Quelle est la différence entre abstraction et généralisation?
Je comprends que l'abstraction consiste à prendre quelque chose de plus concret et à le rendre plus abstrait. Que quelque chose peut être soit une structure de données ou une procédure. Par exemple:
- abstraction de Données: Un rectangle est une abstraction d'un carré. Il se concentre sur le fait qu'un carré a deux paires de côtés opposés et il ignore le fait que les côtés adjacents d'un carré sont égaux.
-
abstraction procédurale: la fonction d'ordre supérieur
mapest une l'abstraction d'une procédure qui effectue une série d'opérations sur une liste de valeurs pour produire une toute nouvelle liste de valeurs. Il se concentre sur le fait que la procédure parcourt chaque élément de la liste dans l'ordre de produire une nouvelle liste et ignore les réelles opérations effectuées sur chaque élément de la liste.
Ma question est donc la suivante: en quoi l'abstraction est-elle différente de la généralisation? Je cherche des réponses principalement liées à la programmation fonctionnelle. Cependant, si il y a parallels dans la programmation orientée objet alors je voudrais en apprendre davantage sur ceux-ci aussi.
8 réponses
Objet:

Abstraction:

Généralisation:

Exemple dans Haskell:
L'implémentation du tri de sélection en utilisant la file d'attente prioritaire avec trois interfaces différentes:
- une interface ouverte avec la file d'attente en cours d'implémentation en tant que liste triée,
- une interface abstraite (donc les détails sont cachés derrière la couche d'abstraction),
- un interface généralisée (les détails sont encore visibles, mais l'implémentation est plus flexible).
{-# LANGUAGE RankNTypes #-}
module Main where
import qualified Data.List as List
import qualified Data.Set as Set
{- TYPES: -}
-- PQ new push pop
-- by intention there is no build-in way to tell if the queue is empty
data PriorityQueue q t = PQ (q t) (t -> q t -> q t) (q t -> (t, q t))
-- there is a concrete way for a particular queue, e.g. List.null
type ListPriorityQueue t = PriorityQueue [] t
-- but there is no method in the abstract setting
newtype AbstractPriorityQueue q = APQ (forall t. Ord t => PriorityQueue q t)
{- SOLUTIONS: -}
-- the basic version
list_selection_sort :: ListPriorityQueue t -> [t] -> [t]
list_selection_sort (PQ new push pop) list = List.unfoldr mypop (List.foldr push new list)
where
mypop [] = Nothing -- this is possible because we know that the queue is represented by a list
mypop ls = Just (pop ls)
-- here we abstract the queue, so we need to keep the queue size ourselves
abstract_selection_sort :: Ord t => AbstractPriorityQueue q -> [t] -> [t]
abstract_selection_sort (APQ (PQ new push pop)) list = List.unfoldr mypop (List.foldr mypush (0,new) list)
where
mypush t (n, q) = (n+1, push t q)
mypop (0, q) = Nothing
mypop (n, q) = let (t, q') = pop q in Just (t, (n-1, q'))
-- here we generalize the first solution to all the queues that allow checking if the queue is empty
class EmptyCheckable q where
is_empty :: q -> Bool
generalized_selection_sort :: EmptyCheckable (q t) => PriorityQueue q t -> [t] -> [t]
generalized_selection_sort (PQ new push pop) list = List.unfoldr mypop (List.foldr push new list)
where
mypop q | is_empty q = Nothing
mypop q | otherwise = Just (pop q)
{- EXAMPLES: -}
-- priority queue based on lists
priority_queue_1 :: Ord t => ListPriorityQueue t
priority_queue_1 = PQ [] List.insert (\ls -> (head ls, tail ls))
instance EmptyCheckable [t] where
is_empty = List.null
-- priority queue based on sets
priority_queue_2 :: Ord t => PriorityQueue Set.Set t
priority_queue_2 = PQ Set.empty Set.insert Set.deleteFindMin
instance EmptyCheckable (Set.Set t) where
is_empty = Set.null
-- an arbitrary type and a queue specially designed for it
