Comment puis-je charger un grand fichier plat dans une table de base de données en utilisant SSIS?
Je ne sais pas comment ça marche donc je cherche la bonne solution. Je pense que SSIS est la bonne voie à suivre mais je ne l'ai jamais utilisé avant
scénario:
chaque matin, je reçois un onglet délimité fichier avec 800K enregistrements. Je dois le charger dans ma base de données:
- Obtenir le fichier du ftp ou en local
- tout d'abord, je dois supprimer celui qui n'existe pas dans le nouveau fichier de la base de données;
- Comment puis-je comparer les données dans tsql
- Où dois-je charger des données à partir d'un fichier délimité par des onglets afin de les comparer avec le fichier? Dois-je utiliser une table d'intérim?
ItemIDest la colonne unique du tableau.
- deuxièmement, je dois insérer seulement les nouveaux enregistrements dans la base de données.
- bien sûr, il devrait être automatisé.
- il devrait être manière efficace sans surchauffe SQL Base de données
N'oubliez pas que le fichier contient des notices de 800K.
de l'Échantillon de données de fichier plat:
ID ItemID ItemName ItemType
-- ------ -------- --------
1 2345 Apple Fruit
2 4578 Banana Fruit
comment aborder ce problème?
5 réponses
Oui, SSIS peut exécuter les exigences que vous avez spécifiées dans la question. L'exemple suivant devrait vous donner une idée de la façon dont il peut être fait. Exemple utilise SQL Server comme back-end. Certains des scénarios d'essai de base exécutés sur le colis sont présentés ci-dessous. Désolé pour la longue réponse.
