Quelle est la différence entre NoSQL et une base de données axée sur les colonnes?
plus j'en apprends sur NoSQL, plus ça commence à ressembler à une base de données orientée colonne pour moi.
Quelle est la différence entre NoSQL (par ex. CouchDB, Cassandra, MongoDB) et une base de données orientée colonne (par ex. Vertica, MonetDB)?
7 réponses
certaines bases de données NoSQL sont des bases de données à colonnes, et certaines bases de données SQL sont également à colonnes. Que la base de données soit orientée colonne ou ligne est un détail d'implémentation de stockage physique de la base de données et peut être vrai à la fois des bases de données relationnelles et non relationnelles (NoSQL).
Vertica, par exemple, est une base de données relationnelle orientée sur les colonnes, donc elle ne se qualifierait pas réellement comme un datastore NoSQL.
un datastore "NoSQL movement" est mieux défini comme être une base de données non relationnelle, partagée-rien, horizontalement évolutive sans (nécessairement) garanties acides. Certaines bases de données axées sur les colonnes peuvent être caractérisées de cette façon. En plus des stocks de colonnes, les implémentations NoSQL incluent également les magasins de documents, les magasins d'objets, les magasins de tuples et les magasins de graphiques.
NoSQL est le terme utilisé pour non seulement SQL, qui couvre quatre grandes catégories - Clé-Valeur, un Document, une Famille de Colonne et le Graphique de bases de données.
- les bases de données sont bien adaptées aux applications qui ont fréquemment de petites lectures et écritures avec des modèles de données simples. Ces enregistrements sont stockés et récupérés à l'aide d'une clé qui identifie l'enregistrement de façon unique, et est utilisé pour trouver rapidement les données dans la base de données.
par exemple Redis, Riak etc.
bases de données de documents ont la capacité de stocker des attributs variables avec de grandes quantités de données
par exemple MongoDB, CouchDB etc.
famille de colonnes les bases de données sont conçues pour de grands volumes de données, lire et écrire la performance, et la haute disponibilité
e.g Cassandra, HBase etc.
graphe la base de données est une base de données qui utilise des structures de graphe pour des requêtes sémantiques avec des noeuds, des bords et des propriétés pour représenter et stocker des données
E. g Neo4j, InfiniteGraph etc.
avant de comprendre NoSQL, vous devez comprendre certains concepts clés.
consistance - tous les serveurs du système auront les mêmes données de sorte que quiconque utilisant le système obtiendra la même copie quel que soit le serveur qui répond à leur demande.
Disponibilité - le système répondra toujours à une demande (même si ce ne sont pas les données les plus récentes ou cohérentes à travers le système ou juste un message disant que le système ne fonctionne pas) .
Tolérance De Partition - le système continue de fonctionner comme un tout même si les serveurs individuels échouent ou ne peuvent pas être atteints.
la plupart du temps, seulement deux au-dessus de trois propriétés seront satisfaits par NoSQL bases de données.
à Partir de votre question,
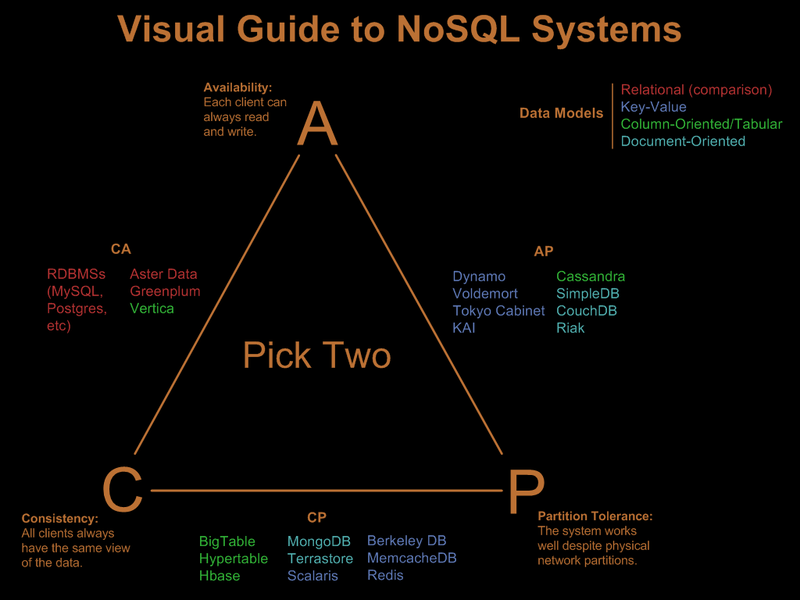
CouchDB: AP (disponibility & Partition) & document database
Cassandra: AP (disponibility & Partition) & Column family database
MongoDB: CP ( de la Cohérence Et de la Partition) Et le Document de base de données
Vertica: CA ( Cohérence & Disponibilité) & base de données des familles de colonnes
MonetDB: acide (atomicité Consistency Isolation durabilité) & Base de données relationnelles
:http://blog.nahurst.com/visual-guide-to-nosql-systems
jetez un oeil à cette article 1,article 2 et ppt pour divers scénarios pour sélectionner un type particulier de la base de données.