data ABC = A | B | C deriving (Eq, Ord, Show)
-- priority queue based on counting
data PQ3 t = PQ3 Integer Integer Integer
priority_queue_3 :: PriorityQueue PQ3 ABC
priority_queue_3 = PQ new push pop
where
new = (PQ3 0 0 0)
push A (PQ3 a b c) = (PQ3 (a+1) b c)
push B (PQ3 a b c) = (PQ3 a (b+1) c)
push C (PQ3 a b c) = (PQ3 a b (c+1))
pop (PQ3 0 0 0) = undefined
pop (PQ3 0 0 c) = (C, (PQ3 0 0 (c-1)))
pop (PQ3 0 b c) = (B, (PQ3 0 (b-1) c))
pop (PQ3 a b c) = (A, (PQ3 (a-1) b c))
instance EmptyCheckable (PQ3 t) where
is_empty (PQ3 0 0 0) = True
is_empty _ = False
{- MAIN: -}
main :: IO ()
main = do
print $ list_selection_sort priority_queue_1 [2, 3, 1]
-- print $ list_selection_sort priority_queue_2 [2, 3, 1] -- fail
-- print $ list_selection_sort priority_queue_3 [B, C, A] -- fail
print $ abstract_selection_sort (APQ priority_queue_1) [B, C, A] -- APQ hides the queue
print $ abstract_selection_sort (APQ priority_queue_2) [B, C, A] -- behind the layer of abstraction
-- print $ abstract_selection_sort (APQ priority_queue_3) [B, C, A] -- fail
print $ generalized_selection_sort priority_queue_1 [2, 3, 1]
print $ generalized_selection_sort priority_queue_2 [B, C, A]
print $ generalized_selection_sort priority_queue_3 [B, C, A]-- power of generalization
-- fail
-- print $ let f q = (list_selection_sort q [2,3,1], list_selection_sort q [B,C,A])
-- in f priority_queue_1
-- power of abstraction (rank-n-types actually, but never mind)
print $ let f q = (abstract_selection_sort q [2,3,1], abstract_selection_sort q [B,C,A])
in f (APQ priority_queue_1)
-- fail
-- print $ let f q = (generalized_selection_sort q [2,3,1], generalized_selection_sort q [B,C,A])
-- in f priority_queue_1
Le code est également disponible via pastebin.
Les types existentiels méritent d'être remarqués. Comme @lukstafi l'a déjà souligné, l'abstraction est similaire au quantificateur existentiel et la généralisation est similaire au quantificateur universel. Observez qu'il existe un lien non trivial entre le fait que ∀X. P (x) implique ∃X. P(x) (dans un univers non vide), et que il y a rarement une généralisation sans abstraction (même les fonctions surchargées de type C++forment une sorte d'abstraction dans un certain sens).
Crédits: Portail gâteau par Solo . Table à Dessert par djttwo . Le symbole était basé sur l'œuvre D'artPortal .
Une question très intéressante en effet. J'ai trouvé cet article sur le sujet, qui stipule de manière concise que:
Alors que l'abstraction réduit la complexité en masquant des détails non pertinents, la généralisation réduit la complexité en remplaçant plusieurs entités qui exécutent des fonctions similaires par une seule construction.
Prenons l'ancien exemple d'un système qui gère les livres pour une bibliothèque. Un livre a des tonnes de propriétés (nombre de pages, poids, taille(S), couvrir,...) mais pour les besoins de notre bibliothèque, nous ne pouvons avoir besoin
Book(title, ISBN, borrowed)
Nous venons de faire abstraction des vrais livres de notre bibliothèque, et nous n'avons pris que les propriétés qui nous intéressaient dans le contexte de notre application.
La généralisation d'autre part ne cherche pas à supprimer des détails mais à rendre la fonctionnalité applicable à une gamme plus large (plus générique) d'éléments. Les conteneurs génériques sont un très bon exemple pour cet état d'Esprit: vous ne voudriez pas écrire une implémentation de StringList, IntList, et ainsi de suite, c'est pourquoi vous préférez écrire une liste Générique qui s'applique à tous les types (comme List[T] dans Scala). Notez que vous n'avez pas abstrait la liste, parce que vous n'avez pas supprimé de détails ou d'opérations, vous les avez simplement rendus génériquement applicables à tous vos types.