procédé par étapes:
-
dans la base de données SQL Server, créer deux tables à savoir
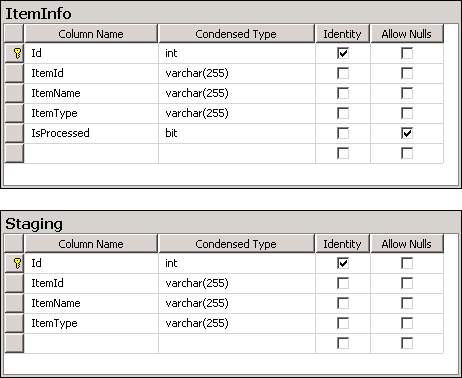
dbo.ItemInfoetdbo.Staging. Les requêtes de création de table sont disponibles sous Scripts section. La Structure de ces tableaux est montrée dans la capture d'écran # 1 .ItemInfoconservera les données réelles etStagingconservera les données de stadification pour comparer et mettre à jour les enregistrements réels. La colonneIdde ces deux tableaux est une colonne d'identité unique générée automatiquement. La colonneIsProcesseddu tableau ItemInfo sera utilisée pour identifier et supprimer les enregistrements qui ne sont plus valides. -
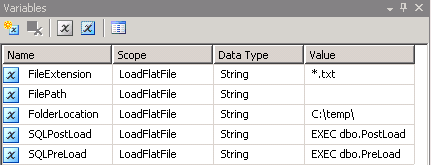
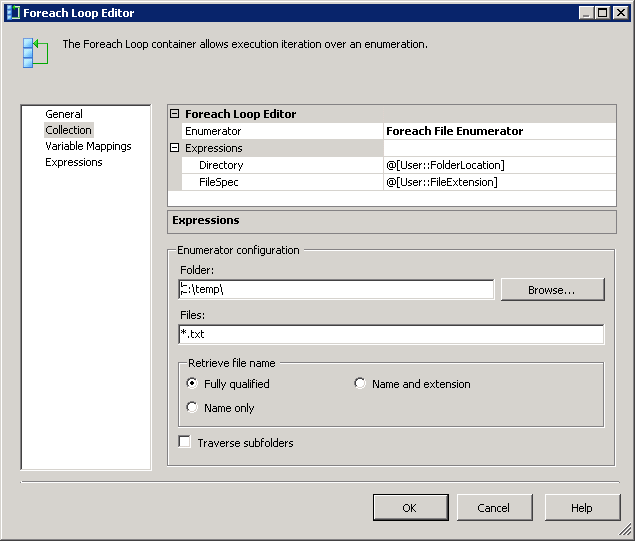
créez un paquet SSIS et créez 5 variables comme montré dans la capture d'écran # 2 . J'ai utilisé
.txtextension pour l'onglet fichiers délimités et donc la valeur*.txtdans la variable extension de fichier . La variableFilePathsera assignée avec une valeur pendant l'exécution. La variableFolderLocationindique que la les fichiers seront localisés. Les variablesSQLPostLoadetSQLPreLoadindiquent les procédures stockées utilisées pendant les opérations avant et après la charge. Les Scripts pour ces procédures stockées sont fournis dans la section Scripts . -
