Quel est l'algorithme optimal pour le jeu 2048?
j'ai récemment trébuché sur le jeu 2048 . Vous fusionnez des tuiles similaires en les déplaçant dans l'une des quatre directions pour faire des tuiles "plus grandes". Après chaque déplacement, une nouvelle tuile apparaît en position vide aléatoire avec une valeur de 2 ou 4 . Le jeu se termine lorsque toutes les cases sont remplies et il n'y a pas de mouvements qui peuvent fusionner des tuiles, ou vous créez une tuile avec une valeur de 2048 .
un, je dois suivre un stratégie bien définie pour atteindre l'objectif. Donc, j'ai pensé à écrire un programme pour ça.
mon algorithme actuel:
while (!game_over) {
for each possible move:
count_no_of_merges_for_2-tiles and 4-tiles
choose the move with a large number of merges
}
ce que je fais est à tout moment, je vais essayer de fusionner les tuiles avec les valeurs 2 et 4 , c'est-à-dire, j'essaie d'avoir 2 et 4 tuiles, aussi minimum que possible. Si je l'essaye de cette façon, toutes les autres tuiles étaient automatiquement fusionnées et la stratégie semble bonne.
mais, quand j'utilise cet algorithme, je n'obtiens qu'environ 4000 points avant la fin du jeu. Points maximum AFAIK est légèrement plus de 20.000 points ce qui est beaucoup plus grand que mon score actuel. Est-il un meilleur algorithme que ceux ci-dessus?
14 réponses
j'ai développé un AI 2048 en utilisant l'optimisation expectimax , au lieu de la recherche minimax utilisée par l'algorithme de @ovolve. L'IA effectue simplement la maximisation sur tous les mouvements possibles, suivie par l'attente sur tous les fraiements possibles de tuile (pondérée par la probabilité des tuiles, c.-à-d. 10% pour un 4 et 90% pour un 2). Pour autant que je sache, il n'est pas possible de prune optimisation expectimax (sauf pour enlever les branches qui sont excessivement peu probable), et donc l'algorithme on utilise une recherche de force brute soigneusement optimisée.
Performance
L'IA dans sa configuration par défaut (profondeur de recherche max de 8) prend n'importe où de 10ms à 200ms pour exécuter un mouvement, en fonction de la complexité de la position de la carte. Dans les tests, L'IA atteint un taux de déplacement moyen de 5-10 mouvements par seconde au cours d'un jeu entier. Si la profondeur de recherche est limitée à 6 mouvements, L'IA peut facilement exécuter 20 + mouvements par seconde, ce qui permet certains intéressant regarder .
pour évaluer le score de performance de L'IA, j'ai exécuté l'IA 100 fois (connecté au jeu du navigateur via télécommande). Pour chaque vignette, voici les proportions de jeux dans lesquels cette tuile a été réalisée au moins une fois:
2048: 100%
4096: 100%
8192: 100%
16384: 94%
32768: 36%
la note minimale pour toutes les descentes était de 124024; la note maximale obtenue était de 794076. Le score médian est de 387222. L'IA n'a jamais manqué d'obtenir la tuile 2048 (donc il jamais perdu le jeu, même une fois dans 100 jeux); en fait, il a atteint le 8192 la tuile au moins une fois dans chaque course!
Voici la capture d'écran de la meilleure course:

ce jeu a pris 27830 mouvements sur 96 minutes, soit une moyenne de 4,8 mouvements par seconde.
mise en œuvre
mon approche encode toute la carte (16 entrées) comme un un seul entier de 64 bits (où les tuiles sont les nybbles, c.-à-d. les morceaux de 4 bits). Sur une machine 64 bits, cela permet de passer la totalité de la carte dans un seul registre de machine.
Les opérations de décalage de bitssont utilisées pour extraire des lignes et des colonnes individuelles. Une seule ligne ou colonne est un 16 bits, donc un tableau de taille 65536 peut encoder des transformations qui opèrent sur une seule ligne ou colonne. Par exemple, les mouvements sont implémentés sous forme de 4 Lookup dans une table d'effet de déplacement précomputée." qui décrit comment chaque mouvement affecte une seule ligne ou colonne (par exemple, le tableau "déplacer à droite" contient la mention "1122 -> 0023" qui décrit comment la ligne [2,2,4,4] devient la ligne [0,0,4,8] lorsqu'elle est déplacée à droite).
Le pointageest également effectué à l'aide d'une recherche de table. Les tableaux contiennent les scores heuristiques calculés sur toutes les lignes/colonnes possibles, et la note résultante pour un tableau est simplement la somme des valeurs du tableau pour chaque ligne et Colonne.
This la représentation au Conseil d'administration, ainsi que l'approche de recherche de table pour le mouvement et la notation, permet à L'IA de rechercher un grand nombre d'états de jeu dans une courte période de temps (plus de 10.000.000 états de jeu par seconde sur un noyau de mon ordinateur portable mi-2011).
la recherche expectimax elle-même est codée comme une recherche récursive qui alterne entre les étapes "attente" (tester tous les emplacements possibles de tuile spawn et les valeurs, et la pondération de leurs scores optimisés par la probabilité de chaque possibilité), et les étapes de "maximisation" (tester tous les mouvements possibles et sélectionner celui qui a le meilleur score). La recherche d'arbre se termine lorsqu'elle voit une position déjà vue (en utilisant un table de transposition ), lorsqu'elle atteint une limite de profondeur prédéfinie, ou lorsqu'elle atteint un État de planche qui est hautement improbable (par exemple, il a été atteint en obtenant 6 "4" tuiles dans une rangée de la position de départ). La profondeur de recherche typique est de 4 à 8 mouvements.
Heuristics
Plusieurs heuristiques sont utilisées pour diriger l'algorithme d'optimisation vers des positions favorables. Le choix de l'heuristique a un impact énorme sur les performances de l'algorithme. Les diverses heuristiques sont pondérées et combinées en un score positionnel, qui détermine comment "bon" une position donnée de conseil est. La recherche d'optimisation visera alors à maximiser le score moyen de toutes les positions possibles du Conseil d'administration. Le score réel, comme le montre le jeu, est pas utilisé pour calculer la note du tableau, car il est trop fortement pondéré en faveur de la fusion des carreaux (lorsque la fusion retardée pourrait produire un grand avantage).
au départ, j'ai utilisé deux heuristiques très simples, accordant des "primes" pour les carrés ouverts et pour avoir de grandes valeurs sur le bord. Ces heuristiques ont fonctionné assez bien, atteignant fréquemment 16384 mais jamais à 32768.
Petr Morávek (@xificurk) a pris mon IA et a ajouté deux nouvelles heuristiques. Le premier heuristique était une pénalité pour avoir Non-rangées monotones et des colonnes qui ont augmenté que les rangs ont augmenté, assurant que les rangées non-monotones de petits nombres n'affecteraient pas fortement le score, mais non-rangées monotones de grands nombres blessent le score de façon substantielle. La deuxième heuristique a compté le nombre de fusions de potentiel (valeurs égales adjacentes) en plus des espaces ouverts. Ces deux heuristiques ont servi à pousser l'algorithme vers les cartes monotones (qui sont plus faciles à fusionner), et vers des positions du conseil avec des lots de fusions (l'encourageant à aligner les fusions lorsque c'est possible pour plus d'effet).
de plus, Petr a également optimisé les poids heuristiques en utilisant une stratégie de" méta-optimisation "(en utilisant un algorithme appelé CMA-ES ), où les poids eux-mêmes ont été ajustés pour obtenir le score moyen le plus élevé possible.
l'effet de ces changements est extrêmement significatif. L'algorithme est passé de la réalisation la tuile 16384 environ 13% du temps pour l'atteindre plus de 90% du temps, et l'algorithme a commencé à atteindre 32768 sur 1/3 du temps (alors que l'ancienne heuristique jamais une fois produit une tuile 32768).
je crois qu'il y a encore de la place pour l'amélioration heuristique. Cet algorithme n'est certainement pas encore "optimale", mais j'ai l'impression que c'est presque.
