de localisation des programmes C qu'ils causent. Les billets précédents ont détaillé les questions en détail, donc je ne vais pas ajouter quoi que ce soit à cet égard.
pour faire court, j'ai fini par écrire ma propre couche de compatibilité UTF-8 sur la bibliothèque C Standard de Visual C++. Fondamentalement, cette bibliothèque garantit qu'un programme C standard fonctionne correctement, dans n'importe quelle page de code, utilisation de L'UTF-8 à l'interne.
cette bibliothèque, appelée MsvcLibX, est disponible en open source à https://github.com/JFLarvoire/SysToolsLib . Caractéristiques principales:
- C sources encodées en UTF-8, en utilisant la normale char[] C cordes, et de la bibliothèque standard C Api.
- dans n'importe quelle page de code, tout est traité en interne comme UTF-8 dans votre code, y compris la routine principale () argv [], avec entrée et sortie standard conversion automatique à la page de code de droite.
- Tous les stdio.les fonctions de fichier H prennent en charge les noms de chemin UTF-8 > 260 caractères, jusqu'à 64 KOctets en fait.
- les mêmes sources peuvent compiler et lier avec succès sous Windows en utilisant Visual C++ et MsvcLibX et Visual C++ C library, et sous Linux en utilisant gcc et Linux standard C library, sans besoin de #ifdef ... #endif blocs.
- ajoute des fichiers include communs à Linux, mais manquants dans Visual C.++ Ex: unistd.h
- ajoute des fonctions manquantes, comme celles pour l'E/S des répertoires, la gestion des liens symboliques, etc., toutes avec le support UTF-8 Bien sûr :-).
plus de détails dans le MsvcLibX README sur GitHub , y compris la façon de construire la bibliothèque et de l'utiliser dans vos propres programmes.
la section "release section dans le dépôt GitHub ci-dessus fournit plusieurs programmes en utilisant ce MsvcLibX bibliothèque, qui montrera ses capacités. Ex: Essayez mon quoi.l'outil exe avec des répertoires avec des noms non-ASCII dans le chemin, la recherche de programmes avec des noms non-ASCII, et le changement de pages de code.
un autre outil utile est le conv.programme exe. Ce programme peut facilement convertir un flux de données de n'importe quelle page de code à n'importe quel autre. Sa valeur par défaut est entrée dans la page de code Windows, et sortie dans la page de code console actuelle. Cela permet d'afficher correctement les données générées par Windows GUI apps (ex: Notepad) dans une console de commande, avec une commande simple comme: type WINFILE.txt | conv
cette bibliothèque MsvcLibX n'est en aucun cas complète, et les contributions pour l'améliorer sont les bienvenues!