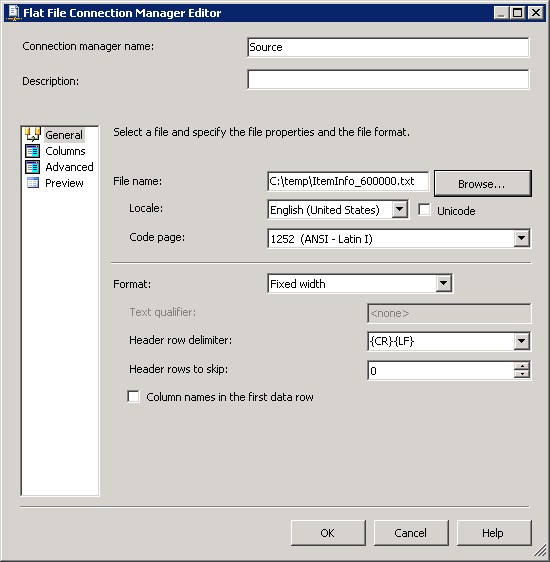
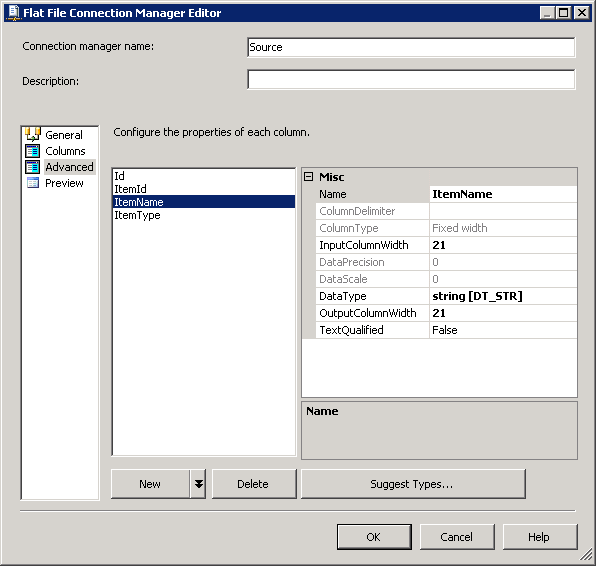
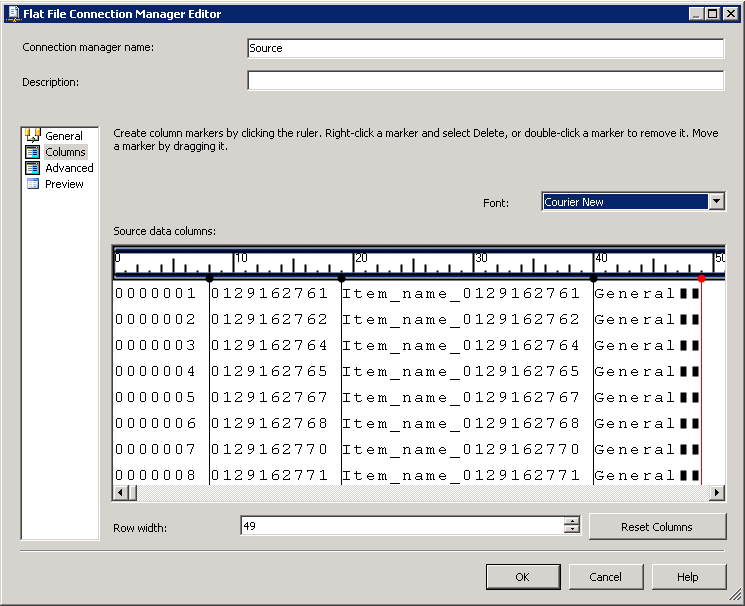
créer une connexion OLE DB pointant vers la base de données du serveur SQL. Créez une connexion de fichier à plat comme indiqué dans les captures d'écran # 3 et # 4 . de connexions de Fichiers Plats Colonnes section contient des de la colonne au niveau de l'information. La capture d'écran # 5 montre l'aperçu des données des colonnes.
-
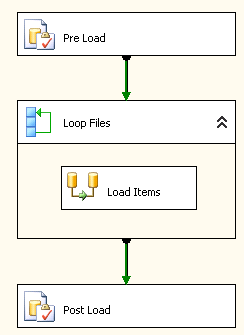
configurer la tâche de flux de contrôle comme montré dans la capture d'écran # 6 . Configurer les tâches
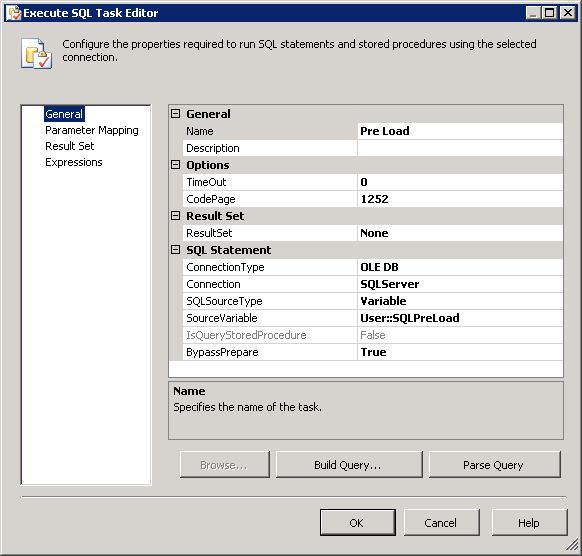
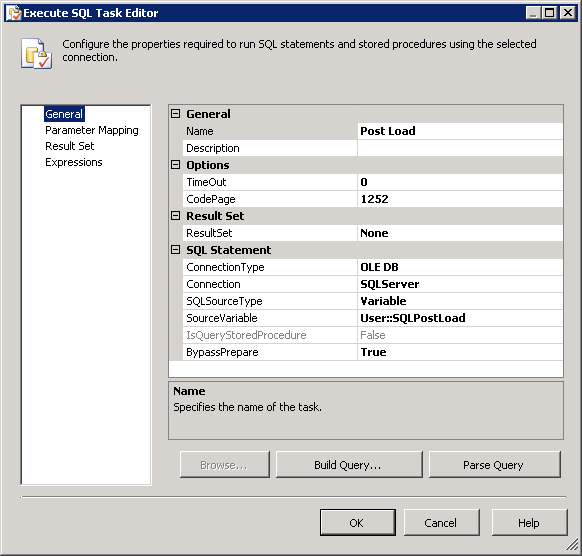
Pre Load,Post LoadetLoop Filescomme indiqué dans les captures d'écran # 7 - # 10 . Pré Charge tronquer table de staging et mettre le drapeauIsProcessedà false pour toutes les lignes de la table Itemfo. Post Load mettra à jour les modifications et supprimera les lignes dans la base de données qui ne se trouvent pas dans le fichier. Référez-vous aux procédures stockées utilisées dans ces tâches pour comprendre ce qui est fait dans ces tâchesExecute SQL. -
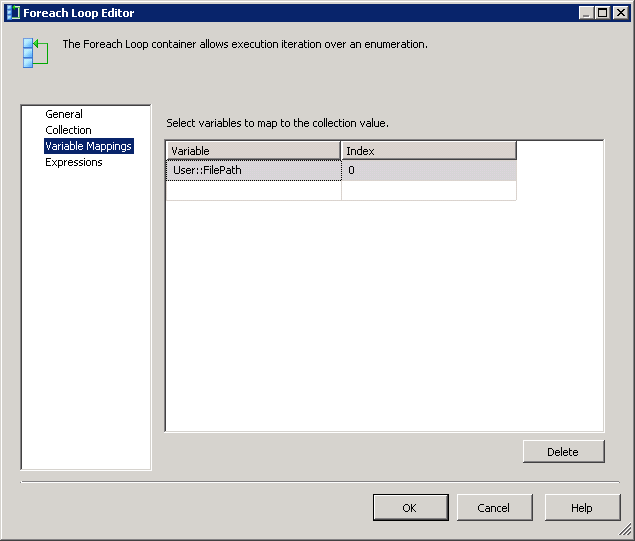
double-cliquez sur la tâche de flux de données des éléments de charge et configurez-la comme indiqué dans la capture d'écran # 11 .
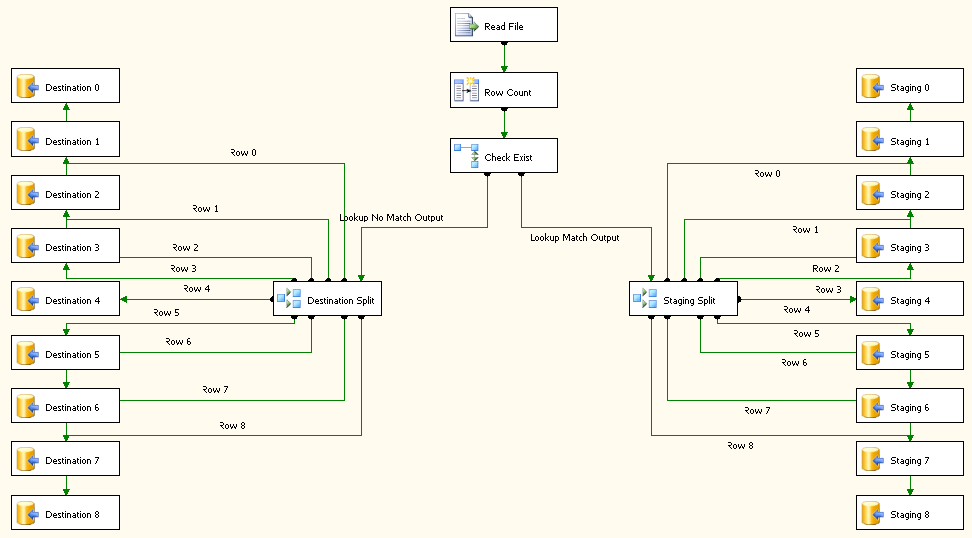
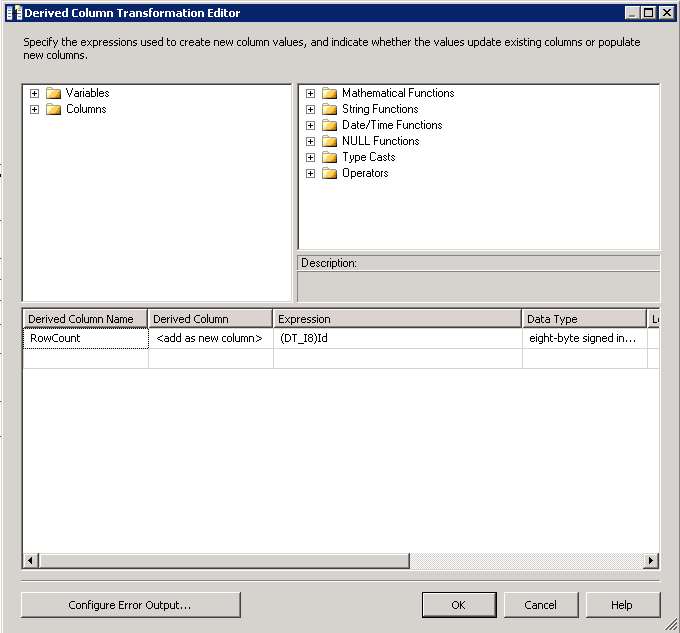
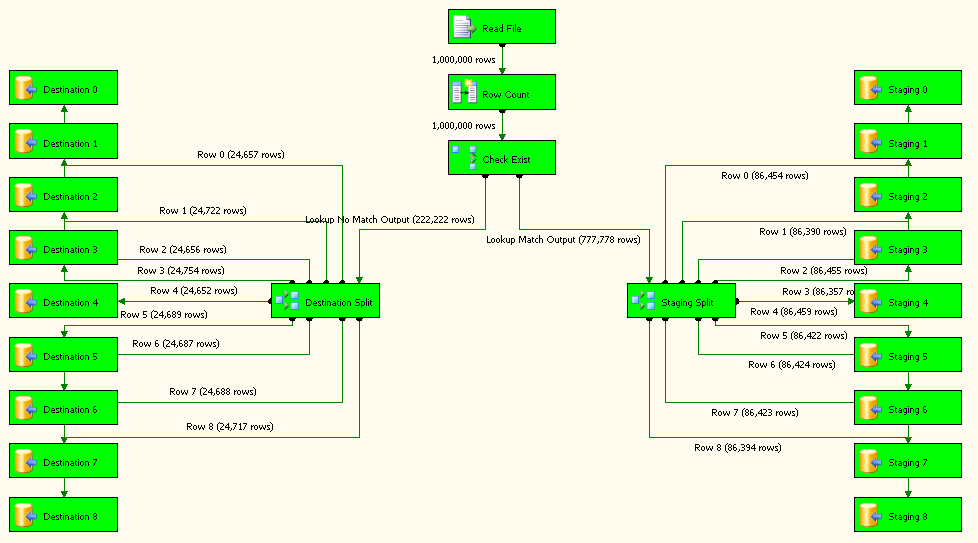
