Comment convertir une chaîne de caractères en minuscules, en Bash?
y a-t-il un moyen dans bash de convertir une chaîne en une chaîne minuscule?
par exemple, si j'ai:
a="Hi all"
je veux le convertir en:
"hi all"
19 réponses
Les différentes manières:
POSIX standard
tr
$ echo "$a" | tr '[:upper:]' '[:lower:]'
hi all
AWK
$ echo "$a" | awk '{print tolower("151910920")}'
hi all
Non-POSIX
vous pouvez rencontrer des problèmes de portabilité avec les exemples suivants:
Bash 4.0
$ echo "${a,,}"
hi all
sed
$ echo "$a" | sed -e 's/\(.*\)/\L/'
hi all
# this also works:
$ sed -e 's/\(.*\)/\L/' <<< "$a"
hi all
Perl
$ echo "$a" | perl -ne 'print lc'
hi all
Bash
lc(){
case "" in
[A-Z])
n=$(printf "%d" "'")
n=$((n+32))
printf \$(printf "%o" "$n")
;;
*)
printf "%s" ""
;;
esac
}
word="I Love Bash"
for((i=0;i<${#word};i++))
do
ch="${word:$i:1}"
lc "$ch"
done
In Bash 4:
en minuscules
$ string="A FEW WORDS"
$ echo "${string,}"
a FEW WORDS
$ echo "${string,,}"
a few words
$ echo "${string,,[AEIUO]}"
a FeW WoRDS
$ string="A Few Words"
$ declare -l string
$ string=$string; echo "$string"
a few words
en majuscule
$ string="a few words"
$ echo "${string^}"
A few words
$ echo "${string^^}"
A FEW WORDS
$ echo "${string^^[aeiou]}"
A fEw wOrds
$ string="A Few Words"
$ declare -u string
$ string=$string; echo "$string"
A FEW WORDS
bascule (non documenté, mais configurable au moment de la compilation)
$ string="A Few Words"
$ echo "${string~~}"
a fEW wORDS
$ string="A FEW WORDS"
$ echo "${string~}"
a FEW WORDS
$ string="a few words"
$ echo "${string~}"
A few words
capitaliser (non documenté, mais configurable en option au moment de la compilation)
$ string="a few words"
$ declare -c string
$ string=$string
$ echo "$string"
A few words
affaire de titre:
$ string="a few words"
$ string=($string)
$ string="${string[@]^}"
$ echo "$string"
A Few Words
$ declare -c string
$ string=(a few words)
$ echo "${string[@]}"
A Few Words
$ string="a FeW WOrdS"
$ string=${string,,}
$ string=${string~}
$ echo "$string"
A few words
pour désactiver un attribut declare , utiliser + . Par exemple, declare +c string . Cela a une incidence sur les affectations subséquentes et non sur la valeur actuelle.
les options declare changent l'attribut de la variable, mais pas le contenu. Les réaffectations dans mes exemples mettent à jour le contenu pour montrer les changements.
Edit:
a ajouté "bascule premier caractère par mot" ( ${var~} ) comme suggéré par ghostdog74 .
Edit: Corriged tilde behavior to match Bash 4.3.
tr :
a="$(tr [A-Z] [a-z] <<< "$a")"
AWK :
{ print tolower("151910920") }
sed :
y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/
je sais que c'est un post oldish mais j'ai fait cette réponse pour un autre site donc j'ai pensé que je le posterais ici:
supérieur - > inférieur : use python:
b=`echo "print '$a'.lower()" | python`
Ou Ruby:
b=`echo "print '$a'.downcase" | ruby`
Ou Perl (probablement mon préféré):
b=`perl -e "print lc('$a');"`
ou PHP:
b=`php -r "print strtolower('$a');"`
Ou Awk:
b=`echo "$a" | awk '{ print tolower() }'`
Ou Sed:
b=`echo "$a" | sed 's/./\L&/g'`
Ou Bash 4:
b=${a,,}
Ou NodeJS si vous en avez un (et un peu de noix...):
b=`echo "console.log('$a'.toLowerCase());" | node`
vous pouvez aussi utiliser dd (mais je ne le ferais pas!):
b=`echo "$a" | dd conv=lcase 2> /dev/null`
inférieur - > supérieur :
utiliser python:
b=`echo "print '$a'.upper()" | python`
Ou Ruby:
b=`echo "print '$a'.upcase" | ruby`
ou Perl (probablement mon favori):
b=`perl -e "print uc('$a');"`
ou PHP:
b=`php -r "print strtoupper('$a');"`
Ou Awk:
b=`echo "$a" | awk '{ print toupper() }'`
Ou Sed:
b=`echo "$a" | sed 's/./\U&/g'`
Ou Bash 4:
b=${a^^}
Ou NodeJS si vous en avez un (et un peu de noix...):
b=`echo "console.log('$a'.toUpperCase());" | node`
vous pouvez aussi utiliser dd (mais je ne le ferais pas!):
b=`echo "$a" | dd conv=ucase 2> /dev/null`
aussi quand vous dites "shell" je suis en supposant que vous voulez dire bash mais si vous pouvez utiliser zsh c'est aussi simple que
b=$a:l
pour les minuscules et
b=$a:u
pour majuscule.
