Algorithmes De Clustering Python
j'ai cherché autour de scipy et sklearn des algorithmes de regroupement pour un problème particulier que j'ai. J'ai besoin d'un moyen de caractériser une population de particules N en groupes k, où k n'est pas nécessairement connu, et en plus de cela, aucune longueur de liaison a priori n'est connue (similaire à ceci question).
j'ai essayé kmeans, qui fonctionne bien si vous combien de grappes vous voulez. J'ai essayé dbscan, ce qui est mauvais à moins que vous dire il s'agit d'une échelle de longueur caractéristique sur laquelle on arrête de chercher (ou commence à chercher) des amas. Le problème est que j'ai potentiellement des milliers de ces amas de particules, et je ne peux pas passer le temps de dire aux algorithmes kmeans/dbscan ce qu'ils devraient faire.
Voici un exemple de ce que dbscan trouver:
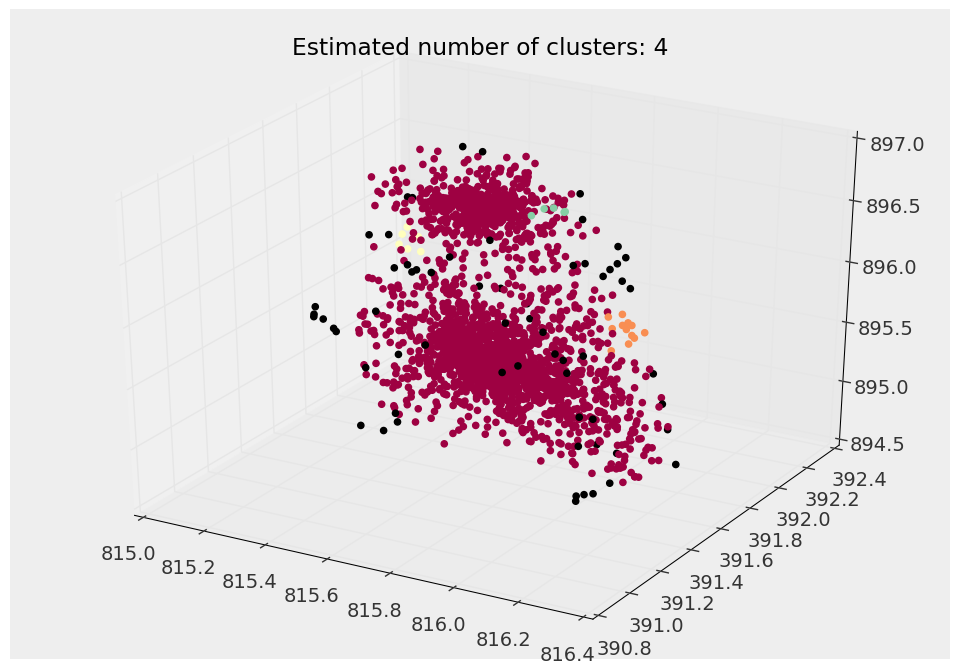
vous pouvez voir qu'il y a vraiment deux populations séparées ici, en ajustant le facteur epsilon (le Max. distance entre le paramètre clusters voisins), Je ne peux tout simplement pas le faire voir ces deux populations de particules.
Est-il d'autres algorithmes qui pourrait fonctionner ici? Je suis à la recherche d'un minimum d'information à l'avance - en d'autres termes, j'aimerais que l'algorithme soit en mesure de prendre des décisions "intelligentes" sur ce qui pourrait constituer un groupe distinct.
4 réponses
j'en ai trouvé un qui n'exige aucune information/supposition a priori et qui fait très bien ce que je lui demande de faire. Il est appelé Changement Moyen et est situé dans le SciKit-Learn. Il est aussi relativement rapide (comparé à d'autres algorithmes comme la Propagation D'affinité).
voici un exemple de ce qu'il donne:
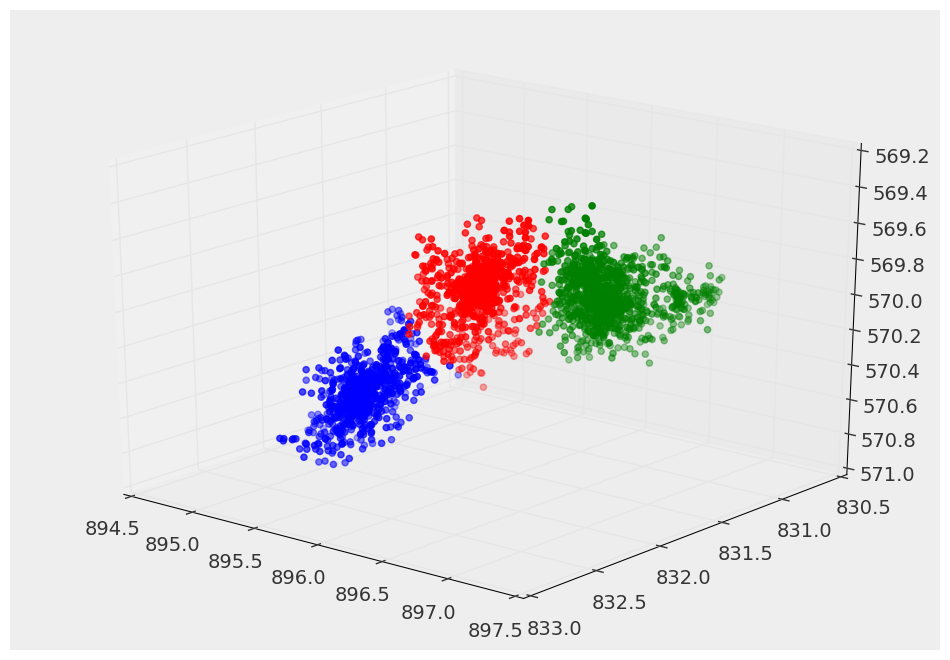
je tiens aussi à souligner que, dans la documentation indique qu'il ne peut pas l'échelle.
