Comment compter les lignes totales modifiées par un auteur spécifique dans un dépôt Git?
y a-t-il une commande que je peux invoquer pour compter les lignes modifiées par un auteur spécifique dans un dépôt Git? Je sais qu'il doit y avoir des façons de compter le nombre de commits comme Github le fait pour leur graphique D'Impact.
21 réponses
la sortie de la commande suivante doit être raisonnablement facile à envoyer au script pour additionner les totaux:
git log --author="<authorname>" --oneline --shortstat
donne des statistiques pour toutes les propagations sur la tête courante. Si vous voulez ajouter des statistiques dans d'autres branches, vous devrez les fournir comme arguments à git log .
pour passer à un script, en supprimant même le format "oneline" peut être fait avec un format de log vide, et comme commenté par Jakub Narębski, --numstat est une autre alternative. Il génère des statistiques par fichier plutôt que par ligne, mais il est encore plus facile à analyser.
git log --author="<authorname>" --pretty=tformat: --numstat
cela donne quelques statistiques sur l'auteur, modifier si nécessaire.
Utilisant Gawk:
git log --author="_Your_Name_Here_" --pretty=tformat: --numstat \
| gawk '{ add += ; subs += ; loc += - } END { printf "added lines: %s removed lines: %s total lines: %s\n", add, subs, loc }' -
utilisant Awk sur Mac OSX:
git log --author="_Your_Name_Here_" --pretty=tformat: --numstat | awk '{ add += ; subs += ; loc += - } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }' -
EDIT (2017)
il y a un nouveau paquet sur github qui semble lisse et utilise bash comme dépendances (testé sur linux). Il est plus adapté à un usage direct plutôt qu'à des scripts.
Il est git-rapide-stats (lien github) .
copier git-quick-stats dans un dossier et ajouter le dossier au chemin.
mkdir ~/source
cd ~/source
git clone git@github.com:arzzen/git-quick-stats.git
mkdir ~/bin
ln -s ~/source/git-quick-stats/git-quick-stats ~/bin/git-quick-stats
chmod +x ~/bin/git-quick-stats
export PATH=${PATH}:~/bin
Utilisation:
git-quick-stats
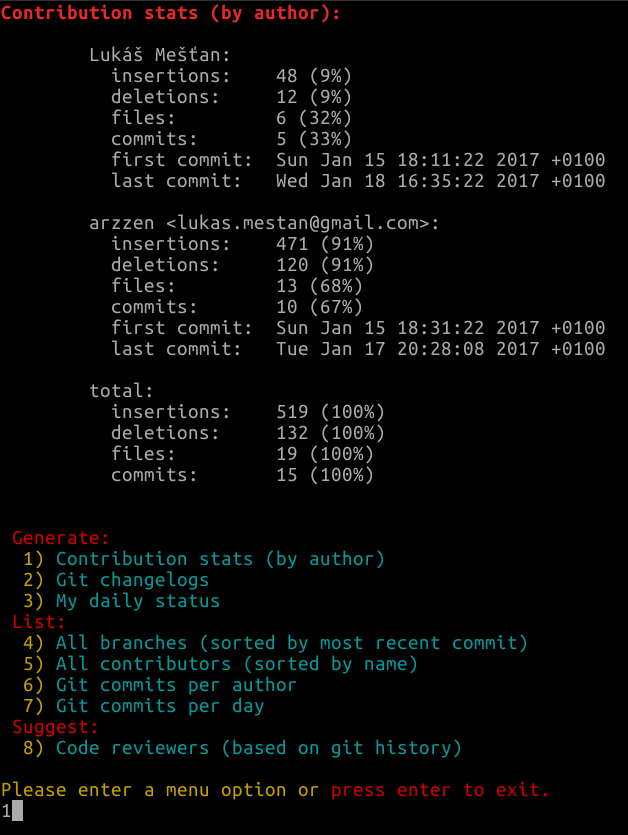
dans le cas où quelqu'un veut voir les statistiques pour chaque utilisateur dans leur base de codes, un couple de mes collègues ont récemment mis en place cet horrible one-liner:
git log --shortstat --pretty="%cE" | sed 's/\(.*\)@.*//' | grep -v "^$" | awk 'BEGIN { line=""; } !/^ / { if (line=="" || !match(line, "151900920")) {line = "151900920" "," line }} /^ / { print line " # " "151900920"; line=""}' | sort | sed -E 's/# //;s/ files? changed,//;s/([0-9]+) ([0-9]+ deletion)/ 0 insertions\(+\), /;s/\(\+\)$/\(\+\), 0 deletions\(-\)/;s/insertions?\(\+\), //;s/ deletions?\(-\)//' | awk 'BEGIN {name=""; files=0; insertions=0; deletions=0;} {if ( != name && name != "") { print name ": " files " files changed, " insertions " insertions(+), " deletions " deletions(-), " insertions-deletions " net"; files=0; insertions=0; deletions=0; name=; } name=; files+=; insertions+=; deletions+=} END {print name ": " files " files changed, " insertions " insertions(+), " deletions " deletions(-), " insertions-deletions " net";}'
(prend quelques minutes pour passer à travers notre repo, qui a environ 10-15K commits.)
