Quelle est la différence entre les objets HashMap et Map en Java?
Quelle est la différence entre les cartes suivantes que je crée (dans une autre question, les gens ont répondu en les utilisant apparemment de manière interchangeable et je me demande si/comment elles sont différentes):
HashMap<String, Object> map = new HashMap<String, Object>();
Map<String, Object> map = new HashMap<String, Object>();
13 réponses
Il n'y a pas de différence entre les objets; vous avez un HashMap<String, Object> dans les deux cas. Il y a une différence dans l'interface que vous avez à l'objet. Dans le premier cas, l'interface est HashMap<String, Object>, tandis que dans le second c'est Map<String, Object>. Mais l'objet sous-jacent est le même.
L'avantage d'utiliser Map<String, Object> est que vous pouvez changer l'objet sous-jacent pour qu'il soit un type de carte différent sans rompre votre contrat avec le code qui l'utilise. Si vous le déclarez comme HashMap<String, Object>, vous devez modifiez votre contrat si vous souhaitez modifier l'implémentation sous-jacente.
Exemple: disons que j'écris cette classe:
class Foo {
private HashMap<String, Object> things;
private HashMap<String, Object> moreThings;
protected HashMap<String, Object> getThings() {
return this.things;
}
protected HashMap<String, Object> getMoreThings() {
return this.moreThings;
}
public Foo() {
this.things = new HashMap<String, Object>();
this.moreThings = new HashMap<String, Object>();
}
// ...more...
}
La classe A quelques cartes internes de string- > object qu'elle partage (via des méthodes d'accesseur) avec des sous-classes. Disons que je l'écris avec HashMaps pour commencer parce que je pense que c'est la structure appropriée à utiliser lors de l'écriture de la classe.
Plus tard, Mary écrit le code sous-classant. Elle a quelque chose qu'elle doit faire avec les deux things et moreThings, donc naturellement elle met cela dans une méthode commune, et elle utilise le même type que j'ai utilisé sur getThings/getMoreThings lors de la définition de sa méthode:
class SpecialFoo extends Foo {
private void doSomething(HashMap<String, Object> t) {
// ...
}
public void whatever() {
this.doSomething(this.getThings());
this.doSomething(this.getMoreThings());
}
// ...more...
}
Plus Tard, je décide qu'en fait, c'est mieux si j'utilise TreeMap au lieu de HashMap dans Foo. Je mets à jour Foo, en changeant HashMap à TreeMap. Maintenant, SpecialFoo ne compile plus, parce que j'ai rompu le contrat: {[16] } disait qu'il fournissait HashMap s, mais maintenant il fournit TreeMaps à la place. Nous devons donc réparer SpecialFoo maintenant (et ce genre de chose peut onduler grâce à une base de code).
À moins d'avoir une très bonne raison de partager que mon implémentation utilisait un HashMap (et cela arrive), ce que j'aurais dû faire était de déclarer getThings et getMoreThings comme juste retourner Map<String, Object> sans être plus spécifique que cela. En fait, sauf une bonne raison de faire autre chose, même dans Foo je devrais probablement déclarer things et moreThings comme Map, pas HashMap/TreeMap:
class Foo {
private Map<String, Object> things; // <== Changed
private Map<String, Object> moreThings; // <== Changed
protected Map<String, Object> getThings() { // <== Changed
return this.things;
}
protected Map<String, Object> getMoreThings() { // <== Changed
return this.moreThings;
}
public Foo() {
this.things = new HashMap<String, Object>();
this.moreThings = new HashMap<String, Object>();
}
// ...more...
}
Notez comment j'utilise maintenant Map<String, Object> partout où je peux, seulement en étant spécifique quand je crée les objets réels.
Si j'avais fait cela, alors Marie aurait fait ceci:
class SpecialFoo extends Foo {
private void doSomething(Map<String, Object> t) { // <== Changed
// ...
}
public void whatever() {
this.doSomething(this.getThings());
this.doSomething(this.getMoreThings());
}
}
...et changer Foo n'aurait pas fait arrêter SpecialFoo de compiler.
Interfaces (et classes de base) laissez-nous révéler seulement autant que nécessaire , en gardant notre flexibilité sous les couvertures pour apporter des modifications appropriées. En général, nous voulons que nos références soient aussi basiques que possible. Si nous n'avons pas besoin de savoir que c'est un HashMap, appelez-le simplement un Map.
Ce n'est pas une règle aveugle, mais en général, le codage sur l'interface la plus générale sera moins fragile que le codage sur quelque chose de plus spécifique. Si je m'en étais souvenu, Je n'aurais pas créé un {[16] } qui a mis Mary en échec avec SpecialFoo. Si Mary s'en était souvenue, alors même si j'avais foiré Foo, elle aurait déclaré sa méthode privée avec Map au lieu de HashMap et mon changement de contrat de Foo ne l'aurait pas impactée code.