lors de L'utilisation de DBSCAN, il peut être utile de mettre à l'échelle/normaliser les données ou les distances à l'avance, de sorte que l'estimation d'epsilon sera relative.
il y a une mise en oeuvre de DBSCAN - je pense que c'est celle Anony-Mousse, quelque part, désigné comme "flottant autour de" -, qui est avec une fonction d'estimateur epsilon. Il fonctionne, tant que son non nourri avec de grands ensembles de données.
Il y a plusieurs versions incomplètes de Optique à github. Peut-être vous pouvez en trouver un pour s'adapter à votre objectif. Encore essayer de comprendre moi-même, quel effet minPts a, en utilisant un et la même méthode d'extraction.
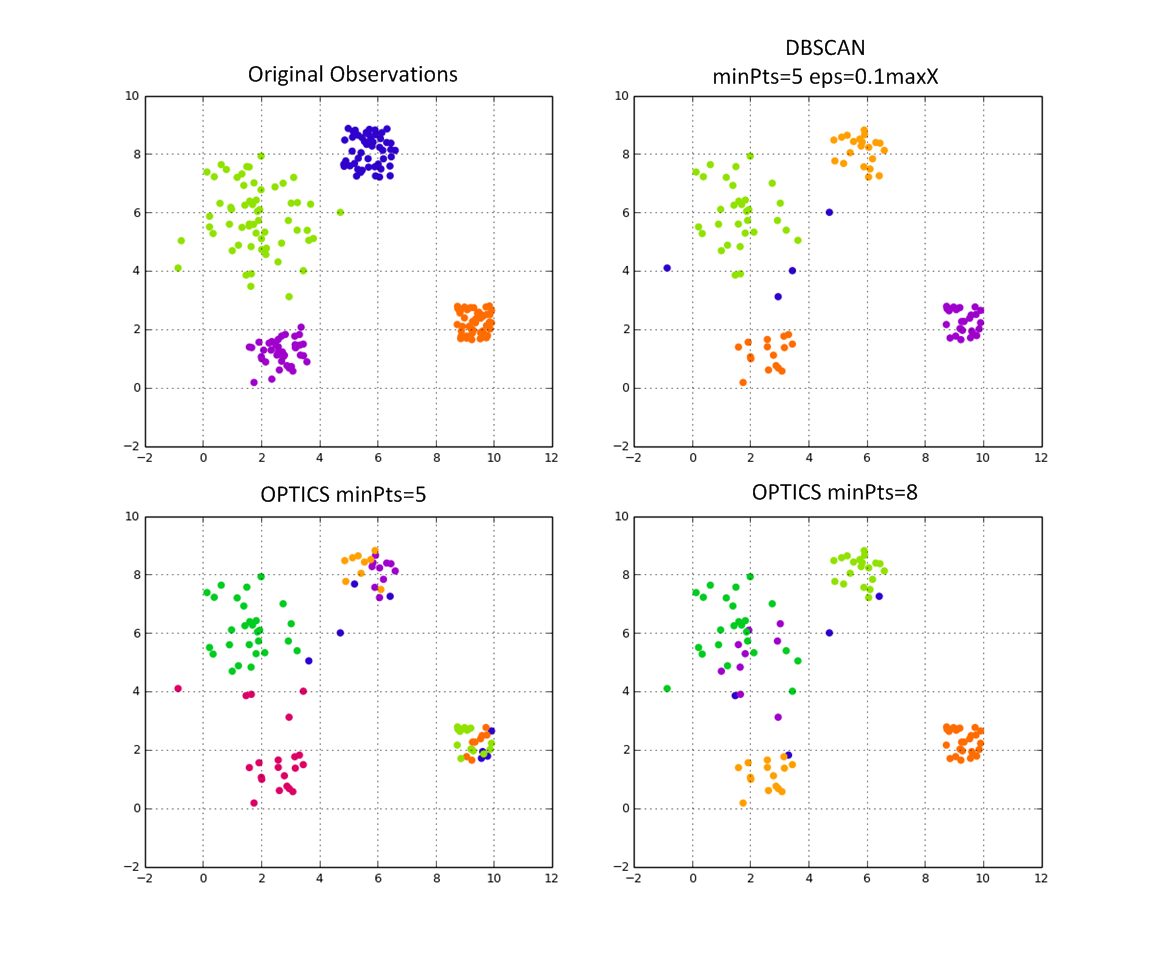
vous pouvez essayer un arbre de enjambement minimum (algorithme de zahn) et ensuite enlever le bord le plus long similaire aux formes alpha. Je l'ai utilisé avec une triangulation de delaunay et une partie concave de la coque:http://www.phpdevpad.de/geofence. Vous pouvez également essayer une classification hiérarchique par exemple clusterfck.
votre graphique indique que vous avez choisi le minPts paramètre trop petit.
regardez L'optique, qui n'a plus besoin du paramètre epsilon de DBSCAN.