Read Fileest un fichier plat source configuré pour utiliser la connexion de fichier plat.Row Countest la transformation de colonne dérivée et sa configuration est montrée dans la capture d'écran # 12 .Check Existest une transformation de recherche et ses configurations sont affichées en screenshots # 13 - # 15 . recherche Pas de sortie de correspondance est redirigé versDestination Splitsur le côté gauche. sortie de correspondance de recherche est redirigéStaging Splitsur le côté gauche.Destination SplitetStaging Splitont la même configuration que sur la capture d'écran # 16 . La raison de 9 destinations différentes pour la destination et la table d'étape est d'améliorer la performance du paquet. -
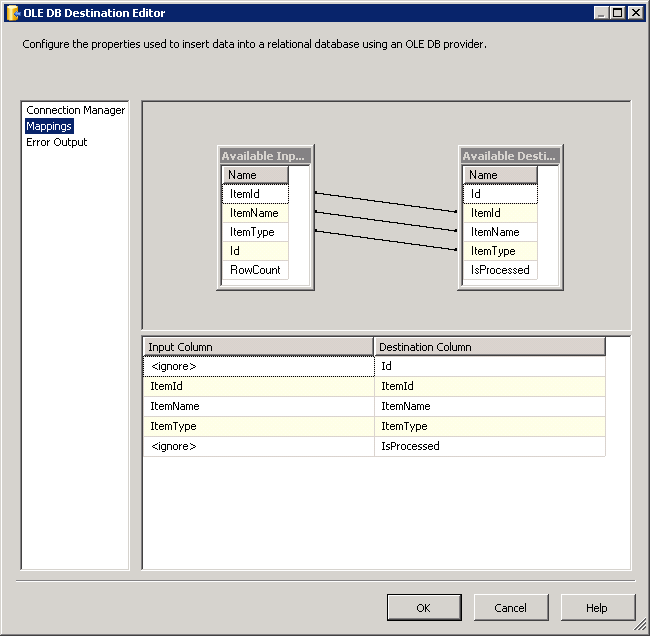
toutes les tâches de destination 0 - 8 sont configurées pour insérer des données dans le tableau
dbo.ItemInfocomme le montre la capture d'écran # 17 . Tous les les tâches de mise en scène 0-8 sont configurées pour insérer des données dansdbo.Stagingcomme le montre la capture d'écran # 18 . -
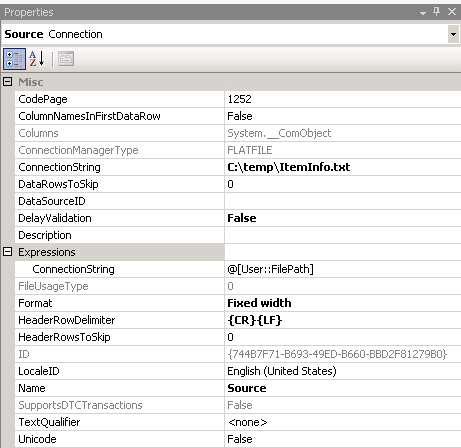
sur le Flat File connection manager, définissez la propriété ConnectionString pour utiliser la variable FilePath comme indiqué sur la capture d'écran # 19 . Cela permettra au paquet d'utiliser la valeur définie dans la variable en boucle à travers chaque fichier d'un dossier.
scénarios D'essai:
Test results may vary from machine to machine.
