Quelle est la différence entre L'UNION et L'UNION tout?
22 réponses
UNION supprime les enregistrements en double (où toutes les colonnes dans les résultats sont les mêmes), UNION ALL ne le fait pas.
il y a un succès de performance lorsque vous utilisez UNION au lieu de UNION ALL , puisque le serveur de base de données doit faire un travail supplémentaire pour supprimer les lignes dupliquées, mais habituellement vous ne voulez pas les doublons (surtout lors de l'élaboration des rapports).
exemple D'UNION:
SELECT 'foo' AS bar UNION SELECT 'foo' AS bar
Résultat:
+-----+
| bar |
+-----+
| foo |
+-----+
1 row in set (0.00 sec)
UNION tout exemple:
SELECT 'foo' AS bar UNION ALL SELECT 'foo' AS bar
résultat:
+-----+
| bar |
+-----+
| foo |
| foo |
+-----+
2 rows in set (0.00 sec)
L'UNION et L'UNION concaténent toutes deux le résultat de deux SQL différentes. Ils diffèrent dans la façon dont ils traitent les doublons.
-
UNION effectue un DISTINCT sur l'ensemble de résultats, en éliminant les lignes en double.
-
UNION tout ne supprime pas les doublons, et il est donc plus rapide que L'UNION.
Note: Tandis Que en utilisant cette commande toutes les colonnes sélectionnées doivent être du même type de données.
exemple: si nous avons deux tables, 1) employé et 2) Client
- données de la table des employés:
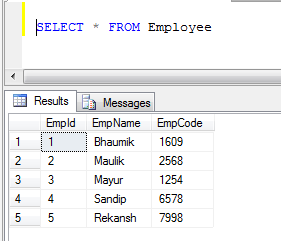
- données de table de client:
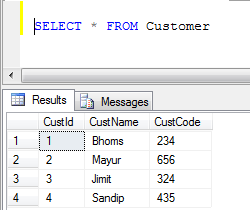
- exemple de syndicat (Il supprime tous les enregistrements en double):
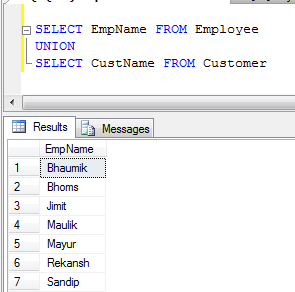
- l'UNION de TOUS Exemple (Il vient de concaténer des dossiers, de ne pas éliminer les doublons, de sorte qu'il est plus rapide que l'UNION):
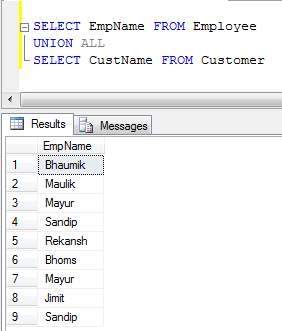
UNION supprime les doublons, alors que UNION ALL ne le fait pas.
afin d'éliminer les doublons, le jeu de résultats doit être trié, et ce peut avoir un impact sur les performances de L'UNION, en fonction du volume de données triées, et les réglages de divers paramètres RDBMS ( pour Oracle PGA_AGGREGATE_TARGET avec WORKAREA_SIZE_POLICY=AUTO ou SORT_AREA_SIZE et SOR_AREA_RETAINED_SIZE si WORKAREA_SIZE_POLICY=MANUAL ).
en gros, la sorte est plus rapide si elle peut être effectuée en mémoire, mais la même mise en garde sur le volume de données s'applique.
bien sûr, si vous avez besoin de données retournées sans duplicata alors vous doit utiliser UNION, en fonction de la source de vos données.
j'aurais commenté sur le premier message pour qualifier le commentaire" est beaucoup moins performant", mais ont la réputation insuffisante (points) pour le faire.
in ORACLE: UNION does not support BLOB (or CLOB) column types, UNION ALL does.