git fame https://github.com/oleander/git-fame-rb
est un bel outil pour obtenir le nombre pour tous les auteurs à la fois, y compris la propagation et le nombre de fichiers modifiés:
sudo apt-get install ruby-dev
sudo gem install git_fame
cd /path/to/gitdir && git fame
il y a aussi la version Python à https://github.com/casperdcl/git-fame (mentionné par @fracz):
sudo apt-get install python-pip python-dev build-essential
pip install --user git-fame
cd /path/to/gitdir && git fame
sortie de L'échantillon:
Total number of files: 2,053
Total number of lines: 63,132
Total number of commits: 4,330
+------------------------+--------+---------+-------+--------------------+
| name | loc | commits | files | percent |
+------------------------+--------+---------+-------+--------------------+
| Johan Sørensen | 22,272 | 1,814 | 414 | 35.3 / 41.9 / 20.2 |
| Marius Mathiesen | 10,387 | 502 | 229 | 16.5 / 11.6 / 11.2 |
| Jesper Josefsson | 9,689 | 519 | 191 | 15.3 / 12.0 / 9.3 |
| Ole Martin Kristiansen | 6,632 | 24 | 60 | 10.5 / 0.6 / 2.9 |
| Linus Oleander | 5,769 | 705 | 277 | 9.1 / 16.3 / 13.5 |
| Fabio Akita | 2,122 | 24 | 60 | 3.4 / 0.6 / 2.9 |
| August Lilleaas | 1,572 | 123 | 63 | 2.5 / 2.8 / 3.1 |
| David A. Cuadrado | 731 | 111 | 35 | 1.2 / 2.6 / 1.7 |
| Jonas Ängeslevä | 705 | 148 | 51 | 1.1 / 3.4 / 2.5 |
| Diego Algorta | 650 | 6 | 5 | 1.0 / 0.1 / 0.2 |
| Arash Rouhani | 629 | 95 | 31 | 1.0 / 2.2 / 1.5 |
| Sofia Larsson | 595 | 70 | 77 | 0.9 / 1.6 / 3.8 |
| Tor Arne Vestbø | 527 | 51 | 97 | 0.8 / 1.2 / 4.7 |
| spontus | 339 | 18 | 42 | 0.5 / 0.4 / 2.0 |
| Pontus | 225 | 49 | 34 | 0.4 / 1.1 / 1.7 |
+------------------------+--------+---------+-------+--------------------+
mais attention: comme L'a mentionné Jared dans le commentaire, le faire sur un très grand dépôt prendra des heures. Pas sûr que ce pourrait être améliorée, considérant qu'il doit traiter tellement Git de données.