que L'IA réalise la 32768 tuile dans plus d'un tiers de son les jeux sont un grand Jalon; je serai surpris d'entendre si des joueurs humains ont atteint 32768 sur le jeu officiel (i.e. sans utiliser des outils comme savestates ou undo). Je pense que la tuile 65536 est à portée de main!
vous pouvez essayer L'IA pour vous-même. Le code est disponible à https://github.com/nneonneo/2048-ai .
je suis l'auteur du programme AI que d'autres ont mentionné dans ce fil. Vous pouvez voir L'IA dans action ou lire la source .
actuellement, le programme atteint un taux de GAIN d'environ 90% en cours d'exécution en javascript dans le navigateur sur mon ordinateur portable donné environ 100 millisecondes de temps de réflexion par mouvement, alors tout en pas parfait (encore!) il remplit assez bien.
puisque le jeu est un État discret espace, informations parfaites, jeu à tour de rôle comme les échecs et les dames, j'ai utilisé les mêmes méthodes qui ont fait leurs preuves sur ces jeux, à savoir minimax recherche avec alpha-beta pruning . Puisqu'il y a déjà beaucoup d'information sur cet algorithme là-bas, je vais juste parler des deux heuristiques principales que j'utilise dans le fonction d'évaluation statique et qui formalisent beaucoup des intuitions que d'autres personnes ont exprimé ici.
Monotonicité
cette heuristique essaie de s'assurer que les valeurs des tuiles sont toutes en hausse ou en baisse le long des directions gauche/droite et Haut/Bas. Cette seule heuristique saisit l'intuition que beaucoup d'autres ont mentionné, que les tuiles de valeur supérieure devraient être groupées dans un coin. Il empêchera généralement de plus petits carreaux de valeur de devenir orphelins et gardera le Conseil d'administration très organisé, avec des tuiles plus petites en cascade et remplir dans les tuiles plus grandes.
voici une capture d'écran d'une grille parfaitement monotone. J'ai obtenu en exécutant l'algorithme avec la fonction eval mis à ignorer les autres heuristiques et seulement envisager de monotonicité.

Douceur
l'heuristique ci-dessus seul tend à créer des structures dans lesquelles les tuiles adjacentes diminuent en valeur, mais bien sûr pour fusionner, tuiles adjacentes doivent être la même valeur. Par conséquent, le lissage heuristique mesure juste la différence de valeur entre les tuiles voisines, en essayant de minimiser ce compte.
un commentateur sur Hacker Nouvelles a donné une formalisation intéressante de cette idée en termes de théorie des graphes.
voici une capture d'écran d'une grille parfaitement lisse, gracieuseté de cette excellente fourchette de parodie .

Tuiles Libres
et enfin, il y a une pénalité pour avoir trop peu de tuiles gratuites, car les options peuvent s'épuiser rapidement lorsque le plateau de jeu devient trop étroit.
Et c'est tout! Chercher dans l'espace de jeu tout en optimisant ces critères donne des performances remarquablement bonnes. Un avantage à utiliser une approche généralisée comme celle-ci plutôt qu'une approche explicite stratégie de mouvement codé est que l'algorithme peut souvent trouver des solutions intéressantes et inattendues. Si vous le regardez courir, il fera souvent des mouvements surprenants mais efficaces, comme changer soudainement quel mur ou coin il construit contre.
Edit:
Voici une démonstration de la puissance de cette approche. J'ai déballé les valeurs des carreaux (donc il a continué à aller après avoir atteint 2048) et voici le meilleur résultat après huit essais.

Oui, c'est un 4096 à côté d'un 2048. = ) Cela signifie qu'il a atteint la tuile 2048 insaisissable trois fois sur la même planche.
EDIT: C'est une naïve de l'algorithme, la modélisation de l'homme conscient processus de pensée, et devient très faible par rapport aux résultats de l'intelligence artificielle, la recherche de toutes les possibilités, car elle ne ressemble à une mosaïque à l'avance. Il a été soumis au début du délai de réponse.
j'ai affiné l'algorithme et battu le jeu! Il peut échouer en raison de la simple malchance proche de la fin (vous êtes forcé de descendre, ce que vous ne devriez jamais faire, et une tuile apparaît où votre plus haut devrait être. Il suffit d'essayer de garder la rangée du haut rempli, de sorte que le déplacement à gauche ne casse pas le modèle), mais fondamentalement, vous finissez par avoir une partie fixe et une partie mobile à jouer avec. C'est votre objectif:

C'est le modèle que j'ai choisi par défaut.
1024 512 256 128
8 16 32 64
4 2 x x
x x x x
le coin choisi est arbitraire, vous ne Appuyez jamais sur une touche (le mouvement interdit), et si vous le faites, vous appuyez à nouveau sur le contraire et essayer remédier. Pour les tuiles futures, le modèle s'attend toujours à ce que la prochaine tuile aléatoire soit un 2 et apparaisse du côté opposé au modèle actuel (alors que la première rangée est incomplète, dans le coin inférieur droit, une fois la première rangée terminée, dans le coin inférieur gauche).
Voici l'algorithme. Environ 80% gagne (il semble qu'il soit toujours possible de gagner avec des techniques D'IA plus "professionnelles", Je ne suis pas sûr de cela, cependant.)
initiateModel();
while(!game_over)
{
checkCornerChosen(); // Unimplemented, but it might be an improvement to change the reference point
for each 3 possible move:
evaluateResult()
execute move with best score
if no move is available, execute forbidden move and undo, recalculateModel()
}
evaluateResult() {
calculatesBestCurrentModel()
calculates distance to chosen model
stores result
}
calculateBestCurrentModel() {
(according to the current highest tile acheived and their distribution)
}
quelques pointeurs sur les marches manquantes. Ici: 
Le modèle a changé en raison de la chance de se rapprocher du modèle. Le modèle que L'IA tente de réaliser est
512 256 128 x
X X x x
X X x x
x x x x
et la chaîne pour y arriver est devenue:
512 256 64 O
8 16 32 O
4 x x x
x x x x
les O représentent des espaces interdits...
ainsi il pressera à droite, puis à droite de nouveau, puis (à droite ou en haut selon où le 4 a créé) alors procéder à la chaîne jusqu'à ce qu'il obtient:

donc maintenant le modèle et la chaîne sont de retour à:
512 256 128 64
4 8 16 32
X X x x
x x x x
Deuxième pointeur, il a eu de la malchance et sa principale place a été prise. Il est probable qu'elle échouera, mais elle peut encore l'atteindre:

ici le modèle et la chaîne est:
O 1024 512 256
O O O 128
8 16 32 64
4 x x x
quand il parvient à atteindre les 128 il gagne une rangée entière est gagnée à nouveau:
O 1024 512 256
x x 128 128
x x x x
x x x x
je me suis intéressé à l'idée d'une AI pour ce jeu contenant aucune intelligence codée (I. e no heuristics, scoring functions etc.). L'IA doit "savoir" seulement les règles du jeu, et "comprendre" le jeu. C'est en contraste avec la plupart des AIs (comme ceux dans ce fil) où le jeu est essentiellement la force brute dirigé par une fonction de notation représentant la compréhension humaine du jeu.
algorithme AI
j'ai trouvé un algorithme de jeu simple mais étonnamment bon: pour déterminer le prochain mouvement pour une planche donnée, L'IA joue le jeu en mémoire en utilisant mouvements aléatoires jusqu'à ce que le jeu est terminé. Ceci est fait plusieurs fois tout en gardant la trace du score de fin de jeu. Ensuite, le score final moyen par mouvement de départ est calculé. Le mouvement de départ avec le score final moyen le plus élevé est choisi comme le prochain déplacement.
