Comment comprendre L'algorithme D'optimisation des politiques proximales dans RL?
je connais les bases de L'apprentissage du renforcement, mais quels termes il est nécessaire de comprendre pour pouvoir lire arxiv PPO paper ?
Quelle est la feuille de route pour apprendre et utiliser PPO ?
3 réponses
les autres réponses ont dit quelques choses utiles au sujet du PPO, mais je ne pense pas qu'ils fondaient le papier assez bien dans les bases (exigeant la connaissance du TRPO, qui est une méthode mathématique dense et difficile à comprendre) ou de jeter beaucoup de lumière sur ce que la fonction d'objectif de coupure fait.
pour mieux comprendre PPO, je pense qu'il est utile d'examiner les principales contributions du document, qui sont: (1) la Tondue de Substitution Objectif et (2) l'utilisation de "plusieurs époques de la stochastique gradient de montée à effectuer chaque jour de la politique".
Tout d'abord, pour ancrer ces points dans l'original PPO paper:
nous avons introduit [PPO], une famille de méthodes d'optimisation des politiques qui utilisent plusieurs époques d'ascension du gradient stochastique pour effectuer chaque mise à jour de politique. Ces méthodes ont la stabilité et la fiabilité de confiance-région [ TRPO] les méthodes, mais sont beaucoup plus simples à mettre en œuvre, nécessitant seulement quelques lignes de code à modifier à la vanille, de la politique de gradient de mise en œuvre, applicable dans des contextes plus généraux (par exemple, en utilisant une architecture conjointe pour la fonction de politique et de valeur), et avoir une meilleure performance globale.
1. L'Objectif De La Mère Porteuse Coupée
L'objectif de Substitution tronqué remplace l'Objectif du gradient de politique qui est conçu pour: améliorez la stabilité de la formation en limitant les changements que vous apportez à votre politique à chaque étape.
Pour la vanille de la politique de dégradés (par exemple, RENFORCER) --- que vous devez être familier avec, ou familiarisez-vous avec avant de lire ceci - - - l'objectif utilisé pour optimiser le réseau neuronal ressemble à:

C'est la formule standard que vous pouvez voir dans le Sutton livre, et autresressources, où l'avantage (un chapeau) est souvent remplacé par le rendement escompté. En faisant un pas de pente ascendante sur cette perte par rapport aux paramètres du réseau, vous encouragerez les actions qui ont conduit à une récompense plus élevée.
la méthode vanilla policy gradient utilise la probabilité logarithmique de votre action (log π (a / s)) pour tracer l'impact des actions, mais vous pouvez imaginer d'utiliser une autre fonction pour le faire. Une autre fonction, introduit dans ce document, utilise la probabilité de l'action sous le politique actuelle (π(a|s)), divisée par la probabilité de l'action sous votre politique précédente (n_old (a / s)). Cela ressemble un peu à l'échantillonnage d'importance si vous êtes familier avec cela:
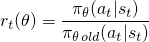
ce r (θ) sera supérieur à 1 lorsque l'action est plus probable pour votre Politique que pour votre vieux politique; elle doit être comprise entre 0 et 1 lorsque l'action est moins probable pour votre politique actuelle que pour les vieux.
maintenant, pour construire une fonction objective avec CE r (θ), Nous pouvons simplement l'échanger pour le terme log π(a|s). C'est ce qui est fait dans la méthode TRPO:
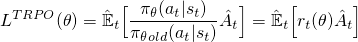
mais que se passerait-il ici si votre action est beaucoup plus probable (comme 100x plus) pour votre police actuelle? r (θ) aura tendance à être vraiment grand et conduire à prendre de grandes mesures de gradient qui pourraient détruire votre politique. Pour faire face à cette situation, la méthode du TRPO ajoute plusieurs cloches et sifflets supplémentaires (p. ex., des contraintes de Divergence KL) pour limiter le montant que la politique peut changer et aider à garantir qu'elle s'améliore de façon monotone.
