Quelles sont les différences entre les transformations jointure et Lookup dans SSIS?
Salut, je suis nouveau sur des packages SSIS et la rédaction d'un paquet et à la lecture à leur sujet en même temps.
j'ai besoin de convertir un DTS en un paquet SSIS et j'ai besoin d'effectuer une jointure sur deux sources à partir de différentes bases de données et je me demandais ce qui était la meilleure répartition, pour utiliser une recherche ou une jointure de fusion?
à la surface, ils semblent très similaires. La "jointure de fusion" exige que les données soient triées avant la main tandis que la "recherche" ne nécessite pas ce. Tout conseil serait très utile. Remercier.
7 réponses
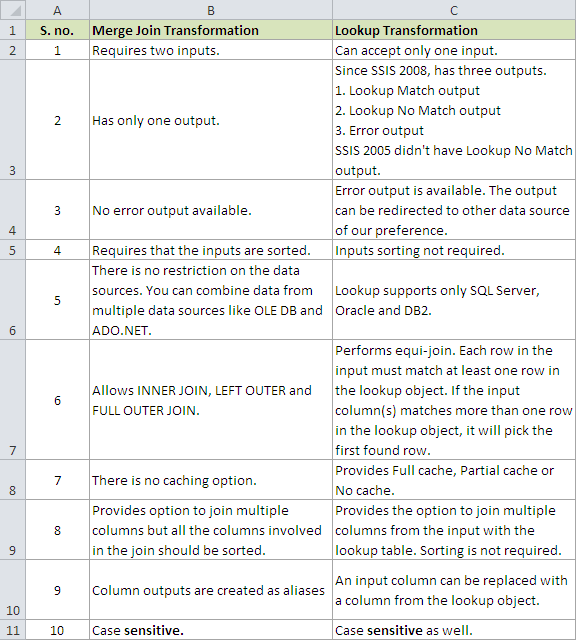
Screenshot # 1 montre peu de points pour distinguer entre Merge Join transformation et Lookup transformation .
Concernant La Recherche:
si vous voulez trouver des lignes correspondant à la source 2 à partir de la source 1 et si vous savez qu'il n'y aura qu'une seule correspondance pour chaque ligne d'entrée, alors je suggère d'utiliser L'opération de recherche. Un exemple serait vous OrderDetails table et vous voulez trouver le correspondant Order Id et Customer Number , alors la recherche est une meilleure option.
Concernant La Fusion Rejoindre:
si vous voulez effectuer des jointures comme aller chercher toutes les adresses (maison, travail, autre) de Address table pour un client donné dans la table Customer , alors vous devez aller avec jointure de fusion parce que le client peut avoir 1 ou plusieurs adresses associées avec eux.
un exemple à comparer:
voici un scénario pour démontrer les différences de rendement entre Merge Join et Lookup . Les données utilisées ici est une jointure qui est le seul scénario commun entre eux à comparer.
-
j'ai trois tables nommées
dbo.ItemPriceInfo,dbo.ItemDiscountInfoetdbo.ItemAmount. Les scripts de création pour ces tables sont fournis dans la section scripts SQL. -
Tables
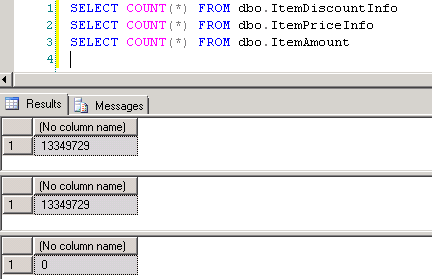
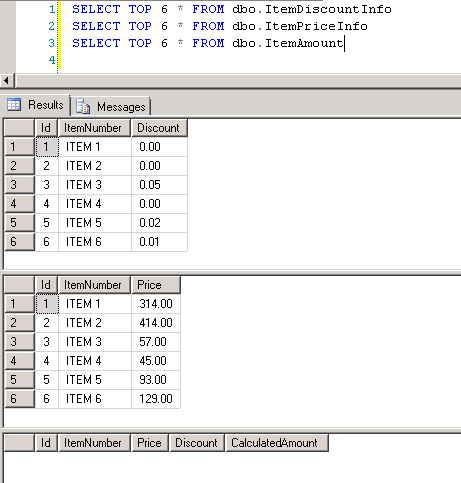
dbo.ItemPriceInfoetdbo.ItemDiscountInfoont toutes deux 13 349 729 lignes. Les deux tableaux ont le numéro D'article comme colonne commune. ItemPriceInfo contient des informations sur les prix et ItemDiscountInfo contient des informations sur les remises. La capture d'écran # 2 montre le nombre de lignes dans chacun de ces tableaux. La capture d'écran # 3 montre les 6 premières lignes pour donner une idée des données présentes dans les tableaux. -
