Pourquoi l'allocation de mémoire pour les processus est-elle lente et peut-elle être plus rapide?
Je connais relativement bien le fonctionnement de la mémoire virtuelle. Toute la mémoire du processus est divisée en pages et chaque page de la mémoire virtuelle correspond à une page en mémoire réelle ou à une page dans un fichier d'échange ou il peut s'agir d'une nouvelle page, ce qui signifie que la page physique n'est toujours pas allouée. Le système d'exploitation mappe les nouvelles pages à la mémoire réelle à la demande, pas lorsqu'une application demande de la mémoire avec malloc, mais seulement lorsqu'une application accède réellement à chaque page à partir de la mémoire allouée. Mais j'ai encore des questions.
J'ai remarqué c'était quand profilait mon application avec l'outil linux perf.
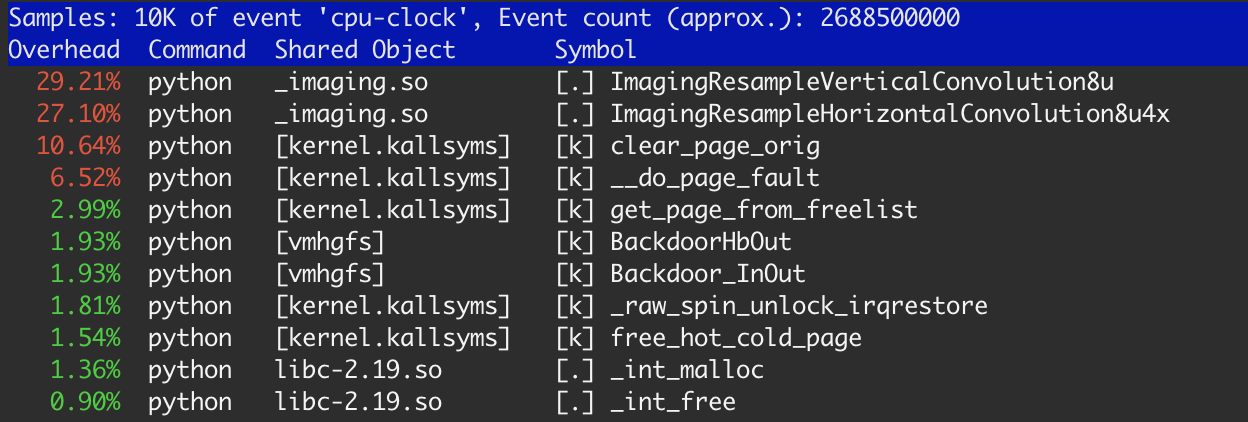
Il y a environ 20% du temps pris des fonctions du noyau: clear_page_orig, __do_page_fault et get_page_from_free_list. C'est beaucoup plus que ce à quoi je m'attendais pour cette tâche et j'ai fait quelques recherches.
Commençons par un petit exemple:
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#define SIZE 1 * 1024 * 1024
int main(int argc, char *argv[]) {
int i;
int sum = 0;
int *p = (int *) malloc(SIZE);
for (i = 0; i < 10000; i ++) {
memset(p, 0, SIZE);
sum += p[512];
}
free(p);
printf("sum %dn", sum);
return 0;
}
Supposons que memset est juste un traitement lié à la mémoire. Dans ce cas, nous allouons une petite partie de mémoire une fois et la réutilisons encore et encore. Je vais exécuter ce programme comme ce:
$ gcc -O1 ./mem.c && time ./a.out
-O1 nécessaire parce que clang avec -O2 entièrement élimine la boucle et calcule la valeur instantanément.
Les résultats sont: user: 0.520 s, sys: 0.008 S. Selon perf, 99% de ce temps est dans memset de libc. Donc, pour ce cas, la performance d'écriture est d'environ 20 gigaoctets / s, ce qui est plus que la performance théorique 12,5 Gb / s pour ma mémoire. On dirait que cela est dû au cache du processeur L3.
Laissez le test de changement et commencez à allouer de la mémoire en boucle (je vais ne pas répéter les mêmes parties du code):
#define SIZE 1 * 1024 * 1024
for (i = 0; i < 10000; i ++) {
int *p = (int *) malloc(SIZE);
memset(p, 0, SIZE);
free(p);
}
, Le résultat est exactement le même. Je crois que free ne libère pas réellement de mémoire pour OS, il le met simplement dans une liste libre dans le processus. Et malloc lors de la prochaine itération, obtenez exactement le même bloc de mémoire. C'est pourquoi il n'y a pas de différence notable.