Parfois, vous ne pouvez pas faire cela, parfois vous devez être précis. Mais à moins que vous ayez une raison d'être, err vers l'interface la moins spécifique.
Carte est une interface HashMap met en œuvre. La différence est que dans la deuxième implémentation, votre référence au HashMap ne permettra que l'utilisation de fonctions définies dans L'interface Map, tandis que la première permettra l'utilisation de toutes les fonctions publiques dans HashMap (qui inclut l'interface Map).
Cela aura probablement plus de sens si vous lisez le tutoriel D'interface de Sun
J'allais juste le faire comme un commentaire sur la réponse acceptée mais c'est devenu trop funky (je déteste ne pas avoir de sauts de ligne)
Ah, donc la différence est que dans général, Map a certaines méthodes associé avec elle. mais il y a différentes façons ou la création d'une carte, tels que comme un HashMap, et ces différentes façons fournir des méthodes uniques qui ne sont pas toutes les cartes ont.
Exactement-et vous voulez toujours utiliser l'interface la plus générale possible. Considérez ArrayList vs LinkedList. Énorme différence dans la façon dont vous les utilisez, mais si vous utilisez "Liste", vous pouvez basculer entre eux facilement.
En fait, vous pouvez remplacer le côté droit de l'initialiseur par une instruction plus dynamique. Que diriez-vous de quelque chose comme ceci:
List collection;
if(keepSorted)
collection=new LinkedList();
else
collection=new ArrayList();
De cette façon, si vous allez remplir la collection avec un tri d'insertion, vous utiliserez une liste liée (un tri d'insertion dans une liste de tableau est criminel. Mais si vous n'avez pas besoin de garder triés et sont juste ajouter, que vous utilisez un ArrayList (plus efficace pour d'autres opérations).
C'est un gros tronçon ici parce que les collections ne sont pas le meilleur exemple, mais dans OO design, l'un des concepts les plus importants est d'utiliser la façade de l'interface pour accéder à différents objets avec exactement le même code.
Modifier la réponse au commentaire:
En ce qui concerne votre commentaire de carte ci-dessous, Oui, l'utilisation de l'interface "Map" vous limite à ces méthodes, sauf si vous renvoyez la collection de Map à HashMap (ce qui va à l'encontre de l'objectif).
Souvent, ce que vous allez faire est de créer un objet et de le remplir en utilisant son type spécifique (HashMap), dans une sorte de méthode "create" ou "initialize", mais cette méthode renverra une "Map" qui n'a plus besoin d'être manipulée en tant que HashMap.
Si jamais vous devez lancer en passant, vous utilisez probablement la mauvaise interface ou votre code n'est pas assez structuré. Notez qu'il est acceptable qu'une section de votre code la traite comme une "HashMap" tandis que l'autre le traite comme une "carte", mais cela devrait couler"vers le bas". de sorte que vous ne sont jamais de casting.
Notez également l'aspect semi-soigné des rôles indiqués par les interfaces. Une LinkedList fait une bonne pile ou une file d'attente, une ArrayList fait une bonne pile mais une file d'attente horrible (encore une fois, une suppression provoquerait un décalage de la liste entière) donc LinkedList implémente L'interface de file d'attente, ArrayList ne le fait pas.
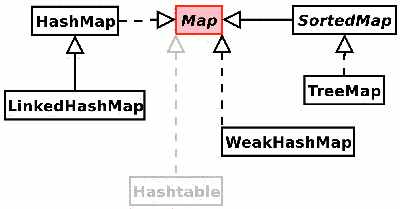
Map ayant les implémentations suivantes,
HashMap
Map m = new HashMap();LinkedHashMap
Map m = new LinkedHashMap();Arborescence De La Carte
Map m = new TreeMap();WeakHashMap
Map m = new WeakHashMap();
Supposons que vous ayez créé une méthode (c'est juste du code spudo).
public void HashMap getMap(){
return map;
}
Supposons que les exigences du projet changent à chaque fois comme suit,
- méthode devrait retourner le contenu de la carte-besoin de retourner
HashMap.
La méthode - doit renvoyer les clés de la carte dans l'ordre d'insertion - il faut changer le type de retour
HashMapenLinkedHashMap. - méthode doit retourner la clé de la carte dans l'ordre trié-besoin de changer le type de retour
LinkedHashMapàTreeMap.
Si votre méthode retourne des classes spécifiques au lieu de l'interface Map, vous devez changer le type de retour de la méthode getMap() à chaque fois.
Mais, si vous utilisez la fonctionnalité polymorphism de java, au lieu de renvoyer une classe spécifique utilisée interface Map, il conduit la réutilisabilité du code et moins d'impact si une exigence change.
