Quand les accumulateurs sont-ils vraiment fiables?
Je veux utiliser un accumulateur pour recueillir des statistiques sur les données que je manipule sur un travail Spark. Idéalement, je le ferais pendant que le travail calcule les transformations requises, mais puisque Spark recalculerait les tâches sur différents cas, les accumulateurs ne refléteraient pas les vraies métriques. Voici comment la documentation décrit ceci:
Pour les mises à jour de l'accumulateur effectuées uniquement à l'intérieur des actions, Spark garantit que la mise à jour de chaque tâche vers l'accumulateur ne sera appliquer une fois, c'est-à-dire les tâches redémarrées ne mettront pas à jour la valeur. Dans les utilisateurs doivent être conscients que la mise à jour de chaque tâche peut être appliqué plus d'une fois si des tâches ou des étapes de travail sont ré-exécutées.
C'est déroutant puisque la plupart Mesures à prendre ne permettez pas d'exécuter du code personnalisé (où les accumulateurs peuvent être utilisés), ils prennent principalement les résultats des transformations précédentes (paresseusement). La documentation montre également ceci:
val acc = sc.accumulator(0)
data.map(x => acc += x; f(x))
// Here, acc is still 0 because no actions have cause the `map` to be computed.
Mais si on ajoute data.count() à la fin, serait-ce garanti pour être correct (n'ont pas de doublons) ou non? Il est clair que acc n'est pas utilisé "inside actions only" , car map est une transformation. Donc, il ne devrait pas être garanti.
D'autre part, la discussion sur les tickets JIRA connexes parle de "tâches de résultat" plutôt que d ' "actions". Par exemple ici et ici. Cela semble indiquer que le résultat serait en effet garanti pour être correct, puisque nous utilisons acc immédiatement avant et action et devrait donc être calculé comme une seule étape.
Je suppose que ce concept de "tâche de résultat" A à voir avec le type d'opérations impliquées, étant la dernière qui inclut une action, comme dans cet exemple, qui montre comment plusieurs opérations sont divisées en étapes (en magenta, image tirée de ici):
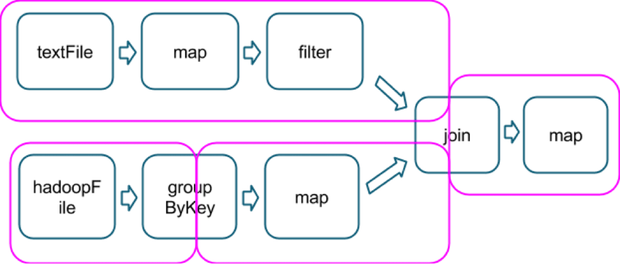
Donc hypothétiquement, une action count() à la fin de cette chaîne ferait partie de la même étape finale, et je serais assuré que les accumulateurs utilisés sur la dernière la carte ne comprennent tous les doublons?
Clarification autour de cette question serait génial! Grâce.
3 réponses
Pour répondre à la question " quand les accumulateurs sont-ils vraiment fiables ?"
Réponse : Quand ils sont présents dans une Action opération.
Selon la Documentation de la tâche Action, même si des tâches redémarrées sont présentes, L'accumulateur ne sera mis à jour qu'une seule fois.
Pour les mises à jour d'accumulateur effectuées uniquement dans les actions, Spark garantit que la mise à jour de chaque tâche sur l'accumulateur ne sera appliquée qu'une seule fois, c'est-à-dire que les tâches redémarrées ne seront pas mises à jour valeur. Dans les transformations, les utilisateurs doivent savoir que la mise à jour de chaque tâche peut être appliquée plus d'une fois si des tâches ou des étapes de travail sont ré-exécutées.
Et l'Action ne permettent d'exécuter du code personnalisé.
Par Ex.
val accNotEmpty = sc.accumulator(0)
ip.foreach(x=>{
if(x!=""){
accNotEmpty += 1
}
})
Mais, pourquoi Carte + Action à savoir. Result Task les opérations ne sont pas fiables pour une opération D'accumulateur?
- la tâche a échoué en raison d'une exception dans le code. Spark va essayer 4 fois(nombre par défaut de essayer).Si la tâche échoue à chaque fois, elle donnera une exception.Si par hasard il réussit alors Spark continuera et mettra simplement à jour la valeur de l'accumulateur pour l'état réussi et les États échoués les valeurs de l'accumulateur sont ignorées.
Verdict: Manipulé Correctement - échec de L'étape: si un nœud d'exécuteur se bloque, aucune faute de l'utilisateur mais une défaillance matérielle - et si le nœud tombe en mode aléatoire stage.As la sortie shuffle est stockée localement, si un nœud tombe en panne, cette sortie shuffle est gone.So Spark remonte à l'étape qui a généré la sortie de lecture aléatoire, regarde quelles tâches doivent être réexécutées, et les exécute sur l'un des nœuds qui est encore en vie.Après avoir régénéré la sortie aléatoire manquante, l'étape qui a généré la sortie de la carte a exécuté certaines de ses tâches plusieurs fois.Spark compte les mises à jour de l'accumulateur de tous.