j'ai trouvé ce qui suit utile pour voir qui avait le plus de lignes qui étaient actuellement dans la base de code:
git ls-files -z | xargs -0n1 git blame -w | ruby -n -e '$_ =~ /^.*\((.*?)\s[\d]{4}/; puts .strip' | sort -f | uniq -c | sort -n
les autres réponses se sont surtout concentrées sur les lignes modifiées dans les commits, mais si les commits ne survivent pas et sont écrasés, ils peuvent juste avoir été barattés. L'incantation ci-dessus vous permet également de trier tous les committers par lignes au lieu d'une seule à la fois. Vous pouvez ajouter quelques options à git blame (- C-M) pour obtenir de meilleurs nombres qui prennent le fichier mouvement et mouvement de ligne entre les fichiers dans le compte, mais la commande peut fonctionner beaucoup plus longtemps si vous le faites.
aussi, si vous cherchez des lignes modifiées dans all commits pour tous les committers, le petit script suivant est utile:
pour compter le nombre de commet par un auteur donné (ou tous les auteurs) sur une branche donnée, vous pouvez utiliser git-shortlog ; voir en particulier ses options --numbered et --summary , par exemple lorsqu'il est exécuté sur un dépôt git:
$ git shortlog v1.6.4 --numbered --summary
6904 Junio C Hamano
1320 Shawn O. Pearce
1065 Linus Torvalds
692 Johannes Schindelin
443 Eric Wong
après avoir regardé Alex's et Gerty3000 'S réponse, j'ai essayé de raccourcir le One-liner:
essentiellement, en utilisant git log numstat et pas garder la trace du nombre de fichiers changé.
Git version 2.1.0 on Mac OSX:
git log --format='%aN' | sort -u | while read name; do echo -en "$name\t"; git log --author="$name" --pretty=tformat: --numstat | awk '{ add += ; subs += ; loc += - } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }' -; done
exemple:
Jared Burrows added lines: 6826, removed lines: 2825, total lines: 4001
Le Réponse à partir de AaronM l'utilisation de la coque d'un paquebot est bon, mais en fait, il est encore un autre bug, où les espaces corrompre les noms d'utilisateur si il y a de différentes quantités de blanc d'espace entre le nom d'utilisateur et la date. Les noms d'utilisateurs corrompus donneront plusieurs lignes pour les comptes d'utilisateurs et vous devez les résumer vous-même.
Ce petit changement résolu le problème pour moi:
git ls-files -z | xargs -0n1 git blame -w | perl -n -e '/^.*?\((.*?)\s+[\d]{4}/; print ,"\n"' | sort -f | uniq -c | sort -n
noter le + après \s qui consommera tous les espaces blancs du nom à la date.
ajoutant en fait cette réponse autant pour mon propre souvenir que pour aider quelqu'un d'autre, puisque c'est au moins la deuxième fois que je google le sujet:)
@mmrobins @AaronM @ErikZ @JamesMishra a fourni des variantes qui ont toutes un problème en commun: ils demandent à git de produire un mélange d'informations non destinées à la consommation de script, y compris le contenu de ligne à partir du dépôt sur la même ligne, puis de faire correspondre le mess avec un regexp.
c'est un problème quand certaines lignes ne sont pas du texte UTF-8 valide, et aussi quand certaines lignes se produisent pour correspondre à la regexp (ceci s'est produit ici).
Voici une ligne modifiée qui n'a pas ces problèmes. Il demande à git de produire des données proprement sur des lignes séparées, ce qui le rend facile de filtrer ce que nous voulons fermement:
git ls-files -z | xargs -0n1 git blame -w --line-porcelain | grep -a "^author " | sort -f | uniq -c | sort -n
Vous pouvez grep pour d'autres chaînes, comme l'auteur-mail, committer, etc.
peut-être d'abord faire export LC_ALL=C (en supposant bash ) pour forcer le traitement au niveau byte (cela se produit aussi pour accélérer grep énormément à partir des locales basées sur UTF-8).
voici une courte doublure qui produit des statistiques pour tous les auteurs. C'est beaucoup plus rapide que la solution de Dan ci-dessus à https://stackoverflow.com/a/20414465/1102119 (la mine présente une complexité temporelle O(N) au lieu de O (NM) où N est le nombre de propagations, et M le nombre d'auteurs).