une base de données NoSQL est un paradigme différent des bases de données traditionnelles basées sur des schémas. Ils sont conçus pour dimensionner et contenir des documents comme les données json. Évidemment, ils ont une façon d'interroger l'information, mais vous devriez vous attendre à une syntaxe comme eval("person = * and age > 10) pour extraire des données. Même s'ils prennent en charge l'interface SQL standard, ils sont destinés à autre chose, donc si vous aimez SQL, vous devriez vous en tenir aux bases de données traditionnelles.
une base de données axée sur les colonnes est différente de les bases de données traditionnelles axées sur les rangées en raison de la façon dont elles emmagasinent les données. En stockant une colonne entière ensemble au lieu d'une rangée, vous pouvez minimiser l'accès au disque lors de la sélection de quelques colonnes à partir d'une rangée contenant plusieurs colonnes. Dans les bases de données orientées en ligne, il n'y a pas de différence si vous sélectionnez seulement un ou tous les champs d'une ligne.
vous devez payer pour un insert Plus cher cependant. L'insertion d'une nouvelle ligne provoquera de nombreuses opérations disque, en fonction du nombre de colonnes.
Mais il y a aucune différence avec les bases de données traditionnelles en termes de SQL, acide, clés étrangères et des trucs comme ça.
je suggère la lecture de l' section taxonomie de l'entrée NoSQL wikipedia pour avoir une idée de la façon dont les différentes bases de données NoSQL sont à partir d'une base de données traditionnelle orientée schema. Le fait d'être orienté vers les colonnes implique des rangées et des colonnes, ce qui implique un schéma (bidimensionnel), tandis que les bases de données NoSQL ont tendance à être sans schéma (stockage de valeurs de clés) ou à avoir des contenus structurés, mais sans schéma formel (stockage de documents).
pour les magasins de documents, la structure et le contenu chaque "document" sont indépendants des autres documents de la même "collection". Ajouter un champ est habituellement un changement de code plutôt qu'un changement de base de données: les nouveaux documents reçoivent une entrée pour le nouveau champ, tandis que les documents plus anciens sont considérés comme ayant une valeur nulle pour le champ inexistant. De même, "supprimer" un champ pourrait signifier que vous arrêtez tout simplement de vous y référer dans votre code plutôt que d'aller à la peine de le supprimer de chaque document (à moins que l'espace est à un supplément, et alors vous avez l'option de supprimer seulement ceux qui ont le contenu le plus grand). Comparez ceci à la façon dont une table entière doit être changée pour ajouter ou supprimer une colonne dans une base de données ligne/colonne traditionnelle.
les Documents peuvent aussi contenir des listes ainsi que d'autres documents imbriqués. Voici un exemple de document de MongoDB (un billet d'un blog ou d'un autre forum), représenté comme JSON:
{
_id : ObjectId("4e77bb3b8a3e000000004f7a"),
when : Date("2011-09-19T02:10:11.3Z"),
author : "alex",
title : "No Free Lunch",
text : "This is the text of the post. It could be very long.",
tags : [ "business", "ramblings" ],
votes : 5,
voters : [ "jane", "joe", "spencer", "phyllis", "li" ],
comments : [
{ who : "jane", when : Date("2011-09-19T04:00:10.112Z"),
comment : "I agree." },
{ who : "meghan", when : Date("2011-09-20T14:36:06.958Z"),
comment : "You must be joking. etc etc ..." }
]
}
notez comment "comments" est une liste de documents imbriqués avec leur propre structure indépendante. Les requêtes peuvent "atteindre" ces documents du document externe, par exemple pour trouver des billets qui ont des commentaires de Jane, ou des billets avec des commentaires d'une certaine date.
donc, en résumé, deux des principales différences typiques des bases de données NoSQL sont l'absence d'un schéma (formel) et de contenus qui vont au-delà de l'orientation bidimensionnelle d'une base de données traditionnelle ligne/colonne.
distinction entre les magasins coloumn lire ce blog. Ceci répond à votre question.
comme l'a écrit @tuinstoel, le article répond à votre question au point 3:
3. Interface. le groupe a se distingue en faisant partie du NoSQL et ne se déplace pas habituellement avoir une interface SQL traditionnelle. Le groupe B supporte le SQL standard interface.
Voici comment je le vois: les bases de données axées sur les colonnes traitent de la façon dont les données sont stockées physiquement sur le disque. Comme son nom l'indique, chaque colonne est stockée dans son propre espace séparé/fichier. Cela permet 2 choses importantes:
- vous obtenez un meilleur taux de compression de l'ordre de 10:1 parce que vous avez un type de données unique à traiter.
- vous obtenez de meilleures performances de lecture de données parce que vous évitez les scans de rang entier et pouvez simplement choisir et choisir les colonnes spécifié dans votre requête SELECT.
NoSQL d'un autre côté sont une toute nouvelle race de bases de données qui définissent des niveaux agrégés "logiques" pour expliquer les données. Certains traitent les données comme ayant une relation hiérachique (agrégat étant un "noeud"), tandis que l'autre traitent les données comme des documents (qui est le niveau agrégé). Elles ne dictent pas la stratégie de stockage physique (certaines peuvent le faire, mais sont abstraites pour l'utilisateur final).
en outre, tout le mouvement NoSQL est plus font avec des données non structurées, ou plutôt des ensembles de données dont le schéma ne peut pas être prédéfini, ou dans l'inconnu au préalable, et donc ne peut pas se conformer au modèle relationnel strict.
les bases de données axées sur les colonnes traitent encore des données relationnelles, bien qu'elles éliminent le besoin d'index, etc.