La compréhension de "l'aléatoire"
Je ne peux pas avoir ma tête autour de ça, qui est plus aléatoire?
rand()
ou
rand() * rand()
Im trouver un véritable casse-tête, pourriez-vous m'aider?
EDIT:
intuitivement je sais que la réponse mathématique sera qu'ils sont également aléatoires, mais je ne peux pas m'empêcher de penser que si vous "Exécuter l'algorithme de nombre aléatoire" deux fois lorsque vous multipliez les deux ensemble, vous créerez quelque chose de plus aléatoire qu'une fois.
28 réponses
une clarification
bien que les réponses précédentes soient exactes chaque fois que vous essayez de repérer le caractère aléatoire d'une variable pseudo-aléatoire ou sa multiplication, vous devez être conscient que tandis que Random () est généralement distribué uniformément, Random() * Random () n'est pas.
exemple
il s'agit d'un échantillon de distribution aléatoire uniforme simulé par une variable pseudo-aléatoire:
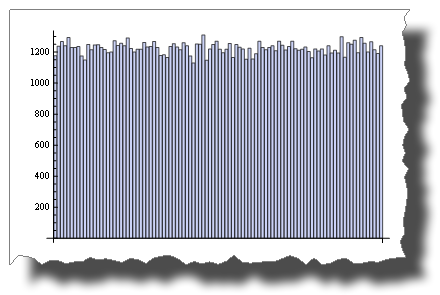
BarChart[BinCounts[RandomReal[{0, 1}, 50000], 0.01]]
alors que c'est la distribution que vous obtenez après avoir multiplié deux variables aléatoires:
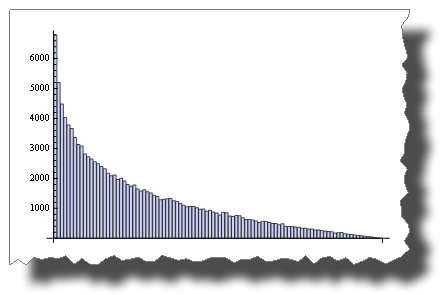
BarChart[BinCounts[Table[RandomReal[{0, 1}, 50000] *
RandomReal[{0, 1}, 50000], {50000}], 0.01]]
donc, les deux sont "aléatoires", mais leur distribution est très différente.
autre exemple
alors que 2 * Random () est répartition uniforme:
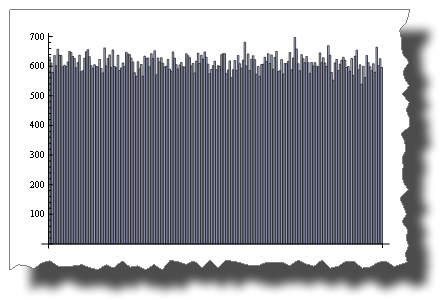
BarChart[BinCounts[2 * RandomReal[{0, 1}, 50000], 0.01]]
Random() + Random() ne l'est pas!
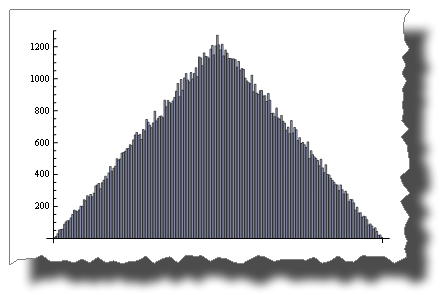
BarChart[BinCounts[Table[RandomReal[{0, 1}, 50000] +
RandomReal[{0, 1}, 50000], {50000}], 0.01]]
Le Théorème De La Limite Centrale
le théorème de la limite centrale indique que la somme de aléatoire () tend à un normal distribution comme les Termes augmentent.
avec seulement quatre termes vous obtenez:
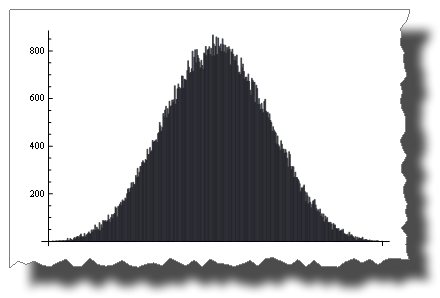
BarChart[BinCounts[Table[RandomReal[{0, 1}, 50000] + RandomReal[{0, 1}, 50000] +
Table[RandomReal[{0, 1}, 50000] + RandomReal[{0, 1}, 50000],
{50000}],
0.01]]
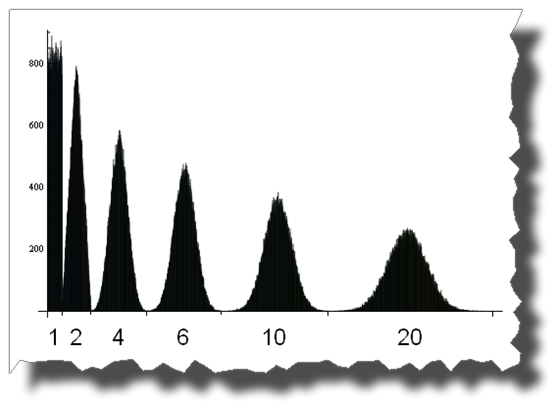
et ici vous pouvez voir la route d'une distribution uniforme à une distribution normale en additionnant 1, 2, 4, 6, 10 et 20 variables aléatoires uniformément réparties:
Modifier
quelques crédits
merci à Thomas Ahle pour avoir souligné dans les commentaires que les distributions de probabilité montrées dans les deux dernières images sont connues sous le nom de Irwin-Hall distribution
Grâce à Heike pour son merveilleux déchiré[] la fonction
je suppose que les deux méthodes sont aussi aléatoires bien que mon gutfeel dirait que rand() * rand() est moins aléatoire parce qu'il semerait plus de zéros. Dès qu'un rand() est 0 , le total devient 0
n'est " plus aléatoire.
rand() génère un ensemble prévisible de nombres basés sur une pseudo-aléatoire (généralement basée sur l'heure actuelle, qui est toujours en évolution). La multiplication de deux nombres consécutifs dans la séquence génère une séquence de nombres différente, mais également prévisible.
pour ce qui est de savoir si cela réduira les collisions, la réponse est non. Il va en fait augmenter les collisions dues à l'effet de multiplication deux numéros où 0 < n < 1 . Le résultat sera une plus petite fraction, provoquant un biais dans le résultat vers l'extrémité inférieure du spectre.
