Optimisation de l'hyperparamètre pour les Structures D'apprentissage en profondeur à L'aide de L'optimisation Bayésienne
j'ai construit une structure CLDNN (Convolutional, LSTM, Deep Neural Network) pour la tâche de classification du signal brut.
chaque période d'entraînement dure environ 90 secondes et les hyperparamètres semblent très difficiles à optimiser.
j'ai fait des recherches sur diverses façons d'optimiser les hyperparamètres (par ex. recherche au hasard ou sur Grille) et j'ai découvert l'optimisation Bayésienne.
bien que je ne comprenne pas encore tout à fait l'algorithme d'optimisation, Je se nourrir comme il va m'aider grandement.
je voudrais poser quelques questions concernant la tâche d'optimisation.
- comment mettre en place L'optimisation Bayésienne par rapport à un réseau profond?(Quelle est la fonction de coût que nous essayons d'optimiser?)
- Quelle est la fonction que j'essaie d'optimiser? Est-ce le coût de la validation établie après N epochs?
- est-ce que spearmint est un bon point de départ pour cette tâche? Toute autre suggestion pour ceci tâche?
je vous serais très reconnaissant de tout comprendre dans ce problème.
1 réponses
bien que je ne comprenne pas encore tout à fait l'optimisation algorithme, je me nourris comme si ça m'aiderait beaucoup.
tout d'Abord, permettez-moi de vous expliquer brièvement cette partie. Les méthodes d'optimisation bayésiennes visent à traiter le compromis exploration-exploitation dans le multi-armed bandit problem. Dans ce problème, il y a un inconnu fonction, que l'on peut évaluer à n'importe quel point, mais chaque évaluation coûte (pénalité directe ou opportunité le coût), et le but est de trouver son maximum avec le moins d'essais possible. Fondamentalement, le compromis est ceci: vous connaissez la fonction dans un ensemble fini de points (dont certains sont bons et certains sont mauvais), de sorte que vous pouvez essayer une zone autour du maximum local actuel, en espérant l'améliorer (exploitation), ou vous pouvez essayer une zone entièrement nouvelle de l'espace, qui peut potentiellement être beaucoup mieux ou bien pire (exploration), ou quelque part entre les deux.
méthodes D'optimisation bayésiennes (par exemple PI, EI, UCB), construisez un modèle de la fonction cible en utilisant un Processus Gaussien (GP) et à chaque étape de choisir le point le plus "prometteur" basé sur leur modèle GP (notez que "prometteur" peut être défini différemment par différentes méthodes particulières).
Voici un exemple:
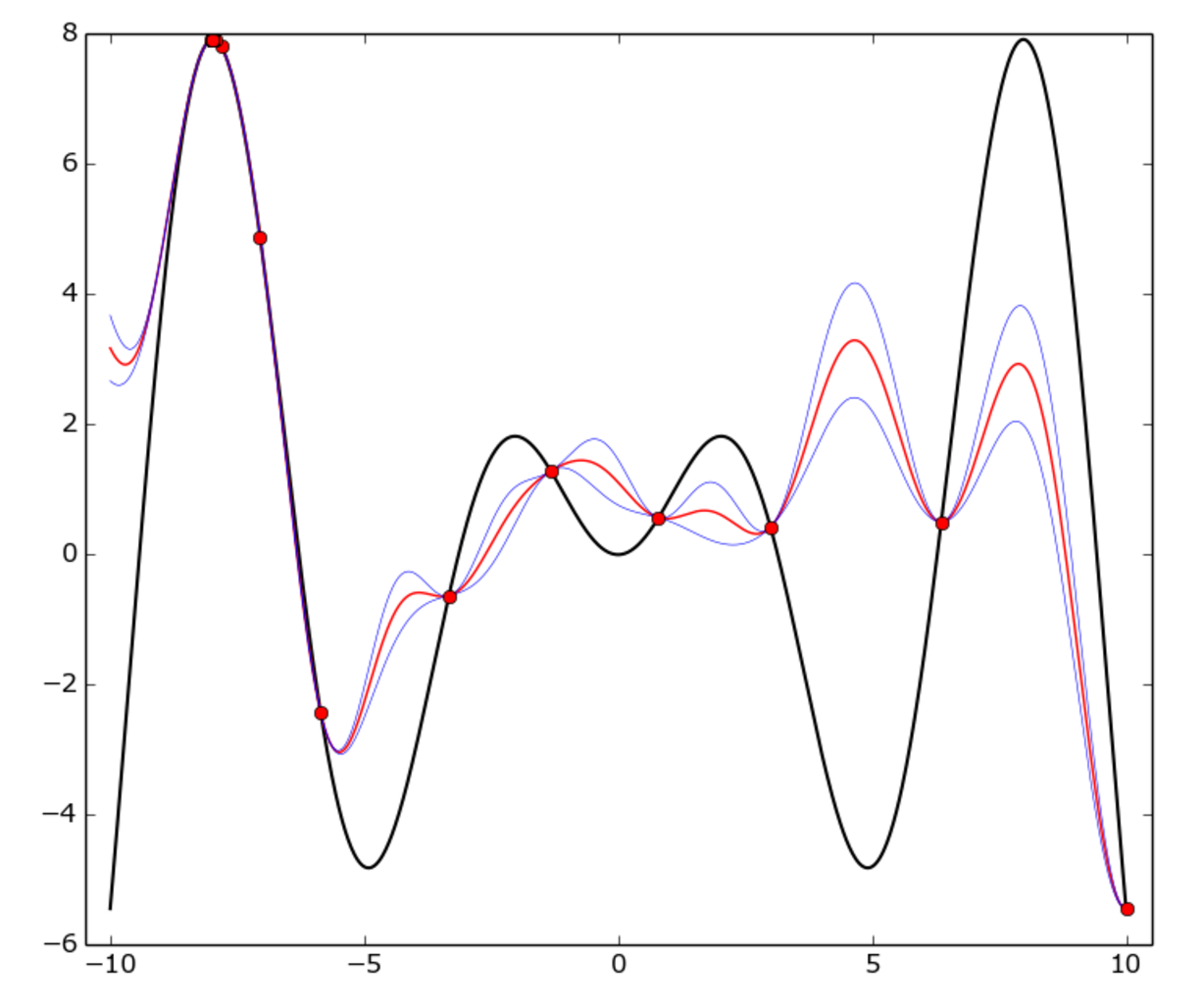