utilisant GNU sed :
sed 's/.*/\L&/'
exemple:
$ foo="Some STRIng";
$ foo=$(echo "$foo" | sed 's/.*/\L&/')
$ echo "$foo"
some string
pour un shell standard (sans bashismes) utilisant uniquement des builtins:
uppers=ABCDEFGHIJKLMNOPQRSTUVWXYZ
lowers=abcdefghijklmnopqrstuvwxyz
lc(){ #usage: lc "SOME STRING" -> "some string"
i=0
while ([ $i -lt ${#1} ]) do
CUR=${1:$i:1}
case $uppers in
*$CUR*)CUR=${uppers%$CUR*};OUTPUT="${OUTPUT}${lowers:${#CUR}:1}";;
*)OUTPUT="${OUTPUT}$CUR";;
esac
i=$((i+1))
done
echo "${OUTPUT}"
}
et pour la majuscule:
uc(){ #usage: uc "some string" -> "SOME STRING"
i=0
while ([ $i -lt ${#1} ]) do
CUR=${1:$i:1}
case $lowers in
*$CUR*)CUR=${lowers%$CUR*};OUTPUT="${OUTPUT}${uppers:${#CUR}:1}";;
*)OUTPUT="${OUTPUT}$CUR";;
esac
i=$((i+1))
done
echo "${OUTPUT}"
}
Pre Bash 4.0
Bash abaisser le cas d'une chaîne et attribuer à la variable
VARIABLE=$(echo "$VARIABLE" | tr '[:upper:]' '[:lower:]')
echo "$VARIABLE"
expression Régulière
je voudrais m'attribuer le mérite de l'ordre que je veux partager mais la vérité est que je l'ai obtenu pour mon propre usage de http://commandlinefu.com . Il a l'avantage que si vous cd à n'importe quel répertoire dans votre propre dossier d'accueil qui est il va changer tous les dossiers et les dossiers pour les cas inférieurs récursivement s'il vous plaît utiliser avec prudence. C'est une solution de ligne de commande brillante et particulièrement utile pour ces multitudes d'albums vous avez stockées sur votre disque.
find . -depth -exec rename 's/(.*)\/([^\/]*)/\/\L/' {} \;
vous pouvez spécifier un répertoire à la place du point(.) après la find qui indique répertoire courant ou chemin complet.
j'espère que cette solution se révèle utile la seule chose que cette commande ne fait pas est de remplacer les espaces par des underscores - Oh bien une autre fois peut-être.
dans bash 4, Vous pouvez utiliser la typographie
exemple:
A="HELLO WORLD"
typeset -l A=$A
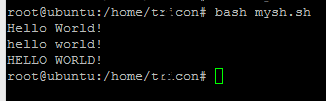
vous pouvez essayer ceci
s="Hello World!"
echo $s # Hello World!
a=${s,,}
echo $a # hello world!
b=${s^^}
echo $b # HELLO WORLD!
ref : http://wiki.workassis.com/shell-script-convert-text-to-lowercase-and-uppercase /
si vous utilisez v4, c'est cuit-dans . Si non, voici une solution simple, largement applicable . D'autres réponses (et commentaires) sur ce fil ont été très utiles pour créer le code ci-dessous.