Quelques explications supplémentaires. Dans ce qui suit, "imprévisible" et "aléatoire" se réfère à la capacité de quelqu'un de deviner ce que le prochain nombre sera basé sur les nombres précédents, c.-à-d.. Oracle.
semence donnée x générant la liste de valeurs suivante:
0.3, 0.6, 0.2, 0.4, 0.8, 0.1, 0.7, 0.3, ...
rand() générera la liste ci-dessus, et rand() * rand() générera:
0.18, 0.08, 0.08, 0.21, ...
les deux méthodes produiront toujours la même Liste de nombres pour la même graine, et sont donc également prévisibles par un oracle. Mais si vous regardez les résultats pour multiplier les deux appels, vous verrez qu'ils sont tous sous 0.3 malgré une distribution décente dans la séquence originale. Les nombres sont biaisés à cause de l'effet de la multiplication de deux fractions. Le résultant le nombre est toujours plus petit, donc beaucoup plus susceptible d'être une collision malgré être tout aussi imprévisible.
simplification excessive pour illustrer un point.
suppose que votre fonction aléatoire ne produit que 0 ou 1 .
random() est l'un de (0,1) , mais random()*random() est l'un de (0,0,0,1)
vous pouvez clairement voir que les chances d'obtenir un 0 dans le deuxième cas ne sont en aucune façon égaux à ceux d'obtenir un 1 .
lorsque j'ai publié cette réponse pour la première fois , j'ai voulu la garder aussi courte que possible afin qu'une personne qui la lit comprenne d'un coup d'oeil la différence entre random() et random()*random() , mais je ne peux pas me retenir de répondre à la question originale ad litteram:
Qu'est-ce qui est plus aléatoire?
étant que random() , random()*random() , random()+random() , (random()+1)/2 ou toute autre combinaison qui ne conduit pas à un résultat fixe ont la même source d'entropie (ou le même état initial dans le cas des générateurs de pseudorandom), la réponse serait qu'ils sont également aléatoire (la différence est dans leur distribution). Un exemple parfait que nous pouvons regarder est le jeu de Craps. Le nombre que vous obtenez serait random(1,6)+random(1,6) et nous savons tous que l'obtention de 7 a la plus grande chance, mais cela ne signifie pas le résultat de rouler deux dés est plus ou moins aléatoire que le résultat de roulement.
Voici une réponse simple. Envisager De Monopole. Vous lancez deux dés à six faces (ou 2d6 pour ceux d'entre vous qui préfèrent la notation de jeu) et prenez leur somme. Le résultat le plus commun est 7 parce qu'il y a 6 façons possibles de rouler un 7 (1,6 2,5 3,4 4,3 5,2 et 6,1). Alors qu'un 2 ne peut être roulé que sur 1,1. Il est facile de voir que le rolling 2d6 est différent du rolling 1d12, même si la gamme est la même (en ignorant que vous pouvez obtenir un 1 sur un 1d12, le point reste le même). Multipliant votre résultats au lieu de les ajouter va les fausser d'une manière similaire, avec la plupart de vos résultats à venir dans le milieu de la gamme. Si vous essayez de réduire les valeurs aberrantes, c'est une bonne méthode, mais cela n'aidera pas à faire une distribution uniforme.
(et assez curieusement il augmentera des rouleaux bas aussi bien. En supposant que votre aléatoire commence à 0, Vous verrez un pic à 0 parce qu'il transformera ce que l'autre rouleau est en 0. Considérons deux nombres aléatoires entre 0 et 1 (inclus) et de multiplier. Si le résultat est 0, le tout devient un 0 aucun autre résultat. La seule façon d'obtenir un 1 de il est pour les deux rouleaux à 1. En pratique, cela n'aurait probablement pas d'importance, mais cela fait un graphique bizarre.)

il pourrait être utile d'y penser en chiffres plus discrets. Considérez voulez générer des nombres aléatoires entre 1 et 36, donc vous décidez que la manière la plus facile est de lancer deux dé justes, 6 côtés. Vous obtenez ceci:
1 2 3 4 5 6
-----------------------------
1| 1 2 3 4 5 6
2| 2 4 6 8 10 12
3| 3 6 9 12 15 18
4| 4 8 12 16 20 24
5| 5 10 15 20 25 30
6| 6 12 18 24 30 36
nous avons donc 36 nombres, mais tous ne sont pas équitablement représentés, et certains ne se produisent pas du tout. Les nombres près de la diagonale centrale (coin inférieur gauche au coin supérieur droit) se produiront avec la fréquence la plus élevée.
le même les principes qui décrivent la distribution injuste entre les dés s'appliquent également aux nombres à virgule flottante entre 0.0 et 1.0.
certaines choses au sujet de" l'aléatoire " sont contre-intuitives.
en supposant une distribution plane de rand() , vous obtiendrez les distributions non planes suivantes:
- des biais importants:
sqrt(rand(range^2)) - biais de pointe dans le milieu:
(rand(range) + rand(range))/2 - faible:biais:
range - sqrt(rand(range^2))
il existe de nombreuses autres façons de créer des courbes de biais spécifiques. J'ai fait une rapide test de rand() * rand() et il vous obtient une distribution très non linéaire.