With just 100 runs(I. e dans les jeux de mémoire) par mouvement, L'IA atteint la 2048 tuile 80% des temps et la 4096 tuile 50% des temps. En utilisant 10000 passages obtient la 2048 tuile 100%, 70% pour 4096 tuile, et environ 1% pour la 8192 tuile.
le meilleur score obtenu est affiché ici:
An fait intéressant à propos de cet algorithme, alors que les jeux au hasard sont sans surprise assez mauvais, le choix du meilleur (ou le moins mauvais) mouvement conduit à un très bon jeu de jeu: un jeu AI typique peut atteindre 70000 points et les derniers 3000 coups, mais les jeux en mémoire de jeu au hasard à partir de n'importe quelle position donne une moyenne de 340 points supplémentaires en environ 40 mouvements supplémentaires avant de mourir. (Vous pouvez le voir par vous-même en exécutant L'IA et en ouvrant la console de débogage.)
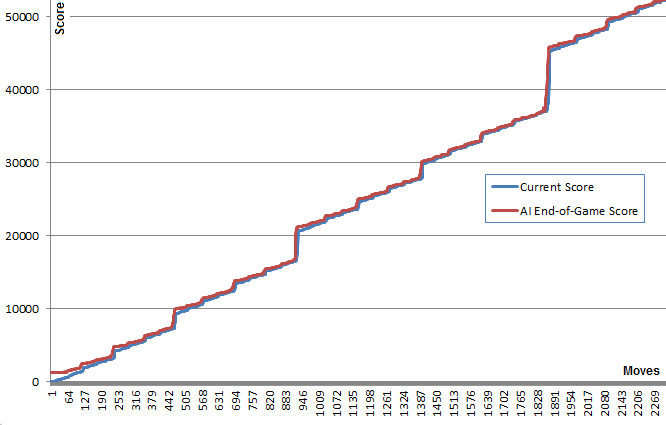
Ce graphique illustration de ce point: la ligne bleue montre le score du tableau après chaque mouvement. La ligne rouge indique le meilleur score de fin de jeu aléatoire de l'algorithme à partir de cette position. Essentiellement, les valeurs rouges "tirent" les valeurs bleues vers le haut, car elles constituent la meilleure estimation de l'algorithme. Il est intéressant de voir que la ligne rouge est juste un tout petit peu au-dessus de la ligne bleue à chaque point, mais la ligne bleue continue d'augmenter de plus en plus.
je trouve assez surprenant que l'algorithme n'ait pas besoin de prévoir un bon jeu pour choisir les mouvements qui le produisent.
recherche plus tard, j'ai trouvé cet algorithme pourrait être classé comme un Pure recherche D'Arbre de Monte Carlo algorithme.
mise en œuvre et liens
J'ai d'abord créé une version JavaScript qui peut être vu en action ici . Cette version peut exécuter des centaines de passages en temps voulu. Ouvrez la console pour plus d'informations. ( source )
plus tard, pour en savoir plus, j'ai utilisé l'infrastructure hautement optimisée de @nneonneo et j'ai implémenté ma version en C++. Cette version permet jusqu'à 100000 fonctionne par mouvement et même 1000000 si vous avez la patience. Instructions de construction fournies. Il tourne dans la console et dispose également d'une télécommande pour lire le web version. ( source )
résultats
étonnamment, l'augmentation du nombre de points n'améliore pas radicalement le jeu. Il semble y avoir une limite à cette stratégie à environ 80000 points avec la tuile 4096 et tous les plus petits, très proche de la réalisation de la tuile 8192. L'augmentation du nombre de descentes de 100 à 100000 fait augmenter les chances d'atteindre cette limite de score (de 5% à 40%) mais pas de rupture à travers elle.
Exécution de 10000 fonctionne avec une augmentation temporaire de 1000000 près de positions critiques réussi à briser cette barrière, moins de 1% de la fois la réalisation d'un max de score de 129892 et la 8192 tuile.
améliorations
après la mise en œuvre de cet algorithme, j'ai essayé de nombreuses améliorations,y compris l'utilisation des scores min ou max,ou une combinaison de min, max, ET avg. J'ai également essayé d'utiliser la profondeur: au lieu D'essayer K fonctionne par move, j'ai essayé K moves par move list d'une longueur donnée ("up,up,left" par exemple) et en sélectionnant le premier mouvement de la liste des meilleurs mouvements de notation.
plus tard, j'ai mis en œuvre un arbre de notation qui a pris en compte la probabilité conditionnelle d'être en mesure de jouer un mouvement après une liste de mouvements donnée.
cependant, aucune de ces idées n'a montré un réel avantage sur la simple première idée. J'ai laissé le code pour ces idées commentées dans le Le code C++.
j'ai ajouté un mécanisme" Deep Search " qui a augmenté le nombre d'exécution temporairement à 1000000 lorsque l'une des courses a réussi à atteindre accidentellement la tuile la plus élevée suivante. Cela a offert une amélioration de temps.
je serais intéressé d'entendre si quelqu'un a d'autres idées d'amélioration qui maintiennent le domaine de l'indépendance de l'IA.
2048 variantes et Clones
Juste pour le fun, j'ai aussi mis en œuvre L'IA comme un bookmarklet , accroché dans les contrôles du jeu. Cela permet à L'IA de travailler avec le jeu original et beaucoup de ses variantes .
cela est possible en raison de la nature indépendante du domaine de L'IA. Certaines variantes sont assez distinctes, comme le clone Hexagonal.
je copie ici le contenu d'un post sur mon blog
la solution que je propose est très simple et facile à mettre en œuvre. Bien que, il a atteint le score de 131040. Plusieurs points de référence des performances de l'algorithme sont présentés.
algorithme
notation heuristique algorithme
l'hypothèse sur laquelle mon algorithme est basé est assez simple: si vous voulez obtenir une note plus élevée, le tableau doit être aussi ordonné que possible. En particulier, la configuration optimale est donnée par un linéaire et monotone ordre décroissant des valeurs de mosaïque.
Cette intuition vous donnera aussi la limite supérieure pour une valeur de tuile: 
(Il ya une possibilité de atteindre la tuile 131072 si la 4 tuiles est générée au hasard au lieu de la 2 tuiles si nécessaire)
deux façons possibles d'organiser le Conseil sont présentées dans les images suivantes:
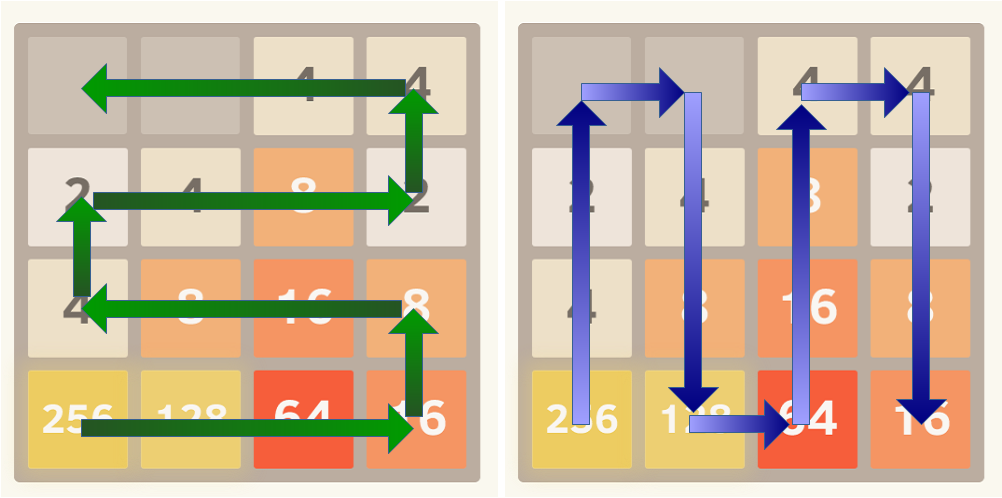
pour appliquer l'ordination des carreaux dans un ordre décroissant monotone, le score si calculé comme la somme des valeurs linéarisées sur la planche multipliée par les valeurs d'une séquence géométrique avec rapport commun r<1 .