Ronde 2
La réponse de@dtldarek est vraiment une très bonne illustration! Sur cette base, voici un code qui pourrait fournir des éclaircissements supplémentaires.
Rappelez-vous le Book je mentionné? Bien sûr, il y a d'autres choses dans une bibliothèque que l'on peut emprunter (j'appellerai l'ensemble de tous ces objets Borrowable même si ce n'est probablement même pas un mot: D):
Http://f.cl.ly/items/3z0f1S3g1h1m2u3c0l0g/diagram.png
{kind=link}
Tous ces éléments auront une représentation abstract dans notre base de données et notre logique métier, probablement similaire à celle de notre Book. De plus, nous pourrions définir un trait commun à tous les Borrowable s:
trait Borrowable {
def itemId:Long
}
Nous pourrait alors écrire logique généralisée qui s'applique à tous les Borrowables (à ce stade, nous ne nous soucions pas si c'est un livre ou un magazine):
object Library {
def lend(b:Borrowable, c:Customer):Receipt = ...
[...]
}
Pour résumer: nous avons stocké une représentation abstraite de tous les livres, magazines et DVD de notre base de données, car une représentation exacte n'est ni réalisable ni nécessaire. Nous sommes ensuite allés de l'avant et dit
Peu importe qu'un livre, un magazine ou un DVD soit emprunté par un client. C'est toujours la même processus.
Ainsi nous généralisons l'opération d'emprunt d'un article, en définissant tout ce que l'on peut emprunter comme BorrowableS.
Je vais utiliser quelques exemples pour décrire la généralisation et l'abstraction, et je vais me référer à Cet article.
À ma connaissance, il n'y a pas de source officielle pour la définition de l'abstraction et de la généralisation dans le domaine de la programmation (Wikipédia est probablement la plus proche d'une définition officielle à mon avis), donc j'ai plutôt utilisé un article que je juge crédible.
La Généralisation
L'article stipule que:
" le concept de généralisation en POO signifie qu'un objet encapsule état et comportement communs pour une catégorie d'objets."
Par exemple, si vous appliquez une généralisation aux formes, les propriétés communes pour tous les types de forme sont area et perimeter.
Par conséquent, une forme généralisée (par exemple la forme) et les spécialisations de celle-ci (par exemple un cercle), peuvent être représentées dans les classes comme suit (notez que cette image a été tirée de ce qui précède de l'article)
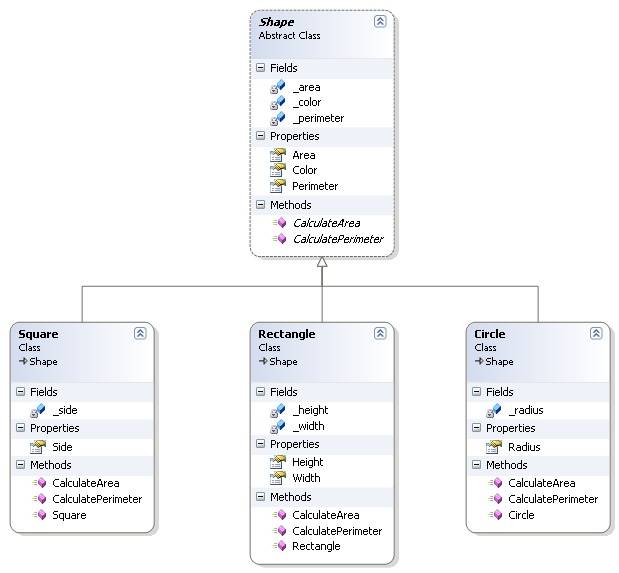
De même, si vous travaillez dans le domaine des avions à réaction, vous pourriez avoir un Jet comme une généralisation, qui aurait une propriété d'envergure. Une spécialisation d'un Jet pourrait être un FighterJet, qui hériterait de la propriété d'envergure et aurait sa propre propriété unique aux avions de combat, par exemple NumberOfMissiles.
Abstraction
L'article définit l'abstraction comme suit:
"le processus d'identification des modèles communs systématique variations; une abstraction représente le modèle commun et fournit un moyen pour spécifier quelle variation utiliser"(Richard Gabriel) "
Dans le domaine de la programmation:
Une classe abstraite est une classe parente qui autorise l'héritage mais peut ne jamais être instancié.