"aléatoire" et "random" est un peu comme demander à qui le Zéro plus zéro des goujons.
dans ce cas, rand est un PRNG, donc pas totalement aléatoire. (en fait, tout à fait prévisible si la graine est connu). En le multipliant par une autre valeur, il n'est ni plus ni moins aléatoire.
un vrai RNG crypto-type sera en fait aléatoire. Et courir des valeurs à travers n'importe quelle sorte de fonction ne peut pas ajouter plus d'entropie à elle, et peut très probablement supprimer entropie, il n'a pas été plus aléatoire.
la plupart des implémentations de rand() ont une certaine période. I. e. après un certain nombre énorme d'appels de la séquence se répète. La séquence des sorties de rand() * rand() se répète en deux fois moins de temps, il est donc "moins aléatoire" dans ce sens.
aussi, sans construction soigneuse, l'exécution arithmétique sur les valeurs aléatoires tend à causer moins d'aléatoire. Une affiche citée ci-dessus " rand() + rand() + rand() ..."(K fois, say) qui aura en fait tendance à K fois la moyenne valeur de la plage de valeurs rand() retourne. (C'est une marche aléatoire avec des mesures symétriques par rapport à cette moyenne.)
suppose de façon concrète que votre fonction rand() renvoie un nombre réel aléatoire uniformément distribué dans la gamme [0,1]. (Oui, cet exemple permet une précision infinie. Cela ne changera pas le résultat.) Vous n'avez pas choisi une langue particulière et différentes langues peuvent faire des choses différentes, mais l'analyse suivante tient avec des modifications pour toute mise en œuvre non perverse de rand(). Le produit rand() * rand() est également dans la gamme [0,1] mais n'est plus distribué uniformément. En fait, le produit est plus susceptibles d'être dans l'intervalle [0,1/4) dans l'intervalle [1/4,1). Plus de multiplication, le résultat sera encore plus proche de zéro. Cela rend le résultat plus prévisible. Dans les grandes lignes, plus prévisible = = moins aléatoire.
à peu près n'importe quelle séquence d'opérations sur l'entrée aléatoire uniforme sera aléatoire non uniforme, conduisant à une prévisibilité accrue. Avec soin, on peut surmonter cette propriété, mais il aurait été plus facile de générer un chiffre aléatoire uniformément distribué dans la gamme que vous vouliez plutôt que de perdre du temps avec l'arithmétique.
le concept que vous recherchez est "entropie", le "degré" de désordre d'une chaîne de bits. L'idée est la plus facile à comprendre en termes de concept d ' "entropie maximale".
une définition approximative d'une chaîne de bits avec entropie maximale est qu'elle ne peut pas être exprimée exactement en termes d'une chaîne plus courte de bits (c.-à-d. utiliser un algorithme pour développez la plus petite chaîne à la chaîne d'origine).
la pertinence du maximum l'entropie au hasard découle du fait que si vous choisissez un nombre "aléatoire", vous aurez presque certainement choisir un nombre dont la chaîne de bits est proche de l'entropie maximale, c'est-à-dire qu'elle ne peut pas être compressée. C'est notre meilleure compréhension de ce qui caractérise un "hasard" le nombre.
Donc, si vous voulez faire un nombre aléatoire de deux échantillons aléatoires qui est "deux fois" plus au hasard, vous concaténez les deux chaînes de bits ensemble. Pratiquement, vous feriez juste empiler les échantillons dans les moitiés hautes et basses d'un mot de double longueur.
sur une note plus pratique, si vous vous retrouvez avec un rand pourri(), il peut parfois, à xor un couple d'échantillons --- bien que, si ses vraiment brisé même cette procédure ne va pas aider.
la réponse acceptée est très jolie, mais il y a une autre façon de répondre à votre question. Pachydermpuncher's answer prend déjà cette approche alternative, et je vais juste l'étendre un peu.
la façon la plus facile de penser la théorie de l'information est en termes de la plus petite unité d'information, un seul morceau.
dans la bibliothèque standard C, rand() renvoie un entier dans l'intervalle 0 à RAND_MAX , une limite qui peut être définie différemment selon la plate-forme. Supposons que RAND_MAX se trouve être défini comme 2^n - 1 où n est un entier (ce qui se trouve être le cas dans L'implémentation de Microsoft, où n est 15). Ensuite, nous dirions qu'une bonne mise en œuvre retournerait n bits d'information.
Imagine que rand() construit des nombres aléatoires en retournant une pièce pour trouver la valeur d'un bit, et puis répéter jusqu'à ce qu'il dispose d'un lot de 15 bits. Les bits sont alors indépendants (la valeur d'un bit n'influence pas la probabilité que d'autres bits du même lot aient une certaine valeur). Donc, chaque bit considéré indépendamment est comme un nombre aléatoire entre 0 et 1 inclusivement, et est" également distribué " dans cette fourchette (aussi susceptible d'être 0 comme 1).
l'indépendance des bits assure que les nombres représentés par les lots de bits seront également répartis uniformément sur leur gamme. C'est intuitivement évident: s'il y a 15 bits, la plage autorisée est zéro à 2^15 - 1 = 32767. Chaque nombre dans cette gamme est un modèle unique de bits, tels que:
010110101110010
et si les bits sont indépendants, alors aucun motif n'est plus susceptible de se produire que tout autre motif. Donc tous les nombres possibles dans la gamme sont également probables. Et donc l'inverse est vrai: si rand() produit des entiers uniformément répartis, alors ces nombres sont faits de bits indépendant.
