Est-ce que quelqu'un peut donner un exemple concret d'apprentissage supervisé et d'apprentissage non supervisé?
j'ai récemment étudié l'apprentissage supervisé et l'apprentissage non supervisé. En théorie, je sais que supervisée signifie obtenir l'information à partir d'ensembles de données étiquetés et non supervisée signifie regrouper les données sans aucune étiquette donnée.
mais, le problème est que je suis toujours confus pour identifier si l'exemple donné est l'apprentissage supervisé ou l'apprentissage sans supervision pendant mes études.
quelqu'un Peut-il donner un exemple concret?
6 réponses
apprentissage Supervisé:
- vous obtenez tas de photos avec des informations sur ce qui est sur eux et vous formez un mannequin pour reconnaître de nouvelles photos
- vous avez des tas de molécules et informations qui sont des médicaments et vous former un modèle de déterminer si une nouvelle molécule est aussi un médicament
apprentissage sans supervision:
- vous avez des tas de photos de 6 personnes, mais sans information qui est sur lequel et voulez diviser cet ensemble de données en 6 piles, chacune avec des photos d'un individu
- vous avez des molécules, une partie d'entre eux sont des médicaments et ne sont pas mais vous ne savez pas qui sont et vous voulez algorithme pour découvrir les médicaments
Apprentissage Supervisé
C'est simple et vous l'auriez fait plusieurs fois, par exemple:
- Cortana ou n'importe quel système automatisé de la parole dans votre téléphone mobile Forme votre voix et commence à travailler sur la base de cette formation.
- basé sur diverses caractéristiques (antécédents de tête-à-tête, lancer, lancer, joueur-vs-Joueur) WASP prédit le pourcentage de réussite des deux équipes.
- formez votre écriture à la reconnaissance optique des caractères système et une fois formé, il sera en mesure de convertir vos images d'écriture à la main en texte (jusqu'à une certaine précision évidemment)
- basé sur des connaissances préalables (quand il fait beau, la température est plus élevée; quand il fait nuageux, l'humidité est plus élevée, etc.) la météo de prédire les paramètres pour un temps donné.
basé sur des informations passées sur les spams, filtrant un nouvel email entrant dans Boîte de réception (normal) ou dossier de courrier Indésirable (Spam)
assistance biométrique ou ATM etc systèmes où vous entraînez la machine après quelques entrées (de votre identité biométrique - que ce soit le pouce ou l'iris ou le lobe de l'oreille, etc.), machine peut valider vos entrées futures et vous identifier.
Apprentissage Sans Supervision
Un ami vous invite à sa fête où vous satisfaire totalement étrangers. Maintenant, vous allez les classer en utilisant l'apprentissage sans supervision (pas de cette classification peut être basée sur le sexe, le groupe d'âge, l'habillement, le niveau de scolarité ou tout autre critère que vous souhaitez. Pourquoi cet apprentissage est différente de l'Apprentissage Supervisé? Depuis que vous n'avez pas utilisé de connaissances passées/antérieures sur les gens et les a classés "en cours de route".
la NASA découvre de nouveaux corps célestes et les trouve différents de objets astronomiques déjà connus-étoiles, planètes, astéroïdes, blackholes etc. (c'est à dire qu'il n'a aucune connaissance de ces nouveaux organismes) et les classifie de la façon dont il le voudrait (distance de la Voie Lactée, intensité, force gravitationnelle, décalage rouge/bleu ou autre)
supposons que vous n'avez jamais vu un match de Cricket avant et par hasard regarder une vidéo sur internet, maintenant vous pouvez classer les joueurs sur la base de différents critères: les joueurs portant le même genre de kits sont dans une classe, les joueurs d'un style sont dans une classe (Batteurs, bowler, fielders), ou sur le base de la main de jeu (RH vs LH) ou de quelque manière que vous l'observiez [et classifiez].
nous effectuons un sondage auprès de 500 questions sur la prévision du niveau de QI des étudiants d'un collège. Comme ce questionnaire est trop grand, après 100 étudiants, l'administration décide de le réduire à moins de questions et pour cela nous utilisons une procédure statistique comme PCA pour la réduire.
j'espère que ces quelques des exemples expliquent la différence en détail.
Apprentissage Supervisé:
- c'est comme apprendre avec un professeur
- ensemble de données d'apprentissage est comme un prof
- l'ensemble de données d'apprentissage est utilisé pour former la machine
Exemple:
Classement: Machine est formé pour classer quelque chose dans une certaine classe.
