Quelle est la différence entre ramper et gratter? [dupliquer]
cette question a déjà une réponse ici:
- robot vs grattoir 4 réponses
y a-t-il une différence entre ramper et gratter?
S'il y a une différence, Quelle est la meilleure méthode à utiliser afin de recueillir des données web pour fournir une base de données pour une utilisation ultérieure dans un moteur de recherche personnalisée?
6 réponses
ramper serait essentiellement ce que Google, Yahoo, MSN, etc. do, je cherche N'importe quelle information. Grattage est généralement destiné à certains sites web, pour des données spécif iques, par exemple pour la comparaison des prix, sont donc codés très différemment.
habituellement, un racleur sera sur mesure pour les sites Web qu'il est censé racler, et ferait des choses qu'un (bon) rampeur ne ferait pas, c.-à-d.:
- N'ont aucun respect pour les robots.txt
- S'identifier comme un navigateur
- Soumettre les formulaires avec des données
- exécuter Javascript (si nécessaire pour agir comme un utilisateur)
Oui, ils sont différents. En pratique, vous devrez peut-être utiliser les deux.
(j'ai sauter dans les parce que, jusqu'à présent, les autres réponses ne sont pas l'essence. Ils utilisent des exemples mais n'établissent pas clairement les distinctions. Certes, ils datent de 2010!)
Web scraping , pour utiliser une définition minimale, est le processus de traitement d'un document web et d'extraire l'information. Vous pouvez faire du raclage web sans faire du web ramper.
web crawling , pour utiliser une définition minimale, est le processus itératif de trouver et de récupérer des liens web à partir d'une liste d'URLs seed. Strictement parlant, pour faire web crawling, vous devez faire un certain degré de raclage web (pour extraire les URLs.)
pour clarifier certains concepts mentionnés dans les autres réponses:
-
robots.txtest destiné à s'appliquer à toute processus automatisé qui accède à une page web. Donc ça s'applique à la fois aux rampeurs et aux racleurs. -
Bon " robots et des grattoirs, à la fois, doit s'identifier avec précision.
Quelques références:
AFAIK web Crawling est ce que Google fait - il va autour d'un site web à la recherche de liens et la construction d'une base de données de la mise en page de ce site et les sites qu'il relie à
grattage Web serait l'analyse progamatique d'une page Web pour charger certaines données hors de celui-ci, par exemple le chargement de BBC weather et déchirer (raclage) le forcast de temps hors de lui et le placer ailleurs ou l'utiliser dans un autre programme.
Il y a une différence fondamentale entre ces deux. Pour ceux qui cherchent à creuser plus profondément, je vous suggère de lire ceci - racleur de bande, Rampeur de bande
Ce post va dans les détails. Un bon résumé est dans ce tableau de l'article:
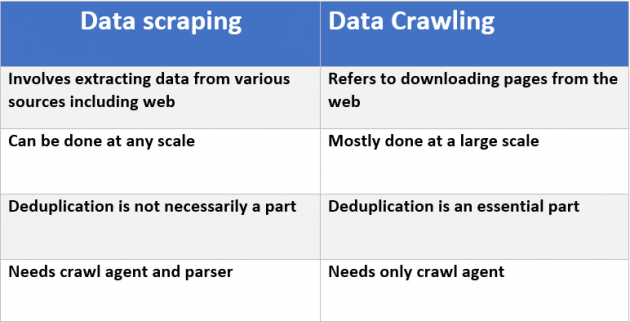
il y a définitivement une différence entre ces deux-là. On se réfère à la visite d'un site, l'autre pour l'extraction.
nous parcourons les sites pour avoir une perspective large comment le site est structuré, ce qui sont des liens entre les pages, pour estimer combien de temps nous avons besoin pour visiter toutes les pages que nous sommes intéressés. Le raclage est souvent plus difficile à mettre en œuvre, mais c'est une essence de l'extraction de données. Pensons à gratter comme à couvrir le site Web avec une feuille de papier avec quelques rectangles découpés. Nous ne pouvons maintenant voir que les choses dont nous avons besoin, en ignorant complètement les parties du site qui sont communes pour toutes les pages (comme la navigation, pied de page, ads), ou des informations externes comme des commentaires ou des miettes de pain. En savoir plus sur les différences entre rampant et la mise à la ferraille vous trouverez ici: https://tarantoola.io/web-scraping-vs-web-crawling/