git log --no-merges --pretty=format:%an --numstat | awk '/./ && !author { author = "151900920"; next } author { ins[author] += ; del[author] += } /^$/ { author = ""; next } END { for (a in ins) { printf "%10d %10d %10d %s\n", ins[a] - del[a], ins[a], del[a], a } }' | sort -rn
Une solution a été donnée avec ruby dans le milieu, perl être un peu plus disponible par défaut ici est une alternative à l'aide de perl pour les lignes actuelles de l'auteur.
git ls-files -z | xargs -0n1 git blame -w | perl -n -e '/^.*\((.*?)\s*[\d]{4}/; print ,"\n"' | sort -f | uniq -c | sort -n
en plus de réponse de Charles Bailey , vous pouvez ajouter le paramètre -C aux commandes. Sinon fichier renomme compter que beaucoup d'ajouts et de suppressions (autant que le fichier contient des lignes), même si le contenu du fichier n'a pas été modifié.
pour illustrer, voici a commit avec beaucoup de fichiers déplacés autour d'un de mes projets, en utilisant la commande git log --oneline --shortstat :
9052459 Reorganized project structure
43 files changed, 1049 insertions(+), 1000 deletions(-)
et ici le même commit en utilisant la commande git log --oneline --shortstat -C qui détecte les copies de fichiers et les renommages:
9052459 Reorganized project structure
27 files changed, 134 insertions(+), 85 deletions(-)
à mon avis, ce dernier donne une vision plus réaliste de l'impact qu'une personne a eu sur le projet, parce que renommer un fichier est une opération beaucoup plus petite que d'écrire le fichier à partir de zéro.
voici un script ruby rapide qui corrige l'impact par utilisateur contre une requête log donnée.
par exemple, pour rubinius :
Brian Ford: 4410668
Evan Phoenix: 1906343
Ryan Davis: 855674
Shane Becker: 242904
Alexander Kellett: 167600
Eric Hodel: 132986
Dirkjan Bussink: 113756
...
le script:
#!/usr/bin/env ruby
impact = Hash.new(0)
IO.popen("git log --pretty=format:\"%an\" --shortstat #{ARGV.join(' ')}") do |f|
prev_line = ''
while line = f.gets
changes = /(\d+) insertions.*(\d+) deletions/.match(line)
if changes
impact[prev_line] += changes[1].to_i + changes[2].to_i
end
prev_line = line # Names are on a line of their own, just before the stats
end
end
impact.sort_by { |a,i| -i }.each do |author, impact|
puts "#{author.strip}: #{impact}"
end
j'ai fourni une modification d'une réponse courte ci-dessus, mais elle n'était pas suffisante pour mes besoins. J'avais besoin d'être capable de catégoriser à la fois les lignes engagées et les lignes dans le code final. Je voulais aussi une rupture par fichier. Ce code n'est pas récursif, il retournera seulement les résultats pour un seul répertoire, mais c'est un bon début si quelqu'un voulait aller plus loin. Copier et coller dans un fichier et de le rendre exécutable ou Perl.