la vraie fonction est f(x) = x * sin(x) (courbe noire) sur [-10, 10] intervalle. Les points rouges représentent chaque essai, la courbe rouge est le GP moyenne, la courbe bleue est la moyenne plus ou moins un écart-type.
Comme vous pouvez le voir, le modèle GP ne correspond pas à la vraie fonction partout, mais l'optimiseur a identifié assez rapidement la zone" chaude " autour de -8 et a commencé à l'exploiter.
comment mettre en place L'optimisation Bayésienne en ce qui concerne une profondeur le réseau?
Dans ce cas, l'espace est défini par (éventuellement transformé) hyperparameters, habituellement une unité multidimensionnelle hypercube.
par exemple, supposons que vous ayez trois hyperparamètres: un taux d'apprentissage α in [0.001, 0.01], le régularisateur λ in [0.1, 1] (les deux continus) et la taille de la couche cachée N in [50..100] (entier). L'espace pour l'optimisation est un cube tridimensionnel [0, 1]*[0, 1]*[0, 1]. Chaque point (p0, p1, p2) dans ce cube correspond à une trinité (α, λ, N) par la transformation suivante:
p0 -> α = 10**(p0-3)
p1 -> λ = 10**(p1-1)
p2 -> N = int(p2*50 + 50)
Quelle est la fonction que j'essaie d'optimiser? Est-il le coût de le validation établie après N epochs?
Correct, la fonction cible est la précision de validation du réseau neuronal. De toute évidence, chaque évaluation est coûteuse, car elle nécessite au moins plusieurs Epoch pour la formation.
notez Également que la fonction cible est stochastique, c'est-à-dire que deux évaluations sur le même point peuvent différer légèrement, mais ce n'est pas un bloqueur pour L'optimisation Bayésienne, bien que cela augmente évidemment l'incertitude.
est-ce que spearmint est un bon point de départ pour cette tâche? Toute autre suggestions pour cette tâche?
menthe verte est une bonne bibliothèque, vous pouvez certainement l'utiliser. Je peux aussi recommander hyperopt.
dans mes propres recherches, j'ai fini par écrire ma propre petite bibliothèque, essentiellement pour deux raisons: je voulais coder la méthode Bayésienne exacte à utiliser (en particulier, j'ai trouvé un stratégie de portefeuille d'UCB et PI convergé de plus, il existe une autre technique qui permet d'économiser jusqu'à 50% du temps de formation appelé prédiction de la courbe d'apprentissage (l'idée est de passer plein cycle d'apprentissage lors de l'optimiseur est convaincue que le modèle n'apprend pas aussi vite que dans d'autres domaines). Je ne connais aucune bibliothèque qui utilise ça, donc je l'ai codé moi-même, et à la fin ça a payé. Si vous êtes intéressé, le code est GitHub.