- classifier si un patient est malade ou non
- classement de savoir si un email est un spam ou pas
Régression:
- prévision du prix des maisons / propriétés
- prévision du cours des actions
Apprentissage Sans Supervision:
- c'est comme apprendre sans maître
- la machine apprend par l'observation et la recherche de structures dans les données
Exemple:
Clustering: un problème de clustering est où vous voulez découvrir les regroupements inhérents dans les données
- groupement de clients par le comportement d'achat
Association: un problème d'apprentissage de règles d'association est où vous voulez découvrir des règles qui décrivent de grandes parties de vos données
- comme les gens que X acheter aussi tendance à acheter Y
Lire la suite:supervisée et non Supervisée des Algorithmes d'Apprentissage automatique
Apprentissage Supervisé
L'apprentissage supervisé est assez courant dans les problèmes de classification parce que le but est souvent d'amener l'ordinateur à apprendre un système de classification que nous avons créé. Encore une fois, la reconnaissance numérique est un exemple courant d'apprentissage en classification. De façon plus générale, l'apprentissage de la classification est approprié pour tout problème où la déduction d'une classification est utile et la classification est facile à déterminer. Dans certains cas, il pourrait même ne pas il est nécessaire de donner des classifications prédéfinies à chaque instance d'un problème si l'agent peut élaborer les classifications pour lui-même. Il s'agirait d'un exemple d'apprentissage non supervisé dans un contexte de classification.
L'apprentissage supervisé est la technique la plus courante pour former les réseaux neuronaux et les arbres de décision. Ces deux techniques dépendent fortement de l'information fournie par les classifications prédéfinies. Dans le cas des réseaux neuronaux, la classification est utilisé pour déterminer l'erreur du réseau, puis ajuster le réseau pour la minimiser, et dans les arbres de décision, les classifications sont utilisées pour déterminer quels attributs fournissent le plus d'information qui peut être utilisé pour résoudre le puzzle de classification. Nous allons examiner ces deux exemples plus en détail, mais pour l'instant, il devrait être suffisant de savoir que ces deux exemples prospèrent sur le fait d'avoir une certaine "supervision" sous la forme de classifications prédéterminées.
reconnaissance de la Parole les modèles Markov cachés et les réseaux bayésiens s'appuient également sur certains éléments de supervision afin d'ajuster les paramètres pour, comme d'habitude, minimiser l'erreur sur les entrées données.
Remarquez quelque chose d'important ici: le problème de classement, l'objectif de l'algorithme d'apprentissage est de minimiser l'erreur à l'égard des entrées données. Ces entrées, souvent appelées "l'ensemble de formation", sont les exemples à partir desquels l'agent tente d'apprendre. Mais apprendre à bien s'entraîner n'est pas forcément la meilleure chose à faire. Par exemple, si j'ai essayé de vous enseigner l'exclusivité-ou, mais seulement vous a montré des combinaisons consistant en un vrai et un faux, mais jamais les deux faux ou les deux vrai, vous pourriez apprendre la règle que la réponse est toujours vrai. De même, avec les algorithmes d'apprentissage automatique, un problème courant consiste à SUR-ajuster les données et essentiellement à mémoriser l'ensemble de la formation plutôt qu'à apprendre une technique de classification plus générale.
sans supervision L'apprentissage
apprendre sans supervision semble beaucoup plus difficile: le but est d'apprendre à l'ordinateur à faire quelque chose que nous ne lui disons pas comment faire! Il existe en fait deux approches de l'apprentissage non supervisé. La première approche consiste à enseigner à l'agent non pas en donnant des catégorisations explicites, mais en utilisant une sorte de système de récompense pour indiquer le succès. Il est à noter que ce type de formation s'inscrit généralement dans le cadre du problème de décision parce que l'objectif n'est pas de produire une la classification, mais pour prendre des décisions qui maximisent les récompenses. Cette approche généralise bien au monde réel, où les agents pourraient être récompensés pour avoir commis certaines actions et punis pour en avoir commis d'autres.
