comment expliquer l'arbre de décision de scikit-learn
j'ai deux problèmes à comprendre le résultat de l'arbre de décision de scikit-learn. Par exemple, c'est un de mes arbres de décision:
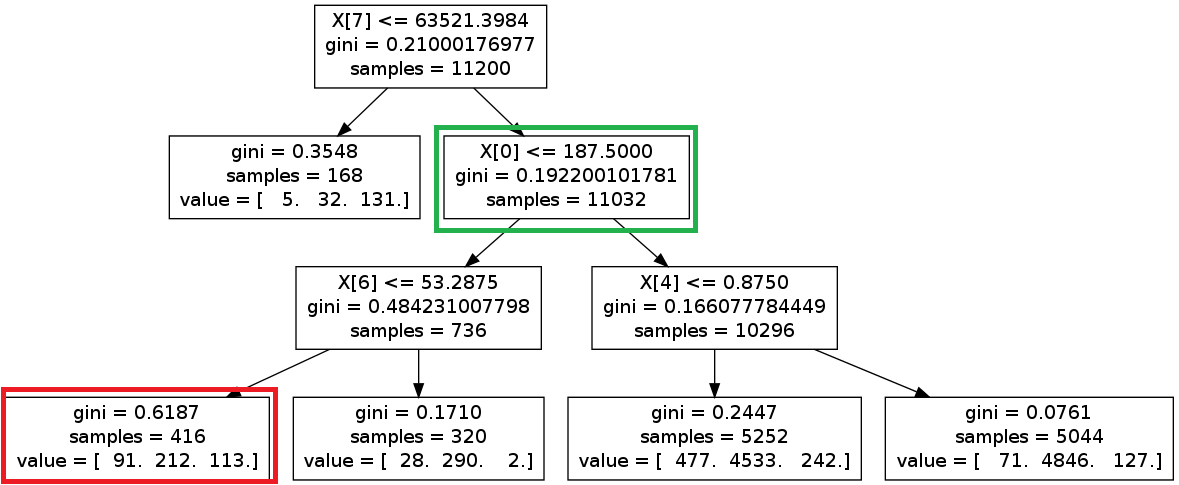 Ma question Est de savoir comment je peux utiliser l'arbre?
Ma question Est de savoir comment je peux utiliser l'arbre?
la première question Est que: si un échantillon satisfait à la condition, alors il va à la gauche succursale (s'il existe), sinon, il va RIGHT. Dans mon cas, si un échantillon avec X[7] > 63521.3984. Ensuite, l'échantillon ira à la boîte verte. - Il Correct?
la deuxième question Est la suivante: quand un échantillon atteint le noeud de la feuille, Comment puis-je savoir quelle catégorie il appartient? Dans cet exemple, j'ai trois catégories pour classer. Dans la boîte rouge, il ya 91, 212, et 113 échantillons sont satisfaits de la condition, respectivement. Mais comment puis-je décider de la catégorie? Je sais qu'il existe une fonction nSi.prédire (échantillon) pour dire la catégorie. Puis-je le faire à partir du graphique??? Merci beaucoup.
3 réponses
value la ligne dans chaque boîte vous dit combien d'échantillons à ce noeud tombent dans chaque catégorie, dans l'ordre. C'est pourquoi, dans chaque case, les nombres value additionnez le nombre indiqué dans sample. Par exemple, dans votre boîte rouge, 91+212+113=416. Cela signifie que si vous atteignez ce noeud, il y avait 91 points de données dans la catégorie 1, 212 dans la catégorie 2, et 113 dans la catégorie 3.
si vous deviez prédire le résultat pour un nouveau point de données qui a atteint cette feuille dans la décision arbre, vous pouvez prédire la catégorie 2, parce que c'est la catégorie la plus commune pour les échantillons à ce noeud.
première question: Oui, votre logique est correcte. Le noeud gauche est vrai et le noeud droit est faux. C'est contre-intuitif; true signifie généralement une valeur plus petite.
deuxième question: Le meilleur moyen de résoudre ce problème est de visualiser l'arbre sous forme de graphique avec pydotplus. L'attribut 'class_names' de tree.export_graphviz () ajoutera une déclaration de classe à la classe majoritaire de chaque noeud. Le Code est exécuté en iPython.