pensez donc à rand() comme une ligne de production pour la fabrication de bits, qui se trouve juste à les servir dans des lots de taille arbitraire. Si vous n'aimez pas la taille, cassez les lots vers le haut en bits individuels, puis remettez-les ensemble dans les quantités que vous aimez (bien que si vous avez besoin d'une gamme particulière qui n'est pas une puissance de 2, vous devez rétrécir vos nombres, et de loin la manière la plus facile de le faire est de convertir en point flottant).
pour revenir à votre suggestion originale, supposez que vous voulez passer de lots de 15 à lots de 30, demandez rand() pour le premier nombre, bit-shift de 15 places, puis Ajouter un autre rand() à elle. C'est une façon de combiner deux appels à rand() sans perturber une distribution uniforme. Cela fonctionne simplement parce qu'il n'y a pas de chevauchement entre les endroits où vous placez les bits d'information.
C'est très différent de "stretching" la gamme de rand() en multipliant par une constante. Par exemple, si vous voulez doubler la gamme de rand() vous pouvez multiplier par deux - mais maintenant vous n'obtiendrez que des nombres pairs, et jamais des nombres impairs! Ce n'est pas exactement une distribution en douceur et pourrait être un problème sérieux en fonction de l'application, par exemple un jeu de roulette permettant des paris impairs/pairs. (En pensant en termes de bits, vous éviteriez cette erreur intuitivement, parce que vous réaliseriez que multiplier par deux est la même chose que déplacer les bits vers la gauche (plus grande signification) par un endroit et combler le vide avec zéro. Alors, évidemment, la quantité d'information est le même - c'est un peu déplacé.)
de tels écarts dans les intervalles de nombres ne peuvent pas être critiqués dans les applications de nombres à virgule flottante, parce que les intervalles de nombres à virgule flottante ont intrinsèquement des écarts en eux qui ne peuvent tout simplement pas être représentés du tout: un infini nombre de nombres réels manquants existent dans l'intervalle entre chaque deux nombres représentables à virgule flottante! Donc nous devons juste apprendre à vivre avec des trous de toute façon.
comme d'autres l'ont prévenu, l'intuition est risquée dans ce domaine, en particulier parce que les mathématiciens ne peuvent pas résister à l'attrait des nombres réels, qui sont horriblement confus choses pleines d'infinies et de paradoxes apparents.
mais au moins si vous pensez qu'il s'agit de bits, votre intuition pourrait vous obtenir un peu plus loin. Les Bits sont vraiment faciles - même ordinateurs peut les comprendre.
comme d'autres l'ont dit, la réponse facile et brève est: non, ce n'est pas plus aléatoire, mais cela change la distribution.
supposez que vous jouiez aux dés. Vous avez certains tout à fait juste, au hasard des dés. Serait le dé roule être "aléatoire" si avant chaque jet de dé, vous mettez d'abord deux dés dans un bol, secoua autour de, choisi l'un des dés au hasard, et ensuite roulé? De toute évidence, elle ne ferait aucune différence. Si les deux dés donnent nombres aléatoires, puis au hasard choisir l'un des deux dés ne fera aucune différence. De toute façon, vous obtiendrez un nombre aléatoire entre 1 et 6 avec une distribution uniforme sur un nombre suffisant de rouleaux.
je suppose que dans la vie réelle une telle procédure pourrait être utile si vous soupçonniez que les dés pourraient ne pas être juste. Si, par exemple, les dés sont légèrement déséquilibrés de sorte qu'on a tendance à donner 1 plus souvent que 1/6 du temps, et une autre a tendance à donner 6 inhabituellement souvent, alors au hasard le choix entre les deux aurait tendance à obscurcir le parti pris. (Bien que dans ce cas, 1 et 6 seraient encore plus de 2, 3, 4, et 5. Eh bien, je suppose que cela dépend de la nature du déséquilibre.)
Il existe de nombreuses définitions de l'aléatoire. Une définition d'une série aléatoire, c'est que c'est une série de chiffres produits par un processus aléatoire. Par cette définition, si je tire un juste mourir 5 fois et obtenir les numéros de 2, 4, 3, 2, 5, c'est une série aléatoire. Si je puis rouler que même juste mourir 5 fois plus et obtenir 1, 1, 1, 1, 1, c'est aussi une série aléatoire.
plusieurs posters ont souligné que les fonctions aléatoires sur un ordinateur ne sont pas vraiment aléatoires mais plutôt pseudo-aléatoires, et que si vous connaissez l'algorithme et la graine ils sont complètement prévisibles. C'est vrai, mais la plupart du temps complètement hors de propos. Si je mélange un jeu de cartes et puis les retourner un par un, CE devrait être une série aléatoire. Si quelqu'un regarde les cartes, le résultat sera complètement prévisible, mais par la plupart des définitions de l'aléatoire cela ne le rendra pas moins aléatoire. Si la série passe les tests statistiques de l'aléatoire, le fait que j'ai regardé les cartes ne changera pas ce fait. En pratique, si nous parions de grosses sommes d'argent sur votre capacité à deviner la prochaine carte, alors le fait que vous avez regardé les cartes est très pertinent. Si nous utilisons la série pour simuler les choix de menu des visiteurs de notre site web afin de tester les performances du système, alors le fait que vous avez regardé ne pas faire de différence. (Tant que vous ne modifiez pas le programme afin de profiter de cette connaissance.)
