Normalisation par rapport à la normalisation par lots
je comprends que la Normalisation par lots aide à une formation plus rapide en tournant l'activation vers la distribution gaussienne de l'unité et en s'attaquant ainsi au problème de la disparition des gradients. Les actes normatifs des lots sont appliqués différemment à la formation(utiliser la moyenne/var de chaque lot) et au temps d'essai (utiliser la moyenne/var de course finalisée de la phase de formation).
la normalisation des instances, d'autre part, agit comme la normalisation des contrastes comme mentionné dans cet article https://arxiv.org/abs/1607.08022<!--4 . Les auteurs mentionnent que les images de sortie stylisées ne doivent pas dépendre du contraste de l'image de contenu d'entrée et donc la normalisation des instances aide.
mais alors nous ne devrions pas aussi utiliser la normalisation d'instance pour la classification d'image où l'étiquette de classe ne devrait pas dépendre du contraste de l'image d'entrée. Je n'ai vu aucun papier utilisant la normalisation d'instance en lieu et place de la normalisation de lot pour la classification. Quelle est la raison? Aussi, peut et devrait batch et l'instance la normalisation doit être utilisée conjointement. Je suis impatient d'obtenir une compréhension intuitive aussi bien que théorique du moment d'utiliser quelle normalisation.
3 réponses
Définition
commençons par la définition stricte des deux:
normalisation des lots
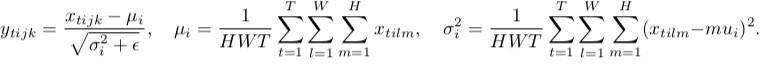
normalisation des instances
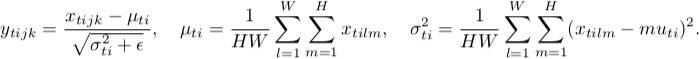
comme vous pouvez le voir, ils font la même chose, sauf pour le nombre de tenseurs d'entrée qui sont normalisés conjointement. La version par lot normalise toutes les images à travers le lot et les emplacements spatiaux (en le cas ordinaire, à CNN ); la version de l'instance normalise chaque lot indépendamment, i.e., à travers localisations spatiales une seule.
en d'autres termes, lorsque la norme discontinue calcule une moyenne et un dev std (faisant ainsi la distribution de la couche entière gaussienne), la norme d'instance calcule T d'entre eux, ce qui rend chaque distribution d'image individuelle gaussienne, mais pas conjointement.
une simple analogie: lors de l'étape de pré-traitement des données, c'est possibilité de normaliser les données par image ou de normaliser l'ensemble des données.
Crédit: les formules sont de ici.
quelle normalisation est la meilleure?
La réponse dépend de l'architecture du réseau, en particulier sur ce qui est fait après la couche de normalisation. Les réseaux de classification d'Image empilent habituellement les cartes de traits ensemble et les filent à la couche FC, qui poids des actions à travers le lot (la manière moderne est d'utiliser la couche CONV au lieu de FC, mais l'argument s'applique toujours).
C'est là que les nuances de distribution commencent à compter: le même neurone va recevoir l'entrée de toutes les images. Si la variance à travers le lot est élevée, le gradient des petites activations sera complètement supprimé par les activations élevées, ce qui est exactement le problème que la norme du lot essaie de résoudre. C'est pourquoi il est assez possible que par instance la normalisation n'améliorera pas du tout la convergence des réseaux.
d'un autre côté, la normalisation par lots ajoute du bruit supplémentaire à la formation, car le résultat pour une instance particulière dépend des instances voisines. Il s'avère que ce genre de bruit peut être bon ou mauvais pour le réseau. Ceci est bien expliqué dans le "Poids Normalisation" papier par Tim Salimans de l'al, le nom de réseaux de neurones récurrents et l'apprentissage par renforcement que DQNs applications sensibles au bruit. Je ne suis pas tout à fait sûr, mais je pense que la même sensibilité au bruit était le principal problème dans la tâche de stylisation, qui instance norm essayé de se battre. Il serait intéressant de vérifier si la norme de poids donne de meilleurs résultats pour cette tâche particulière.
pouvez-vous combiner la normalisation des lots et des instances?
bien qu'il fasse un réseau neuronal valide, il n'y a aucune utilité pratique pour lui. Le bruit de normalisation par lots est soit aider l'apprentissage processus (dans ce cas, c'est préférable) ou de le blesser (dans ce cas, il est préférable de le supprimer). Dans les deux cas, de quitter le réseau, avec un type de normalisation est susceptible d'améliorer les performances.
