Estimation du nombre de neurones et du nombre de couches d'un réseau neuronal artificiel [fermé]
Je cherche une méthode sur la façon de calculer le nombre de couches et le nombre de neurones par couche. Comme entrée, je n'ai que la taille du vecteur d'entrée, la taille du vecteur de sortie et la taille de la formation ensemble.
Habituellement, le meilleur réseau est déterminé en essayant différentes topologies de réseau et en sélectionnant celle avec le moins d'erreur. Malheureusement, je ne peux pas le faire.
3 réponses
C'est un problème vraiment difficile.
Plus un réseau a de structure interne, mieux ce réseau représentera des solutions complexes. D'un autre côté, une trop grande structure interne est plus lente, peut entraîner une divergence de la formation ou entraîner un suréquipement-ce qui empêcherait votre réseau de bien se généraliser aux nouvelles données.
Les gens ont traditionnellement abordé ce problème de plusieurs façons différentes:
Essayez différentes configurations, voir ce fonctionne le mieux. vous pouvez diviser votre ensemble de formation en deux parties - une pour la formation, une pour l'évaluation - et ensuite former et évaluer différentes approches. Malheureusement, il semble que dans votre cas, cette approche expérimentale n'est pas disponible.
Utilisez une règle de base. beaucoup de gens sont venus avec beaucoup de suppositions quant à ce qui fonctionne le mieux. En ce qui concerne le nombre de neurones dans la couche cachée, les gens ont spéculé que (par exemple) il devrait (a) être entre la taille des couches d'entrée et de sortie, (b) définie sur quelque chose de proche (entrées+sorties) * 2/3, ou (c) jamais plus de deux fois la taille de la couche d'entrée.
le problème avec les règles empiriques est qu'elles ne prennent pas toujours en compte des informations vitales, comme à quel point le problème est" difficile", Quelle est la taille des ensembles de formation et de test , etc. Par conséquent, ces règles sont souvent utilisées comme points de départ approximatifs pour le "allons-essayer-un-tas-de-choses-et-voir-ce-travaux-meilleure" approche.Utiliser un algorithme qui ajuste dynamiquement la configuration du réseau. des algorithmes tels que Cascade Correlation commencent par un réseau minimal, puis ajoutent des nœuds cachés pendant l'entraînement. Cela peut rendre votre configuration expérimentale un peu plus simple et (en théorie) peut entraîner de meilleures performances (car vous n'utiliserez pas accidentellement un nombre inapproprié de nœuds cachés).
Il y a un beaucoup de recherches sur ce sujet, donc si vous êtes vraiment intéressé, il y a beaucoup à lire. Découvrez les citations sur ce résumé, en particulier:
Lawrence, S., Giles, C. L. et Tsoi, A. C. (1996), "quelle taille réseau neuronal donne une généralisation optimale? Propriétés de Convergence de la rétropropagation " . Rapport Technique UMIACS-TR-96-22 et c-TR-3617, Institut des hautes Études en Informatique à l'Université du Maryland, College Parc.
Elisseeff, A., et Paugam-Moisy, H. (1997), "Taille des réseaux multicouches pour l'apprentissage exact: approche analytique" . Avancées en Traitement de l'Information Neuronale des Systèmes 9, Cambridge, MA: MIT Press, pp. 162-168.
En pratique, ce n'est pas difficile (sur la base d'avoir codé et formé des dizaines de MlP).
Dans un sens manuel, obtenir l'architecture "droite" est difficile-c'est-à-dire, pour régler votre architecture réseau de telle sorte que la performance (résolution) ne peut pas être améliorée par une optimisation supplémentaire de l'architecture est difficile, je suis d'accord. Mais ce n'est que dans de rares cas que ce degré d'optimisation est requis.
En pratique, pour atteindre ou dépasser la précision de prédiction d'un réseau de neurones requis par votre spec, vous presque jamais besoin de passer beaucoup de temps avec l'architecture de réseau--trois raisons pour lesquelles cela est vrai:
la plupart des paramètres nécessaire pour préciser l'architecture de réseau sont fixes d une fois que vous avez décidé de votre modèle de données (nombre de caractéristiques dans le vecteur d'entrée, si la variable de réponse souhaitée est numérique ou catégorique, et si ce dernier, combien de classe unique étiquettes que vous avez choisies);
-
Les quelques autres paramètres d'architecture qui sont en fait réglables, sont presque toujours (100% du temps dans mon expérience) fortement contraints par ces architectures fixes paramètres--c'est-à-dire que les valeurs de ces paramètres sont étroitement liées par une valeur max et min; et
L'architecture optimale n'a pas à être déterminé avant la formation commence, en effet, il est très courant pour le code de réseau neuronal de inclure un petit module pour régler le réseau par programmation l'architecture au cours de formation (en supprimant les nœuds dont les valeurs de poids sont proche de zéro (généralement appelé "élagage.")