In this scenario, file was located locally on the machine.
Files on network might perform slower.
This is provided just to give you an idea.
So, please take these results with grain of salt.
-
a été exécuté sur une machine 64 bits avec Xeon single core CPU 2,5 GHz et 3,00 Go RAM.
-
charge un fichier plat avec
1 million rows. Paquet exécuté dans environ 2 minutes 47 secondes . Consultez les captures d'écran # 20 et # 21 . -
a utilisé les requêtes fournies dans la section test queries pour modifier les données afin de simuler la mise à jour, la suppression et la création de nouveaux enregistrements lors de la seconde exécution du paquet.
-
a chargé le même fichier contenant le
1 million rowsaprès l'exécution des requêtes suivantes dans la base de données. Paquet exécuté dans environ 1 min 35 secondes . Consulter les captures d'écran # 22 et # 23 . Veuillez noter le nombre de lignes redirigées vers la table de destination et de staging dans la capture d'écran # 22 .
Espère que ça aide.
des requêtes de Test: .
--These records will be deleted during next run
--because item ids won't match with file data.
--(111111 row(s) affected)
UPDATE dbo.ItemInfo SET ItemId = 'DEL_' + ItemId WHERE Id % 9 IN (3)
--These records will be modified to their original item type of 'General'
--because that is the data present in the file.
--(222222 row(s) affected)
UPDATE dbo.ItemInfo SET ItemType = 'Testing' + ItemId WHERE Id % 9 IN (2,6)
--These records will be reloaded into the table from the file.
--(111111 row(s) affected)
DELETE FROM dbo.ItemInfo WHERE Id % 9 IN (5,9)
De Connexions De Fichiers Plats Colonnes .
Name InputColumnWidth DataType OutputColumnWidth
---------- ---------------- --------------- -----------------
Id 8 string [DT_STR] 8
ItemId 11 string [DT_STR] 11
ItemName 21 string [DT_STR] 21
