Quel est le but de mélanger et de trier la phase dans le réducteur dans la programmation Map Reduce?
Dans la programmation Map Reduce, la phase reduce a été mélangée, triée et réduite comme sous-parties. Le tri est une affaire coûteuse.
Quel est le but de mélanger et de trier la phase dans le réducteur dans la programmation Map Reduce?
9 réponses
Tout d'abord shuffling est le processus de transfert de données des mappeurs aux réducteurs, donc je pense qu'il est évident que c'est nécessaire pour les réducteurs, car sinon, ils ne seraient pas en mesure d'avoir une entrée (ou une entrée de chaque mappeur). Le brassage peut commencer avant même la fin de la phase de la carte, pour gagner du temps. C'est pourquoi vous pouvez voir un statut de réduction supérieur à 0% (mais inférieur à 33%) lorsque l'état de la carte n'est pas encore 100%.
Sorting gain de temps pour le réducteur, l'aidant distinguer facilement quand une nouvelle tâche de réduction devrait commencer. Il démarre simplement une nouvelle tâche de réduction, lorsque la clé suivante dans les données d'entrée triées est différente de la précédente, pour le dire simplement. Chaque tâche reduce prend une liste de paires clé-valeur, mais elle doit appeler la méthode reduce () qui prend une entrée key-list(value), elle doit donc regrouper les valeurs par clé. C'est facile à faire, si les données d'entrée sont pré-triées (localement) dans la phase map et simplement triées par fusion dans la phase reduce (puisque les réducteurs obtiennent des données de beaucoup de cartographes).
Partitioning, que vous avez mentionné dans une des réponses, est un processus différent. Il détermine dans quel réducteur une paire (clé, valeur), sortie de la phase de la carte, sera envoyée. Le partitionneur par défaut utilise un hachage sur les clés pour les distribuer aux tâches de réduction, mais vous pouvez le remplacer et utiliser votre propre partitionneur personnalisé.
Une excellente source d'information pour ces étapes est ce Yahoo tutoriel.
Une belle représentation graphique de ceci est le suivant (shuffle est appelé "copier" dans cette figure):
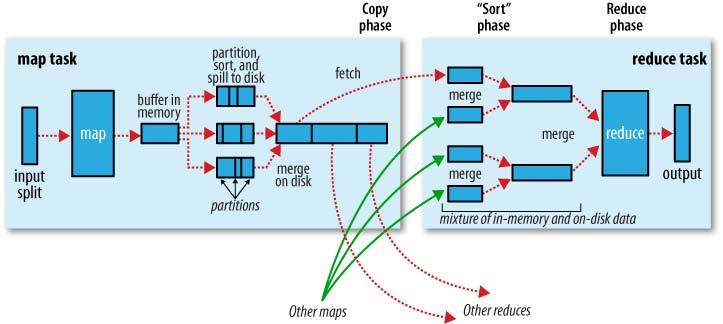
Notez que shuffling et sorting ne sont pas du tout exécutés si vous spécifiez des réducteurs zéro (setNumReduceTasks(0)). Ensuite, le travail MapReduce s'arrête à la phase map, et la phase map n'inclut aucun type de tri (donc même la phase map est plus rapide).
UPDATE: puisque vous cherchez quelque chose de plus officiel, vous pouvez également lire le livre de Tom White "Hadoop: The Definitive Guide". Voici la partie intéressante de votre question.
Tom White a été un Apache Hadoop committer depuis février 2007, et est membre de L'Apache Software Foundation, donc je suppose que c'est assez crédible et officiel...
Revoyons les phases clés du programme Mapreduce.
La phase de la carte est effectuée par les mappeurs. les mappeurs s'exécutent sur des paires clé/valeurs d'entrée non triées. Chaque mappeur émet zéro, une ou plusieurs paires clé/valeur de sortie pour chaque paire clé/valeur d'entrée.
La phase de combinaison est effectuée par des combineurs. Le combineur {[6] } doit combiner des paires clé / valeur avec la même clé. Chaque combineur peut exécuter zéro, une fois ou plusieurs fois.
Le mélanger et trier phase est fait par le cadre. Les données de tous les mappeurs sont regroupées par clé, réparties entre les réducteurs et triées par clé. Chaque réducteur obtient toutes les valeurs associées à la même clé. Le programmeur peut fournir des fonctions de comparaison personnalisées pour le tri et un partitionneur pour le partage de données.
Le partitionneur décide quel réducteur obtiendra une paire clé-valeur particulière.
Le réducteur obtient des paires clé/[liste de valeurs] triées par la clé. La liste de valeurs contient toutes les valeurs avec la même clé produite par les mappeurs. Chaque réducteur émet zéro, une ou plusieurs paires clé/valeur de sortie pour chaque paire clé/valeur d'entrée .
Jetez un oeil à cet article javacodegeeks par Maria Jurcovicova et mssqltips article par Datta pour une meilleure compréhension
Ci-Dessous est l'image de safaribooksonline article
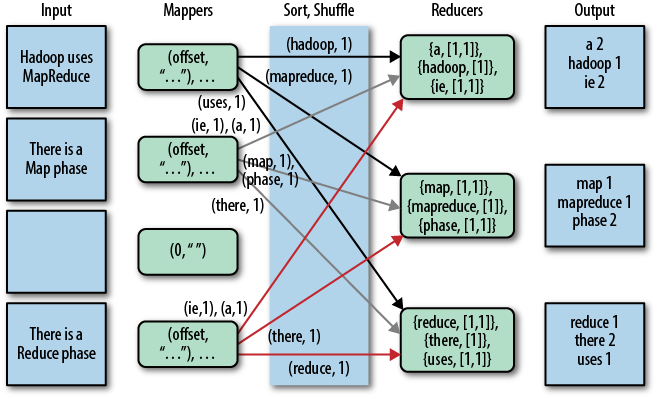
J'ai pensé juste ajouter quelques points manquants dans les réponses ci-dessus. Ce diagramme tiré de ici indique clairement ce qui se passe réellement.