# Like echo, but converts to lowercase
echolcase () {
tr [:upper:] [:lower:] <<< "${*}"
}
# Takes one arg by reference (var name) and makes it lowercase
lcase () {
eval ""=\'$(echo ${!1//\'/"'\''"} | tr [:upper:] [:lower:] )\'
}
Notes:
- faire:
a="Hi All"et puis:lcase afera la même chose que:a=$( echolcase "Hi All" ) - dans la mallette fonction, en utilisant
${!1//\'/"'\''"}au lieu de${!1}permet à cela de fonctionner même lorsque la chaîne a des guillemets.
pour les versions de Bash antérieures à 4.0, cette version devrait être la plus rapide (comme elle ne l'est pas fork / exec any commands):
function string.monolithic.tolower
{
local __word=
local __len=${#__word}
local __char
local __octal
local __decimal
local __result
for (( i=0; i<__len; i++ ))
do
__char=${__word:$i:1}
case "$__char" in
[A-Z] )
printf -v __decimal '%d' "'$__char"
printf -v __octal '%03o' $(( $__decimal ^ 0x20 ))
printf -v __char \$__octal
;;
esac
__result+="$__char"
done
REPLY="$__result"
}
la réponse de technosaurus avait aussi du potentiel, bien qu'elle ait fonctionné correctement pour mee.
malgré l'âge de cette question et similaire à cette réponse par technosaurus . J'ai eu du mal à trouver une solution portable sur la plupart des plateformes (que j'utilise) ainsi que sur les anciennes versions de bash. J'ai également été frustré par les tableaux, les fonctions et l'utilisation d'empreintes, d'échos et de fichiers temporaires pour récupérer des variables triviales. Cela fonctionne très bien pour moi jusqu'à présent j'ai pensé que je partagerais. Mes principaux environnements de test sont:
- GNU bash, version 4.1.2 (1)-release (x86_64-redhat-linux-gnu)
- GNU bash, version 3.2.57 (1)-release (sparc-sun-solaris2.10)
lcs="abcdefghijklmnopqrstuvwxyz"
ucs="ABCDEFGHIJKLMNOPQRSTUVWXYZ"
input="Change Me To All Capitals"
for (( i=0; i<"${#input}"; i++ )) ; do :
for (( j=0; j<"${#lcs}"; j++ )) ; do :
if [[ "${input:$i:1}" == "${lcs:$j:1}" ]] ; then
input="${input/${input:$i:1}/${ucs:$j:1}}"
fi
done
done
Simple style C pour la boucle pour itérer sur les cordes. Pour la ligne ci-dessous si vous n'avez pas vu quelque chose comme ça avant c'est ici que j'ai appris ce . Dans ce cas, la ligne vérifie si le caractère ${entrée:$i:1} (minuscules) existe dans l'entrée et, si oui, remplace le char ${ucs:$j:1} (majuscules) et les stocke en arrière dans l'entrée.
input="${input/${input:$i:1}/${ucs:$j:1}}"
beaucoup de réponses utilisant des programmes externes, ce qui n'est pas vraiment utiliser Bash .
si vous savez que vous aurez Bash4 disponible, vous devez vraiment utiliser la notation ${VAR,,} (c'est facile et cool). Pour Bash avant 4 (Mon Mac utilise encore Bash 3.2 par exemple). J'ai utilisé la version corrigée de la réponse de @ghostdog74 pour créer une version plus portable.
vous pouvez appeler lowercase 'my STRING' et obtenir une version en minuscules. J'ai lu les commentaires sur le réglage du résultat à un var, mais ce n'est pas vraiment portable dans Bash , puisque nous ne pouvons pas retourner les cordes. L'impression c'est la meilleure solution. Facile à capturer avec quelque chose comme var="$(lowercase $str)" .
comment cela fonctionne
la façon dont cela fonctionne est en obtenant la représentation ASCII entier de chaque char avec printf et puis adding 32 si upper-to->lower , ou subtracting 32 si lower-to->upper . Ensuite, utilisez printf encore une fois pour convertir le nombre de nouveau à un char. De 'A' -to-> 'a' nous avons une différence de 32 caractères.
utilisant printf pour expliquer:
$ printf "%d\n" "'a"
97
$ printf "%d\n" "'A"
65
97 - 65 = 32
et ceci est la version de travail avec des exemples.