ItemType 9 string [DT_STR] 9
Scripts: (pour créer à la fois des tables et des procédures stockées) .
CREATE TABLE [dbo].[ItemInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
[IsProcessed] [bit] NULL,
CONSTRAINT [PK_ItemInfo] PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UK_ItemInfo_ItemId] UNIQUE NONCLUSTERED ([ItemId] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Staging](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
CONSTRAINT [PK_Staging] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE PROCEDURE [dbo].[PostLoad]
AS
BEGIN
SET NOCOUNT ON;
UPDATE ITM
SET ITM.ItemName = STG.ItemName
, ITM.ItemType = STG.ItemType
, ITM.IsProcessed = 1
FROM dbo.ItemInfo ITM
INNER JOIN dbo.Staging STG
ON ITM.ItemId = STG.ItemId;
DELETE FROM dbo.ItemInfo
WHERE IsProcessed = 0;
END
GO
CREATE PROCEDURE [dbo].[PreLoad]
AS
BEGIN
SET NOCOUNT ON;
TRUNCATE TABLE dbo.Staging;
UPDATE dbo.ItemInfo
SET IsProcessed = 0;
END
GO
Capture d'écran #1:
Capture d'écran #2:
Capture d'écran #3:
Capture d'écran #4:
Capture d'écran #5:
Capture d'écran #6:
Capture d'écran #7:
Capture d'écran n ° 8:
Capture d'écran n ° 9:
Capture d'écran n ° 10:
Capture d'écran #11:
Capture d'écran n ° 12:
Capture d'écran n ° 13:
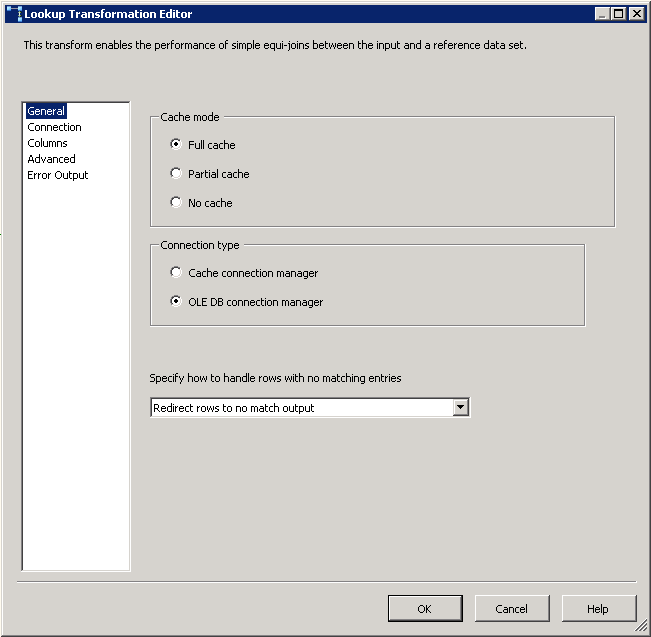
Capture d'écran #14:
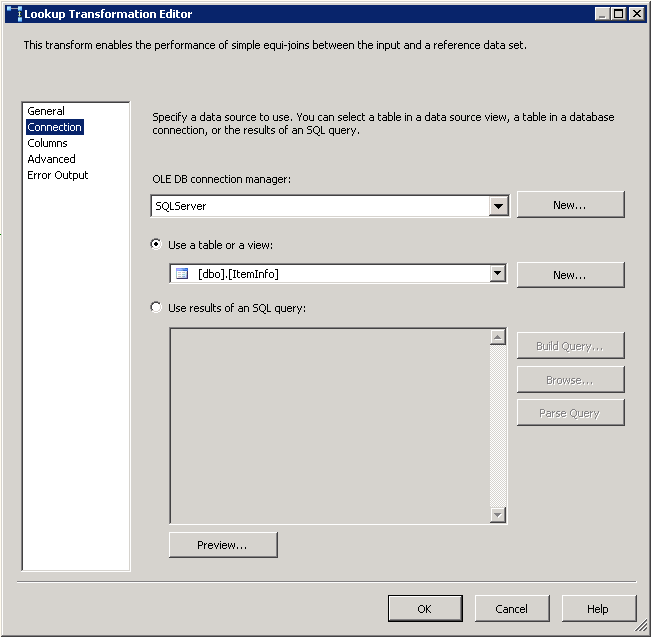
Capture d'écran n ° 15:
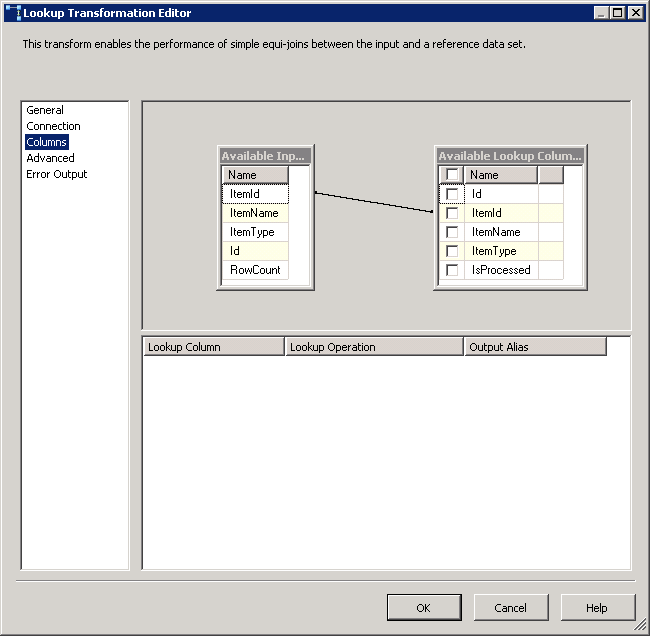
Capture d'écran #16:
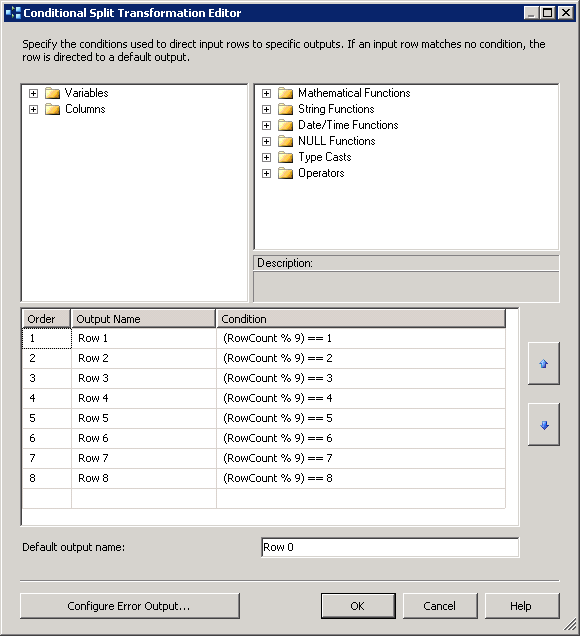
Capture d'écran #17:
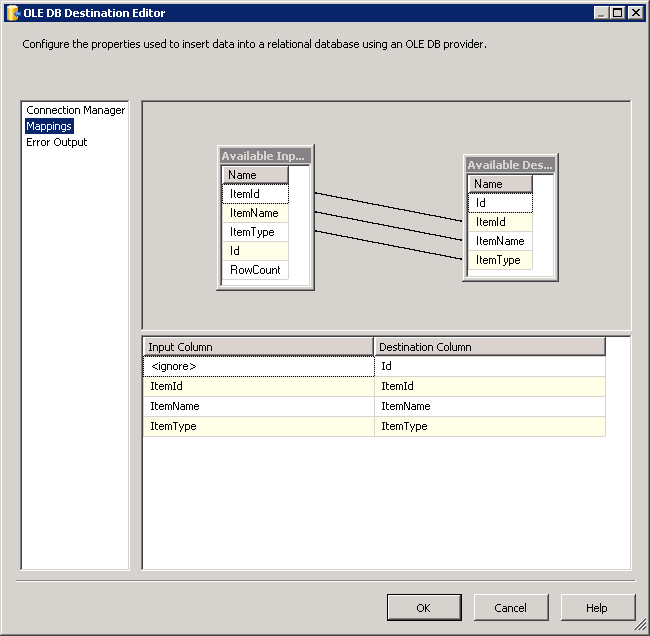
Capture d'écran #18:
Capture d'écran #19:
Capture d'écran n ° 20:
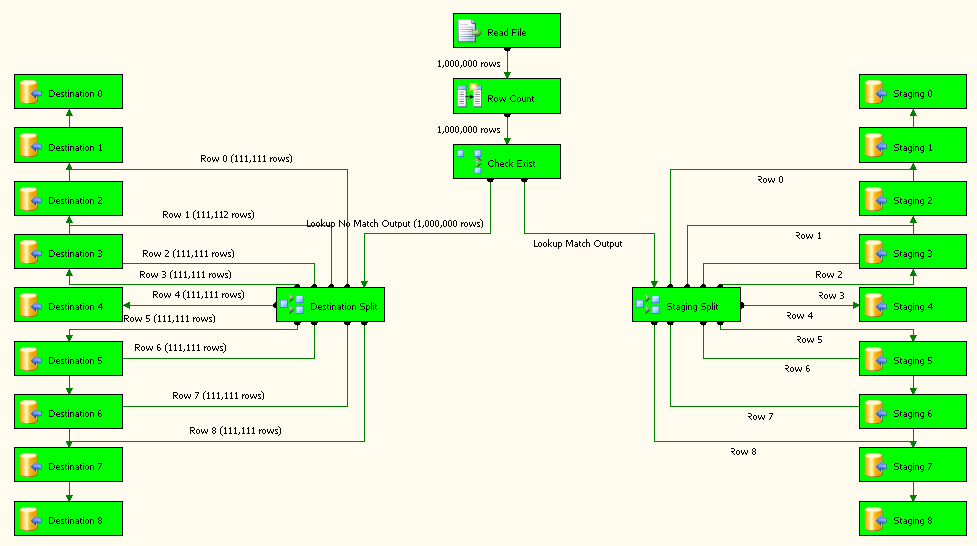
Capture d'écran n ° 21:
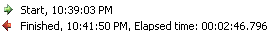
Capture d'écran #22:
Capture d'écran #23:
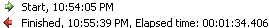
en supposant que vous utilisez SQL Agent (ou un scheduler similaire)