plusieurs chemins linéaires peuvent être évalués à la fois, le score final sera le score maximum de n'importe quel chemin.
règle de décision
la règle de décision implémentée n'est pas très intelligente, le code en Python est présenté ici:
@staticmethod
def nextMove(board,recursion_depth=3):
m,s = AI.nextMoveRecur(board,recursion_depth,recursion_depth)
return m
@staticmethod
def nextMoveRecur(board,depth,maxDepth,base=0.9):
bestScore = -1.
bestMove = 0
for m in range(1,5):
if(board.validMove(m)):
newBoard = copy.deepcopy(board)
newBoard.move(m,add_tile=True)
score = AI.evaluate(newBoard)
if depth != 0:
my_m,my_s = AI.nextMoveRecur(newBoard,depth-1,maxDepth)
score += my_s*pow(base,maxDepth-depth+1)
if(score > bestScore):
bestMove = m
bestScore = score
return (bestMove,bestScore);
Une mise en œuvre de la minmax ou L'Expectiminimax va sûrement améliorer l'algorithme. Évidemment un plus une règle de décision sophistiquée ralentira l'algorithme et il faudra un certain temps pour la mettre en œuvre.Je vais essayer une implémentation minimax dans un futur proche. (restez à l'écoute)
de Référence", 1519160920"
- T1-121 tests-8 chemins différents-r=0,125
- T2 - 122 tests - 8-chemins différents, r=0.25
- T3-132 essais-8-différentes voies-r=0.5
- T4 - 211 tests - 2-chemins différents, r=0.125
- T5 - 274 tests - 2-chemins différents, r=0.25
- T6 - 211 tests - 2-chemins différents, r=0,5
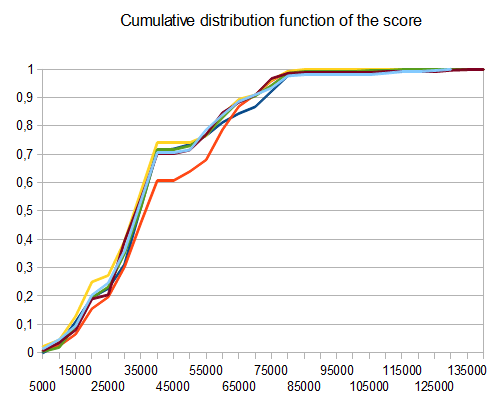
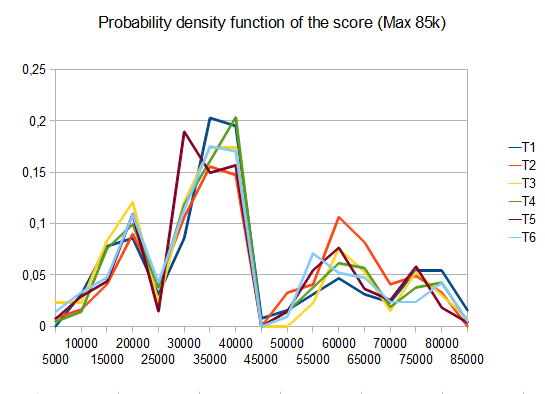
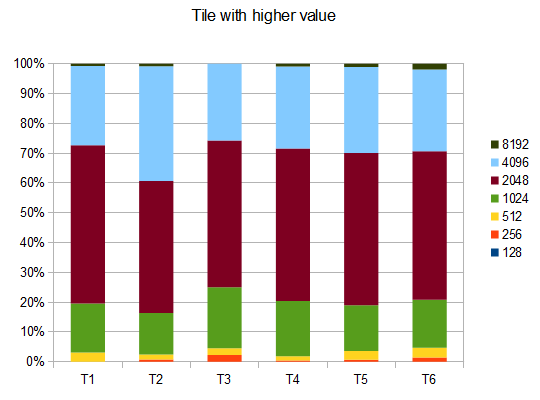
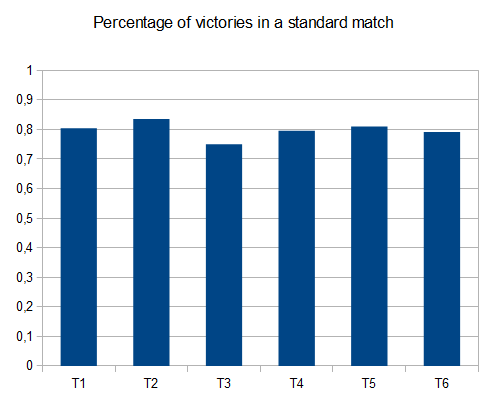
dans le cas de T2, quatre tests sur dix génèrent la tuile 4096 avec une note moyenne de 
Code
le code se trouve sur GiHub au lien suivant: https://github.com/Nicola17/term2048-AI Il est basé sur term2048 et il est écrit en Python. Je vais implémenter une version plus efficace en C++ dès que possible.
ma tentative utilise expectimax comme d'autres solutions ci-dessus, mais sans bitboards. La solution de Nneonneo peut contrôler 10millions de mouvements ce qui est environ une profondeur de 4 avec 6 tuiles à gauche et 4 mouvements possibles (2*6*4) 4 . Dans mon cas, cette profondeur prend trop de temps à explorer, j'ajuste la profondeur de recherche expectimax en fonction du nombre de carreaux libres laissés:
depth = free > 7 ? 1 : (free > 4 ? 2 : 3)
les scores des conseils sont calculés avec la somme pondérée des carré du nombre de tuiles libres et le produit scalaire de la grille 2D avec ceci:
[[10,8,7,6.5],
[.5,.7,1,3],
[-.5,-1.5,-1.8,-2],
[-3.8,-3.7,-3.5,-3]]
qui oblige à organiser les tuiles en descendant dans une sorte de serpent de la tuile supérieure gauche.
Code ci-dessous ou jsbin :
var n = 4,
M = new MatrixTransform(n);
var ai = {weights: [1, 1], depth: 1}; // depth=1 by default, but we adjust it on every prediction according to the number of free tiles
var snake= [[10,8,7,6.5],
[.5,.7,1,3],
[-.5,-1.5,-1.8,-2],
[-3.8,-3.7,-3.5,-3]]
snake=snake.map(function(a){return a.map(Math.exp)})
initialize(ai)
function run(ai) {
var p;
while ((p = predict(ai)) != null) {
move(p, ai);
}
//console.log(ai.grid , maxValue(ai.grid))
ai.maxValue = maxValue(ai.grid)
console.log(ai)
}
function initialize(ai) {
ai.grid = [];
for (var i = 0; i < n; i++) {
ai.grid[i] = []
for (var j = 0; j < n; j++) {
ai.grid[i][j] = 0;
}
}
rand(ai.grid)
rand(ai.grid)
ai.steps = 0;
}
function move(p, ai) { //0:up, 1:right, 2:down, 3:left
var newgrid = mv(p, ai.grid);
if (!equal(newgrid, ai.grid)) {
//console.log(stats(newgrid, ai.grid))
ai.grid = newgrid;
try {
rand(ai.grid)
ai.steps++;
} catch (e) {
console.log('no room', e)
}
}
}
function predict(ai) {
var free = freeCells(ai.grid);
ai.depth = free > 7 ? 1 : (free > 4 ? 2 : 3);
var root = {path: [],prob: 1,grid: ai.grid,children: []};
var x = expandMove(root, ai)
//console.log("number of leaves", x)
//console.log("number of leaves2", countLeaves(root))
if (!root.children.length) return null
var values = root.children.map(expectimax);
var mx = max(values);
return root.children[mx[1]].path[0]
}
function countLeaves(node) {
var x = 0;
if (!node.children.length) return 1;
for (var n of node.children)
x += countLeaves(n);
return x;
}
function expectimax(node) {
if (!node.children.length) {
return node.score
} else {
var values = node.children.map(expectimax);
if (node.prob) { //we are at a max node
return Math.max.apply(null, values)
} else { // we are at a random node
var avg = 0;
for (var i = 0; i < values.length; i++)
avg += node.children[i].prob * values[i]
return avg / (values.length / 2)
}
}
}
function expandRandom(node, ai) {
var x = 0;
for (var i = 0; i < node.grid.length; i++)
for (var j = 0; j < node.grid.length; j++)
if (!node.grid[i][j]) {
var grid2 = M.copy(node.grid),
grid4 = M.copy(node.grid);
grid2[i][j] = 2;
grid4[i][j] = 4;
var child2 = {grid: grid2,prob: .9,path: node.path,children: []};
var child4 = {grid: grid4,prob: .1,path: node.path,children: []}
node.children.push(child2)
node.children.push(child4)
x += expandMove(child2, ai)
x += expandMove(child4, ai)
}
return x;
}
function expandMove(node, ai) { // node={grid,path,score}
var isLeaf = true,
x = 0;
if (node.path.length < ai.depth) {
for (var move of[0, 1, 2, 3]) {
var grid = mv(move, node.grid);
if (!equal(grid, node.grid)) {
isLeaf = false;
var child = {grid: grid,path: node.path.concat([move]),children: []}
node.children.push(child)
x += expandRandom(child, ai)
}
}
}
if (isLeaf) node.score = dot(ai.weights, stats(node.grid))
return isLeaf ? 1 : x;
}
var cells = []