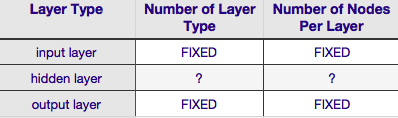
Selon le tableau ci-dessus, l'architecture d'un réseau neuronal est complètement spécifiée par six paramètres (les six cellules de la grille intérieure). Deux d'entre eux (nombre de type de couche pour les couches d'entrée et de sortie) sont toujours un et un-les réseaux de neurones ont une seule couche d'entrée et une seule couche de sortie. Votre NN doit avoir au moins une couche d'entrée et une couche de sortie--pas plus, pas moins. Deuxièmement, le nombre de nœuds comprenant chacune de ces deux couches est fixe-la couche d'entrée, par la taille du vecteur d'entrée-c'est-à-dire que le nombre de nœuds dans la couche d'entrée est égal à la longueur du vecteur d'entrée (en fait, un neurone de plus est presque toujours ajouté à la couche d'entrée en tant
De même, la taille de la couche de sortie est fixée par la variable de réponse (nœud unique pour la réponse numérique variable, et (en supposant que softmax est utilisé, si la variable de réponse est une étiquette de classe, le nombre de nœuds dans la couche de sortie est simplement égal au nombre d'étiquettes de classe uniques).
Cela laisse seulement deux paramètres pour lesquels il n'y a aucune discrétion-le nombre de couches cachées et le nombre de nœuds comprenant chacune de ces couches.
Le nombre de couches cachées
Si vos données sont linéairement séparables (que vous connaissez souvent au moment où vous commencez à coder un NN) alors vous n'avez pas besoin de couches cachées du tout. (Si c'est en fait le cas, je n'utiliserais pas de NN pour ce problème-choisissez un classificateur linéaire plus simple). Le premier d'entre eux-le nombre de couches cachées-est presque toujours un. Il y a beaucoup de poids empirique derrière cette présomption-en pratique, très peu de problèmes qui ne peuvent être résolus avec une seule couche cachée deviennent solubles en ajoutant une autre couche cachée. De même, il y a un consensus est la différence de performance de ajout de couches masquées supplémentaires: les situations dans lesquelles les performances s'améliorent avec une seconde (ou une troisième, etc.) couche cachée sont très petites. Une couche cachée est suffisante pour la grande majorité des problèmes.
Dans votre question, vous avez mentionné que pour une raison quelconque, vous ne pouvez pas trouver l'architecture réseau optimale par essais et erreurs. Une autre façon d'ajuster votre configuration NN (sans utiliser d'essais et d'erreurs) est ' élagage '. L'essentiel de cette technique est de supprimer les nœuds du réseau pendant la formation en identifiant les nœuds qui, s'ils étaient retirés du réseau, n'affecteraient pas sensiblement les performances du réseau (c'est-à-dire la résolution des données). (Même sans utiliser une technique d'élagage formelle, vous pouvez avoir une idée approximative des nœuds qui ne sont pas importants en regardant votre matrice de poids après l'entraînement; recherchez des poids très proches de zéro-ce sont les nœuds de chaque extrémité de ces poids qui sont souvent enlevés pendant l'élagage.) Évidemment, si vous utilisez un algorithme d'élagage pendant la formation commence alors avec une configuration de réseau qui est plus susceptible d'avoir des nœuds excédentaires (c'est-à-dire "élaguables") - en d'autres termes, lorsque vous décidez d'une architecture de réseau, errez du côté de plus de neurones, si vous ajoutez une étape d'élagage.
Autrement dit, en appliquant un algorithme d'élagage à votre réseau pendant la formation, vous pouvez vous rapprocher d'une configuration réseau optimisée que n'importe quelle théorie a priori est susceptible de vous donner.
Le nombre de nœuds comprenant le caché Couche
Mais qu'en est-il du nombre de nœuds composant la couche cachée? Accordé cette valeur est plus ou moins contrainte--c'est à dire, il peut être plus petite ou plus grande que la taille de la couche d'entrée. Au-delà de cela, comme vous le savez probablement, il y a une montagne de commentaires sur la question de la configuration de la couche cachée dans NNs (voir la célèbre FAQ NN pour un excellent résumé de ce commentaire). Il existe de nombreuses règles empiriques dérivées, mais parmi celles-ci, la plus couramment invoquée est la taille de la couche cachée est entre l'entrée et la sortie des couches. Jeff Heaton, auteur de "Introduction to Neural Networks in Java " en propose un peu plus, qui sont récités sur la page que je viens de lier. De même, une analyse de la littérature de réseau neuronal orienté application, révélera presque certainement que la taille de la couche cachée est généralement entre les tailles de couche d'entrée et de sortie. Mais entre ne signifie pas au milieu; en fait, c'est généralement mieux à l'ensemble de la couche cachée taille plus proche de la taille du vecteur d'entrée. La raison en est que si la couche cachée est trop petite, le réseau peut avoir des difficultés à converger. Pour la configuration initiale, err sur la plus grande taille-une couche cachée plus grande donne au réseau plus de capacité qui l'aide à converger, par rapport à une couche cachée plus petite. En effet, cette justification est souvent utilisée pour recommander une taille de couche cachée supérieure à (plus de nœuds) la couche d'entrée-c'est-à-dire, commencer par une architecture initiale qui encouragera une convergence rapide, après quoi vous pourrez élaguer les nœuds "excédentaires" (identifier les nœuds dans la couche cachée avec des valeurs de poids très faibles et les éliminer de votre réseau RE-factorisé).
J'ai utilisé un MLP pour un logiciel commercial qui a une seule couche cachée qui n'a qu'un seul nœud. Comme les nœuds d'entrée et les nœuds de sortie sont fixes, Je n'ai eu qu'à changer le nombre de couches cachées et à jouer avec la généralisation obtenue. Je n'ai jamais vraiment eu une grande différence dans ce que je réalisais avec un seul calque caché et un nœud en changeant le nombre de calques cachés. Je viens d'utiliser une couche cachée avec un nœud. Cela a très bien fonctionné et les calculs réduits ont également été très tentant dans ma prémisse de logiciel.