Commençons à augmenter la taille de 1 mégaoctet. Le temps d'exécution augmentera petit à petit et sera saturé près de 10 mégaoctets (il n'y a pas de différence pour moi entre 10 et 20 mégaoctet).
#define SIZE 10 * 1024 * 1024
for (i = 0; i < 1000; i ++) {
int *p = (int *) malloc(SIZE);
memset(p, 0, SIZE);
free(p);
}
Temps montre: utilisateur: 1.184 s, sys: 0.004 s. perf signale toujours que 99% du temps est dans memset, mais le débit est d'environ 8,3 Gb / s. à ce stade, je comprends ce qui se passe, plus ou moins.
Si nous continuons à augmenter la taille du bloc de mémoire, à un moment donné (pour moi sur 35 Mo) le temps d'exécution augmentera considérablement: user: 0.724 s, sys: 3.300 S.
#define SIZE 40 * 1024 * 1024
for (i = 0; i < 250; i ++) {
int *p = (int *) malloc(SIZE);
memset(p, 0, SIZE);
free(p);
}
Selon perf, memset consommera seulement 18% d'un temps.
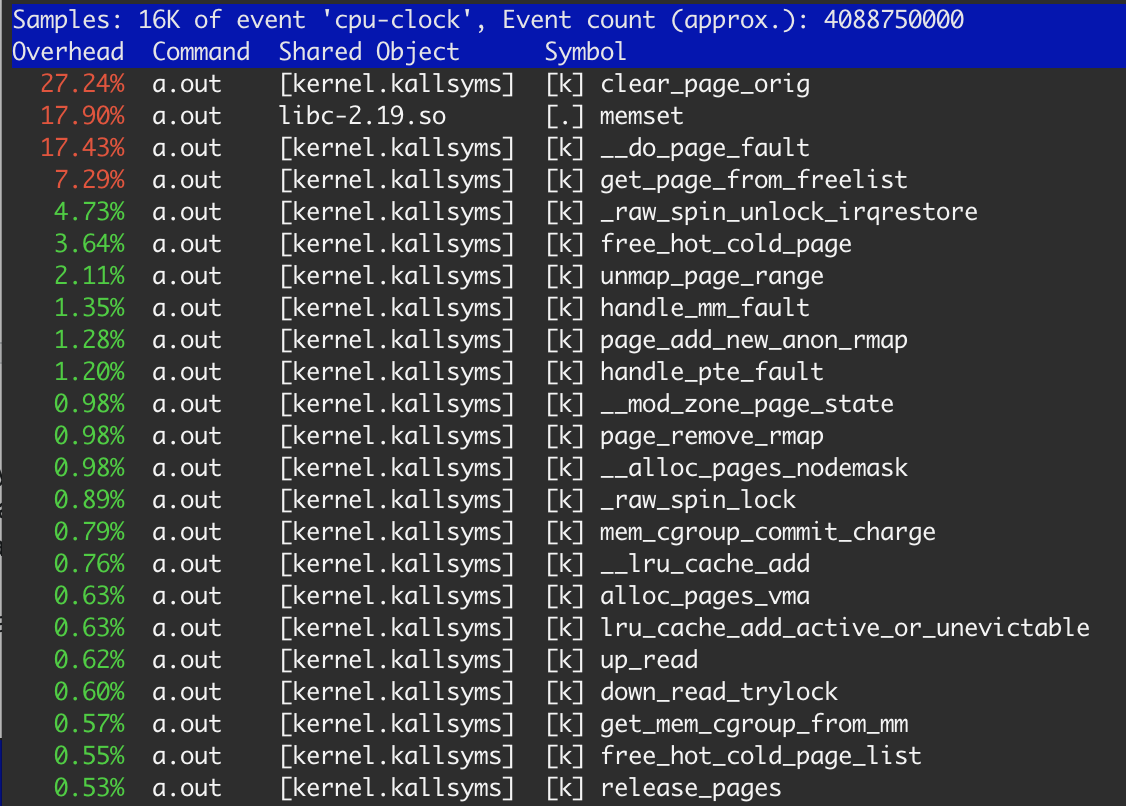
Évidemment, la mémoire est allouée à partir du système D'exploitation et libérée à chaque étape. Comme je l'ai mentionné précédemment, OS devrait effacer chaque page allouée avant utilisation. Donc, 27,3% de clear_page_orig ne semble pas extraordinaire: c'est juste 4s * 0.273 ≈ 1.1 sec pour clear mem - la même chose que nous obtenons dans le troisième exemple. memset a pris 17,9%, ce qui conduit à ≈ 700 msec, ce qui est normal en raison de la mémoire déjà dans le cache L3 après clear_page_orig (premier et deuxième exemple).