Verdict: non géré dans la tâche de résultat.L'accumulateur donnera une mauvaise sortie. - si une tâche est lente, Spark peut lancer une copie spéculative de cette tâche sur un autre nœud.
Verdict: non géré.L'accumulateur donnera une mauvaise sortie. - RDD qui est mis en cache est énorme et ne peut pas résider dans Memory.So chaque fois que le RDD est utilisé, il relancera l'opération de carte pour obtenir le RDD et l'accumulateur sera à nouveau mis à jour par celui-ci.
Verdict: non géré.L'accumulateur donnera une mauvaise sortie.
Il peut donc arriver que la même fonction puisse s'exécuter plusieurs fois sur la même data.So Spark ne fournit aucune garantie pour accumulateur mise à jour en raison de l'opération de Carte.
Il est donc préférable d'utiliser L'accumulateur en fonctionnement D'Action dans Spark.
Pour en savoir plus sur Accumulator et ses problèmes, reportez - vous à cet article de Blog - par Imran Rashid.
Les mises à jour de L'accumulateur sont renvoyées au pilote lorsqu'une tâche est terminée avec succès. Ainsi, les résultats de votre accumulateur sont garantis corrects lorsque vous êtes certain que chaque tâche aura été exécutée exactement une fois et chaque tâche a fait comme prévu.
Je préfère compter sur reduce et aggregate au lieu des accumulateurs car il est assez difficile d'énumérer toutes les façons dont les tâches peuvent être exécutées.
- une action démarre les tâches.
- Si une action dépend d'une étape et les résultats de cette étape ne sont pas (complètement) mis en cache, puis les tâches de l'étape précédente seront démarrées.
- L'exécution spéculative démarre les tâches en double lorsqu'un petit nombre de tâches lentes sont détectées.
Cela dit, il existe de nombreux cas simples où les accumulateurs peuvent être entièrement fiables.
val acc = sc.accumulator(0)
val rdd = sc.parallelize(1 to 10, 2)
val accumulating = rdd.map { x => acc += 1; x }
accumulating.count
assert(acc == 10)
Serait-ce garanti pour être correct (n'ont pas de doublons)?
Oui, si l'exécution spéculative est désactivée. Le map et le count sera un une seule étape, donc comme vous le dites, il n'y a aucun moyen qu'une tâche puisse être exécutée avec succès plus d'une fois.
, Mais un accumulateur est mis à jour comme un effet secondaire. Donc, vous devez être très prudent lorsque vous pensez à la façon dont le code sera exécuté. Considérez ceci au lieu de accumulating.count:
// Same setup as before.
accumulating.mapPartitions(p => Iterator(p.next)).collect
assert(acc == 2)
Cela créera également une tâche pour chaque partition, et chaque tâche sera garantie pour exécuter exactement une fois. Mais le code dans map ne sera pas exécuté sur tous les éléments, juste le premier dans chacun partition.
, L'accumulateur est comme une variable globale. Si vous partagez une référence au RDD qui peut incrémenter l'accumulateur, un autre code (d'autres threads) peut également l'incrémenter.
// Same setup as before.
val x = new X(accumulating) // We don't know what X does.
// It may trigger the calculation
// any number of times.
accumulating.count
assert(acc >= 10)
Je pense que Matei a répondu à cela dans la documentation référée:
Tel Que discuté sur https://github.com/apache/spark/pull/2524 c'est assez difficile de fournir une bonne sémantique pour dans le cas général (mises à jour de l'accumulateur à l'intérieur des étapes non-résultats), pour les éléments suivants motifs:
Un RDD peut être calculé dans le cadre de plusieurs étapes. Pour exemple, si vous mettez à jour un accumulateur dans un MappedRDD, puis mélangez - le, Cela pourrait être une étape. Mais si vous appelez à nouveau map() sur le MappedRDD, et mélanger le résultat de cela, vous obtenez une seconde étape où cette carte est pipeline. Voulez-vous compter cette mise à jour de l'accumulateur deux fois ou non?
Des étapes entières peuvent être soumises à nouveau si les fichiers de lecture aléatoire sont supprimés par le nettoyeur périodique ou sont perdus en raison d'un échec du nœud, donc tout ce qui suit les RDDs devrait le faire pour longues périodes de temps (tant que le RDD est référencable dans l'utilisateur programme), ce qui serait assez compliqué à mettre en œuvre.
Donc j'y vais pour marquer cela comme "ne corrigera pas" pour l'instant, sauf pour la partie pour le résultat étapes effectuées dans SPARK-3628.