var table = document.querySelector("table");
for (var i = 0; i < n; i++) {
var tr = document.createElement("tr");
cells[i] = [];
for (var j = 0; j < n; j++) {
cells[i][j] = document.createElement("td");
tr.appendChild(cells[i][j])
}
table.appendChild(tr);
}
function updateUI(ai) {
cells.forEach(function(a, i) {
a.forEach(function(el, j) {
el.innerHTML = ai.grid[i][j] || ''
})
});
}
updateUI(ai)
function runAI() {
var p = predict(ai);
if (p != null && ai.running) {
move(p, ai)
updateUI(ai)
requestAnimationFrame(runAI)
}
}
runai.onclick = function() {
if (!ai.running) {
this.innerHTML = 'stop AI';
ai.running = true;
runAI();
} else {
this.innerHTML = 'run AI';
ai.running = false;
}
}
hint.onclick = function() {
hintvalue.innerHTML = ['up', 'right', 'down', 'left'][predict(ai)]
}
document.addEventListener("keydown", function(event) {
if (event.which in map) {
move(map[event.which], ai)
console.log(stats(ai.grid))
updateUI(ai)
}
})
var map = {
38: 0, // Up
39: 1, // Right
40: 2, // Down
37: 3, // Left
};
init.onclick = function() {
initialize(ai);
updateUI(ai)
}
function stats(grid, previousGrid) {
var free = freeCells(grid);
var c = dot2(grid, snake);
return [c, free * free];
}
function dist2(a, b) { //squared 2D distance
return Math.pow(a[0] - b[0], 2) + Math.pow(a[1] - b[1], 2)
}
function dot(a, b) {
var r = 0;
for (var i = 0; i < a.length; i++)
r += a[i] * b[i];
return r
}
function dot2(a, b) {
var r = 0;
for (var i = 0; i < a.length; i++)
for (var j = 0; j < a[0].length; j++)
r += a[i][j] * b[i][j]
return r;
}
function product(a) {
return a.reduce(function(v, x) {
return v * x
}, 1)
}
function maxValue(grid) {
return Math.max.apply(null, grid.map(function(a) {
return Math.max.apply(null, a)
}));
}
function freeCells(grid) {
return grid.reduce(function(v, a) {
return v + a.reduce(function(t, x) {
return t + (x == 0)
}, 0)
}, 0)
}
function max(arr) { // return [value, index] of the max
var m = [-Infinity, null];
for (var i = 0; i < arr.length; i++) {
if (arr[i] > m[0]) m = [arr[i], i];
}
return m
}
function min(arr) { // return [value, index] of the min
var m = [Infinity, null];
for (var i = 0; i < arr.length; i++) {
if (arr[i] < m[0]) m = [arr[i], i];
}
return m
}
function maxScore(nodes) {
var min = {
score: -Infinity,
path: []
};
for (var node of nodes) {
if (node.score > min.score) min = node;
}
return min;
}
function mv(k, grid) {
var tgrid = M.itransform(k, grid);
for (var i = 0; i < tgrid.length; i++) {
var a = tgrid[i];
for (var j = 0, jj = 0; j < a.length; j++)
if (a[j]) a[jj++] = (j < a.length - 1 && a[j] == a[j + 1]) ? 2 * a[j++] : a[j]
for (; jj < a.length; jj++)
a[jj] = 0;
}
return M.transform(k, tgrid);
}
function rand(grid) {
var r = Math.floor(Math.random() * freeCells(grid)),
_r = 0;
for (var i = 0; i < grid.length; i++) {
for (var j = 0; j < grid.length; j++) {
if (!grid[i][j]) {
if (_r == r) {
grid[i][j] = Math.random() < .9 ? 2 : 4
}
_r++;
}
}
}
}
function equal(grid1, grid2) {
for (var i = 0; i < grid1.length; i++)
for (var j = 0; j < grid1.length; j++)
if (grid1[i][j] != grid2[i][j]) return false;
return true;
}
function conv44valid(a, b) {
var r = 0;
for (var i = 0; i < 4; i++)
for (var j = 0; j < 4; j++)
r += a[i][j] * b[3 - i][3 - j]
return r
}
function MatrixTransform(n) {
var g = [],
ig = [];
for (var i = 0; i < n; i++) {
g[i] = [];
ig[i] = [];
for (var j = 0; j < n; j++) {
g[i][j] = [[j, i],[i, n-1-j],[j, n-1-i],[i, j]]; // transformation matrix in the 4 directions g[i][j] = [up, right, down, left]
ig[i][j] = [[j, i],[i, n-1-j],[n-1-j, i],[i, j]]; // the inverse tranformations
}
}
this.transform = function(k, grid) {
return this.transformer(k, grid, g)
}
this.itransform = function(k, grid) { // inverse transform
return this.transformer(k, grid, ig)
}
this.transformer = function(k, grid, mat) {
var newgrid = [];
for (var i = 0; i < grid.length; i++) {
newgrid[i] = [];
for (var j = 0; j < grid.length; j++)
newgrid[i][j] = grid[mat[i][j][k][0]][mat[i][j][k][1]];
}
return newgrid;
}
this.copy = function(grid) {
return this.transform(3, grid)
}
}body {
text-align: center
}
table, th, td {
border: 1px solid black;
margin: 5px auto;
}
td {
width: 35px;
height: 35px;
text-align: center;
}<table></table>
<button id=init>init</button><button id=runai>run AI</button><button id=hint>hint</button><span id=hintvalue></span>je suis l'auteur d'un contrôleur 2048 qui scores mieux que tout autre programme mentionné dans ce thread. Une implémentation efficace du contrôleur est disponible sur github . Dans , un rapport distinct , il y a aussi le code utilisé pour former la fonction d'évaluation de l'état du contrôleur. La méthode de formation est décrite dans le papier .
le contrôleur utilise la recherche expectimax avec un État fonction d'évaluation apprise à partir de zéro (sans expertise humaine 2048) par une variante de l'apprentissage de la différence temporelle (une technique d'apprentissage de renforcement). La fonction d'état-valeur utilise un n-tuple réseau , qui est essentiellement une fonction linéaire pondérée des modèles observés sur la carte. Il s'agit de plus de 1 milliards de poids , au total.
Performance
à 1 mouvements / s: 609104 (100 moyenne des jeux)
à 10 coups/s: 589355 (300 moyenne des jeux)
à 3-ply(ca. 1500 mouvements / s): 511759 (1000 moyenne des jeux)
les statistiques de carrelage pour 10 mouvements/s sont les suivantes:
2048: 100%
4096: 100%
8192: 100%
16384: 97%
32768: 64%
32768,16384,8192,4096: 10%
(La dernière ligne signifie avoir donné des tuiles en même temps sur la carte).