S'il vous plaît noter les commentaires dans le code, car ils expliquent beaucoup de choses:
#!/bin/bash
# lowerupper.sh
# Prints the lowercase version of a char
lowercaseChar(){
case "" in
[A-Z])
n=$(printf "%d" "'")
n=$((n+32))
printf \$(printf "%o" "$n")
;;
*)
printf "%s" ""
;;
esac
}
# Prints the lowercase version of a sequence of strings
lowercase() {
word="$@"
for((i=0;i<${#word};i++)); do
ch="${word:$i:1}"
lowercaseChar "$ch"
done
}
# Prints the uppercase version of a char
uppercaseChar(){
case "" in
[a-z])
n=$(printf "%d" "'")
n=$((n-32))
printf \$(printf "%o" "$n")
;;
*)
printf "%s" ""
;;
esac
}
# Prints the uppercase version of a sequence of strings
uppercase() {
word="$@"
for((i=0;i<${#word};i++)); do
ch="${word:$i:1}"
uppercaseChar "$ch"
done
}
# The functions will not add a new line, so use echo or
# append it if you want a new line after printing
# Printing stuff directly
lowercase "I AM the Walrus!"$'\n'
uppercase "I AM the Walrus!"$'\n'
echo "----------"
# Printing a var
str="A StRing WITH mixed sTUFF!"
lowercase "$str"$'\n'
uppercase "$str"$'\n'
echo "----------"
# Not quoting the var should also work,
# since we use "$@" inside the functions
lowercase $str$'\n'
uppercase $str$'\n'
echo "----------"
# Assigning to a var
myLowerVar="$(lowercase $str)"
myUpperVar="$(uppercase $str)"
echo "myLowerVar: $myLowerVar"
echo "myUpperVar: $myUpperVar"
echo "----------"
# You can even do stuff like
if [[ 'option 2' = "$(lowercase 'OPTION 2')" ]]; then
echo "Fine! All the same!"
else
echo "Ops! Not the same!"
fi
exit 0
et les résultats après avoir exécuté ceci:
$ ./lowerupper.sh
i am the walrus!
I AM THE WALRUS!
----------
a string with mixed stuff!
A STRING WITH MIXED STUFF!
----------
a string with mixed stuff!
A STRING WITH MIXED STUFF!
----------
myLowerVar: a string with mixed stuff!
myUpperVar: A STRING WITH MIXED STUFF!
----------
Fine! All the same!
cela ne devrait fonctionner que pour les caractères ASCII bien que .
pour moi, c'est très bien, puisque je sais que je ne lui passerai que des chars ASCII.
Je l'utilise pour certaines options CLI non sensibles à la casse, par exemple.
cas de conversion est fait pour les alphabets seulement. Donc, cela devrait fonctionner parfaitement.
je me concentre sur la conversion des alphabets entre a-z de majuscules en minuscules. Tous les autres caractères devraient être simplement imprimés en stdout comme il est...
Convertit tout le texte dans le chemin / vers / file/filename dans la plage de A-z à A-Z
pour la conversion de minuscules en majuscules
cat path/to/file/filename | tr 'a-z' 'A-Z'
pour la conversion de la majuscule à la minuscule
cat path/to/file/filename | tr 'A-Z' 'a-z'
par exemple,
nom du fichier:
my name is xyz
est converti en:
MY NAME IS XYZ
exemple 2:
echo "my name is 123 karthik" | tr 'a-z' 'A-Z'
# Output:
# MY NAME IS 123 KARTHIK
exemple 3:
echo "my name is 123 &&^&& #@$#@%%& kAR2~thik" | tr 'a-z' 'A-Z'
# Output:
# MY NAME IS 123 &&^&& #@0@%%& KAR2~THIK
pour stocker la chaîne transformée en une variable. Les suivants ont travaillé pour moi -
$SOURCE_NAME à $TARGET_NAME
TARGET_NAME="`echo $SOURCE_NAME | tr '[:upper:]' '[:lower:]'`"
il s'agit d'une variation beaucoup plus rapide de l'approche de JaredTS486 qui utilise des capacités Bash natives (y compris les versions Bash <4.0) pour optimiser son approche.
j'ai chronométré 1000 itérations de cette approche pour une petite chaîne (25 caractères) et une plus grande chaîne (445 caractères), à la fois pour les conversions en minuscules et en majuscules. Étant donné que les chaînes de test sont principalement en minuscules, les conversions en minuscules sont généralement plus rapides qu'en majuscules.
j'ai comparé mon approche avec plusieurs autres réponses sur cette page qui sont compatibles avec Bash 3.2. Mon approche est beaucoup plus performante que la plupart des approches décrites ici, et est même plus rapide que tr dans plusieurs cas.