Par conséquent, dans l'exemple donné dans la section de généralisation ci-dessus, une forme est abstraite comme:
Dans le monde réel, vous ne calculez jamais la surface ou périmètre d'un forme générique, vous devez savoir quel type de forme géométrique vous avez parce que chaque forme (par exemple. carré, cercle, rectangle, etc. dispose de sa propre formules de zone et de périmètre.
Cependant, en plus d'être abstraite, une forme est aussi une généralisation (car elle "encapsule l'état et le comportement communs pour une catégorie d'objets" où dans ce cas les objets sont des formes).
Pour en revenir à l'exemple que j'ai donné sur les Jets et les FighterJets, un Jet n'est pas résumé le béton instance d'un Jet est possible, comme on peut exister dans le monde réel, contrairement à une forme c'est à dire dans le monde réel, vous ne pouvez pas tenir une forme que vous maintenez une instance d'une forme par exemple d'un cube. Ainsi, dans l'avion exemple, un Jet n'est pas abstrait, c'est une généralisation, comme il est possible d'avoir un "béton" instance d'un jet.
Ne s'adressant pas à une source crédible / officielle: un exemple dans Scala
Ayant "Abstraction"
trait AbstractContainer[E] { val value: E }
object StringContainer extends AbstractContainer[String] {
val value: String = "Unflexible"
}
class IntContainer(val value: Int = 6) extends AbstractContainer[Int]
val stringContainer = new AbstractContainer[String] {
val value = "Any string"
}
Et "Généralisation"
def specialized(c: StringContainer.type) =
println("It's a StringContainer: " + c.value)
def slightlyGeneralized(s: AbstractContainer[String]) =
println("It's a String container: " + s.value)
import scala.reflect.{ classTag, ClassTag }
def generalized[E: ClassTag](a: AbstractContainer[E]) =
println(s"It's a ${classTag[E].toString()} container: ${a.value}")
import scala.language.reflectiveCalls
def evenMoreGeneral(d: { def detail: Any }) =
println("It's something detailed: " + d.detail)
Exécution
specialized(StringContainer)
slightlyGeneralized(stringContainer)
generalized(new IntContainer(12))
evenMoreGeneral(new { val detail = 3.141 })
Conduit à
It's a StringContainer: Unflexible
It's a String container: Any string
It's a Int container: 12
It's something detailed: 3.141
Abstraction
L'Abstraction spécifie le cadre et cache les informations de niveau d'implémentation. Le concret sera construit au-dessus de l'abstraction. Il vous donne un plan à suivre lors de la mise en œuvre des détails. Abstraction réduit la complexité en masquant les détails de bas niveau.
Exemple: un modèle de cadre métallique d'une voiture.
Généralisation
La généralisation utilise une relation "is-a" d'une spécialisation à la classe de généralisation. Commun la structure et le comportement sont utilisés de la spécialisation à la classe généralisée. À un niveau très large, vous pouvez comprendre cela comme héritage. Pourquoi je prends le terme héritage est, vous pouvez rapporter ce terme très bien. La généralisation est aussi appelée une relation "est-a".
Exemple: considérez qu'il existe une classe nommée Person. Un étudiant est une personne. Une faculté est une personne. Par conséquent, ici, la relation entre l'étudiant et la personne, de même la faculté et la personne est la généralisation.
Je voudrais offrir une réponse pour le plus grand public possible, donc j'utilise la Lingua Franca du web, Javascript.
Commençons par un morceau ordinaire de code impératif:
// some data
const xs = [1,2,3];
// ugly global state
const acc = [];
// apply the algorithm to the data
for (let i = 0; i < xs.length; i++) {
acc[i] = xs[i] * xs[i];
}
console.log(acc); // yields [1, 4, 9]Dans l'étape suivante, j'introduis l'abstraction la plus importante dans la programmation-fonctions. Fonctions abstraites sur les expressions:
// API
const foldr = f => acc => xs => xs.reduceRight((acc, x) => f(x) (acc), acc);
const concat = xs => ys => xs.concat(ys);
const sqr_ = x => [x * x]; // weird square function to keep the example simple
// some data
const xs = [1,2,3];
// applying
console.log(
foldr(x => acc => concat(sqr_(x)) (acc)) ([]) (xs) // [1, 4, 9]
)Comme vous pouvez le voir, beaucoup de détails d'implémentation sont abstraits. L'Abstraction des moyens la suppression des détails .
