Pourquoi une fonction d'activation non linéaire doit-elle être utilisée dans un réseau neuronal de rétropropagation?
j'ai lu des choses sur les réseaux neuronaux et je comprends le principe général d'un réseau neuronal à couche unique. Je comprends le besoin de couches aditionnelles, mais pourquoi utilise-t-on des fonctions d'activation non linéaires?
cette question est suivie de celle-ci: Qu'est-ce qu'une dérivée de la fonction d'activation utilisée pour la rétropropagation?
8 réponses
Le but de la fonction d'activation est d'introduire non-linéarité dans le réseau
à son tour, cela vous permet de modéliser une variable de réponse (aka variable cible, étiquette de classe, ou score) qui varie de façon non linéaire avec ses variables explicatives
non-linéaire signifie que la sortie ne peut pas être reproduit à partir d'une combinaison linéaire des entrées (ce qui n'est pas le identique à la sortie qui rend à une ligne droite--le mot pour ceci est affine ).
une autre façon d'y penser: sans une fonction d'activation non-linéaire dans le réseau, un NN, peu importe le nombre de couches qu'il possède, se comporterait comme un perceptron à couche unique, parce que la sommation de ces couches vous donnerait juste une autre fonction linéaire (voir définition ci-dessus).
>>> in_vec = NP.random.rand(10)
>>> in_vec
array([ 0.94, 0.61, 0.65, 0. , 0.77, 0.99, 0.35, 0.81, 0.46, 0.59])
>>> # common activation function, hyperbolic tangent
>>> out_vec = NP.tanh(in_vec)
>>> out_vec
array([ 0.74, 0.54, 0.57, 0. , 0.65, 0.76, 0.34, 0.67, 0.43, 0.53])
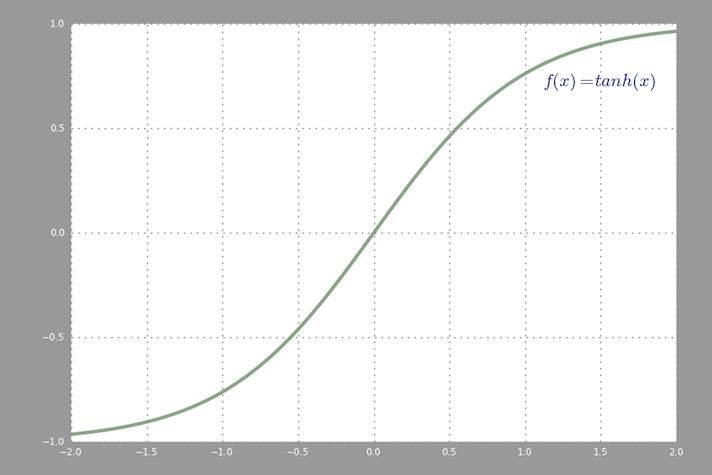
, Une commune de l'activation fonction utilisée dans backprop ( tangente hyperbolique ) évaluée de -2 à 2:
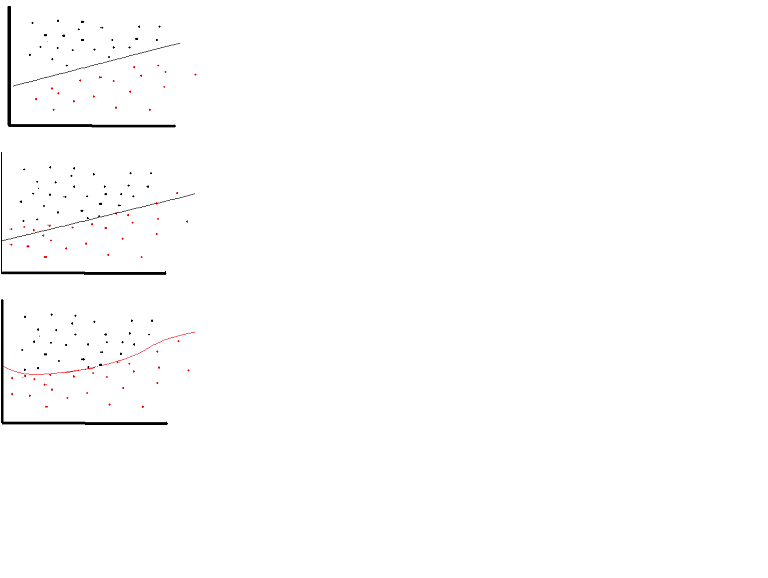
une fonction d'activation linéaire peut être utilisée, mais à des occasions très limitées. En fait, pour mieux comprendre les fonctions d'activation, il est important d'examiner la régression linéaire ou la régression la moins carrée ordinaire. Une régression linéaire vise à trouver les poids optimaux qui donnent un effet vertical minimal entre la variable explicative et la variable cible, lorsqu'elles sont combinées avec l'entrée. En bref, si le résultat attendu reflète la régression linéaire comme indiqué ci-dessous, alors linéaire les fonctions d'activation peuvent être utilisées: (figure du Haut). Mais comme dans la deuxième figure ci-dessous la fonction linéaire ne produira pas les résultats désirés:(figure du milieu). Toutefois, une fonction non linéaire comme celle qui est illustrée ci-dessous produirait les résultats souhaités:(figure du bas))
les fonctions D'Activation ne peuvent pas être linéaires parce que les réseaux neuronaux avec une fonction d'activation linéaire ne sont efficaces que sur une couche profondes, quelle que soit la complexité de leur architecture. L'entrée dans les réseaux est habituellement une transformation linéaire (input * weight), mais le monde réel et les problèmes ne sont pas linéaires. Pour rendre les données entrantes non linéaires, nous utilisons une cartographie non linéaire appelée fonction d'activation. Une fonction d'activation est une fonction de prise de décision qui détermine la présence d'une caractéristique neurale particulière. Il est situé entre 0 et 1, où zéro signifie l'absence de la caractéristique, alors qu'un signifie sa présence. Malheureusement, le petit les changements qui se produisent dans les poids ne peuvent pas être reflétés dans les valeurs d'activation parce qu'ils ne peuvent prendre que 0 ou 1. Par conséquent, les fonctions non linéaires doivent être continues et différenciables entre cette gamme. Un réseau neuronal doit être capable de prendre n'importe quelle entrée de-l'infini à +l'infini, mais il doit être capable de le mapper à une sortie qui varie entre {0,1} ou entre {-1,1} dans certains cas - ainsi le besoin de la fonction d'activation. La Non-linéarité est nécessaire dans les fonctions d'activation parce que son but dans un le réseau neuronal doit produire une frontière de décision non linéaire par des combinaisons non linéaires du poids et des entrées.