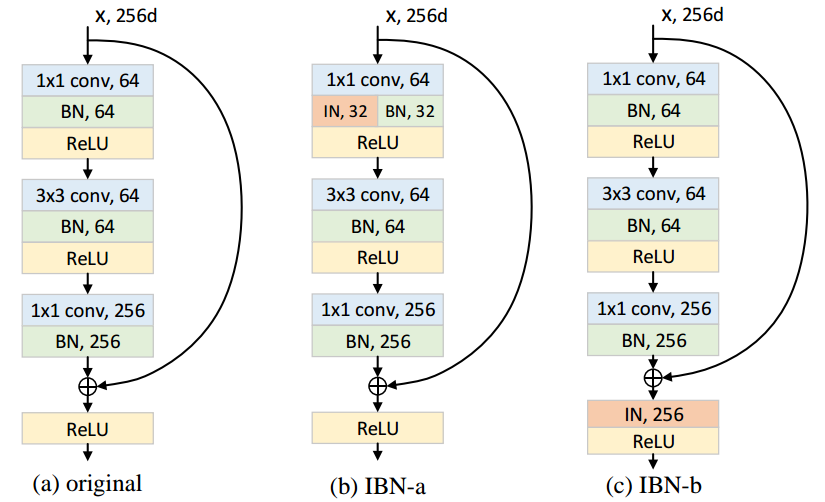
grande question et déjà répondu gentiment. Juste pour ajouter: j'ai trouvé cette visualisation de Kaiming He's groupe Norm paper utile. 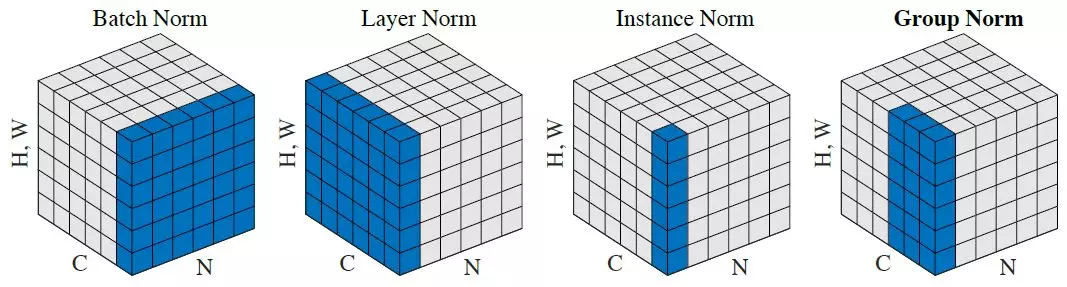
Source:lien vers l'article sur les Moyennes des contrastes entre les Normes
je voulais ajouter plus d'informations à cette question puisqu'il y a quelques œuvres plus récentes dans ce domaine. Votre intuition
utiliser la normalisation d'instance pour la classification d'image où l'étiquette de classe ne devraient pas dépendre du contraste de l'image d'entrée
est en partie correcte. Je dirais qu'un cochon en plein jour est encore un cochon quand l'image est prise à la nuit ou à l'aube. Cependant, cela ne signifie pas utiliser la normalisation d'instance à travers le réseau vous donnera un meilleur résultat. Voici quelques raisons:
- la distribution des couleurs joue toujours un rôle. Il est plus susceptible d'être une pomme qu'une orange si elle a beaucoup de rouge.
- à des couches ultérieures, vous ne pouvez plus imaginer que la normalisation des instances agit comme la normalisation des contrastes. Les détails propres à la classe apparaîtront dans les couches plus profondes et leur normalisation par l'instance nuira grandement aux performances du modèle.
IBN-Net utilise les deux lots normalisation et normalisation des instances dans leur modèle. Ils ont seulement mis la normalisation d'instance dans les couches tôt et ont obtenu l'amélioration à la fois dans la précision et la capacité de généraliser. Ils ont du code source ouvert ici.