la différence fondamentale entre L'UNION et L'UNION tout est l'opération de l'union élimine les lignes dupliquées du jeu de résultats mais l'union retourne toutes les lignes après l'assemblage.
de http://zengin.wordpress.com/2007/07/31/union-vs-union-all /
vous pouvez éviter les doublons et courir encore beaucoup plus vite que UNION DISTINCT (qui est en fait identique à UNION) en lançant requête comme ceci:
SELECT * FROM mytable WHERE a=X UNION ALL SELECT * FROM mytable WHERE b=Y AND a!=X
noter la partie AND a!=X . C'est beaucoup plus rapide que L'UNION.
juste pour ajouter mes deux cents à la discussion ici: on pourrait comprendre l'opérateur UNION comme une UNION pure et orientée sur les ensembles-par exemple ensemble a={2,4,6,8}, ensemble B = {1,2,3,4}, une UNION b = {1,2,3,4,6,8}
quand vous avez affaire à des ensembles, vous ne voulez pas que les numéros 2 et 4 apparaissent deux fois, comme un élément soit est ou n'est pas dans un ensemble.
dans le monde de SQL, cependant, vous pourriez vouloir voir tous les les éléments de deux ensembles ensemble dans un "sac" {2,4,6,8,1,2,3,4}. Et pour cela T-SQL offre l'opérateur UNION ALL .
UNION
La commande UNION est utilisée pour sélectionner des informations connexes à partir de deux tableaux, un peu comme la commande JOIN . Cependant, lorsque vous utilisez la commande UNION , toutes les colonnes sélectionnées doivent être du même type de données. Avec UNION , seules des valeurs distinctes sont sélectionnées.
L'UNION DE TOUS
La commande UNION ALL est égale à Commande UNION , sauf que UNION ALL sélectionne toutes les valeurs.
la différence entre Union et Union all est que Union all n'éliminera pas les lignes dupliquées, au lieu de cela il tire juste toutes les lignes de toutes les tables ajustant vos spécificités de requête et les combine dans une table.
Un UNION déclaration efficacement à un SELECT DISTINCT sur le jeu de résultats. Si vous savez que tous les documents retournés sont uniques de votre syndicat, utilisez UNION ALL à la place, il donne des résultats plus rapides.
pas sûr qu'il importe quelle base de données
UNION et UNION ALL devraient fonctionner sur tous les serveurs SQL.
vous devez éviter d'inutiles UNION s ils sont énormes fuite de performance. Comme une règle d'utilisation de pouce UNION ALL si vous n'êtes pas sûr d'utiliser.
UNION-résultats dans documents distincts
alors que
UNION ALL-résultats dans tous les dossiers, y compris les doublons.
les deux sont des opérateurs de blocage et donc je préfère personnellement utiliser des jointures plutôt que des opérateurs de blocage(UNION, INTERSECT, UNION ALL etc. )) à tout moment.
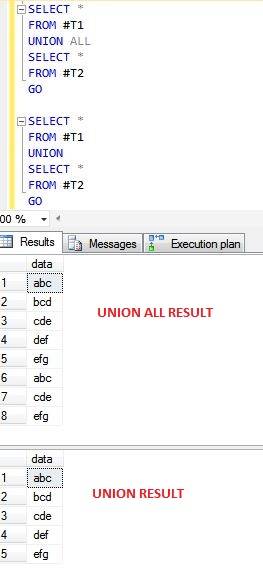
pour illustrer pourquoi les opérations syndicales donnent de mauvais résultats comparaison avec la caisse de tous les syndicats l'exemple suivant.