Une autre étape d'abstraction...
// API
const comp = (f, g) => x => f(g(x));
const foldr = f => acc => xs => xs.reduceRight((acc, x) => f(x) (acc), acc);
const concat = xs => ys => xs.concat(ys);
const sqr_ = x => [x * x];
// some data
const xs = [1,2,3];
// applying
console.log(
foldr(comp(concat, sqr_)) ([]) (xs) // [1, 4, 9]
);Et un autre:
// API
const concatMap = f => foldr(comp(concat, f)) ([]);
const comp = (f, g) => x => f(g(x));
const foldr = f => acc => xs => xs.reduceRight((acc, x) => f(x) (acc), acc);
const concat = xs => ys => xs.concat(ys);
const sqr_ = x => [x * x];
// some data
const xs = [1,2,3];
// applying
console.log(
concatMap(sqr_) (xs) // [1, 4, 9]
);Le principe sous-jacent doit maintenant être clair. Je suis toujours insatisfait de concatMap, car cela ne fonctionne qu'avec Array s. Je veux que cela fonctionne avec tous les types de données pliables:
// API
const concatMap = foldr => f => foldr(comp(concat, f)) ([]);
const concat = xs => ys => xs.concat(ys);
const sqr_ = x => [x * x];
const comp = (f, g) => x => f(g(x));
// Array
const xs = [1, 2, 3];
const foldr = f => acc => xs => xs.reduceRight((acc, x) => f(x) (acc), acc);
// Option (another foldable data type)
const None = r => f => r;
const Some = x => r => f => f(x);
const foldOption = f => acc => tx => tx(acc) (x => f(x) (acc));
// applying
console.log(
concatMap(foldr) (sqr_) (xs), // [1, 4, 9]
concatMap(foldOption) (sqr_) (Some(3)), // [9]
concatMap(foldOption) (sqr_) (None) // []
);I a élargi l'application de concatMap pour englober un plus grand domaine de données types, nameley tous les types de données pliables. La généralisation met l'accent sur les points communs entre différents types, (ou plutôt des objets, des entités).
J'ai réalisé ceci au moyen du passage du dictionnaire (l'argument supplémentaire deconcatMap dans mon exemple). Maintenant, il est un peu ennuyeux de passer ces dicts de type tout au long de votre code. Par conséquent, les gens de Haskell ont introduit des classes de type à, ...euh, résumé par type dicts:
concatMap :: Foldable t => (a -> [b]) -> t a -> [b]
concatMap (\x -> [x * x]) ([1,2,3]) -- yields [1, 4, 9]
concatMap (\x -> [x * x]) (Just 3) -- yields [9]
concatMap (\x -> [x * x]) (Nothing) -- yields []
Ainsi, le générique de Haskell concatMap bénéficie à la fois de l'abstraction et de généralisation.
Laissez-moi vous expliquer de la manière la plus simple possible.
"Toutes les jolies filles sont des femmes."est une abstraction.
"Toutes les jolies filles se maquillent."est une généralisation.
L'Abstraction consiste généralement à réduire la complexité en éliminant les détails inutiles. Par exemple, une classe abstraite dans OOP est une classe parent qui contient des caractéristiques communes de ses enfants mais ne spécifie pas la fonctionnalité exacte.
La généralisation ne nécessite pas nécessairement d'éviter les détails mais plutôt d'avoir un mécanisme permettant d'appliquer la même fonction à un argument différent. Par exemple, les types polymorphes dans les langages de programmation fonctionnels vous permettent de ne pas dérangez-vous sur les arguments, concentrez-vous plutôt sur le fonctionnement de la fonction. De même, en java, vous pouvez avoir un type générique qui est un "parapluie" à tous les types alors que la fonction est la même.