Comment savoir si une chaîne se répète en Python?
je cherche un moyen de tester si une chaîne donnée se répète pour la chaîne entière ou non.
exemples:
[
'0045662100456621004566210045662100456621', # '00456621'
'0072992700729927007299270072992700729927', # '00729927'
'001443001443001443001443001443001443001443', # '001443'
'037037037037037037037037037037037037037037037', # '037'
'047619047619047619047619047619047619047619', # '047619'
'002457002457002457002457002457002457002457', # '002457'
'001221001221001221001221001221001221001221', # '001221'
'001230012300123001230012300123001230012300123', # '00123'
'0013947001394700139470013947001394700139470013947', # '0013947'
'001001001001001001001001001001001001001001001001001', # '001'
'001406469760900140646976090014064697609', # '0014064697609'
]
sont des cordes qui se répètent, et
[
'004608294930875576036866359447',
'00469483568075117370892018779342723',
'004739336492890995260663507109',
'001508295625942684766214177978883861236802413273',
'007518796992481203',
'0071942446043165467625899280575539568345323741',
'0434782608695652173913',
'0344827586206896551724137931',
'002481389578163771712158808933',
'002932551319648093841642228739',
'0035587188612099644128113879',
'003484320557491289198606271777',
'00115074798619102416570771',
]
sont des exemples de ceux qui ne le font pas.
les sections répétitives des cordes que je reçois peuvent être assez longues, et les cordes elles-mêmes peuvent être 500 caractères ou plus, donc en boucle à travers chaque caractère essayer de construire un modèle, puis de vérifier le modèle vs le reste de la chaîne semble terrible lent. Multiplie ça par des centaines de chaînes et je ne vois pas de solution intuitive.
j'ai regardé dans regexes un peu et ils semblent bons pour quand vous savez ce que vous cherchez, ou au moins la longueur du modèle que vous recherchez. Malheureusement, je ne sais ni.
Comment puis-je dire si une chaîne se répète et si elle est, ce qui la plus courte répétition est?
13 réponses
Voici une solution concise qui évite les expressions régulières et les boucles in-Python lentes:
def principal_period(s):
i = (s+s).find(s, 1, -1)
return None if i == -1 else s[:i]
voir la Community Wiki answer commencé par @davidism pour les résultats de référence. En résumé,
la solution de David Zhang est la gagnante évidente, surpassant tous les autres d'au moins 5 fois pour le grand jeu d'exemples.
(ce sont les mots de cette réponse, pas les miens.)
ceci est basé sur l'observation qu'une chaîne est périodique si et seulement si elle est égale à une rotation non triviale de lui-même. Félicitations à @AleksiTorhamo pour avoir réalisé que nous pouvons alors récupérer la période principale à partir de l'index de la première occurrence de s dans (s+s)[1:-1] , et pour m'avoir informé des arguments optionnels start et end de Python string.find .
Voici une solution utilisant des expressions régulières.
import re
REPEATER = re.compile(r"(.+?)+$")
def repeated(s):
match = REPEATER.match(s)
return match.group(1) if match else None
Itération sur les exemples de la question:
examples = [
'0045662100456621004566210045662100456621',
'0072992700729927007299270072992700729927',
'001443001443001443001443001443001443001443',
'037037037037037037037037037037037037037037037',
'047619047619047619047619047619047619047619',
'002457002457002457002457002457002457002457',
'001221001221001221001221001221001221001221',
'001230012300123001230012300123001230012300123',
'0013947001394700139470013947001394700139470013947',
'001001001001001001001001001001001001001001001001001',
'001406469760900140646976090014064697609',
'004608294930875576036866359447',
'00469483568075117370892018779342723',
'004739336492890995260663507109',
'001508295625942684766214177978883861236802413273',
'007518796992481203',
'0071942446043165467625899280575539568345323741',
'0434782608695652173913',
'0344827586206896551724137931',
'002481389578163771712158808933',
'002932551319648093841642228739',
'0035587188612099644128113879',
'003484320557491289198606271777',
'00115074798619102416570771',
]
for e in examples:
sub = repeated(e)
if sub:
print("%r: %r" % (e, sub))
else:
print("%r does not repeat." % e)
... produit cette sortie:
'0045662100456621004566210045662100456621': '00456621'
'0072992700729927007299270072992700729927': '00729927'
'001443001443001443001443001443001443001443': '001443'
'037037037037037037037037037037037037037037037': '037'
'047619047619047619047619047619047619047619': '047619'
'002457002457002457002457002457002457002457': '002457'
'001221001221001221001221001221001221001221': '001221'
'001230012300123001230012300123001230012300123': '00123'
'0013947001394700139470013947001394700139470013947': '0013947'
'001001001001001001001001001001001001001001001001001': '001'
'001406469760900140646976090014064697609': '0014064697609'
'004608294930875576036866359447' does not repeat.