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
clf2 = tree.DecisionTreeClassifier()
clf2 = clf2.fit(iris.data, iris.target)
with open("iris.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
import os
os.unlink('iris.dot')
import pydotplus
dot_data = tree.export_graphviz(clf2, out_file=None)
graph2 = pydotplus.graph_from_dot_data(dot_data)
graph2.write_pdf("iris.pdf")
from IPython.display import Image
dot_data = tree.export_graphviz(clf2, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True, # leaves_parallel=True,
special_characters=True)
graph2 = pydotplus.graph_from_dot_data(dot_data)
## Color of nodes
nodes = graph2.get_node_list()
for node in nodes:
if node.get_label():
values = [int(ii) for ii in node.get_label().split('value = [')[1].split(']')[0].split(',')];
color = {0: [255,255,224], 1: [255,224,255], 2: [224,255,255],}
values = color[values.index(max(values))]; # print(values)
color = '#{:02x}{:02x}{:02x}'.format(values[0], values[1], values[2]); # print(color)
node.set_fillcolor(color )
#
Image(graph2.create_png() )
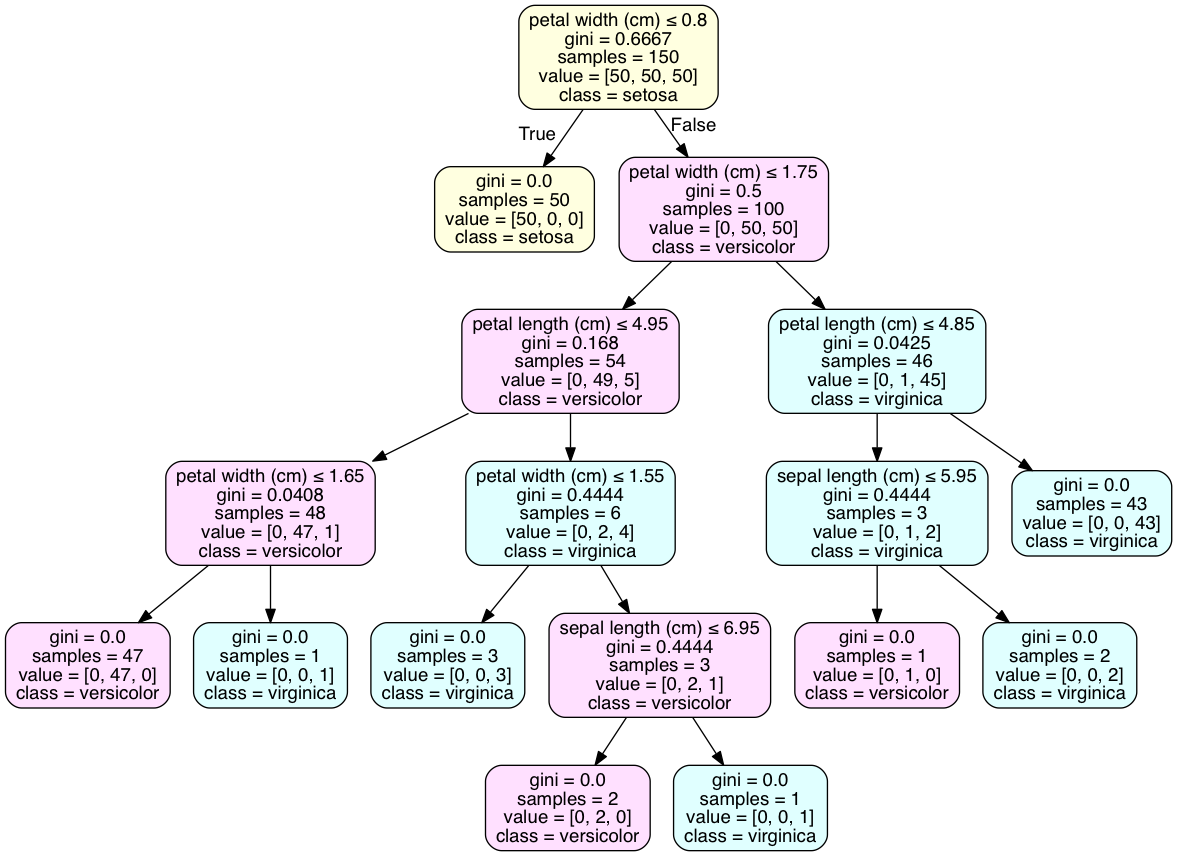
en ce qui concerne la détermination de la classe à la feuille, votre exemple n'a pas de feuilles avec une seule classe, comme le fait l'ensemble de données iris. Cela est courant et peut exiger un ajustement excessif du modèle pour atteindre un tel résultat. Une distribution discrète des classes est le meilleur résultat pour de nombreux modèles à validation croisée.
profitez du code!
selon le livre "Learning scikit-learn: Machine Learning in Python", l'arbre de décision représente une série de décisions basées sur les données de formation.
!(http://i.imgur.com/vM9fJLy.png)
{kind=link}
pour classer une instance, nous devrions répondre à la question à chaque noeud. Par exemple, le sexe, c'Est<=0.5? (sommes-nous parle d'une femme?). Si la réponse est oui, vous allez à la gauche de l'enfant nœud de l'arbre; sinon, vous allez vers la droite nœud enfant. Vous n'arrêtez pas de répondre aux questions (était-elle dans la troisième classe?, elle était dans la première classe? elle avait moins de 13 ans?), jusqu'à ce que vous atteignez une feuille. quand vous êtes là, La Prédiction correspond à la classe cible qui a le plus d'instances.