#!/usr/bin/perl
use strict;
use warnings;
use Data::Dumper;
my $dir = shift;
die "Please provide a directory name to check\n"
unless $dir;
chdir $dir
or die "Failed to enter the specified directory '$dir': $!\n";
if ( ! open(GIT_LS,'-|','git ls-files') ) {
die "Failed to process 'git ls-files': $!\n";
}
my %stats;
while (my $file = <GIT_LS>) {
chomp $file;
if ( ! open(GIT_LOG,'-|',"git log --numstat $file") ) {
die "Failed to process 'git log --numstat $file': $!\n";
}
my $author;
while (my $log_line = <GIT_LOG>) {
if ( $log_line =~ m{^Author:\s*([^<]*?)\s*<([^>]*)>} ) {
$author = lc();
}
elsif ( $log_line =~ m{^(\d+)\s+(\d+)\s+(.*)} ) {
my $added = ;
my $removed = ;
my $file = ;
$stats{total}{by_author}{$author}{added} += $added;
$stats{total}{by_author}{$author}{removed} += $removed;
$stats{total}{by_author}{total}{added} += $added;
$stats{total}{by_author}{total}{removed} += $removed;
$stats{total}{by_file}{$file}{$author}{added} += $added;
$stats{total}{by_file}{$file}{$author}{removed} += $removed;
$stats{total}{by_file}{$file}{total}{added} += $added;
$stats{total}{by_file}{$file}{total}{removed} += $removed;
}
}
close GIT_LOG;
if ( ! open(GIT_BLAME,'-|',"git blame -w $file") ) {
die "Failed to process 'git blame -w $file': $!\n";
}
while (my $log_line = <GIT_BLAME>) {
if ( $log_line =~ m{\((.*?)\s+\d{4}} ) {
my $author = ;
$stats{final}{by_author}{$author} ++;
$stats{final}{by_file}{$file}{$author}++;
$stats{final}{by_author}{total} ++;
$stats{final}{by_file}{$file}{total} ++;
$stats{final}{by_file}{$file}{total} ++;
}
}
close GIT_BLAME;
}
close GIT_LS;
print "Total lines committed by author by file\n";
printf "%25s %25s %8s %8s %9s\n",'file','author','added','removed','pct add';
foreach my $file (sort keys %{$stats{total}{by_file}}) {
printf "%25s %4.0f%%\n",$file
,100*$stats{total}{by_file}{$file}{total}{added}/$stats{total}{by_author}{total}{added};
foreach my $author (sort keys %{$stats{total}{by_file}{$file}}) {
next if $author eq 'total';
if ( $stats{total}{by_file}{$file}{total}{added} ) {
printf "%25s %25s %8d %8d %8.0f%%\n",'', $author,@{$stats{total}{by_file}{$file}{$author}}{qw{added removed}}
,100*$stats{total}{by_file}{$file}{$author}{added}/$stats{total}{by_file}{$file}{total}{added};
} else {
printf "%25s %25s %8d %8d\n",'', $author,@{$stats{total}{by_file}{$file}{$author}}{qw{added removed}} ;
}
}
}
print "\n";
print "Total lines in the final project by author by file\n";
printf "%25s %25s %8s %9s %9s\n",'file','author','final','percent', '% of all';
foreach my $file (sort keys %{$stats{final}{by_file}}) {
printf "%25s %4.0f%%\n",$file
,100*$stats{final}{by_file}{$file}{total}/$stats{final}{by_author}{total};
foreach my $author (sort keys %{$stats{final}{by_file}{$file}}) {
next if $author eq 'total';
printf "%25s %25s %8d %8.0f%% %8.0f%%\n",'', $author,$stats{final}{by_file}{$file}{$author}
,100*$stats{final}{by_file}{$file}{$author}/$stats{final}{by_file}{$file}{total}
,100*$stats{final}{by_file}{$file}{$author}/$stats{final}{by_author}{total}
;
}
}
print "\n";
print "Total lines committed by author\n";
printf "%25s %8s %8s %9s\n",'author','added','removed','pct add';
foreach my $author (sort keys %{$stats{total}{by_author}}) {
next if $author eq 'total';
printf "%25s %8d %8d %8.0f%%\n",$author,@{$stats{total}{by_author}{$author}}{qw{added removed}}
,100*$stats{total}{by_author}{$author}{added}/$stats{total}{by_author}{total}{added};
};
print "\n";
print "Total lines in the final project by author\n";
printf "%25s %8s %9s\n",'author','final','percent';
foreach my $author (sort keys %{$stats{final}{by_author}}) {
printf "%25s %8d %8.0f%%\n",$author,$stats{final}{by_author}{$author}
,100*$stats{final}{by_author}{$author}/$stats{final}{by_author}{total};
}
c'est le meilleur moyen et il vous donne aussi une image claire du nombre total de commits par tout l'utilisateur
git shortlog -s -n
vous pouvez utiliser whodd ( https://www.npmjs.com/package/whodid )
$ npm install whodid -g
$ cd your-project-dir
et
$ whodid author --include-merge=false --path=./ --valid-threshold=1000 --since=1.week
ou il suffit de taper
$ whodid
alors vous pouvez voir le résultat comme ceci
Contribution state
=====================================================
score | author
-----------------------------------------------------
3059 | someguy <someguy@tensorflow.org>
585 | somelady <somelady@tensorflow.org>
212 | niceguy <nice@google.com>
173 | coolguy <coolgay@google.com>
=====================================================
ce script le fera. Mettre en authorship.sh chmod +x, et vous êtes tous ensemble.