Ce que je ne comprends pas - pourquoi le dernier cas est 2 fois plus lent que juste memset pour la mémoire + memset pour le cache L3? Puis-je faire quelque chose avec elle?
Les résultats sont reproductibles (avec de petites différences) sur Mac OS natif, Ubuntu sous VMware et Amazon c4.de grande instance.
Aussi, je pense qu'il y a une place pour l'optimisation sur deux niveaux:
- au niveau du système d'exploitation . Si OS sait qu'il renvoie une page à la même application à laquelle il appartenait précédemment, il ne peut pas effacer il.
- au niveau du processeur . Si CPU sait que la page utilisée pour être libre, il peut ne pas effacer la page en mémoire. Il peut simplement l'effacer dans le cache et le déplacer vers la mémoire seulement après un traitement dans le cache.
2 réponses
Ce qui se passe ici est un peu compliqué car il implique quelques systèmes différents, mais il est certainement Pas lié au coût du changement de contexte; votre programme fait très peu d'appels système (vérifiez cela en utilisant strace ).
Tout d'abord, il est important de comprendre certains principes de base sur la façon dont les implémentations malloc fonctionnent généralement:
- la plupart des implémentations
mallocobtiennent un tas de mémoire du système d'exploitation en appelantsbrkoummappendant initialisation. La quantité de mémoire obtenue peut être ajustée dans certaines implémentationsmalloc. Une fois la mémoire obtenue, elle est généralement découpée en différentes classes de taille et disposée dans une structure de données de sorte que lorsqu'un programme demande de la mémoire avec, par exemple,malloc(123), l'implémentationmallocpeut rapidement trouver un morceau de mémoire correspondant à ces exigences. - lorsque vous appelez
free, la mémoire est renvoyée dans une liste libre et peut être réutilisée lors des appels suivants versmalloc. Certaines implémentationsmallocpermettent vous de régler précisément comment cela fonctionne. - lorsque vous allouez de gros morceaux de mémoire, la plupart des implémentations
mallocpasseront simplement des appels pour d'énormes quantités de mémoire directement à l'appel systèmemmap, qui alloue des "pages" de mémoire à la fois. Pour la plupart des systèmes, 1 page de mémoire est de 4096 octets. - liés, la plupart des systèmes d'exploitation tenteront d'Effacer les pages de mémoire avant de les distribuer aux processus qui ont demandé de la mémoire via
mmapousbrk. C'est pourquoi vous voyez des appels àclear_page_origdans le sortie de perf. Cette fonction tente d'écrire 0s dans des pages de mémoire.
Maintenant, ces principes se croisent avec une autre idée qui a beaucoup de noms, mais est communément appelée "pagination de la demande."Ce que" demande paging " signifie, c'est que lorsqu'un programme utilisateur demande un morceau de mémoire à partir du système d'exploitation (par exemple en appelant mmap), la mémoire est allouée dans l'espace d'adressage virtuel du processus, mais il n'y a pas encore de RAM physique sauvegardant cette mémoire.
Voici un aperçu de la demande processus de pagination:
- UN programme appelé
mmappour allouer 500 Mo de RAM. - le noyau mappe une région d'adresses dans l'espace d'adressage du processus pour les 500 Mo de RAM demandés. Il mappe quelques pages (dépendantes du système D'exploitation) (4096 octets chacune, généralement) de RAM physique pour sauvegarder ces adresses virtuelles.
- le programme utilisateur commence à accéder à la mémoire en y écrivant.