j'ai créé deux petites entreprises paquets pour comparer les performances des transformations jointure et Lookup. Les deux paquets doivent prendre l'information des tableaux
dbo.ItemPriceInfoetdbo.ItemDiscountInfo, calculer le montant total et le sauvegarder dans la tabledbo.ItemAmount. -
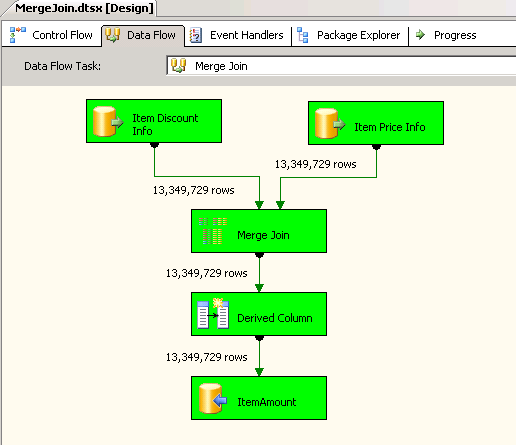
premier paquet utilisé
Merge Jointransformation et à l'intérieur qu'il a utilisé joint interne pour combiner les données. Les captures d'écran # 4 et # 5 montrer l'exemple l'exécution du paquet et la durée de l'exécution. Il a fallu05minutes14secondes719millisecondes pour exécuter le paquet de transformation de jointure de fusion basé. -
Deuxième paquet utilisé
Lookupla transformation Complète du cache (ce qui est le réglage par défaut). creenshots # 6 et # 7 affiche l'exécution du paquet échantillon et la durée de l'exécution. Il a fallu11minutes03secondes610millisecondes pour exécuter le paquet basé sur la transformation Lookup. Vous pourriez rencontrer les informations du message d'avertissement:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.voici un lien qui parle de la façon de calculer la taille du cache de recherche. Au cours de ce package l'exécution, même si la tâche de flux de données s'est terminée plus rapidement, le nettoyage du Pipeline a pris beaucoup de temps. -
ce ne signifie pas que la transformation de la recherche est mauvaise. C'est juste qu'il doit être utilisé à bon escient. Je l'utilise assez souvent dans mes projets mais encore une fois je ne traite pas avec 10+ millions de lignes pour la recherche quotidienne. Habituellement, mes travaux traitent entre 2 et 3 millions de lignes et pour cela la performance est vraiment bonne. Jusqu'à 10 millions de rangs, les deux fonctionnent tout aussi bien. La plupart du temps ce que j'ai remarqué, c'est que le goulot d'étranglement s'avère être le composant de destination plutôt que les des transformations. Vous pouvez surmonter cela en ayant plusieurs destinations. ici est un exemple qui montre la mise en œuvre de destinations multiples.
-
Capture d'écran # 8 indique le nombre d'enregistrements dans les trois tableaux. La capture d'écran # 9 montre les 6 meilleurs enregistrements dans chacun des tableaux.
Espère que ça aide.