si nous n'autorisons que des fonctions d'activation linéaire dans un réseau neuronal, la sortie sera simplement une transformation linéaire de l'entrée, ce qui n'est pas suffisant pour former un approximateur universel de fonction . Un tel réseau peut simplement être représenté comme une multiplication matricielle, et vous ne seriez pas en mesure d'obtenir des comportements très intéressants à partir d'un tel réseau.
la même chose vaut pour le cas où tous les neurones ont affine les fonctions d'activation (c'est-à-dire une fonction d'activation sur la forme f(x) = a*x + c , où a et c sont des constantes, ce qui est une généralisation des fonctions d'activation linéaires), qui aboutiront juste à une transformation affine de l'entrée à la sortie, ce qui n'est pas très excitant non plus.
un réseau neuronal peut très bien contenir des neurones avec des fonctions d'activation linéaires, comme dans la couche de sortie, mais ceux-ci nécessitent la compagnie neurones ayant une fonction d'activation non linéaire dans d'autres parties du réseau.
"Le présent document rend l'utilisation de la Stone-Weierstrass Théorème du cosinus squasher de Gallant et Blanc à établir que la norme multicouches anticipation des architectures de réseau à l'aide de abritrary écraser les fonctions peuvent approximative pratiquement n'importe quelle fonction de l'intérêt de n'importe quel degré de précision, à condition que suffisamment de nombreuses unités cachées sont disponibles."( Hornik et coll., 1989, Réseaux Neuronaux )
une fonction de écrasement est par exemple une fonction d'activation non linéaire qui correspond à [0,1] comme la fonction d'activation sigmoïde.
il y a des moments où un réseau purement linéaire peut donner des résultats utiles. Disons que nous avons un réseau de trois couches avec des formes (3,2,3). En limitant la couche du milieu à seulement deux dimensions, nous obtenons un résultat qui est le "plan de meilleur ajustement" dans l'espace tridimensionnel original.
mais il y a des moyens plus faciles de trouver des transformations linéaires de cette forme, tels que NMF, PCA, etc. Toutefois, il s'agit d'un cas où un réseau à plusieurs niveaux ne se comporte pas de la même manière qu'un perceptron à couche simple.
comme je me souviens - les fonctions sigmoïdes sont utilisées parce que leur dérivée qui s'adapte à l'algorithme de BP est facile à calculer, quelque chose de simple comme f(x)(1-f(x)). Je ne me souviens pas exactement des maths. En fait n'importe quelle fonction avec des dérivés peut être utilisée.
en couches NN de plusieurs neurones peuvent être utilisés pour apprendre de façon linéaire inséparable de problèmes. Par exemple la fonction XOR peut être obtenue avec deux couches avec la fonction d'activation pas à pas.
Ce n'est pas du tout une obligation. En fait, la fonction d'activation linéaire rectifiée est très utile dans les grands réseaux neuronaux. Le calcul du gradient est beaucoup plus rapide, et il induit la sparsity en fixant une limite minimale à 0.
voir ci-dessous pour plus de détails: https://www.academia.edu/7826776/Mathematical_Intuition_for_Performance_of_Rectified_Linear_Unit_in_Deep_Neural_Networks
Edit:
il y a eu une discussion sur la question de savoir si la fonction d'activation linéaire rectifiée peut être appelée une fonction linéaire.
Oui, c'est techniquement une fonction non linéaire parce qu'elle n'est pas linéaire au point x=0, cependant, il est encore correct de dire qu'elle est linéaire à tous les autres points, donc je ne pense pas que c'est utile de nitpick ici,
j'aurais pu choisir la fonction d'identité et ce serait encore vrai, mais J'ai choisi ReLU comme exemple en raison de sa popularité récente.