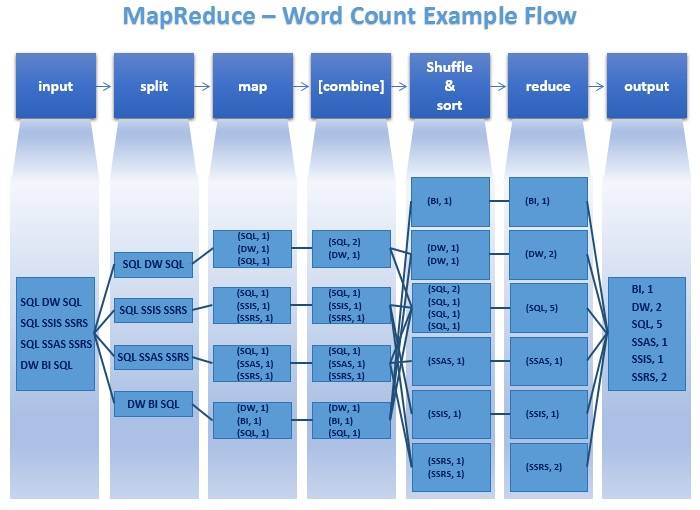
Si je déclare à nouveau le but réel de
Split: améliore le traitement parallèle en répartissant la charge de traitement entre différents nœuds (mappeurs), ce qui économiserait le temps de traitement global.
Combiner: Rétrécit la sortie de chaque Mappeur. Cela économiserait du temps pour déplacer les données d'un nœud à un autre.
Sort (Shuffle & Sort): permet à l'exécution de planifier facilement (spawn/start) de nouveaux réducteurs, où en parcourant la liste des éléments triés, chaque fois que la clé actuelle est différente de la précédente, elle peut générer un nouveau réducteur.
Certaines des exigences de traitement des données n'ont pas besoin de tri du tout. Syncsort avait rendu le tri dans Hadoop enfichable. Voici un joli blog d'eux sur le tri. Le processus de déplacement des données des mappeurs vers les réducteurs est appelé shuffling, consultez Cet article pour plus d'informations sur le même.
J'ai toujours supposé que cela était nécessaire car la sortie du mappeur est l'entrée du réducteur, donc elle a été triée en fonction de l'espace de clés, puis divisée en compartiments pour chaque entrée du réducteur. Vous voulez vous assurer que toutes les mêmes valeurs d'une clé se retrouvent dans le même compartiment allant au réducteur afin qu'elles soient réduites ensemble. Il est inutile d'envoyer K1, V2 et K1, V4 à différents réducteurs car ils doivent être ensemble pour être réduits.
Essayé de l'expliquer aussi simplement que possible
Shuffling est le processus par lequel les données intermédiaires des mappeurs sont transférées à 0,1 ou plusieurs réducteurs. Chaque réducteur reçoit 1 ou plusieurs clés et ses valeurs associées en fonction du nombre de réducteurs (pour une charge équilibrée). De plus, les valeurs associées à chaque clé sont triées localement.
Il N'y a que deux choses que MapReduce fait nativement: Sort et (implémenté par sort) GroupBy évolutif.
La plupart des applications et des modèles de conception sur MapReduce sont construits sur ces deux opérations, qui sont fournies par shuffle et sort.
Ce est une bonne lecture. Espérons que cela aide. En termes de tri, je pense que c'est pour l'opération de fusion dans la dernière étape de la carte. Lorsque l'opération de carte est terminée, et que vous devez écrire le résultat sur le disque local, une fusion multiple sera opérée sur les splits générés à partir du tampon. Et pour une opération de fusion, le tri de chaque partition dans advanced est utile.
Eh bien, Dans Mapreduce il y a deux phrases appelé Mappeur et réducteur les deux sont trop importants, mais le Réducteur est obligatoire. Dans certains programmes réducteurs sont facultatifs. Maintenant, venez à votre question. Le brassage et le tri sont deux opérations importantes dans Mapreduce. Le premier framework Hadoop prend des données structurées/non structurées et sépare les données en clé, valeur.
Maintenant, le programme mapper sépare et arrange les données en clés et valeurs à traiter. Générer La Clé 2 et valeur 2 valeurs. Ces valeurs doivent traiter et réorganiser dans le bon ordre pour obtenir la solution désirée. Maintenant, ce shuffle et le tri fait dans votre système local (Framework prendre soin) et le processus dans le système local après le nettoyage du cadre de processus les données dans le système local. Ok
Ici, nous utilisons combineur et partition également pour optimiser ce processus de lecture aléatoire et de tri. Après un arrangement approprié, ces valeurs clés passent au réducteur pour obtenir la sortie du Client souhaité. Enfin Réducteur obtenir la sortie souhaitée.
K1, V1 -> K2, V2 (nous allons écrire programme Mapper), - > K2, V '( ici aléatoire et doux les données) - > K3, V3 Générer la sortie. K4, V4.
Veuillez noter que toutes ces étapes sont une opération logique uniquement, ne pas modifier les données d'origine.
Votre question: Quel est le but de la phase de brassage et de tri dans le réducteur dans la programmation Map Reduce?
Réponse courte: pour traiter les données pour obtenir la sortie souhaitée. Mélanger est agréger les données, Réduire est obtenir sortie attendue.