souvent, une forme d'apprentissage de renforcement peut être utilisée pour l'apprentissage non supervisé, où l'agent fonde ses actions sur les récompenses et punitions précédentes sans nécessairement même apprendre aucune information sur la façon exacte dont ses actions affectent le monde. En un sens, tout cela l'information n'est pas nécessaire parce qu'en apprenant une fonction de récompense, l'agent sait tout simplement quoi faire sans aucun traitement parce qu'il connaît la récompense exacte qu'il s'attend à obtenir pour chaque action qu'il pourrait prendre. Cela peut être extrêmement bénéfique dans les cas où le calcul de chaque possibilité est très long (même si toutes les probabilités de transition entre les États mondiaux étaient connues). D'autre part, il peut être très long à apprendre par, essentiellement, l'essai et erreur.
mais ce type d'apprentissage peut être puissant parce qu'il suppose aucune classification prédécouverte des exemples. Dans certains cas, par exemple, nos classifications peuvent ne pas être les meilleures possibles. Un exemple frappant est que la sagesse conventionnelle au sujet du jeu de backgammon a été tournée sur sa tête quand une série de programmes informatiques (neuro-gammon et TD-gammon) qui a appris par l'apprentissage sans supervision est devenue plus forte que les meilleurs joueurs d'échecs humains simplement en jouant eux-mêmes. Ces programmes ont découvert certains principes qui ont surpris les experts de backgammon et ont fonctionné mieux que les programmes de backgammon formés sur des exemples pré-classifiés.
un deuxième type d'apprentissage non supervisé est appelé "clustering". Dans ce type d'apprentissage, le but n'est pas de maximiser une fonction d'utilité, mais simplement de trouver des similitudes dans les données d'apprentissage. L'hypothèse est souvent que les clusters découverts correspondront raisonnablement bien avec un classification. Par exemple, le regroupement des personnes en fonction de la démographie pourrait donner lieu à un regroupement des riches dans un groupe et des Pauvres dans un autre.
L'apprentissage supervisé a des entrées et des sorties correctes. Par exemple: Nous avons les données si une personne a aimé le film ou pas. En interviewant les gens et en recueillant leur réponse s'ils ont aimé le film ou pas, nous allons prédire si le film va être frappé ou pas.
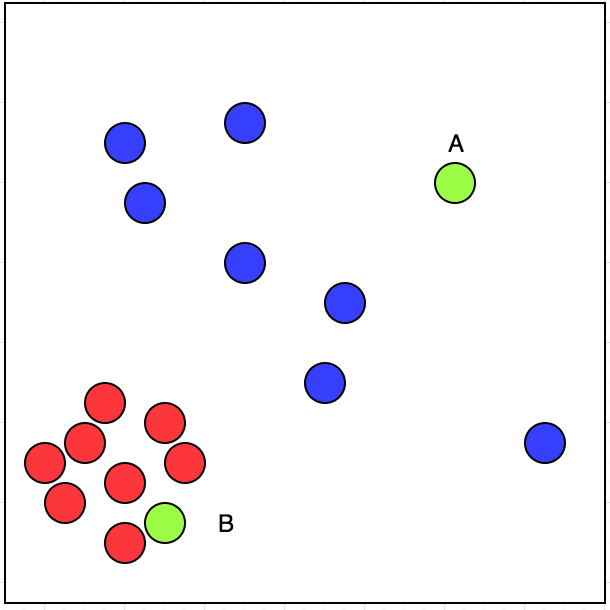
regardons l'image dans le lien ci-dessus. J'ai visité les restaurants marqués par le cercle rouge. Les restaurants que je n'ai pas visités est marqué par un cercle bleu.
Maintenant, Si j'ai deux restaurants, A et B, marquée par la couleur verte, lequel vais-je choisir?
Simple. Nous pouvons classer les données de façon linéaire en deux parties. On peut tracer une ligne séparant le cercle rouge du cercle bleu. Regardez l'image dans le lien ci-dessous:
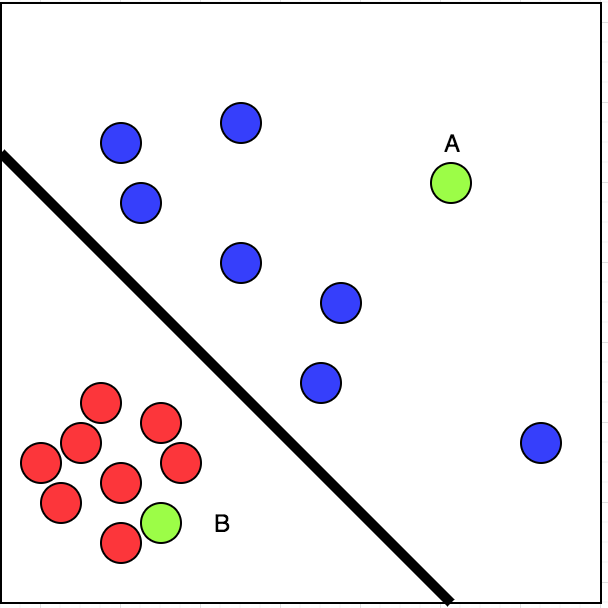
maintenant, nous pouvons dire avec un peu de confiance que les chances de ma visite B est plus que A. Il s'agit d'un cas de supervision apprentissage.