'00469483568075117370892018779342723' does not repeat.
'004739336492890995260663507109' does not repeat.
'001508295625942684766214177978883861236802413273' does not repeat.
'007518796992481203' does not repeat.
'0071942446043165467625899280575539568345323741' does not repeat.
'0434782608695652173913' does not repeat.
'0344827586206896551724137931' does not repeat.
'002481389578163771712158808933' does not repeat.
'002932551319648093841642228739' does not repeat.
'0035587188612099644128113879' does not repeat.
'003484320557491289198606271777' does not repeat.
'00115074798619102416570771' does not repeat.
l'expression régulière (.+?)+$ est divisée en trois parties:
-
(.+?)est un groupe apparenté contenant au moins un (mais aussi peu que possible) de n'importe quel caractère (parce que+?est le non-greedy ). -
+vérifie au moins une répétition du groupe correspondant dans la première partie. -
$vérifie la fin de la chaîne, pour s'assurer qu'il n'y a pas de contenu supplémentaire non répétitif après les substrats répétés (et en utilisantre.match()assure qu'il n'y a pas de texte non répétitif avant les substrats répétés).
en Python 3.4 et plus tard, vous pouvez laisser tomber le $ et utiliser re.fullmatch() à la place, ou (dans n'importe quel Python au moins aussi loin que 2.3) aller dans l'autre sens et utiliser re.search() avec le regex ^(.+?)+$ , qui sont tous plus bas au goût personnel que n'importe quoi d'autre.
vous pouvez faire l'observation que pour qu'une chaîne de caractères soit considérée comme se répétant, sa longueur doit être divisible par la longueur de sa séquence répétée. Étant donné que, voici une solution qui génère des diviseurs de la longueur de 1 à n / 2 inclusivement, divise la chaîne originale en substrats avec la longueur des diviseurs, et teste l'égalité de l'ensemble de résultats:
from math import sqrt, floor
def divquot(n):
if n > 1:
yield 1, n
swapped = []
for d in range(2, int(floor(sqrt(n))) + 1):
q, r = divmod(n, d)
if r == 0:
yield d, q
swapped.append((q, d))
while swapped:
yield swapped.pop()
def repeats(s):
n = len(s)
for d, q in divquot(n):
sl = s[0:d]
if sl * q == s:
return sl
return None
EDIT: En Python 3, le L'opérateur / a changé pour faire la division float par défaut. Pour obtenir la division int de Python 2, Vous pouvez utiliser l'opérateur // à la place. Merci à @TigerhawkT3 d'avoir porté cette question à mon attention.
l'opérateur // exécute la division entière en Python 2 et en Python 3, j'ai donc mis à jour la réponse pour prendre en charge les deux versions. La partie où nous testons pour voir si tous les substrats sont égaux est maintenant une opération de court-circuitage en utilisant all et une expression de générateur.
mise à JOUR: En réponse à un changement dans la question d'origine, le code a été mis à jour à renvoyer le plus petit de répéter sous-chaîne si elle existe et None si il ne le fait pas. @godlygeek a suggéré d'utiliser divmod pour réduire le nombre d'itérations sur les divisors générateur, et le code a été mis à jour pour correspondre à cela. Il retourne maintenant tous les diviseurs positifs de n dans l'ordre croissant, à l'exclusion de n lui-même.
nouvelle mise à jour pour haute performance: après plusieurs tests, je suis arrivé à la conclusion que le simple fait de tester pour l'égalité des cordes a la meilleure performance de n'importe quelle solution de tranchage ou d'itérateur en Python. Ainsi, j'ai pris une feuille du livre de @TigerhawkT3 et mis à jour ma solution. Il est maintenant plus de 6x aussi rapide qu'avant, remarquablement plus rapide que la solution de Tigerhawk mais plus lent que David.