- finalement, le programme utilisateur accédera à une adresse qui est valide, mais n'a pas de support de RAM physique il.
- cela génère un défaut de page sur le CPU.
- le noyau répond à la faute de page en voyant que le processus accède à une adresse valide, mais une Sans RAM physique la sauvegardant.
- le noyau trouve alors la RAM à allouer à cette région. Cela peut être lent si la mémoire d'autres processus doit d'abord être écrite sur le disque ("permutée").
La raison la plus probable pour laquelle vous voyez une dégradation des performances sur le dernier cas est parce que:
- votre noyau n'a plus de page de mémoire nulle qui peut être distribuée pour répondre à votre demande de 40 Mo, donc il réduit à zéro la mémoire encore et encore comme en témoigne votre sortie perf.
- vous générez pagefaults lorsque vous accédez à la mémoire qui n'est pas encore mappée. Puisque vous accédez à 40 Mo au lieu de 10 Mo, vous générerez plus de défauts de page car il y a plus de pages de mémoire qui doivent être mappées.
- comme une autre réponse l'a souligné,
memsetest O (n) signifie que plus vous devez écrire de mémoire, plus cela prendra de temps. - moins probable, puisque 40mb n'est pas beaucoup de RAM ces jours-ci, mais vérifiez la quantité de mémoire libre sur votre système juste pour être sûr que vous avez assez de RAM.
Si votre application est extrêmement sensible aux performances, vous pouvez à la place appeler mmap directement et:
- passez le drapeau
MAP_POPULATEqui provoquera tous les défauts de page et mappera toute la mémoire physique-alors vous ne le serez pas payer le coût de la page faute sur l'accès. - passez l'indicateur
MAP_UNINITIALIZEDqui tentera d'éviter de réduire à zéro les pages de mémoire avant de les distribuer à votre processus. Notez que l'utilisation de cet indicateur est un problème de sécurité et ne doit pas être utilisée à moins que vous ne compreniez parfaitement les implications de l'utilisation de cette option. Il est possible que le processus puisse être émis des pages de mémoire qui ont été utilisées par d'autres processus non liés pour stocker des informations sensibles. Notez également que votre noyau doit être compilé pour autoriser cette option. La plupart des noyaux (comme le noyau AWS Linux) ne viennent pas avec cette option activée par défaut. Vous devriez presque certainement pas utiliser cette option.
Je vous préviens que ce niveau d'optimisation est presque toujours une erreur; la plupart des applications ont des fruits suspendus beaucoup plus faibles pour l'optimisation qui n'implique pas d'optimiser le coût de la page. Dans une application du monde réel, je recommande:
- Évitant l'utilisation de
memsetsur de grands blocs de mémoire à moins qu'il ne soit vraiment nécessaire. La plupart du temps, la mise à zéro de la mémoire avant la réutilisation par le même processus n'est pas nécessaire. - éviter d'allouer et de libérer les mêmes morceaux de mémoire encore et encore; peut-être que vous pouvez simplement allouer un gros bloc à l'avant et le réutiliser au besoin plus tard.
- utiliser l'indicateur
MAP_POPULATEci-dessus si le coût des erreurs de page sur l'accès est vraiment préjudiciable aux performances (peu probable).
Veuillez laisser des commentaires si vous avez des questions et je soyez heureux de modifier ce post un peu plus loin si nécessaire.
Je ne suis pas certain, mais je suis prêt à parier que le coût du changement de contexte du mode utilisateur au noyau, et de nouveau, domine tout le reste. memset prend également beaucoup de temps-rappelez-vous que ce sera O (n).
Mise à Jour
Je crois que free ne libère pas réellement la mémoire pour OS, il suffit de mettre dans une liste gratuite dans le processus. Et malloc sur la prochaine itération juste obtenir exactement le même bloc de mémoire. C'est pourquoi il n'y a pas de notable différence.
C'est, en principe, correct. L'implémentation classique malloc alloue de la mémoire sur une liste liée individuellement; free définit simplement un indicateur indiquant que l'allocation n'est plus utilisée. Au fil du temps, malloc réalloue la première fois qu'il peut trouver un bloc libre assez grand. Cela fonctionne assez bien, mais peut conduire à la fragmentation.
Il y a un certain nombre d'implémentations slicker maintenant, Voir cet article de Wikipedia.