MODIFIER
Je ne pense pas que je pourrais ma réponse au problème de Monty Hall dans un commentaire, donc je vais mettre à jour ma réponse.
pour ceux qui n'ont pas lu Belisarius link, l'essentiel est: un participant à un jeu télévisé a le choix entre 3 portes. Derrière l'un est un prix de valeur, derrière les autres quelque chose d'inutile. Il prend la porte n ° 1. Avant de révéler qu'il est un gagnant ou un perdant, l'animateur ouvre la porte n ° 3 pour révéler qu'il est un perdant. Il donne ensuite au Participant la possibilité de passer à la porte #2. Si le candidat le faire ou pas?
la réponse, qui offense l'intuition de beaucoup de gens, est qu'il devrait changer. La probabilité que son choix original était le gagnant est de 1/3, que l'autre porte est le gagnant est de 2/3. Mon intuition initiale, avec celle de beaucoup d'autres personnes, c'est qu'il n'y aurait aucun gain à changer, que la cote vient d'être changée à 50:50.
après tout, supposons que quelqu'un ait allumé la télé juste après que l'animateur ait ouvert la porte. Cette personne verrait deux portes fermées. En supposant qu'il connaît la nature du jeu, il dirait qu'il y a une 1/2 chance de chaque porte cacher le prix. Comment la cote pour le spectateur d'être 1/2 : 1/2 tandis que la cote pour le concurrent sont 1/3 : 2/3 ?
il fallait vraiment que j'y réfléchisse pour mettre en forme mon intuition. Pour avoir une poignée sur elle, comprenez que lorsque nous parlons de probabilités dans un problème comme celui-ci, nous voulons dire, la probabilité que vous assignez étant donné les informations disponibles. Pour un membre de l'équipage qui a mis le prix derrière, disons, la porte #1, la probabilité que le prix est derrière la porte #1 est de 100% et la probabilité qu'il est derrière l'une des deux autres portes est zéro.
l'équipage les chances d'un membre sont différentes de celles du candidat parce qu'il sait quelque chose que le candidat ne sait pas, à savoir, quelle porte il a mis le prix derrière. De même, les chances du contestant sont différentes de celles du spectateur parce qu'il sait quelque chose que le spectateur ne sait pas, à savoir, quelle porte il a initialement choisie. Cela n'est pas sans importance, parce que le choix de l'hôte de quelle porte ouvrir n'est pas aléatoire. Il n'ouvrira pas la porte la candidate choisi, et il n'ouvrira pas la porte qui cache le prix. Si c'est la même porte, ça lui laisse deux choix. S'il s'agit de portes différentes, il n'en reste qu'une.
alors comment trouver 1/3 et 2/3 ? Quand le participant a choisi une porte, il avait 1/3 de chance de choisir le gagnant. Je pense que c'est assez évident. Cela signifie qu'il y avait 2/3 de chances que l'une des autres portes soit la gagnante. Si le jeu hôte lui la possibilité de passer sans donner aucune information supplémentaire, il n'y aurait aucun gain. Encore une fois, ce devrait être évident. Mais une façon de le voir est de dire qu'il y a 2/3 de chances qu'il gagne en changeant. Mais il a deux alternatives. Donc chacun n'a que 2/3 divisé par 2 = 1/3 de chance d'être le gagnant, ce qui n'est pas mieux que son premier choix. Bien sûr, nous savions déjà le résultat final, cela le calcule simplement d'une manière différente.
Mais maintenant l'hôte révèle que l'un de ces deux choix n'est pas le gagnant. Donc des 2/3 de la chance qu'une porte qu'il n'a pas choisi est la winner, il sait maintenant que l'une des deux alternatives n'est pas elle. L'autre pourrait ou ne pourrait pas être. Il n'a donc plus 2/3 divisé par 2. Il a zéro pour la porte ouverte et de 2/3 pour la porte fermée.
considérez que vous avez un simple problème de pièce de Monnaie flip où même est considéré têtes et Impair est considéré queues. L'implémentation logique est:
rand() mod 2
sur une distribution assez grande, le nombre de nombres pairs devrait égaler le nombre de nombres impairs.
considérez maintenant un léger tweak:
rand() * rand() mod 2
si l'un des résultats est pair, alors le résultat entier devrait être pair. Considérer les 4 résultats possibles (même * même = même, même * impair = pair, impair * pair = pair, impair * impair = impair). Maintenant, sur une distribution suffisamment large, la réponse devrait être même 75% du temps.
je parierais des têtes si j'étais vous.
ce commentaire est vraiment plus une explication de la raison pour laquelle vous ne devriez pas implémenter une fonction aléatoire personnalisée basée sur votre méthode qu'une discussion sur les propriétés mathématiques de l'aléatoire.
en cas de doute sur ce qui arrivera aux combinaisons de vos nombres aléatoires, vous pouvez utiliser les leçons que vous avez apprises en théorie statistique.
dans la situation de L'OP il veut savoir quel est le résultat de X*X = X^2 où X est une variable aléatoire distribuée le long de Uniforme[0,1]. Nous utiliserons la technique CDF puisque ce n'est qu'une cartographie un-à-un.
puisque X ~ Uniform[0,1] c'est cdf Est: f X (x) = 1 Nous voulons que le transformation Y < - X^2 ainsi y = x^2 Trouver l'inverse x(y): sqrt (y) = x cela nous donne x en fonction de Y. Ensuite, trouver le dérivé dx/ dy: d/dy(sqrt (y)) = 1 / (2 sqrt (y))
la distribution de Y est donnée comme suit: f Y (y) = f X (x (y)) / dx/dy / = 1 / (2 sqrt (y))
nous n'avons pas encore fini, nous devons obtenir le domaine de Y. depuis 0 <= x < 1, 0 <= x^2 < 1 donc Y est dans l'intervalle [0, 1). Si vous voulez vérifier si le pdf de Y est en effet un pdf, l'intégrer sur le domaine: intégrer 1 / (2 sqrt (y)) de 0 à 1 et en effet, il apparaît comme 1. Aussi, notez la forme de ladite fonction ressemble à ce que belisarious a posté.
comme pour les choses comme X 1 + X 2 +... + X n , (où X i ~ uniforme[0,1]) nous pouvons simplement faire appel au théorème de limite centrale qui fonctionne pour n'importe quelle distribution dont les moments existent. C'est la raison pour laquelle le Z-test existe réellement.