Voici quelques repères pour les différentes réponses à cette question. Il y a eu des résultats surprenants, y compris des performances très différentes selon la corde testée.
certaines fonctions ont été modifiées pour fonctionner avec Python 3 (principalement en remplaçant / par // pour assurer la division entière). Si vous voyez quelque chose qui ne va pas, vous voulez ajouter votre fonction, ou vous voulez ajouter une autre chaîne de test, ping @ZeroPiraeus dans le Python chat .
en résumé: il y a environ 50x de différence entre les solutions les plus performantes et les moins performantes pour le grand ensemble de données d'exemple fournies par L'OP ici (via ce commentaire ). la solution de David Zhang est la gagnante évidente, surpassant tous les autres par environ 5x pour le grand ensemble d'exemples.
quelques-unes des réponses sont très lent en très grande "aucun match" des cas. Dans le cas contraire, les fonctions semblent être également appariées ou des gagnants clairs selon le test.
Voici les résultats, y compris les placettes faites en utilisant matplotlib et seaborn pour montrer les différentes distributions:
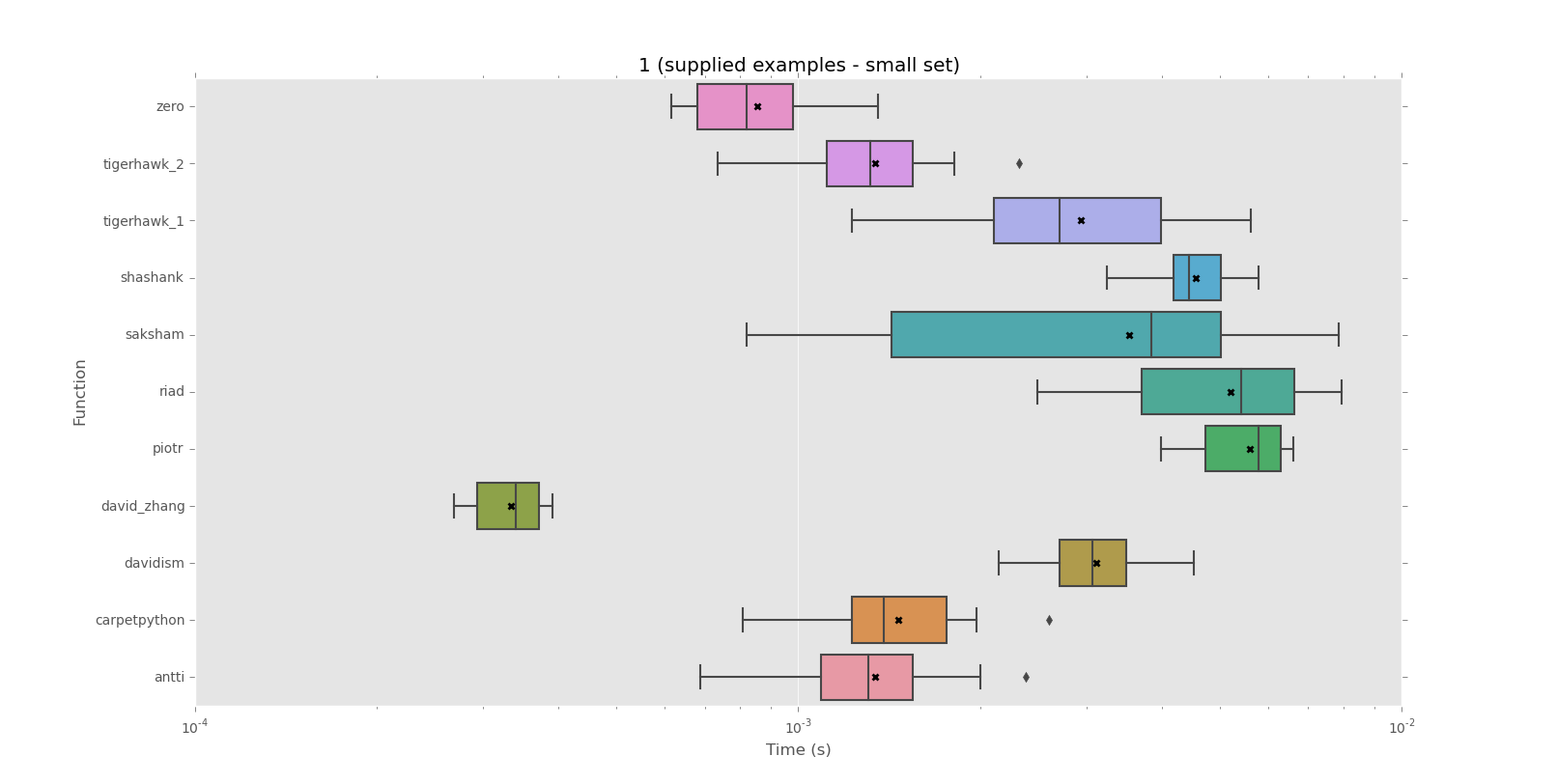
Corpus 1 (exemples fournis - petit ensemble)
mean performance:
0.0003 david_zhang
0.0009 zero
0.0013 antti
0.0013 tigerhawk_2
0.0015 carpetpython
0.0029 tigerhawk_1
0.0031 davidism
0.0035 saksham
0.0046 shashank
0.0052 riad
0.0056 piotr
median performance:
0.0003 david_zhang
0.0008 zero
0.0013 antti
0.0013 tigerhawk_2
0.0014 carpetpython
0.0027 tigerhawk_1
0.0031 davidism
0.0038 saksham
0.0044 shashank
0.0054 riad
0.0058 piotr
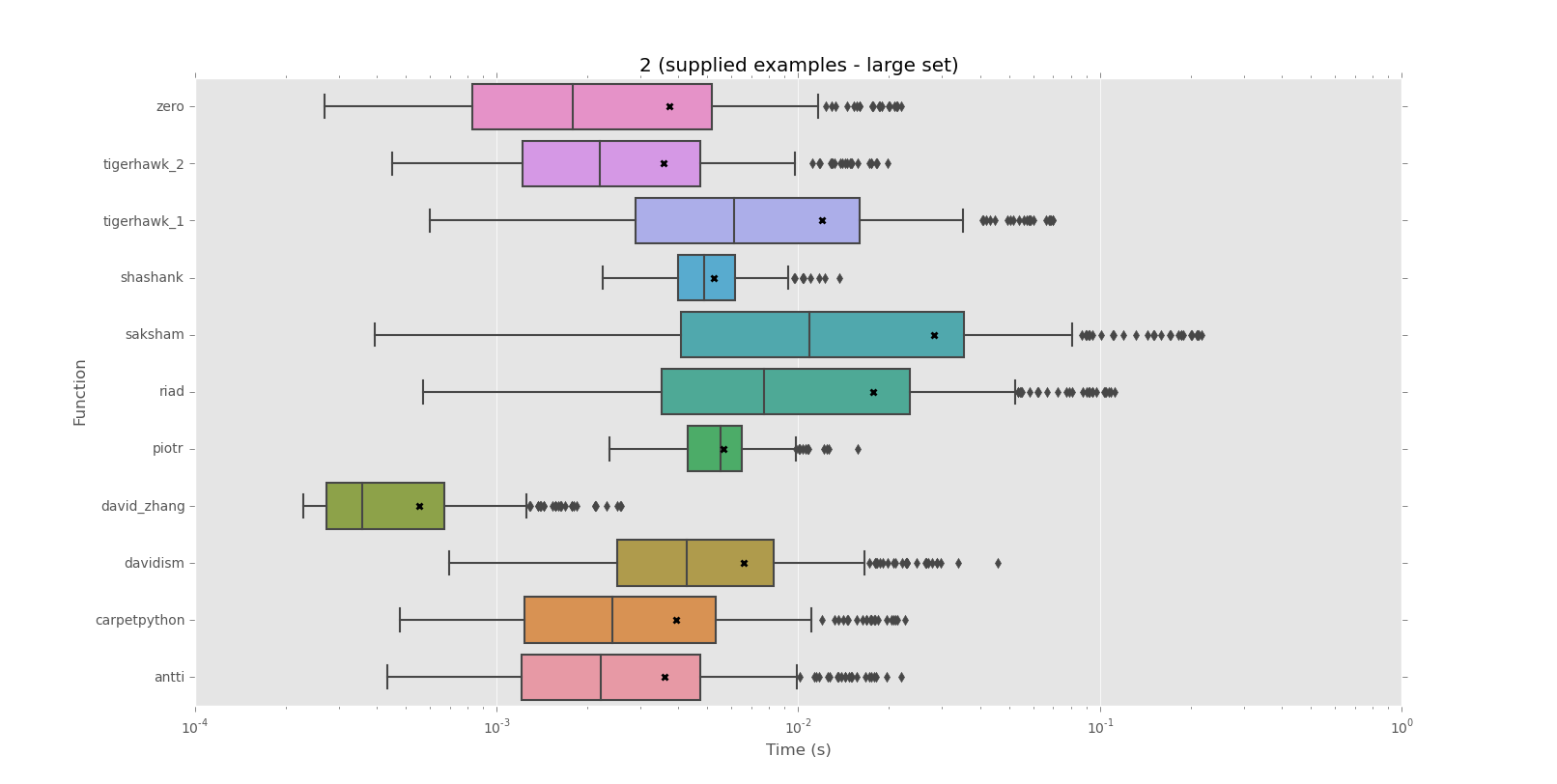
Corpus 2 (exemples fournis-large set)
mean performance:
0.0006 david_zhang
0.0036 tigerhawk_2
0.0036 antti
0.0037 zero
0.0039 carpetpython
0.0052 shashank
0.0056 piotr
0.0066 davidism
0.0120 tigerhawk_1
0.0177 riad
0.0283 saksham
median performance:
0.0004 david_zhang
0.0018 zero
0.0022 tigerhawk_2
0.0022 antti
0.0024 carpetpython
0.0043 davidism
0.0049 shashank
0.0055 piotr
0.0061 tigerhawk_1
0.0077 riad
0.0109 saksham
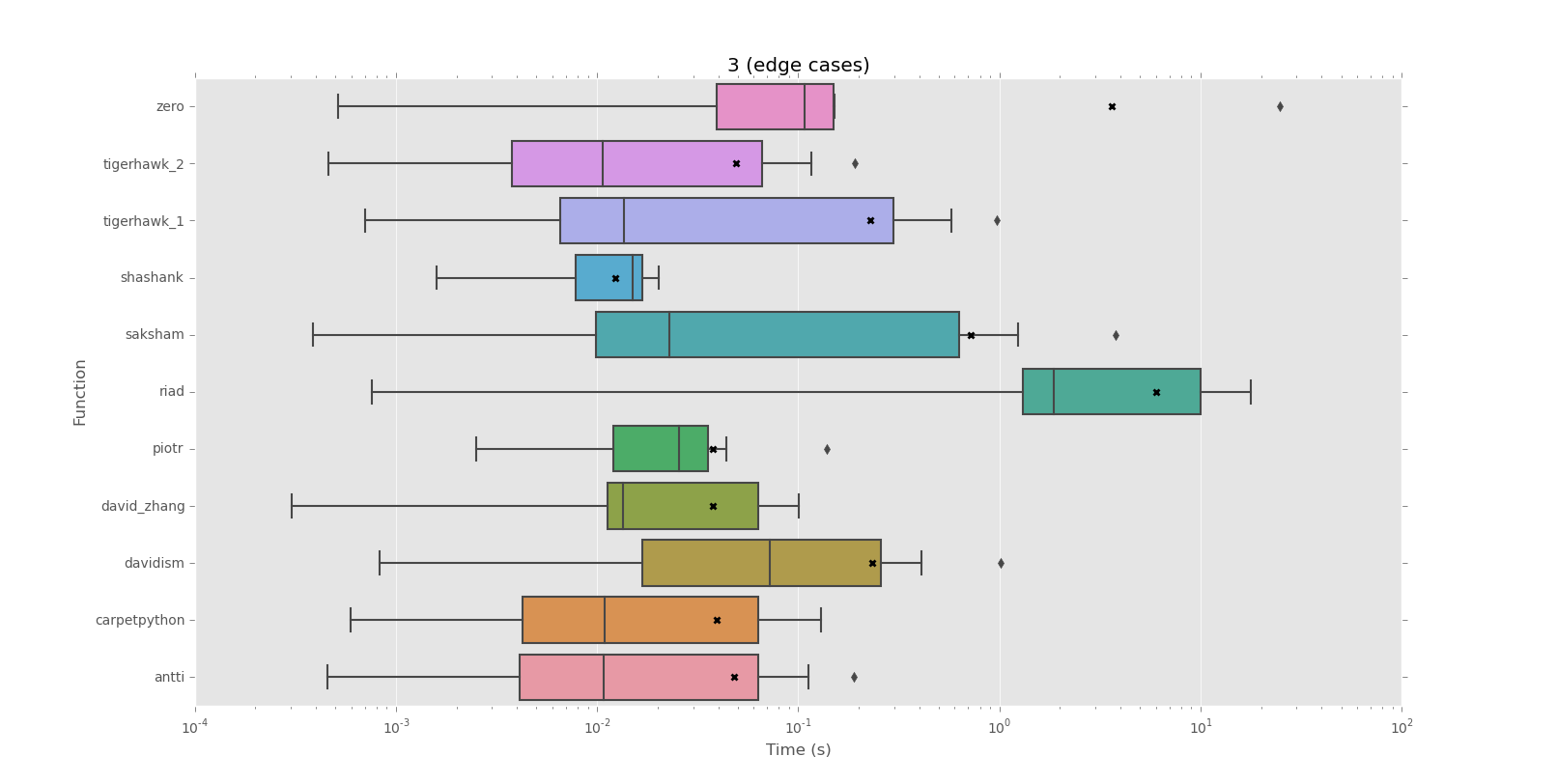
Corpus 3 (cas)