Voici les résultats de temps pour 1000 itérations de 25 caractères:
- 0,46 s pour mon approche à la base; 0,96 s pour la base
- 1,16 s pour Orwellophile de l'approche en lettres minuscules; 1.59 s pour la majuscule
- 3,67 s pour
tren minuscules; 3,81 s pour majuscules - 11.12 s pour ghostdog74 de l'approche en lettres minuscules; 31.41 s pour la majuscule
- de 26,25 s pour technosaurus' approche en lettres minuscules; 26.21 s pour la majuscule
- 25.06 s pour l'approche de JaredTS486 en minuscules; 27.04 s en majuscules
Calendrier résultats pour 1000 itérations de 445 caractères (composé du poème "Les Robin" par Witter Bynner):
- 2s pour mon approche de minuscules; 12 pour les majuscules
- 4s pour
trà minuscule; 4s pour majuscule - 20 " pour Orwellophile de l'approche en lettres minuscules; 29s pour la majuscule
- 75s pour ghostdog74 approche de minuscules; 669s pour la majuscule. Il est intéressant de noter à quel point la différence de performance est dramatique entre un test avec des correspondances prédominantes et un test avec des erreurs prédominantes
- 467s pour technosaurus' approche en lettres minuscules; 449s pour la majuscule
- 660s pour l'approche de JaredTS486 à faible base; 660s pour majuscule. Il est intéressant de noter que cette approche a généré des défauts de page continus (échange de mémoire) dans Bash
Solution:
#!/bin/bash
set -e
set -u
declare LCS="abcdefghijklmnopqrstuvwxyz"
declare UCS="ABCDEFGHIJKLMNOPQRSTUVWXYZ"
function lcase()
{
local TARGET="${1-}"
local UCHAR=''
local UOFFSET=''
while [[ "${TARGET}" =~ ([A-Z]) ]]
do
UCHAR="${BASH_REMATCH[1]}"
UOFFSET="${UCS%%${UCHAR}*}"
TARGET="${TARGET//${UCHAR}/${LCS:${#UOFFSET}:1}}"
done
echo -n "${TARGET}"
}
function ucase()
{
local TARGET="${1-}"
local LCHAR=''
local LOFFSET=''
while [[ "${TARGET}" =~ ([a-z]) ]]
do
LCHAR="${BASH_REMATCH[1]}"
LOFFSET="${LCS%%${LCHAR}*}"
TARGET="${TARGET//${LCHAR}/${UCS:${#LOFFSET}:1}}"
done
echo -n "${TARGET}"
}
l'approche est simple: alors que la chaîne de caractères contient les majuscules restantes, trouvez la suivante et remplacez toutes les instances de cette lettre par sa variante en minuscules. Répéter jusqu'à ce que toutes les lettres majuscules soient remplacées.
quelques caractéristiques de performance de ma solution:
- N'utilise que des utilitaires de construction shell, ce qui évite la surcharge d'invoquer des utilitaires binaires externes dans un nouveau processus
- évite les sous-coquilles, qui entraînent des pénalités de performance
- utilise des mécanismes shell qui sont compilés et optimisés pour la performance, tels que le remplacement global de la chaîne dans les variables, le découpage du suffixe variable, et la recherche et l'appariement regex. Ces mécanismes sont beaucoup plus rapides que itérer manuellement à travers des chaînes
- les Boucles que le nombre de fois requis par le comte de unique de caractères à convertir. Par exemple, convertir une chaîne qui a trois caractères majuscules différents en minuscules ne nécessite que trois itérations de boucle. Pour l'alphabet ASCII préconfiguré, le nombre maximum d'itérations de boucle est de 26
-
UCSetLCSpeuvent être complétés par des caractères supplémentaires