Pour 3 personnes:
2048: 100%
4096: 100%
8192: 100%
16384: 96%
32768: 54%
32768,16384,8192,4096: 8%
cependant, je ne l'ai jamais vu obtenir la tuile 65536.
je pense que j'ai trouvé un algorithme qui fonctionne assez bien, car j'ai souvent des scores supérieurs à 10000, mon meilleur niveau personnel étant d'environ 16000. Ma solution ne vise pas à garder les plus grands nombres dans un coin, mais de le garder dans la rangée du haut.
s'il vous Plaît voir le code ci-dessous:
while( !game_over ) {
move_direction=up;
if( !move_is_possible(up) ) {
if( move_is_possible(right) && move_is_possible(left) ){
if( number_of_empty_cells_after_moves(left,up) > number_of_empty_cells_after_moves(right,up) )
move_direction = left;
else
move_direction = right;
} else if ( move_is_possible(left) ){
move_direction = left;
} else if ( move_is_possible(right) ){
move_direction = right;
} else {
move_direction = down;
}
}
do_move(move_direction);
}
il y a déjà une implémentation AI pour ce jeu: ici . Extrait de README:
l'algorithme est itératif deepening depth first alpha-beta search. La fonction d'évaluation essaie de garder les rangées et les colonnes monotones (toutes en décroissant ou en augmentant) tout en minimisant le nombre de tuiles sur la grille.
il y a aussi une discussion sur ycombinator sur cet algorithme que vous pourriez trouver utiles.
algorithme
while(!game_over)
{
for each possible move:
evaluate next state
choose the maximum evaluation
}
évaluation
Evaluation =
128 (Constant)
+ (Number of Spaces x 128)
+ Sum of faces adjacent to a space { (1/face) x 4096 }
+ Sum of other faces { log(face) x 4 }
+ (Number of possible next moves x 256)
+ (Number of aligned values x 2)
Détails De L'Évaluation
128 (Constant)
il s'agit d'une constante, utilisée comme ligne de base et pour d'autres usages comme les tests.
+ (Number of Spaces x 128)
plus d'espaces rend l'état plus flexible, nous multiplions par 128 (qui est la médiane) depuis une grille remplie de 128 faces est un état optimal impossible.
+ Sum of faces adjacent to a space { (1/face) x 4096 }
ici nous évaluons des tailles qui ont la possibilité d'arriver à fusionner, en les évaluant vers l'arrière, la tuile 2 devient de valeur 2048, tandis que la tuile 2048 est évaluée 2.
+ Sum of other faces { log(face) x 4 }
ici, nous avons encore besoin de vérifier les valeurs empilées, mais d'une manière moins importante qui n'interrompt pas les paramètres de flexibilité, donc nous avons la somme de { x dans [4,44] }.
+ (Number of possible next moves x 256)
un État est plus flexible s'il dispose d'une plus grande liberté de transitions possibles.
+ (Number of aligned values x 2)
C'est une forme simplifiée de vérifier la possibilité d'avoir fusionne dans cet état, sans un regard.
Note: les constantes peuvent être ajustées..
ce n'est pas une réponse directe à la question de L'OP, c'est plus des stuffs (expériences) j'ai essayé jusqu'ici de résoudre le même problème et ai obtenu quelques résultats et ont quelques observations que je veux partager, je suis curieux si nous pouvons avoir quelques idées plus à partir de cela.
