Qu'est-ce qu'une couche de projection dans le contexte des réseaux neuronaux?
J'essaie actuellement de comprendre l'architecture derrière l'algorithme word2vec neural net learning, pour représenter les mots en tant que vecteurs en fonction de leur contexte.
Après avoir lu papier Tomas Mikolov je suis tombé sur ce qu'il définit comme une couche de projection . Même si ce terme est largement utilisé lorsqu'il est fait référence à word2vec , Je n'ai pas pu trouver une définition précise de ce qu'il est réellement dans le réseau neuronal cadre.
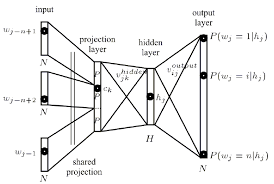
Ma question Est, dans le contexte du réseau neuronal, qu'est-ce qu'une couche de projection? Est-ce le nom donné à une couche cachée dont les liens vers les nœuds précédents partagent les mêmes poids? Est-ce que ses unités ont réellement une fonction d'activation de quelque sorte?
une autre ressource qui fait également référence plus largement au problème se trouve dans ce tutoriel , qui fait également référence à une couche de projection autour de la page 67.
2 réponses
La couche de projection mappe les indices de mots discrets d'un contexte de n grammes à un espace vectoriel continu.
, Comme expliqué dans cette thèse de
La couche de projection est partagée de telle sorte que pour les contextes contenant le même mot plusieurs fois, le même ensemble de poids est appliqué pour former chaque partie du vecteur de projection. Cette organisation augmente efficacement la quantité de données disponibles pour la formation des poids de couche de projection depuis chaque mot de chaque modèle de formation de contexte contribue individuellement à des changements aux valeurs de poids.
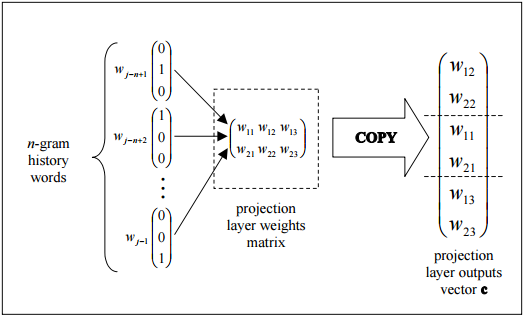
Cette figure montre la topologie triviale comment la sortie de la couche de projection peut être assemblée efficacement en copiant des colonnes de la matrice de poids de couche de projection.
Maintenant, le calque caché:
Le calque masqué traite la sortie du calque de projection et est également créé avec un nombre de neurones spécifié dans la topologie fichier de configuration.
Edit: Une explication de ce qui se passe dans le diagramme
Chaque neurone de la couche de projection est représenté par un nombre de poids égal à la taille du vocabulaire. La couche de projection diffère des couches masquées et de sortie en n'utilisant pas de fonction d'activation non linéaire. Son but est simplement de fournir un moyen efficace de projeter le contexte de n - gramme donné sur un espace vectoriel continu réduit pour des traitement par des couches cachées et de sortie formées pour classer de tels vecteurs. Compte tenu de la nature un ou zéro des éléments vectoriels d'entrée, la sortie d'un mot particulier avec l'index i est simplement la ième colonne de la matrice formée de poids de couche de projection (où chaque ligne de la matrice représente les poids d'un seul neurone).
Le {[0] } est utilisé pour prédire un seul mot compte tenu de ses entrées antérieures et futures: c'est donc un résultat contextuel.
Les entrées sont les poids calculés des entrées précédentes et futures: et toutes sont données de nouveaux poids de manière identique: ainsi le nombre de complexité / caractéristiques de ce modèle est beaucoup plus petit que beaucoup d'autres architectures NN.
RE: what is the projection layer: de l'article que vous avez cité
La couche cachée non linéaire est supprimée et la couche de projection est partagé par tous mots (pas seulement la matrice de projection); ainsi, tous les mots être projeté dans la même position (leurs vecteurs sont moyennés).
Donc la couche de projection est un ensemble unique de shared weights et aucune fonction d'activation n'est indiquée.
Notez que la matrice de poids entre l'entrée et la couche de projection est partagé pour toutes les positions de mots de la même manière que dans le NNLM
Donc, le hidden layer est en fait représenté par cet ensemble unique de poids partagés-comme vous correctement implicite qui est identique sur tous les nœuds d'entrée.