au lieu d'ajouter toutes ces cloches et sifflets supplémentaires, et si nous pouvions construire ces propriétés dans le la fonction objectif? Comme vous pouvez le deviner, C'est ce que fait le PPO. Il gagne les mêmes avantages de performance et évite les complications en optimisant ce simple (mais genre de regard drôle) Clipped objectif de Substitution:
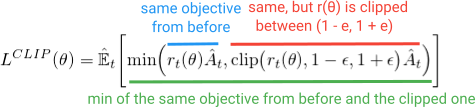
le premier terme (bleu) à l'intérieur de la minimisation est le même terme (R(θ)a) que nous avons vu dans l'Objectif du TRPO. Le second terme (rouge) est une version où le (R(θ)) est clippé entre (1 - e, 1 + e). (dans le papier qu'ils état une bonne valeur pour e est d'environ 0.2, donc r peut varier entre ~(0.8, 1.2)). Puis, finalement, la minimisation de ces deux termes est prise (Vert).
prenez votre temps et regardez attentivement l'équation et assurez-vous de savoir ce que tous les symboles signifient, et mathématiquement ce qui se passe. Regarder le code peut aussi aider; voici la section pertinente dans les deux OpenAI lignes de base et anyrl-py implémentations.
Grande.
ensuite, voyons quel effet la fonction l clip crée. Voici un diagramme de l'article qui trace la valeur de l'Objectif du clip lorsque L'avantage est positif et négatif:
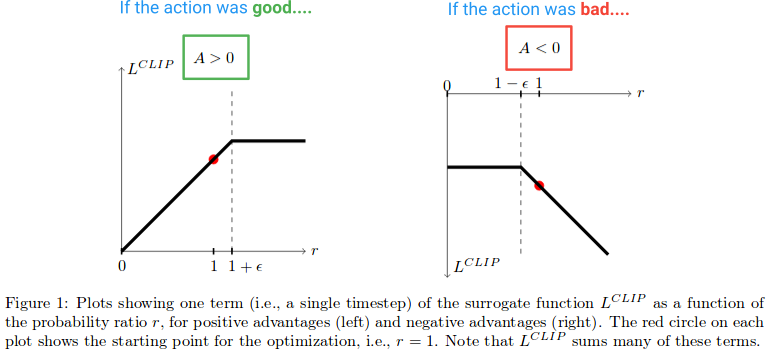
sur la moitié gauche du diagramme, où (A > 0), c'est là que l'action a eu un effet positif estimé sur le résultat. Sur la moitié droite du diagramme, où (A < 0), c'est là que l'action avait estimé négatif effet sur le résultat.
remarquez comment sur la moitié gauche, la valeur r est coupée si elle devient trop élevée. Ce sera le cas si l'action est devenue beaucoup plus probable en vertu de la politique actuelle qu'elle ne l'était pour l'ancienne politique. Lorsque cela se produit, nous ne voulons pas devenir gourmands et aller trop loin (parce que c'est juste une approximation locale et échantillon de notre politique, il ne sera pas exact si nous allons trop loin), et donc nous clip l'objectif pour l'empêcher de croître. (Ce sera l' effet dans le col arrière de blocage du gradient --- la ligne plate provoquant le gradient à 0).
du côté droit du diagramme, où l'action avait une estimation négative effet sur le résultat, nous voyons que le clip s'active près de 0, où l'action dans le cadre de la politique actuelle est peu probable. Cette région de découpage nous empêchera également de mettre à jour trop pour rendre l'action beaucoup moins probable après que nous avons déjà fait un grand pas pour le rendre moins probable.
nous voyons donc que ces deux régions de découpage nous empêchent de devenir trop gourmands et d'essayer de mettre à jour trop à la fois, et de mettre à jour en dehors de la région où cet échantillon offre une bonne approximation.