je viens d'essayer mon implémentation minimax avec élagage alpha-bêta avec coupe de profondeur de l'arbre de recherche à 3 et 5. J'ai essayé de résoudre le même problème pour une grille 4x4 comme un projet de cession de la edX course ColumbiaX: CSMM.101x Intelligence Artificielle (IA) .
j'ai appliqué la combinaison convexe (essayé différents poids heuristiques) de quelques fonctions d'évaluation heuristiques, principalement de l'intuition et de ceux discutés ci-dessus:
- Monotonicité
- Espace Disponible
dans mon cas, le lecteur d'ordinateur est complètement aléatoire, mais j'ai tout de même supposé paramètres adverses et mis en œuvre L'agent AI player en tant que joueur max.
j'ai 4x4 grille pour jouer le jeu.
Observation:
si j'attribue trop de poids à la première fonction heuristique ou à la deuxième fonction heuristique, les deux cas où les scores du Joueur D'IA sont faibles. J'ai joué avec de nombreuses assignations de poids possibles aux fonctions heuristiques et prendre une combinaison convexe, mais très rarement le joueur AI est capable de marquer 2048. La plupart du temps, il s'arrête à 1024 ou 512.
j'ai aussi essayé le coin heuristique, mais pour une raison quelconque, il rend les résultats pire, une intuition pourquoi?
aussi, j'ai essayé d'augmenter la coupure de profondeur de recherche de 3 à 5 (Je ne peux pas l'augmenter davantage depuis la recherche que l'espace dépasse le temps autorisé même avec l'élagage) et a ajouté un heuristique de plus qui regarde les valeurs des tuiles adjacentes et donne plus de points si elles sont fusion-mesure, mais je ne suis pas en mesure d'obtenir 2048.
je pense qu'il sera préférable D'utiliser Expectimax au lieu de minimax, mais je veux tout de même résoudre ce problème avec minimax seulement et obtenir des scores élevés tels que 2048 ou 4096. Je ne suis pas sûr de savoir si je suis absent de quoi que ce soit.
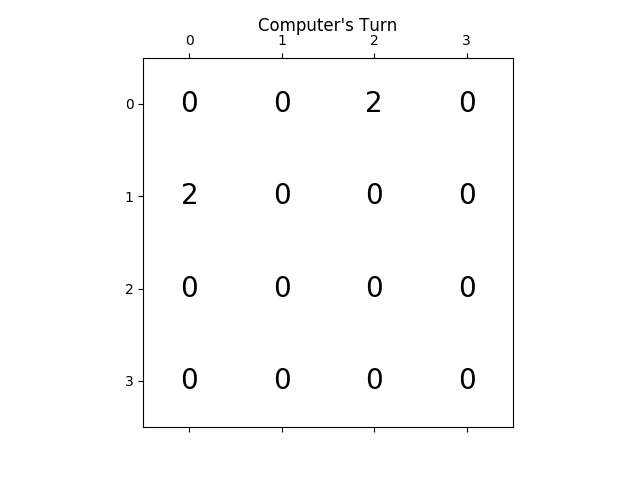
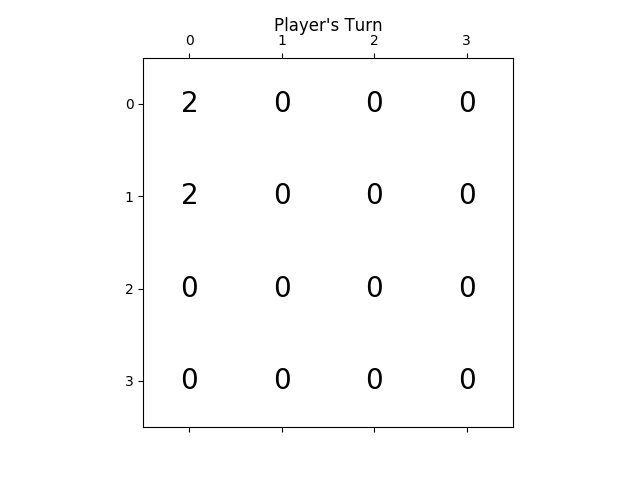
ci-dessous l'animation montre les dernières étapes du jeu joué par L'agent de L'IA avec le joueur informatique:
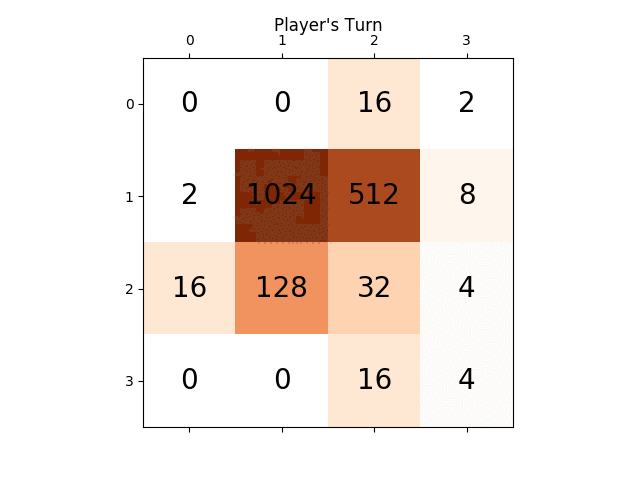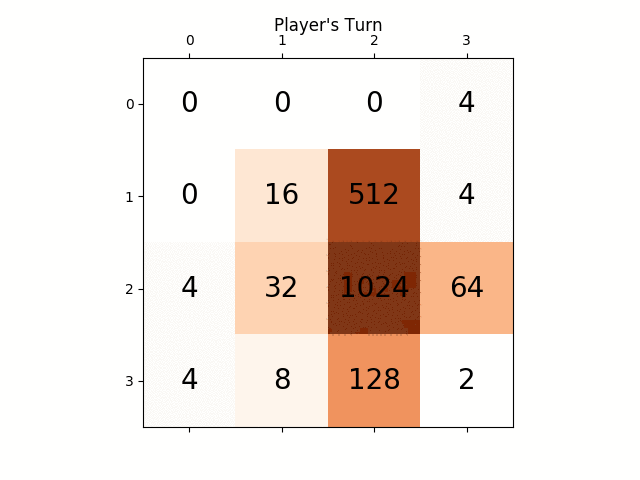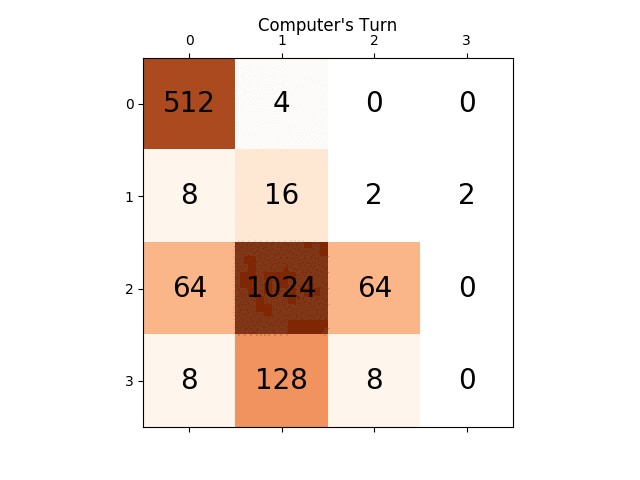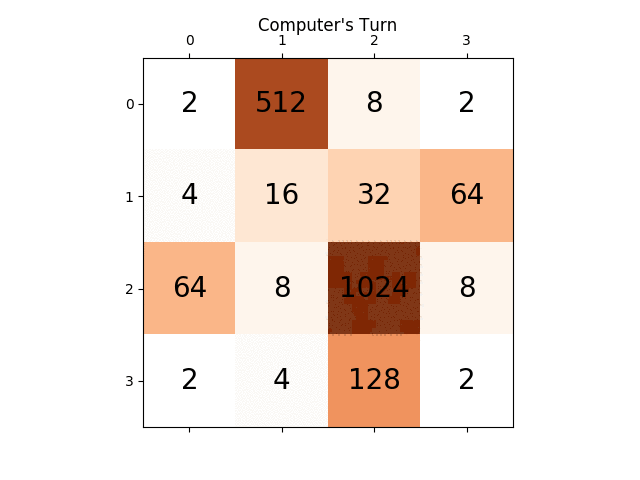
toute perspicacité sera vraiment très utile, merci à l'avance. (Ceci est le lien de mon billet de blog pour l'article: https://sandipanweb.wordpress.com/2017/03/06/using-minimax-with-alpha-beta-pruning-and-heuristic-evaluation-to-solve-2048-game-with-computer / )
l'animation suivante montre les dernières étapes du jeu joué où le joueur agent D'AI pourrait obtenir 2048 scores, ajoutant cette fois l'absolu valeur heuristique aussi:
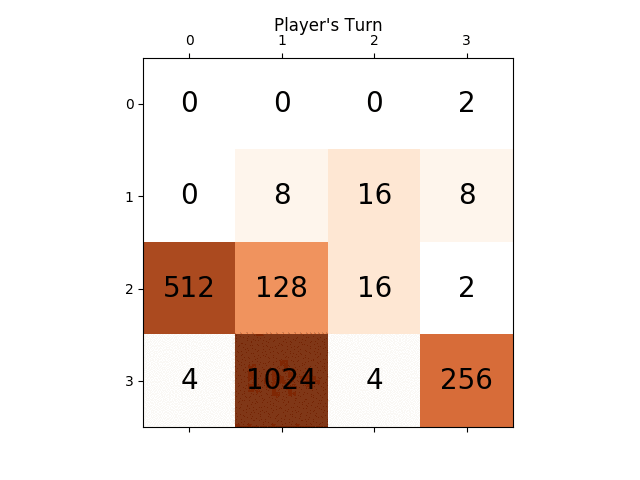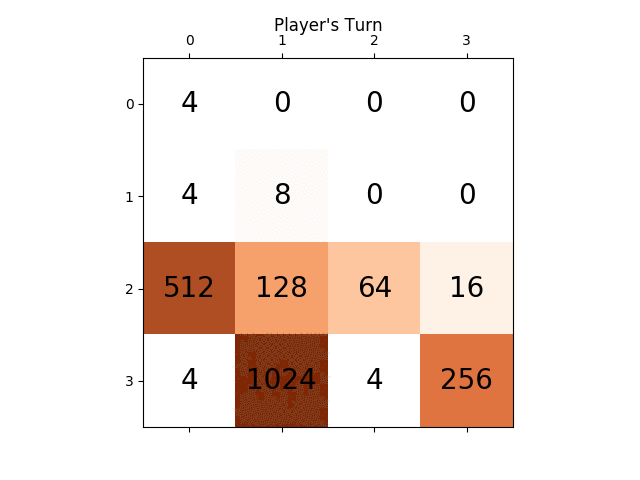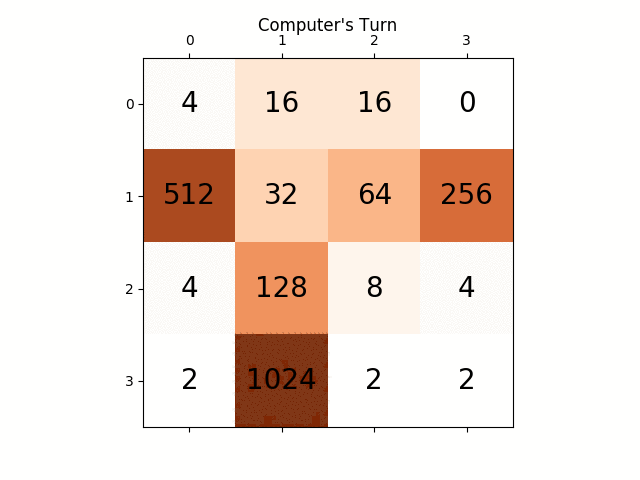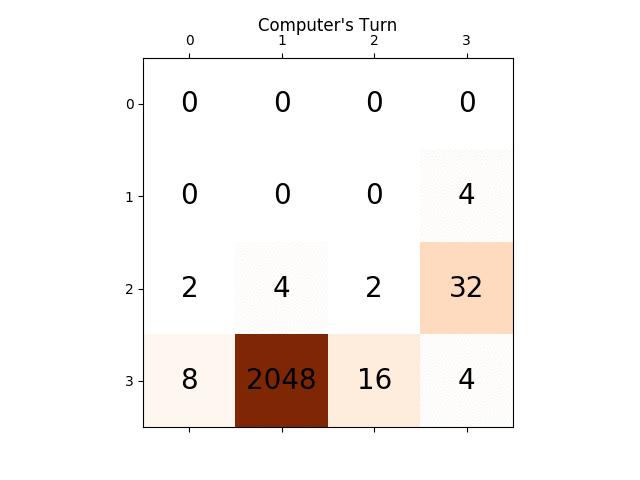
les figures suivantes montrent le game tree exploré par le joueur agent AI en supposant l'ordinateur comme adversaire pour une seule étape:
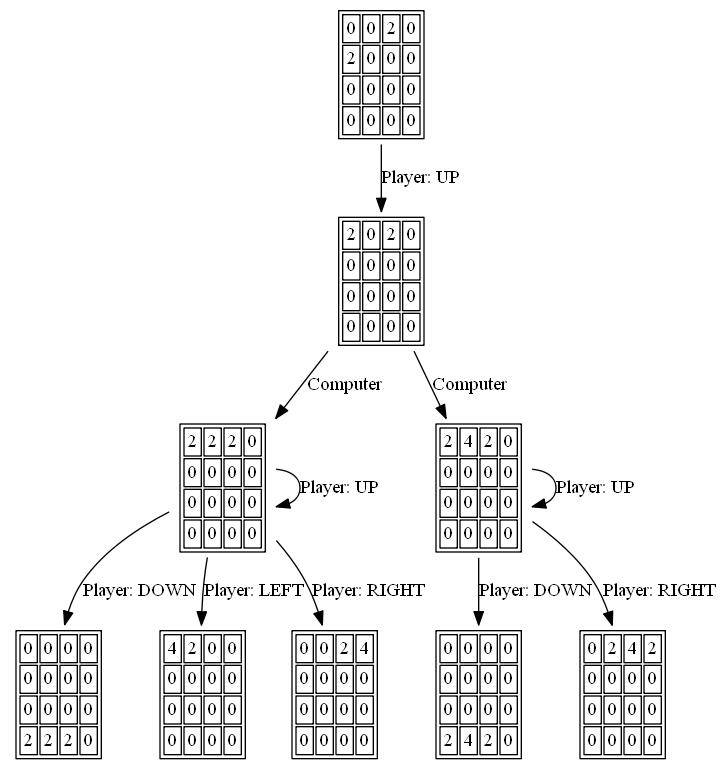
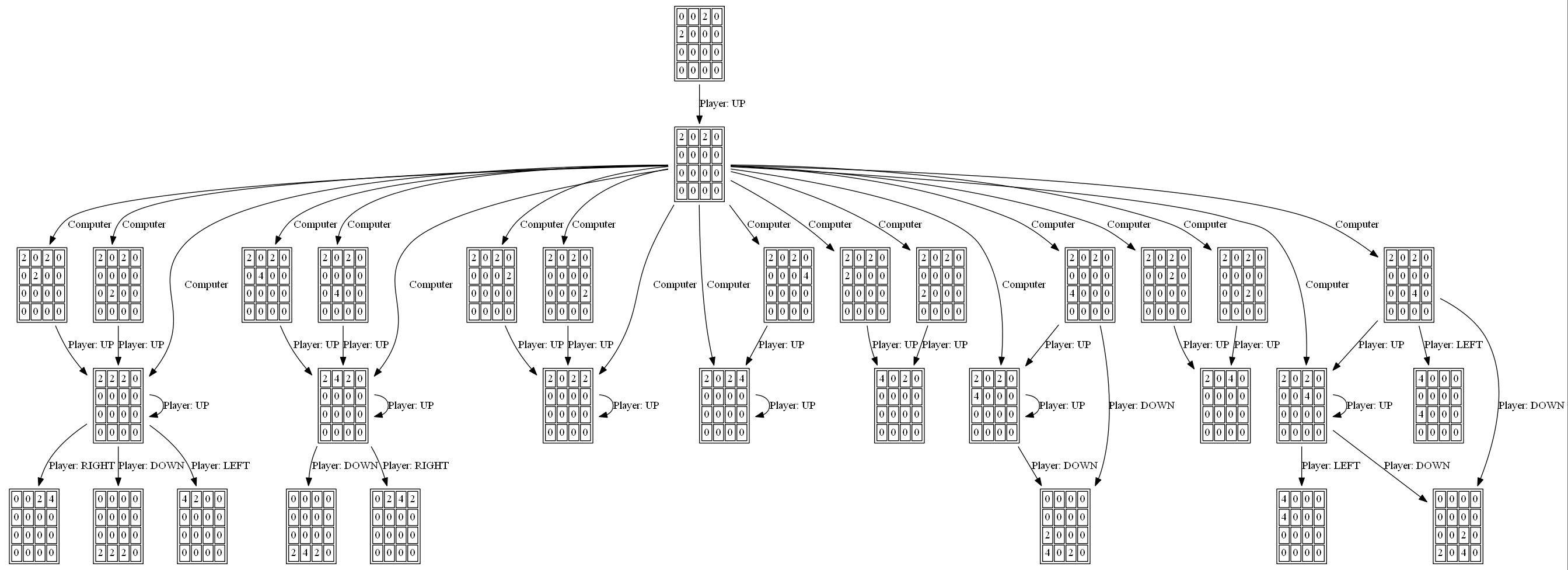


j'ai écrit un solveur 2048 à Haskell, principalement parce que j'apprends cette langue en ce moment.