Comme l'ont noté TJ Crowder et Adamski, une référence est à une interface, l'autre à une implémentation spécifique de l'interface. Selon Joshua Block, vous devriez toujours essayer de coder les interfaces, pour vous permettre de mieux gérer les modifications de l'implémentation sous - jacente-c'est-à-dire si HashMap n'était soudainement pas idéal pour votre solution et que vous deviez changer l'implémentation de la carte, vous pouvez toujours utiliser L'interface de Carte et changer le type d'instanciation.
Dans le deuxième exemple, la "carte" de référence est de type Map, qui est une interface implémentée par HashMap (et d'autres types de Map). Cette interface est un contrat indiquant que l'objet mappe les clés aux valeurs et prend en charge diverses opérations (par exemple put, get). Il dit rien sur l'implémentation du Map (dans ce cas un HashMap).
La deuxième approche est généralement préférée car vous ne voudriez généralement pas exposer l'implémentation de carte spécifique à méthodes utilisant le Map ou via une définition D'API.
Map est le type statique de map, tandis que HashMap est le type Dynamique de map. Cela signifie que le compilateur traitera votre objet map comme étant de type Map, même si à l'exécution, il peut pointer vers n'importe quel sous-type de celui-ci.
Cette pratique de programmation sur des interfaces au lieu d'implémentations a l'avantage supplémentaire de rester flexible: vous pouvez par exemple remplacer le type dynamique de map à l'exécution, tant qu'il s'agit d'un sous-type de Map (par exemple LinkedHashMap), et changer le comportement de la carte à la volée.
Une bonne règle est de rester aussi abstraite que possible au niveau de L'API: si par exemple une méthode que vous programmez doit fonctionner sur des maps, il suffit de déclarer un paramètre comme Map au lieu du type HashMap plus strict (car moins abstrait). De cette façon, le consommateur de votre API peut être flexible sur le type d'implémentation de carte qu'il veut transmettre à votre méthode.
Vous créez les mêmes cartes.
Mais vous pouvez combler la différence lorsque vous l'utiliserez. Avec le premier cas, vous pourrez utiliser des méthodes HashMap spéciales (mais je ne me souviens de personne vraiment utile), et vous pourrez le passer en tant que paramètre HashMap:
public void foo (HashMap<String, Object) { ... }
...
HashMap<String, Object> m1 = ...;
Map<String, Object> m2 = ...;
foo (m1);
foo ((HashMap<String, Object>)m2);
En ajoutant à la réponse votée en haut et beaucoup d'autres CI-DESSUS en soulignant le "plus générique, mieux", je voudrais creuser un peu plus.
Map est le contrat de structure tandis que HashMap est une implémentation fournissant ses propres méthodes pour traiter différents problèmes réels: comment calculer l'index, Quelle est la capacité et comment l'incrémenter, Comment insérer, comment garder l'index unique, etc.
Regardons dans le code source:
Dans Map, nous avons la méthode de containsKey(Object key):
boolean containsKey(Object key);
JavaDoc:
Java booléen.util.Cartographie.containsValue (valeur de L'objet)
Renvoie true si cette carte mappe une ou plusieurs clés à la valeur spécifiée. Plus formellement, renvoie true si et seulement si cette carte contient au moins un mappage à une valeur
vtelle que(value==null ? v==null : value.equals(v)). Cette opération nécessitera probablement un temps linéaire dans la taille de la carte pour la plupart des implémentations de l'interface de carte.Paramètres:valeur
Valeur dont la présence dans cette carte est à betested
Renvoie: true
Si cette carte mappe une ou plusieurs clés sur
ValueThrows:
ClassCastException-si la valeur est d'un type inapproprié pour cette carte (facultatif)
NullPointerException-si la valeur spécifiée est null et que cette carte n'autorise pas les valeurs null (facultatif)
Il nécessite ses implémentations pour l'implémenter, mais le "mode d'emploi" est à sa liberté, seulement pour s'assurer il retourne corriger.
Dans HashMap:
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
Il s'avère que HashMap utilise hashcode pour tester si cette carte contient la clé. Donc, il a l'avantage de l'algorithme de hachage.
Map est L'Interface et Hashmap est la classe qui l'implémente.
Donc, dans cette implémentation, vous créez les mêmes objets
HashMap est une implémentation de Map donc c'est tout à fait la même chose mais a la méthode "clone ()" comme je vois dans le guide de référence))
HashMap<String, Object> map1 = new HashMap<String, Object>();
Map<String, Object> map2 = new HashMap<String, Object>();
Tout d'Abord Map est une interface qu'il a mises en œuvre différentes comme - HashMap, TreeHashMap, LinkedHashMap etc. L'Interface fonctionne comme une super classe pour la classe d'implémentation. Donc, selon la règle de la POO, toute classe concrète qui implémente Map est également un Map. Cela signifie que nous pouvons assigner/mettre n'importe quelle variable de type HashMap à une variable de type Map sans aucun type de coulée.
Dans ce cas, nous pouvons assigner map1 à map2 sans aucune coulée ou perte de données -
map2 = map1