l'apprentissage sans supervision a des entrées. supposons que nous ayons un chauffeur de taxi qui a la possibilité d'accepter ou de rejeter les réservations. Nous avons tracé son emplacement de réservation accepté sur la carte avec Blue circle et est montré ci-dessous:
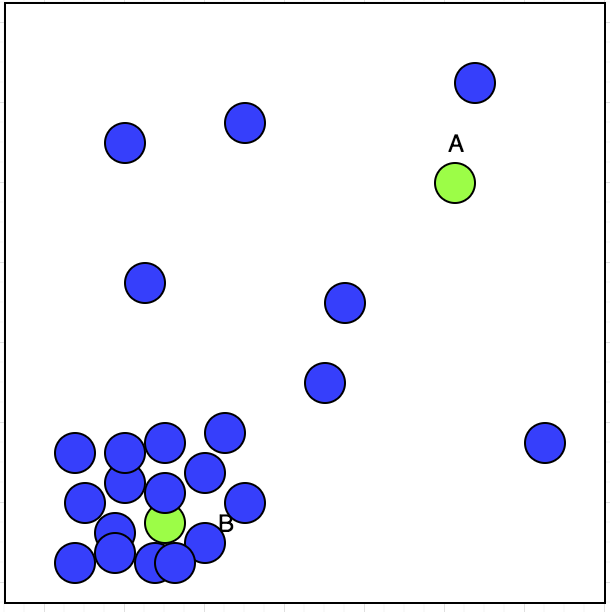
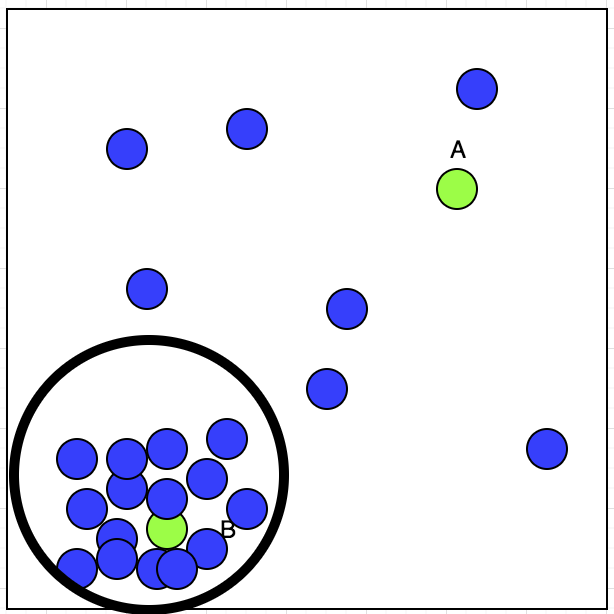
maintenant, le chauffeur de Taxi a deux réservations A et B; lequel il acceptera? Si nous observons l'intrigue, nous pouvons voir que sa réservation acceptée montre un faisceau au coin inférieur gauche. Qui peut être indiqué dans l'image ci-dessous:
apprentissage supervisé: en termes simples, vous avez certains inputs et attendez certains outputs. Par exemple, vous avez une donnée de marché boursier qui est des données précédentes et pour obtenir les résultats de l'entrée actuelle pour les prochaines années en donnant quelques instructions, il peut vous donner les résultats nécessaires.
apprentissage sans supervision: vous avez des paramètres comme la couleur, le type, la taille de quelque chose et vous voulez un programme pour prédire si c'est un fruit, une plante, un animal ou quoi que ce soit d'autre, c'est où Supervisé. Il vous donne la sortie en prenant quelques entrées.