mean performance:
0.0123 shashank
0.0375 david_zhang
0.0376 piotr
0.0394 carpetpython
0.0479 antti
0.0488 tigerhawk_2
0.2269 tigerhawk_1
0.2336 davidism
0.7239 saksham
3.6265 zero
6.0111 riad
median performance:
0.0107 tigerhawk_2
0.0108 antti
0.0109 carpetpython
0.0135 david_zhang
0.0137 tigerhawk_1
0.0150 shashank
0.0229 saksham
0.0255 piotr
0.0721 davidism
0.1080 zero
1.8539 riad
les tests et les résultats bruts sont disponible ici .
Non-regex solution:
def repeat(string):
for i in range(1, len(string)//2+1):
if not len(string)%len(string[0:i]) and string[0:i]*(len(string)//len(string[0:i])) == string:
return string[0:i]
solution non regex plus rapide, grâce à @ThatWeirdo (voir les commentaires):
def repeat(string):
l = len(string)
for i in range(1, len(string)//2+1):
if l%i: continue
s = string[0:i]
if s*(l//i) == string:
return s
la solution ci - dessus est très rarement plus lente que l'originale de quelques pour cent, mais il est généralement un bon peu plus rapide-parfois beaucoup plus rapide. Il n'est toujours pas plus rapide que celui de davidism pour les cordes plus longues, et la solution regex de zero est supérieure pour les cordes courtes. Elle est la plus rapide (selon davidism test sur github-voir sa réponse) avec des cordes d'environ 1000-1500 caractères. Quoi qu'il en soit, il est fiable deuxième plus rapide (ou mieux) dans tous les cas que j'ai testé. Merci, ThatWeirdo.
Test:
print(repeat('009009009'))
print(repeat('254725472547'))
print(repeat('abcdeabcdeabcdeabcde'))
print(repeat('abcdefg'))
print(repeat('09099099909999'))
print(repeat('02589675192'))
Résultats:
009
2547
abcde
None
None
None
d'abord, couper la chaîne de caractères en deux tant que c'est un duplicata "2 parties". Cela réduit l'espace de recherche s'il y a un nombre pair de répétitions. Ensuite, en travaillant vers l'avant pour trouver la plus petite chaîne répétitive, vérifiez si séparer la chaîne complète par des sous-chaînes de plus en plus grandes ne donne que des valeurs vides. Seules les sous-chaînes jusqu'à length // 2 ont besoin d'être testées car tout ce qui est au-dessus n'aurait pas de répétitions.