Reqs 1/4) j'aurais une étape précurseur pour gérer les étapes FTP et/ou copie de fichier. Je n'aime pas encombrer mes paquets de manipulation de fichiers si je peux l'éviter.
Reqs 2/3) au niveau du flux de contrôle, la conception du paquet va ressembler à une tâche SQL exécutée connectée à un flux de données connecté à une autre tâche SQL exécutée. Comme @AllenG l'a indiqué, vous seriez mieux servi par chargement dans une table de staging via la tâche de flux de données. La première tâche SQL exécutera purgera toutes les lignes de la table de staging (tronquer la TABLE dbo.DAILY_STAGE)
le design approximatif de la table ressemble à ceci. La table MICHAEL_BORN est votre table existante et la page DAILY_STAGE est l'endroit où votre flux de données atterrira.
CREATE TABLE DBO.MICHAEL_BORN
(
ID int identity(1,1) NOT NULL PRIMARY KEY CLUSTERED
, ItemID int NOT NULL
, ItemName varchar(20) NOT NULL
, ItemType varchar(20) NOT NULL
)
CREATE TABLE dbo.DAILY_STAGE
(
ItemID int NOT NULL PRIMARY KEY CLUSTERED
, ItemName varchar(20) NOT NULL
, ItemType varchar(20) NOT NULL
)
à des fins de démonstration, je vais charger les tableaux ci-dessus avec des données d'échantillon Via TSQL
-- Original data
INSERT INTO
dbo.MICHAEL_BORN
VALUES
(2345,'Apple','Fruit')
, (4578, 'Bannana','Fruit')
-- Daily load runs
-- Adds a new fruit (pear), corrects misspelling of banana, eliminates apple
INSERT INTO
dbo.DAILY_STAGE
VALUES
(7721,'Pear','Fruit')
, (4578, 'Banana','Fruit')
le Exécuter la tâche SQL profitera de la déclaration MERGE disponible en 2008+ Éditions de SQL Server. Veuillez noter que le point-virgule arrière fait partie de la déclaration de fusion. Le défaut d'inclure il en résultera une erreur de "UNE instruction MERGE doit être terminée par un point-virgule (;)."