Scripts SQL:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Capture d'écran #1:
Capture d'écran #2:
Capture d'écran #3:
Capture d'écran #4:
Capture d'écran #5:

Capture d'écran #6:
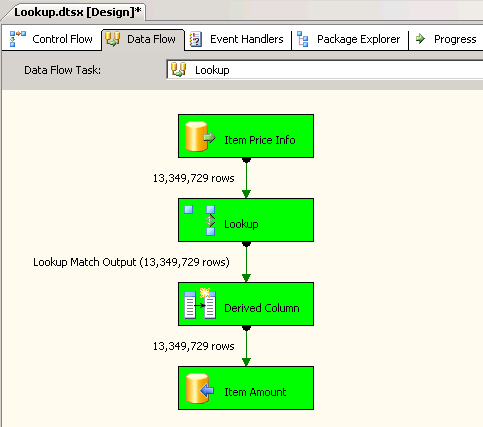
Capture d'écran #7:
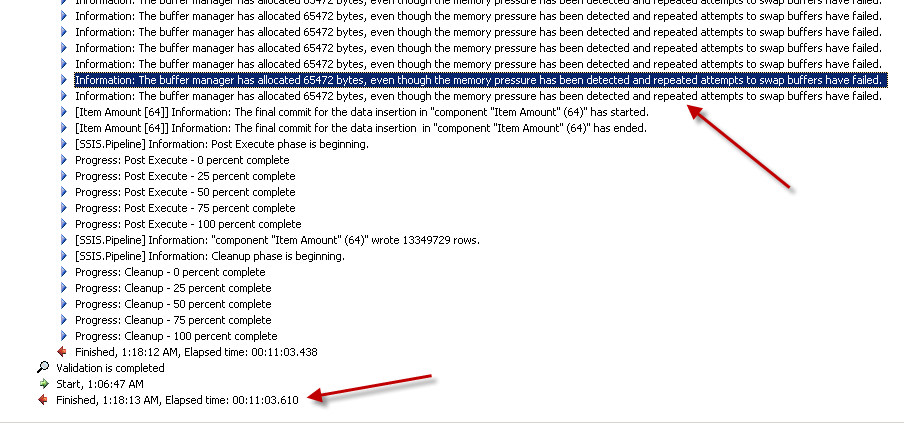
Capture d'écran n ° 8:
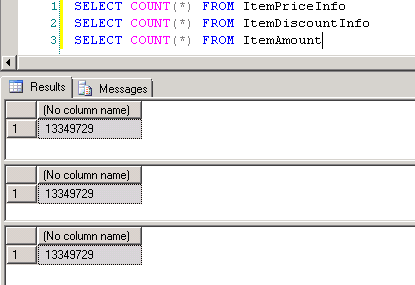
Capture d'écran n ° 9:
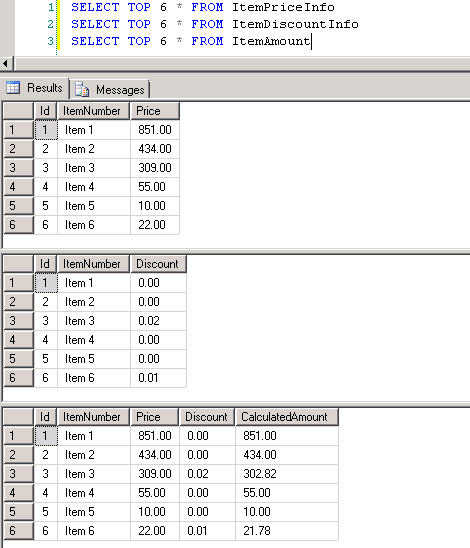
une jointure de fusion est conçu pour produire des résultats similaires à la façon dont les jointures fonctionnent en SQL. Le composant de recherche ne fonctionne pas comme une jointure SQL. Voici un exemple où les résultats seraient différents.
si vous avez une relation de un à plusieurs entre l'entrée 1 (p. ex. factures) et l'entrée 2 (p. ex. Articles de ligne de facture), vous voulez que les résultats de la combinaison de ces deux entrées comprennent une ou plusieurs lignes pour une seule facture.
avec une fusion rejoindre vous sera obtenir la sortie désirée. Avec une Recherche, où l'entrée 2 est la source, la sortie sera une ligne de la facture, peu importe le nombre de lignes existent dans l'entrée 2. Je ne me souviens pas quelle rangée de l'entrée 2 les données viendraient, mais je suis presque sûr que vous obtiendrez un double avertissement de données, au moins.
ainsi, chaque composante a son propre rôle dans les petites industries.
je vais suggérer une troisième alternative à considérer. Votre source OLE DBSource pourrait contenir une requête plutôt qu'une table et vous pourriez faire la jointure là. Ce n'est pas bon dans toutes les situations, mais quand vous pouvez l'utiliser, alors vous n'avez pas à trier au préalable.
Lookup est similaire à gauche-join in Merge Join component. La fusion peut faire d'autres types de jointures, mais si c'est ce que vous voulez, la différence est principalement dans performance et la commodité.
leurs caractéristiques de performance peuvent être très différentes selon la quantité relative de données à rechercher (entrée à composante de recherche) et la quantité de données référencées (cache de recherche ou taille de la source de données).