def shortest_repeat(orig_value):
if not orig_value:
return None
value = orig_value
while True:
len_half = len(value) // 2
first_half = value[:len_half]
if first_half != value[len_half:]:
break
value = first_half
len_value = len(value)
split = value.split
for i in (i for i in range(1, len_value // 2) if len_value % i == 0):
if not any(split(value[:i])):
return value[:i]
return value if value != orig_value else None
renvoie la correspondance la plus courte ou None si il n'y a pas de match.
le problème peut aussi être résolu dans O(n) dans le pire des cas avec la fonction de préfixe.
notez, il peut être plus lent dans le cas général (UPD: et est beaucoup plus lent) que d'autres solutions qui dépendent du nombre de diviseurs de n , mais trouvent généralement échoue plus tôt, je pense que l'un des mauvais cas pour eux sera aaa....aab , où il ya n - 1 = 2 * 3 * 5 * 7 ... *p_n - 1 a 's
tout D'abord vous avez besoin de calculer la fonction de préfixe
def prefix_function(s):
n = len(s)
pi = [0] * n
for i in xrange(1, n):
j = pi[i - 1]
while(j > 0 and s[i] != s[j]):
j = pi[j - 1]
if (s[i] == s[j]):
j += 1
pi[i] = j;
return pi
alors soit il n'y a pas de réponse, soit la période la plus courte est
k = len(s) - prefix_function(s[-1])
et vous avez juste à vérifier si k != n and n % k == 0 (si k != n and n % k == 0 alors la réponse est s[:k] , sinon il n'y a pas de réponse
vous pouvez vérifier la preuve ici (en russe, mais traducteur en ligne fera probablement l'affaire)
def riad(s):
n = len(s)
pi = [0] * n
for i in xrange(1, n):
j = pi[i - 1]
while(j > 0 and s[i] != s[j]):
j = pi[j - 1]
if (s[i] == s[j]):
j += 1
pi[i] = j;
k = n - pi[-1]
return s[:k] if (n != k and n % k == 0) else None
cette version essaie seulement les longueurs de séquence de candidat qui sont des facteurs de la longueur de chaîne; et utilise l'opérateur * pour construire une chaîne pleine longueur de la séquence de candidat:
def get_shortest_repeat(string):
length = len(string)
for i in range(1, length // 2 + 1):
if length % i: # skip non-factors early
continue
candidate = string[:i]
if string == candidate * (length // i):
return candidate
return None
merci à TigerhawkT3 d'avoir remarqué que length // 2 sans + 1 ne correspondrait pas à l'affaire abab .
voici une solution simple, sans regrets.
pour les substrats de s à partir de l'indice zéroth, de longueurs 1 à len(s) , vérifier si cette sous-couche, substr est le motif répété. Ce contrôle peut être effectué en concaténant substr avec lui-même ratio fois, de sorte que la longueur de la chaîne ainsi formée est égale à la longueur de s . D'où ratio=len(s)/len(substr) .
retour quand la première de ces sous-chaîne est trouvée. Ceci fournirait le plus petit substrat possible, si un existe.
def check_repeat(s):
for i in range(1, len(s)):
substr = s[:i]
ratio = len(s)/len(substr)
if substr * ratio == s:
print 'Repeating on "%s"' % substr
return
print 'Non repeating'
>>> check_repeat('254725472547')
Repeating on "2547"
>>> check_repeat('abcdeabcdeabcdeabcde')
Repeating on "abcde"
j'ai commencé avec plus de huit solutions à ce problème. Certains étaient basés sur regex (match, findall, split), d'autres sur string slicing et testing, et d'autres avec des méthodes string (find, count, split). Chacun d'entre eux présentait des avantages en termes de clarté du code, de taille du code, de vitesse et de consommation de mémoire. J'allais poster ma réponse ici quand j'ai remarqué que la vitesse d'exécution était classée comme importante, donc j'ai fait plus de tests et d'améliorations pour arriver à ceci:
def repeating(s):
size = len(s)
incr = size % 2 + 1
for n in xrange(1, size//2+1, incr):
if size % n == 0:
if s[:n] * (size//n) == s:
return s[:n]
cette réponse semble similaire à quelques autres réponses ici, mais il a quelques optimisations de vitesse que d'autres n'ont pas utilisé:
-
xrangeest un peu plus rapide dans cette application, - si une chaîne de caractères d'entrée est une longueur impaire, ne pas vérifier de sous-chaînes de longueur égale,
- en utilisant
s[:n]directement, nous évitons de créer une variable dans chaque boucle.