-- MERGE statement
-- http://technet.microsoft.com/en-us/library/bb510625.aspx
-- Given the above scenario, this script will
-- 1) Update the matched (4578 bannana/banana) row
-- 2) Add the new (pear) row
-- 3) Remove the unmatched (apple) row
MERGE
dbo.[MICHAEL_BORN] AS T
USING
(
SELECT
ItemID
, ItemName
, ItemType
FROM
dbo.DAILY_STAGE
) AS S
ON T.ItemID = S.ItemID
WHEN
MATCHED THEN
UPDATE
SET
T.ItemName = S.ItemName
, T.ItemType = S.ItemType
WHEN
NOT MATCHED THEN
INSERT
(
ItemID
, ItemName
, ItemType
)
VALUES
(
ItemID
, ItemName
, ItemType
)
WHEN
NOT MATCHED BY SOURCE THEN
DELETE
;
Req 5) L'efficacité est totalement basée sur vos données et la largeur de vos lignes sont mais cela ne devrait pas être terrible.
-- Performance testing
-- Assumes you have a similar fast row number generator function
-- http://billfellows.blogspot.com/2009/11/fast-number-generator.html
TRUNCATE TABLE dbo.MICHAEL_BORN
TRUNCATE TABLE dbo.DAILY_STAGE
-- load initial rows
-- 20ish seconds
INSERT INTO
dbo.MICHAEL_BORN
SELECT
N.number AS ItemID
, 'Spam & eggs ' + CAST(N.number AS varchar(10)) AS ItemName
, 'SPAM' AS ItemType
--, CASE N.number % 2 WHEN 0 THEN N.number + 1000000 ELSE N.number END AS UpTheEvens
FROM
dbo.GenerateNumbers(1000000) N
-- Load staging table
-- Odds get item type switched out
-- Evens get delete and new ones created
-- 20ish seconds
INSERT INTO
dbo.DAILY_STAGE
SELECT
CASE N.number % 2 WHEN 0 THEN N.number + 1000000 ELSE N.number END AS ItemID
, 'Spam & eggs ' + CAST(N.number AS varchar(10)) AS ItemName
, CASE N.number % 2 WHEN 0 THEN 'SPAM' ELSE 'Not much spam' END AS ItemType
FROM
dbo.GenerateNumbers(1000000) N
-- Run MERGE statement, 32 seconds 1.5M rows upserted
-- Probably fast enough for you
je veux juste donner mon idée pour le prochain gars qui peut passer par cette question. Donc je vais suggérer mon idée pour chaque scénario.
1. Getfile de FTP ou local.
Je vous suggérerais d'utiliser Drop box, Google Drive ou tout autre service cloud de synchronisation de fichiers de votre choix.voir ce lien pour plus de détails.
2. Je suggère de charger toutes les données du fichier plat dans la table de staging comme vous l'avez suggéré Ensuite, comparer les données serait facilement fait en utilisant la fusion entre votre table de staging et la table de cible sur votre colonne unique (ID). Vous pouvez voir ce lien pour savoir comment utiliser le script de fusion. Les scénarios 2 et 3 seront résolus si vous utilisez le Script de fusion.
Pour les deux derniers scénarios, je vous suggère D'utiliser SQL JOB pour exécuter automatiquement le paquet et le programmer aux heures creuses ou à l'heure où le serveur n'est pas occupé.Veuillez prendre un coup d'oeil sur le lien pour détail sur la façon d'exécuter un paquet en utilisant un travail D'Agent de serveur SQL il suffit de le taper sur votre moteur de recherche préféré et vous trouverez des tonnes de blogs qui montre comment son fait.
SSIS sonne comme la voie à suivre. La façon dont j'ai vu votre type de problème traité précédemment est avec une table de mise en scène. Le nouveau document se charge dans la table de Staging - puis la Staging et la Production sont comparées - les enregistrements obsolètes sont archivés (pas seulement supprimés) de la Production, les lignes existantes avec quelques modifications sont mises à jour (encore une fois, les données originales archivées quelque part), et de nouvelles lignes sont insérées.
Note: votre définition de" obsolète " doit être très, très précise. Pour exemple: est-ce que quelque chose devrait être archivé parce qu'une ligne correspondante n'existe pas dans votre fichier le plus récent? Devrait-il rester pour X période de temps dans le cas où il vient sur un dossier ultérieur? Ces questions et d'autres devraient être considérés.
presque n'importe quel tutoriel standard de SSIS devrait vous indiquer la bonne voie pour faire chacune de ces étapes.
je donnerais une chance à Merge. Assurez-vous que vous avez éventuellement des index sur ItemID sur les deux tables.
Merge [dbo].[ItemInfo] as target
using
(
SELECT stg.ItemID, stg.ItemName, stg.ItemType
FROM [dbo].[ItemInfo_Staging] stg
LEFT OUTER JOIN [dbo].[ItemInfo] final
on stg.ItemId = final.ItemId
) as SOURCE
ON SOURCE.ItemID = target.ItemID
WHEN MATCHED THEN
Update SET
target.ItemID = SOURCE.ItemID
, target.ItemName = SOURCE.ItemName
, target.ItemType = SOURCE.ItemType
WHEN NOT MATCHED BY TARGET THEN
INSERT (ItemID, ItemName, ItemType )
VALUES (SOURCE.ItemID, SOURCE.ItemName, SOURCE.ItemType )
WHEN NOT MATCHED BY SOURCE THEN
DELETE
;