D'autres techniques pour déterminer le pdf résultant comprennent la transformation Jacobienne (qui est la version généralisée de la technique cdf) et la technique MGF.
EDIT: à titre de clarification, notez que je parle de la distribution de la transformation résultante et non de son aléatoire . C'est en fait pour une autre discussion. Aussi ce que j'ai en fait dérivé était pour (rand ())^2. Pour rand () * rand () c'est beaucoup plus compliqué, ce qui, dans tous les cas, n'aboutira pas à une distribution uniforme de toutes sortes.
ce n'est pas exactement évident, mais rand() est typiquement plus aléatoire que rand()*rand() . Ce qui est important, c'est que ce n'est pas très important pour la plupart des utilisations.
Mais d'abord, ils produisent des distributions différentes. Ce n'est pas un problème si c'est ce que vous voulez, mais il n'importe. Si vous avez besoin d'une distribution particulière, alors ignorez l'ensemble de la question "qui est plus aléatoire". Alors pourquoi rand() est-il plus aléatoire?
Le noyau de pourquoi rand() est plus aléatoire (dans l'hypothèse qu'elle est la production de floating-point des nombres aléatoires dans l'intervalle [0..1], ce qui est très commun) est que lorsque vous multipliez deux nombres FP avec beaucoup d'information dans le mantissa, vous obtenez une certaine perte d'information sur le bout; il n'y a tout simplement pas assez de bit dans un flotteur de double précision de L'IEEE pour contenir toutes les informations qui étaient dans deux flotteurs de double précision de l'IEEE uniformément choisis au hasard de [0..1], et ceux des informations supplémentaires sont perdues. Bien sûr, cela n'a pas tellement d'importance puisque vous (probablement) n'alliez pas utiliser cette information, mais la perte est réelle. De plus, peu importe la distribution que vous produisez (c.-à-d. l'opération que vous utilisez pour faire la combinaison). Chacun de ces nombres aléatoires a (au mieux) 52 bits d'information aléatoire – c'est combien un double IEEE peut contenir – et si vous combinez deux ou plus en un, vous êtes encore limité à avoir au plus 52 bits d'information aléatoire information.
la plupart des utilisations de nombres aléatoires n'utilisent même pas autant de nombres aléatoires que ce qui est réellement disponible dans la source aléatoire. Prends un bon PRNG et ne t'en fais pas trop. (Le niveau de "bonté" dépend de ce que vous faites avec elle; vous devez être prudent lors de la simulation Monte Carlo ou de la cryptographie, mais autrement vous pouvez probablement utiliser le standard PRNG que ce est généralement beaucoup plus rapide.)
randoms flottants sont basés, en général, sur un algorithme qui produit un entier entre zéro et une certaine gamme. Ainsi, en utilisant rand ()*rand (), vous dites essentiellement int_rand ()*int_rand ()/rand_max^2 - ce qui signifie que vous excluez tout nombre premier / rand_max^2.
qui modifie de façon significative la distribution aléatoire.
rand() est uniformément distribué sur la plupart des systèmes, et difficile à prédire si correctement ensemencé. L'utilisation que sauf si vous avez une raison particulière de faire des calculs (c.-à-d. façonner la distribution à une courbe nécessaire).
nombres multiplicateurs finirait dans une plus petite gamme de solution selon votre architecture informatique.
si l'affichage de votre ordinateur montre 16 chiffres rand() serait dire 0.1234567890123
multiplié par un second rand() , 0,1234567890123, donnerait 0,0152415 quelque chose
vous trouverez certainement moins de solutions si vous répétez l'expérience 10^14 fois.
la plupart de ces distributions se produisent parce que vous devez limiter ou normaliser le nombre aléatoire.
nous le normalisons pour être tout positif, s'adapter dans une gamme, et même s'adapter dans les contraintes de la taille de la mémoire pour le type de variable assigné.
en d'autres termes, parce que nous devons limiter l'appel aléatoire entre 0 et X (X étant la limite de taille de notre variable) , nous aurons un groupe de nombres" aléatoires "entre 0 et X.
maintenant quand vous ajoutez le nombre aléatoire à un autre nombre aléatoire la somme sera quelque part entre 0 et 2x...cela dévie les valeurs loin des points de bord (la probabilité d'ajouter deux petits nombres ensemble et deux grands nombres ensemble est très faible quand vous avez deux nombres aléatoires sur une large gamme).
pensez au cas où vous aviez un nombre qui est proche de zéro et vous l'ajoutez avec un autre nombre aléatoire il va certainement devenir plus grand et loin de 0 (cela sera vrai pour les grands nombres aussi bien qu'il est peu probable d'avoir deux grands nombres (nombres proches de X) retournés par la fonction aléatoire deux fois.
maintenant si vous deviez configurer la méthode aléatoire avec des nombres négatifs et des nombres positifs (s'étendant également à travers l'axe zéro) ce ne serait plus le cas.
dire par exemple RandomReal({-x, x}, 50000, .01) alors vous obtiendriez une distribution égale des nombres sur le côté négatif un positif et si vous deviez ajouter les nombres aléatoires ensemble, ils conserveraient leur "aléatoire".
maintenant, je ne suis pas sûr de ce qui se passerait avec le Random() * Random() avec le négatif à positif...que serait un graphique intéressant à voir...mais je dois retourner à l'écriture du code maintenant. :- P
-
Il n'y a pas une telle chose comme plus aléatoire. C'est soit aléatoire ou non. Aléatoire signifie "difficile à prévoir". Cela ne signifie pas non-déterministe. Random () et random () * random () sont également aléatoires si random () est aléatoire. La Distribution n'est pas pertinente en ce qui concerne le caractère aléatoire. Si une distribution non uniforme se produit, cela signifie simplement que certaines valeurs sont plus probables que d'autres; elles sont encore imprévisibles.