E. g. si vous avez seulement besoin pour rechercher 10 lignes, mais l'ensemble de données référencées est de 10 millions de lignes - la recherche en utilisant le mode de cache partiel ou sans cache sera plus rapide car il ne récupérera que 10 enregistrements, plutôt que 10 millions. Si vous avez besoin de rechercher 10 millions de lignes, et l'ensemble de données référencées est de 10 lignes - la recherche en cache est probablement plus rapide (à moins que ces 10 millions de lignes soient déjà triées de toute façon et que vous puissiez essayer de fusionner jointure). Si les deux ensembles de données sont grands (en particulier si plus de RAM disponible) ou le plus grand est trié - fusionner pourrait être meilleur choix.
il y a 2 différences:
-
Tri:
- une jonction de fusion nécessite les deux entrées doivent être triées de la même manière La recherche
- ne nécessite aucune entrée pour être triée.
-
requête de Base de données de la charge:
- une jointure de fusion ne se réfère pas à la base de données, juste les 2 entrées flux (bien que les données de référence est généralement sous la forme de "select * from table order by joindre les critéres' ) La recherche
- émettra une requête pour chaque valeur (distincte, si mise en cache) à laquelle il est demandé de participer. Cela devient rapidement plus cher que le select ci-dessus.
cela conduit à: si ce n'est pas un effort pour produire une liste triée, et que vous voulez plus de 1% des lignes (une seule ligne sélectionne ~100x le coût de la même ligne en streaming) (vous ne voulez pas trier une table de 10 millions de lignes en mémoire ..) puis fusionner rejoindre est la voie à suivre.
si vous attendez seulement un petit nombre d'allumettes (valeurs distinctes levées, lorsque la mise en cache est activée) alors la recherche est meilleure.
pour moi, le compromis entre les deux se situe entre des rangées de 10k et 100k qui doivent être levées.
celui qui est Le plus rapide dépendra de
- le nombre total de lignes à traiter. (si la table est résidente de mémoire, une sorte de données à fusionner il est bon marché)
- le nombre de recherches en double attendu. (haut par ligne des frais indirects de la recherche)
- si vous pouvez sélectionner des données triées (notez que les tris de texte sont influencés par la compilation de code, alors faites attention que ce que sql considère trié est aussi ce que ssis considère trié)
- quel pourcentage de la table entière vous regardez vers le haut. (la fusion exigera de sélectionner chaque ligne, la recherche est meilleure si vous avez seulement quelques lignes d'un côté)
- la largeur d'une rangée (les rangées par page peuvent fortement influencer le coût de l'io de faire des recherches simples vs un balayage) (les rangées étroites -> plus de préférence pour la fusion)
- l'ordre des données sur le disque (facile à produire la sortie triée, préfèrent la fusion, si vous pouvez organiser les recherches à faire dans l'ordre physique du disque, les recherches sont moins coûteux en raison de moins les défauts de cache)
- latence réseau entre le serveur ssis et la destination (latence plus grande -> prefer merge)
- combien d'effort de codage vous souhaitez dépenser (la fusion est un peu plus complexe à écrire)
- la compilation des données d'entrée -- Fusion SSIS a des idées wierd sur le tri des chaînes de texte qui contiennent des caractères non alphanumériques, mais ne sont pas nvarchar. (cela va au tri, et de faire en sorte que sql émette une sorte que ssis est heureux à l'opération de fusion est dur)
Merge Join vous permet de vous joindre à plusieurs colonnes basées sur un ou plusieurs critères, alors qu'une recherche est plus limitée en ce sens qu'elle ne récupère qu'une ou plusieurs valeurs basées sur des informations de colonne correspondantes -- la recherche de recherche de recherche va être lancée pour chaque valeur dans votre source de données (bien que SSIS cache la source de données si elle le peut).
cela dépend vraiment de ce que vos deux sources de données contiennent et comment vous voulez que votre source finale veille à la fusion. Pourriez-vous fournir plus de détails sur les schémas de votre paquet DTS?
une autre chose à considérer est la performance. Si utilisé incorrectement, chacun pourrait être plus lent que l'autre, mais encore une fois, il va dépendre de la quantité de données que vous avez et vos schémas de source de données.
je sais qu'il s'agit d'une vieille question, mais un point critique qui, à mon avis, n'a pas été couvert par les réponses données est que parce que la jonction de fusion est la fusion de deux flux de données, il peut combiner des données à partir de n'importe quelle source. Alors qu'avec la recherche, une source de données doit être conservée dans un OLE DB.