je serais intéressé de voir comment cela fonctionne dans le tests standard avec un matériel courant. Je pense qu'il sera bien en deçà de L'excellent algorithme de David Zhang dans la plupart des tests, mais devrait être assez rapide sinon.
j'ai trouvé ce problème très contre-intuitif. Les solutions que je pensais rapides étaient lentes. Les solutions qui semblaient lentes étaient rapides! Il semble que la création de chaînes de Python avec l'opérateur multiply et les comparaisons de chaînes sont hautement optimisées.
cette fonction fonctionne très rapidement (testé et il est plus de 3 fois plus rapide que la solution la plus rapide ici sur les chaînes avec plus de 100k caractères et la différence devient plus grande plus le motif de répétition est). Il essaie de minimiser le nombre de comparaisons nécessaires pour obtenir la réponse:
def repeats(string):
n = len(string)
tried = set([])
best = None
nums = [i for i in xrange(2, int(n**0.5) + 1) if n % i == 0]
nums = [n/i for i in nums if n/i!=i] + list(reversed(nums)) + [1]
for s in nums:
if all(t%s for t in tried):
print 'Trying repeating string of length:', s
if string[:s]*(n/s)==string:
best = s
else:
tried.add(s)
if best:
return string[:best]
noter que par exemple pour la chaîne de longueur 8 il ne vérifie que le fragment de taille 4 et il n'a pas à tester davantage parce que le modèle de longueur 1 ou 2 résulterait en motif répétitif de la longueur 4:
>>> repeats('12345678')
Trying repeating string of length: 4
None
# for this one we need only 2 checks
>>> repeats('1234567812345678')
Trying repeating string of length: 8
Trying repeating string of length: 4
'12345678'
dans la réponse de David Zhang si nous avons une sorte de tampon circulaire cela ne fonctionnera pas: principal_period('6210045662100456621004566210045662100456621') en raison du départ 621 , où j'aurais aimé qu'il crache: 00456621 .
étendre sa solution nous pouvons utiliser ce qui suit:
def principal_period(s):
for j in range(int(len(s)/2)):
idx = (s[j:]+s[j:]).find(s[j:], 1, -1)
if idx != -1:
# Make sure that the first substring is part of pattern
if s[:j] == s[j:][:idx][-j:]:
break
return None if idx == -1 else s[j:][:idx]
principal_period('6210045662100456621004566210045662100456621')
>>> '00456621'
Voici le code en python qui vérifie que la répétition de sous-chaîne dans la chaîne principale donnée par l'utilisateur .
print "Enter a string...."
#mainstring = String given by user
mainstring=raw_input(">")
if(mainstring==''):
print "Invalid string"
exit()
#charlist = Character list of mainstring
charlist=list(mainstring)
strarr=''
print "Length of your string :",len(mainstring)
for i in range(0,len(mainstring)):
strarr=strarr+charlist[i]
splitlist=mainstring.split(strarr)
count = 0
for j in splitlist:
if j =='':
count+=1
if count == len(splitlist):
break
if count == len(splitlist):
if count == 2:
print "No repeating Sub-String found in string %r"%(mainstring)
else:
print "Sub-String %r repeats in string %r"%(strarr,mainstring)
else :
print "No repeating Sub-String found in string %r"%(mainstring)
Entrée :
00456621004566210045662100456621004500456621
Sortie :
Longueur de votre chaîne : 40
Sous-chaîne '00456621' répétitions dans la chaîne '0045662100456621004566210045662100456621'
Entrée :
004608294930875576036866359447
Sortie :
Longueur de votre chaîne : 30
Pas de répétition des Sous-Chaîne dans la chaîne '004608294930875576036866359447'