mais pourquoi laissons-nous le r(θ) croître indéfiniment du côté droit du diagramme? Cela semble étrange en premier lieu, mais qu'est-ce qui ferait croître R(θ) vraiment grand dans ce cas? R (θ) la croissance dans cette région sera causée par un gradient l'étape qui a fait de notre action beaucoup plus probable, et il en train de rendre notre politique pire. Si tel était le cas, nous souhaiterions être en mesure de défaire cette pente. Et il se trouve que la L fonction clip permet. La fonction est négative ici, donc le gradient nous dira de marcher dans l'autre direction et de rendre l'action moins probable d'une quantité proportionnelle à combien nous l'avons foiré.
et si vous vous demandiez encore pourquoi nous prenons la minimisation des termes non découpés et découpés, c'est la région qu'il explique. C'est la région qui correspond à la déclipse r(θ)ayant une valeur inférieure à la version détourée et se retourné par la minimisation.
Normalement nous voulons couper l'objectif et nous empêcher de faire trop grand d'un pas. Mais, dans ce cas particulier, nous ne voulons pas nous empêcher de pouvoir réparer l'erreur que nous venons de commettre.
Et ici est un diagramme résumant ceci:
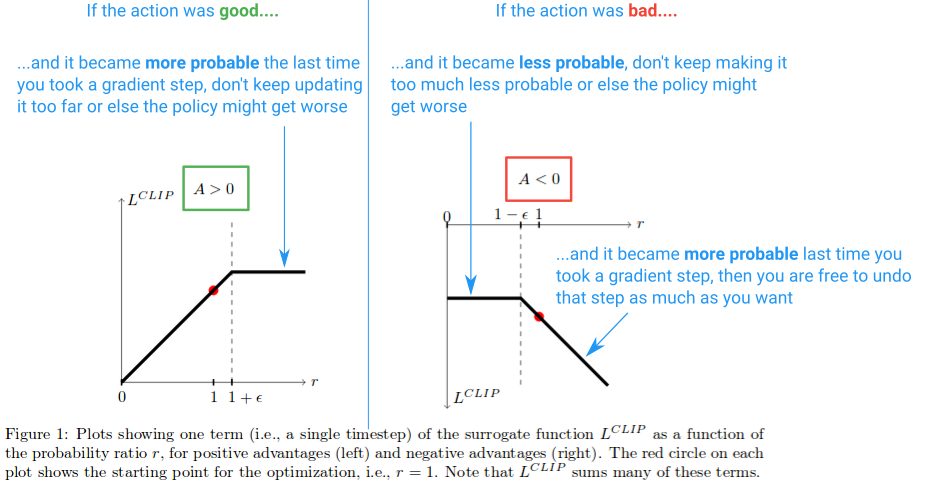
Et c'est l'essentiel. L'objectif de Substitution Clipped n'est qu'une solution de remplacement que vous pouvez utiliser dans le gradient de politique vanille, et son but est de limiter le changement efficace que vous pouvez faire à chaque étape, afin d'améliorer la stabilité. Une chose que je n'ai pas discutée est ce que signifie le fait que le PPO soit une "limite inférieure" comme discuté dans le document. Pour en savoir plus, je vous suggère d' ceci la partie d'une conférence de l'auteur.
2. Plusieurs époques pour la mise à jour des politiques
Contrairement aux méthodes de gradient de politique vanille, et en raison de la fonction de Substitution objective clippée, PPO vous permet d'exécuter plusieurs époques de gradient ascendant sur vos échantillons sans causer de grandes mises à jour destructives de la Politique. Cela vous permet d'extraire plus de vos données et de réduire l'inefficacité de l'échantillon.
PPO exécute la politique en utilisant N des acteurs parallèles recueillant chacun des données, et puis il prélève des mini-lots de ces données pour s'entraîner à K epochs utilisant la fonction D'objectif de Substitution coupée. Voir l'algorithme complet ci-dessous (les valeurs approximatives de param sont: K = 3-15, M = 64-4096, T (horizon) = 128-2048):

la partie des acteurs parallèles a été popularisée par le A3C papier et est devenu un moyen assez standard de collecter des données.