-
comme le pseudo-hasard est impliqué, les nombres sont très déterministes. Cependant, la pseudo-aléatoire est souvent suffisante dans les modèles de probabilité et les simulations. Il est assez bien connu que rendre un générateur de nombres pseudo-aléatoires compliqué ne fait qu'il est difficile à analyser. Il est peu probable qu'elle améliore le caractère aléatoire; elle fait souvent échouer les tests statistiques.
-
les propriétés désirées des nombres aléatoires sont important: répétabilité et reproductibilité, aléatoire statistique, (généralement) uniformément distribué, et une grande période sont quelques-uns.
-
concernant les transformations sur des nombres aléatoires: comme quelqu'un l'a dit, la somme de deux ou plus uniformément distribués se traduit dans une distribution normale. C'est le additif théorème de limite centrale. Elle s'applique quelle que soit la distribution source, dans la mesure où toutes les distributions sont indépendantes et identique. Le multiplicatif théorème de la limite centrale dit que le produit de deux ou plusieurs variables aléatoires indépendantes et distribuées de façon indentique est lognormal. Le graphe que quelqu'un d'autre a créé semble exponentiel, mais il est vraiment lognormal. Donc random () * random () est distribué de façon lognormale (bien qu'il ne puisse pas être indépendant puisque les nombres sont tirés du même flux). Cela peut être souhaitable dans certaines applications. Toutefois, il est généralement préférable de générer un nombre aléatoire et le transformer en un nombre distribué de façon lognormale. Random() * random() peut être difficile à analyser.
pour plus d'informations, consultez mon livre à www.performorama.org. Le livre est en construction, mais les documents pertinents sont là. Notez que les numéros de chapitre et de section peuvent changer au fil du temps. Chapitre 8 (théorie des probabilités) -- sections 8.3.1 et 8.3.3, chapitre 10 (nombres aléatoires).
Nous pouvons comparer deux tableaux de chiffres concernant le caractère aléatoire en utilisant complexité de Kolmogorov Si la séquence de nombres ne peut pas être compressée, alors il est le plus aléatoire que nous pouvons atteindre à cette longueur... Je sais que ce type de mesure est plus une option théorique...
en fait, quand on y pense rand() * rand() est moins aléatoire que rand() . Voici pourquoi.
essentiellement, il y a le même nombre de nombres impairs que les nombres pairs. Et dire que 0,04325 est impair, et comme 0,388 est Pair, et 0,4 est Pair, et 0,15 est impair,
qui signifie que rand() a une chance égale d'être une décimale pair ou impair .
On d'un autre côté, rand() * rand() a ses chances empilées un peu différemment.
Disons:
double a = rand();
double b = rand();
double c = a * b;
a et b ont 50% de chance d'être pair ou impair. Sachant que
- pair * pair = pair
- pair * impair = pair
- Impair * Impair = Impair
- Impair * even = even
signifie qu'il y a 75% chance que c est pair, alors que seulement un 25% chance c'est impair, ce qui rend la valeur de rand() * rand() plus prévisible que rand() , donc moins aléatoire.
utiliser un registre de décalage de rétroaction linéaire (LFSR) qui implémente un polynôme primitif.
le résultat sera une séquence de 2^n nombres pseudo-aléatoires, c'est-à-dire aucun se répétant dans la séquence où n est le nombre de bits dans le LFSR .... résultant dans une distribution uniforme.
http://en.wikipedia.org/wiki/Linear_feedback_shift_register http://www.xilinx.com/support/documentation/application_notes/xapp052.pdf
utilisez une graine "aléatoire" basée sur les microsecs de votre horloge informatique ou peut-être un sous-ensemble du résultat md5 sur certaines données changeantes en continu dans votre système de fichiers.
par exemple, un LFSR 32 bits générera 2^32 nombres uniques dans l'ordre (No 2 semblable) à partir d'une graine donnée. La séquence sera toujours dans le même ordre, mais le point de départ sera différente (bien évidemment) pour différentes graines. Donc, si une séquence qui se répète entre têtes de série n'est pas un problème, cela pourrait être un bon choix.
j'ai utilisé LFSR 128-bit pour générer des tests aléatoires dans des simulateurs matériels en utilisant une graine qui est les résultats md5 sur les données système changeant en permanence.