mon implémentation du jeu diffère légèrement du jeu réel, en ce qu'une nouvelle tuile est toujours un '2' (plutôt que 90% 2 et 10% 4). Et que la nouvelle tuile n'est pas aléatoire, mais toujours la première disponible du haut à gauche. Cette variante est également connue sous le nom de Det 2048 .
en conséquence, ce solveur est déterministe.
j'ai utilisé un algorithme exhaustif qui favorise les carreaux vides. Il fonctionne assez rapidement pour la profondeur 1-4, mais sur la profondeur 5 il devient plutôt lent à environ 1 seconde par mouvement.
ci-dessous est le code d'implémentation de l'algorithme de résolution. La grille est représentée par un tableau de 16 longueurs D'entiers. Et le pointage est fait simplement en comptant le nombre de carrés vides.
bestMove :: Int -> [Int] -> Int
bestMove depth grid = maxTuple [ (gridValue depth (takeTurn x grid), x) | x <- [0..3], takeTurn x grid /= [] ]
gridValue :: Int -> [Int] -> Int
gridValue _ [] = -1
gridValue 0 grid = length $ filter (==0) grid -- <= SCORING
gridValue depth grid = maxInList [ gridValue (depth-1) (takeTurn x grid) | x <- [0..3] ]
je pense que c'est assez réussi pour sa simplicité. Le résultat atteint en commençant par une grille vide et en résolvant à la profondeur 5 est:
Move 4006
[2,64,16,4]
[16,4096,128,512]
[2048,64,1024,16]
[2,4,16,2]
Game Over
code Source peut être trouvé ici: https://github.com/popovitsj/2048-haskell
cet algorithme n'est pas optimal pour gagner le jeu, mais il est assez optimal en termes de performance et de quantité de code nécessaire:
if(can move neither right, up or down)
direction = left
else
{
do
{
direction = random from (right, down, up)
}
while(can not move in "direction")
}
beaucoup d'autres réponses utilisent AI avec la recherche computationnellement coûteuse de futurs possibles, heuristiques, l'apprentissage et les tels. C'est impressionnant et probablement la voie à suivre, mais je tiens à ajouter une autre idée.
modèle le genre de stratégie que les bons joueurs du jeu utilisent.
par exemple:
13 14 15 16
12 11 10 9
5 6 7 8
4 3 2 1
lire les carrés dans l'ordre indiqué ci-dessus jusqu'à ce que la valeur des carrés suivants soit supérieure que l'actuel. Cela pose le problème d'essayer de fusionner une autre tuile de la même valeur dans ce carré.
pour résoudre ce problème, leurs sont 2 façons de se déplacer qui ne sont pas laissés ou pire vers le haut et l'examen des deux possibilités peuvent révéler immédiatement plus de problèmes, cela forme une liste de dépendances, chaque problème nécessitant un autre problème à résoudre en premier. Je pense que j'ai cette chaîne ou dans certains cas arbre de dépendances en interne lors de la décision de mon prochain mouvement, en particulier lorsque coincé.
tuile a besoin de fusionner avec le voisin mais est trop petit: fusionner un autre voisin avec celui-ci.
Plus de vignette: Augmenter la valeur d'une petite tuiles environnantes.
etc...
l'approche dans son ensemble sera probablement plus compliquée que celle-ci, mais pas beaucoup plus. Ce pouvait être une mécanique sensation de manque scores, poids, neurones et recherches profondes de possibilités. L'arbre des possibles rairly même doit être assez grand pour avoir besoin d'ramification.