CREATE TABLE #T1 (data VARCHAR(10))
INSERT INTO #T1
SELECT 'abc'
UNION ALL
SELECT 'bcd'
UNION ALL
SELECT 'cde'
UNION ALL
SELECT 'def'
UNION ALL
SELECT 'efg'
CREATE TABLE #T2 (data VARCHAR(10))
INSERT INTO #T2
SELECT 'abc'
UNION ALL
SELECT 'cde'
UNION ALL
SELECT 'efg'
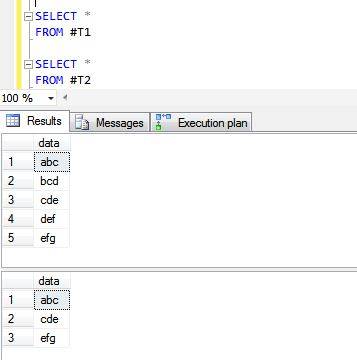
Voici les résultats des opérations de L'Union et de L'UNION.
une déclaration syndicale effectue effectivement un SELECT DISTINCT sur l'ensemble des résultats. Si vous savez que tous les enregistrements les retours sont uniques de votre union, utilisez UNION tous à la place, il donne des résultats plus rapides.
utilisant les résultats de L'UNION dans Tri Distinct opérations dans le Plan d'exécution. La preuve pour prouver cette déclaration est montrée ci-dessous:

(de Microsoft SQL Server Book Online)
UNION [TOUS]
spécifie que plusieurs ensembles de résultats doivent être combinés et retournés sous la forme d'un seul ensemble de résultats.
tous
incorpore toutes les lignes dans les résultats. Cela comprend les doublons. Si non spécifié, les doublons sont supprimés.
UNION prendra trop de temps car un doublon comme DISTINCT est appliqué sur les résultats.
SELECT * FROM Table1
UNION
SELECT * FROM Table2
est l'équivalent de:
SELECT DISTINCT * FROM (
SELECT * FROM Table1
UNION ALL
SELECT * FROM Table2) DT
un effet secondaire de l'application de
DISTINCTsur les résultats est une opération de tri sur les résultats.
UNION ALL les résultats seront affichés comme suit: arbitraire ordre des résultats mais UNION les résultats seront affichés comme ORDER BY 1, 2, 3, ..., n (n = column number of Tables) appliqué sur les résultats. Vous pouvez voir cet effet secondaire quand vous n'avez pas de ligne dupliquée.
il est bon de comprendre avec un diagramme de Venn.
voici le lien à la source. Il y a une bonne description.

j'ajoute un exemple,
UNION , il fusionne avec distinct --> plus lent, parce qu'il a besoin de comparer (dans Oracle SQL developer, choisissez requête, appuyez sur F10 pour voir l'analyse des coûts).
UNION ALL , il fusionne sans se distinguer --> plus vite.
SELECT to_date(sysdate, 'yyyy-mm-dd') FROM dual
UNION
SELECT to_date(sysdate, 'yyyy-mm-dd') FROM dual;
et
SELECT to_date(sysdate, 'yyyy-mm-dd') FROM dual
UNION ALL
SELECT to_date(sysdate, 'yyyy-mm-dd') FROM dual;
Une chose que je voudrais ajouter-
Union : - les résultats sont classés par ordre croissant.
Union All : - L'ensemble des résultats n'est pas trié. deux sorties de requête viennent d'être ajoutées.
UNION fusionne le contenu de deux tableaux structurellement compatibles en un seul tableau combiné.
- différence:
la différence entre UNION et UNION ALL est que UNION will omet les enregistrements en double tandis que UNION ALL inclura les enregistrements en double.
Le jeu de résultats Union est trié dans l'ordre croissant tandis que le jeu de résultats UNION ALL n'est pas trié
UNION exécute un DISTINCT sur son ensemble de résultats de sorte qu'il éliminera toute ligne dupliquée. Alors que UNION ALL ne va pas supprimer les doublons et donc il est plus rapide que UNION .*
Note : la performance de UNION ALL sera généralement meilleure que UNION , car UNION exige que le serveur fasse le travail supplémentaire de suppression des doublons. Ainsi, dans les cas où il est certain qu'il n'y aura pas de duplicata, ou lorsque le fait d'en avoir n'est pas un problème, l'utilisation de UNION ALL serait recommandée pour des raisons de performance.