en supposant que rand() renvoie un nombre entre [0, 1) il est évident que rand() * rand() sera biaisé vers 0. En effet, si l'on multiplie x par un nombre compris entre [0, 1) , on obtient un nombre inférieur à x . Voici la distribution de 10000 plus nombres aléatoires:
google.charts.load("current", { packages: ["corechart"] });
google.charts.setOnLoadCallback(drawChart);
function drawChart() {
var i;
var randomNumbers = [];
for (i = 0; i < 10000; i++) {
randomNumbers.push(Math.random() * Math.random());
}
var chart = new google.visualization.Histogram(document.getElementById("chart-1"));
var data = new google.visualization.DataTable();
data.addColumn("number", "Value");
randomNumbers.forEach(function(randomNumber) {
data.addRow([randomNumber]);
});
chart.draw(data, {
title: randomNumbers.length + " rand() * rand() values between [0, 1)",
legend: { position: "none" }
});
}<script src="https://www.gstatic.com/charts/loader.js"></script>
<div id="chart-1" style="height: 500px">Generating chart...</div> si rand() renvoie un entier entre [x, y] alors vous avez la distribution suivante. Notez le nombre de valeurs impaires vs Pair:
google.charts.load("current", { packages: ["corechart"] });
google.charts.setOnLoadCallback(drawChart);
document.querySelector("#draw-chart").addEventListener("click", drawChart);
function randomInt(min, max) {
return Math.floor(Math.random() * (max - min + 1)) + min;
}
function drawChart() {
var min = Number(document.querySelector("#rand-min").value);
var max = Number(document.querySelector("#rand-max").value);
if (min >= max) {
return;
}
var i;
var randomNumbers = [];
for (i = 0; i < 10000; i++) {
randomNumbers.push(randomInt(min, max) * randomInt(min, max));
}
var chart = new google.visualization.Histogram(document.getElementById("chart-1"));
var data = new google.visualization.DataTable();
data.addColumn("number", "Value");
randomNumbers.forEach(function(randomNumber) {
data.addRow([randomNumber]);
});
chart.draw(data, {
title: randomNumbers.length + " rand() * rand() values between [" + min + ", " + max + "]",
legend: { position: "none" },
histogram: { bucketSize: 1 }
});
}<script src="https://www.gstatic.com/charts/loader.js"></script>
<input type="number" id="rand-min" value="0" min="0" max="10">
<input type="number" id="rand-max" value="9" min="0" max="10">
<input type="button" id="draw-chart" value="Apply">
<div id="chart-1" style="height: 500px">Generating chart...</div>OK, donc je vais essayer d'ajouter une valeur pour compléter les autres réponses en disant que vous créez et utilisez un générateur de nombres aléatoires.
générateurs de nombres aléatoires sont des dispositifs (dans un sens très général) qui ont de multiples caractéristiques qui peuvent être modifiées pour correspondre à un but. Certains d'entre eux (de moi):
- entropie: comme dans Shannon entropie
- Distribution: distribution statistique (poisson, normal, etc.)
- Type: Quelle est la source des nombres (algorithme, événement naturel, combinaison de, etc.) et algorithme appliqué.
- efficacité: rapidité ou complexité d'exécution.
- Modèles: la périodicité, les séquences, les courses, etc.
- et probablement plus...
dans la plupart des réponses ici, la distribution est le principal point d'intérêt, mais par le mélange et les fonctions de correspondance et les paramètres, vous créer de nouvelles façons de générer des nombres aléatoires qui auront des caractéristiques différentes pour certaines dont l'évaluation peut ne pas être évidente à première vue.
Il est facile de montrer que la somme des deux nombres aléatoires n'est pas nécessairement aléatoire. Imaginez que vous ayez un dé 6 côtés et roulez. Chaque numéro a 1/6 de chance d'apparaître. Maintenant, dites que vous avez eu 2 dés et a résumé le résultat. La distribution de ces sommes n'est pas 1/12. Pourquoi? Parce que certains numéros apparaissent plus que d'autres. Il y a plusieurs partitions d'entre eux. Par exemple, le numéro 2 est la somme de 1+1 mais 7 peut être constitué par 3+4 ou 4+3 ou 5+2 etc... il a donc un plus de chance de monter.
par conséquent, appliquer une transformation, dans ce cas l'addition sur une fonction aléatoire ne le rend pas plus aléatoire, ou préserve nécessairement l'aléatoire. Dans le cas des dés ci-dessus, la distribution est asymétrique à 7 et donc moins aléatoire.
comme d'autres l'ont déjà souligné, cette question Est difficile à répondre puisque chacun de nous a son propre image de l'aléatoire dans sa tête.
C'est pourquoi, je vous recommande vivement de prendre un certain temps et lire à travers ce site pour obtenir une meilleure idée de l'aléatoire:
pour revenir à la vraie question. Il n'y a pas plus ou moins de hasard dans ce terme:
les deux n'apparaissent qu'au hasard !
Dans les deux cas - juste rand() ou rand() * rand() - la situation est la même: Après quelques milliards de nombres, la séquence se répétera(!) . apparaît aléatoire pour l'observateur, parce qu'il ne sait pas l'ensemble de la séquence, mais l'ordinateur a pas de véritable source aléatoire - donc il ne peut pas non plus produire l'aléatoire.
par exemple: le temps est-il aléatoire? Nous ne disposons pas de suffisamment de capteurs ou de connaissances pour déterminer si les conditions météorologiques sont aléatoires ou non.
La réponse serait elle repose, nous l'espérons, le rand()*rand() serait plus aléatoire que rand(), mais comme:
- les deux réponses dépendent de la taille du bit de votre valeur
- que dans la plupart des cas vous produisez en fonction d'un algorithme pseudo-aléatoire (qui est principalement un générateur de nombres qui dépend de votre horloge informatique, et pas tant que cela au hasard).
- rendre votre code plus lisible (et ne pas invoquer quelque voodoo Dieu du hasard avec ce genre de mantra).
si vous cochez l'une des cases ci-dessus, je vous suggère d'opter pour le simple "rand()". Parce que votre code serait plus lisible (ne vous demanderait pas pourquoi vous avez écrit ceci, pour ...bien... plus de 2 secondes), Facile à entretenir (si vous voulez remplacer votre fonction rand par une super_rand).
Si vous voulez une meilleure aléatoire, je vous recommande de le lire de toute source qui fournissent assez de bruit ( radio statique ), puis un simple rand() devrait suffire.