La nouvelle partie, c'est qu'ils sont en mesure d'exécuter K époques de gradient ascendant sur les échantillons de trajectoire. Comme ils l'indiquent dans le document, il serait agréable d'exécuter l'optimisation de gradient de politique vanille pour les passages multiples sur les données afin que vous puissiez en apprendre plus de chaque échantillon. Cependant, cela échoue généralement dans la pratique pour les méthodes à la vanille parce qu'ils prennent trop de mesures sur les échantillons locaux et ce épaves de la politique. PPO, d'un autre côté, a le mécanisme intégré pour empêcher trop d'une mise à jour.
pour chaque itération, après avoir échantillonné l'environnement avec n_old (ligne 3) et lorsque nous démarrons l'optimisation (ligne 6), notre Politique π sera exactement égale à n_old. Ainsi, au début, aucune de nos mises à jour ne sera clippée et nous sommes assurés d'apprendre quelque chose de ces exemples. Cependant, à mesure que nous mettrons à jour π En utilisant plusieurs époques, l'objectif commencera à atteindre les limites de coupe, le gradient passera à 0 pour ces échantillons, et l'entraînement s'arrêtera progressivement...jusqu'à ce que nous passons à la prochaine itération et de recueillir de nouveaux échantillons.
....
Et c'est tout pour aujourd'hui. Si vous êtes intéressé à obtenir une meilleure compréhension, je recommande creuser plus dans le papier original, en essayant de le mettre en œuvre vous-même, ou plonger dans l' les lignes de base de mise en œuvre et jouer avec le code.
PPO est un algorithme simple, qui relève de la classe des algorithmes d'optimisation des politiques (par opposition aux méthodes basées sur des valeurs telles que DQN). Si vous "connaissez" les rudiments de la RL (je veux dire si vous avez au moins lu attentivement certains premiers chapitres de Le Livre de Sutton par exemple), puis une première étape logique est de se familiariser avec la politique de gradient algorithmes. Vous pouvez lire ce document ou le chapitre 13 de l' Le Livre de Sutton nouvelle édition. En outre, vous pouvez aussi lire ce document sur TRPO, qui est un travail précédent du premier auteur de PPO (ce papier a de nombreuses erreurs de notation; notez juste). Espérons que cela aide. -- Mehdi!--9-->
PPO, et en incluant TRPO tente de mettre à jour la Politique de façon prudente, sans affecter son rendement de manière négative entre chaque mise à jour de politique.
Pour ce faire, vous avez besoin d'un moyen de mesurer combien la politique a changé après chaque mise à jour. Cette mesure est effectuée en examinant la divergence KL entre la politique mise à jour et l'ancienne politique.
cela devient un problème d'optimisation limité, nous voulons changer la politique dans la direction de la performance maximale, suivant les contraintes que la divergence KL entre ma nouvelle politique et l'ancienne ne dépasse pas un certain seuil prédéfini (ou adaptatif).
avec TRPO, nous calculons la contrainte KL pendant la mise à jour et trouvons le taux d'apprentissage pour ce problème (via la matrice Fisher et le gradient conjugué). C'est un peu salissant à mettre en œuvre.
avec PPO, nous simplifions le problème en tournant la divergence KL d'une contrainte à un terme de pénalité, similaire par exemple à L1, L2 pénalité de poids (pour éviter un poids croissant de grandes valeurs). PPO apporte des modifications supplémentaires en supprimant la nécessité de calculer la divergence KL tous ensemble, en découpant le ratio de la Politique (ratio de la politique mise à jour avec l'ancienne) pour être dans une petite fourchette autour de 1,0, où 1,0 signifie que la nouvelle politique est la même que l'ancienne.