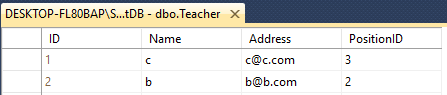
supposons que vous ayez deux tableaux enseignant & étudiant "15198090920 "
tous les deux ont 4 colonne avec un nom différent comme ceci
Teacher - ID(int), Name(varchar(50)), Address(varchar(50)), PositionID(varchar(50))
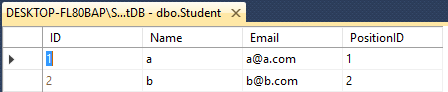
Student- ID(int), Name(varchar(50)), Email(varchar(50)), PositionID(int)
vous pouvez demander le syndicat ou L'UNION tout pour les deux tableaux qui ont le même nombre de colonnes. Mais ils ont un nom ou un type de données différent.
quand vous appliquez UNION opération sur 2 tables, il néglige toutes les entrées en double(toutes les colonnes valeur de ligne dans une table est même d'une autre table). Comme ceci
SELECT * FROM Student
UNION
SELECT * FROM Teacher
le résultat sera
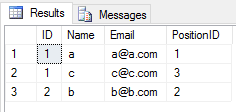
Quand vous appliquez UNION ALL opération sur 2 tables, il retourne toutes les entrées avec dupliquer(s'il y a une différence entre n'importe quelle valeur de colonne d'une ligne dans 2 tables). Comme ceci
SELECT * FROM Student
UNION ALL
SELECT * FROM Teacher
Sortie

Performance:
évidemment UNION toute la performance est meilleure que UNION comme ils font tâche supplémentaire pour supprimer les valeurs dupliquées. Vous pouvez vérifier que de exécution Temps Estimé par la presse ctrl+L à MSSQL
en termes très simples, la différence entre L'UNION et L'UNION est que L'UNION omettra les enregistrements en double, alors que L'UNION inclura tous les enregistrements en double.
UNION supprime les enregistrements en double dans une autre main UNION tout ne le fait pas. Mais il faut vérifier la majorité des données qui vont être traitées et la colonne et le type de données doivent être les mêmes.
puisque union utilise en interne un comportement "distinct" pour sélectionner les lignes, il est donc plus coûteux en termes de temps et de performance. comme
select project_id from t_project
union
select project_id from t_project_contact
cela me donne de l'2020 dossiers
d'autre part
select project_id from t_project
union all
select project_id from t_project_contact
me donne plus de 17402 lignes
sur la perspective de priorité les deux ont la même priorité.
s'il n'y a pas de ORDER BY , un UNION ALL peut rapporter des lignes comme il va, alors qu'un UNION vous ferait attendre jusqu'à la toute fin de la requête avant de vous donner le résultat entier ensemble à la fois. Cela peut faire une différence dans une situation de temporisation-un UNION ALL maintient la connexion en vie, pour ainsi dire.
donc si vous avez un problème de temps d'arrêt, et qu'il n'y a pas de tri, et que les doublons ne sont pas un problème, UNION ALL peut être plutôt utile.
UNION et UNION tous utilisés pour combiner deux ou plusieurs résultats de requête.
La commandesélectionne des informations distinctes et connexes à partir de deux tableaux, ce qui élimine les lignes dupliquées.
D'un autre côté, la commande UNION ALL sélectionne toutes les valeurs des deux tables, qui affiche toutes les lignes.
différence entre Union et Union tout en Sql
Qu'est-ce que le syndicat en SQL?
l'opérateur de L'UNION est utilisé pour combiner l'ensemble de résultats de deux ensembles de données ou plus .
Each SELECT statement within UNION must have the same number of columns
The columns must also have similar data types
The columns in each SELECT statement must also be in the same order