#!/bin/sh
declare -A map
while read line; do
if grep "^[a-zA-Z]" <<< "$line" > /dev/null; then
current="$line"
if [ -z "${map[$current]}" ]; then
map[$current]=0
fi
elif grep "^[0-9]" <<<"$line" >/dev/null; then
for i in $(cut -f 1,2 <<< "$line"); do
map[$current]=$((map[$current] + $i))
done
fi
done <<< "$(git log --numstat --pretty="%aN")"
for i in "${!map[@]}"; do
echo -e "$i:${map[$i]}"
done | sort -nr -t ":" -k 2 | column -t -s ":"
Enregistrez vos journaux dans le fichier en utilisant:
git log --author="<authorname>" --oneline --shortstat > logs.txt
pour les amateurs de Python:
with open(r".\logs.txt", "r", encoding="utf8") as f:
files = insertions = deletions = 0
for line in f:
if ' changed' in line:
line = line.strip()
spl = line.split(', ')
if len(spl) > 0:
files += int(spl[0].split(' ')[0])
if len(spl) > 1:
insertions += int(spl[1].split(' ')[0])
if len(spl) > 2:
deletions += int(spl[2].split(' ')[0])
print(str(files).ljust(10) + ' files changed')
print(str(insertions).ljust(10) + ' insertions')
print(str(deletions).ljust(10) + ' deletions')
vos sorties seraient comme:
225 files changed
6751 insertions
1379 deletions
la question demandait de l'information sur un auteur spécifique , mais beaucoup de réponses étaient des solutions qui renvoyaient des listes classées d'auteurs en fonction de leurs lignes de code changées.
c'était Ce que je cherchais, mais les solutions existantes n'étaient pas tout à fait parfaite. Dans l'intérêt des personnes qui pourraient trouver cette question via Google, j'ai apporté quelques améliorations sur eux et les ai transformés en un script shell, que j'affiche ci-dessous. Annotée un (que je vais continuer à maintenir) peut être trouvé sur mon Github .
Il y a non les dépendances à Perl ou Ruby. De plus, les espaces, les renommages et les mouvements de ligne sont pris en compte dans le compte de changement de ligne. Mettez ceci dans un fichier et passez votre dépôt Git comme premier paramètre.
#!/bin/bash
git --git-dir="/.git" log > /dev/null 2> /dev/null
if [ $? -eq 128 ]
then
echo "Not a git repository!"
exit 128
else
echo -e "Lines | Name\nChanged|"
git --work-tree="" --git-dir="/.git" ls-files -z |\
xargs -0n1 git --work-tree="" --git-dir="/.git" blame -C -M -w |\
cut -d'(' -f2 |\
cut -d2 -f1 |\
sed -e "s/ \{1,\}$//" |\
sort |\
uniq -c |\
sort -nr
fi
le meilleur outil identifié jusqu'à présent est gitinspector. Il donne le rapport établi par utilisateur, par semaine, etc. Vous pouvez installer comme ci-dessous avec npm
npm install-g gitinspector
Les liens pour obtenir plus de détails
https://www.npmjs.com/package/gitinspector
https://github.com/ejwa/gitinspector/wiki/Documentation
https://github.com/ejwa/gitinspector
exemples de commandes:
gitinspector -lmrTw
gitinspector --since=1-1-2017 etc