Quelle est la différence entre SAX et DOM?
J'ai lu quelques articles sur l' XML analyseurs et suis tombé sur SAX et DOM.
SAX est basé sur des événements et DOM est un modèle d'arbre - Je ne comprends pas les différences entre ces concepts.
D'après ce que j'ai compris, basé sur des événements signifie qu'une sorte d'événement arrive au nœud. Comme quand on clique sur un nœud particulier, il donnera tous les sous-nœuds plutôt que de charger tous les nœuds en même temps. Mais dans le cas de DOM l'analyse va charger tous les nœuds et créer le modèle d'arbre.
Ma compréhension est-elle correcte?
Veuillez me corriger si je me trompe ou m'expliquer le modèle basé sur les événements et l'arbre d'une manière plus simple.
10 réponses
Eh bien, vous êtes proche.
Dans SAX, les événements sont déclenchés lorsque le XML est analysé . Lorsque l'analyseur analyse le XML et rencontre un début de balise (par exemple <something>), il déclenche l'événement tagStarted (le nom réel de l'événement peut différer). De même, lorsque la fin de la balise est atteinte lors de l'analyse (</something>), elle déclenche tagEnded. L'utilisation D'un analyseur SAX implique que vous devez gérer ces événements et donner un sens aux données renvoyées avec chaque événement.
Dans DOM, il n'y a pas d'événements déclenchée lors de l'analyse. Le XML entier est analysé et une arborescence DOM (des nœuds du XML) est générée et renvoyée. Une fois analysé, l'utilisateur peut naviguer dans l'arborescence pour accéder aux différentes données précédemment intégrées dans les différents nœuds du XML.
En général, DOM est plus facile à utiliser mais a une surcharge d'analyse de L'ensemble du XML avant de pouvoir commencer à l'utiliser.
En quelques mots...
SAX (Smise UNPI pour XML): Est un flux à base de processeur. Vous n'avez qu'une petite partie en mémoire à tout moment et vous "reniflez" le flux XML en implémentant du code de rappel pour des événements comme tagStarted() etc. Il n'utilise presque pas de mémoire, mais vous ne pouvez pas faire des choses "DOM", comme utiliser xpath ou traverser des arbres.
DOM (Document Oobjet Model): Vous chargez le tout dans la mémoire - c'est un énorme dévoreur de mémoire. Vous pouvez souffler la mémoire avec même des documents de taille moyenne. Mais vous pouvez utiliser xpath et traverser l'arbre, etc.
Ici en mots plus simples:
DOM
Analyseur de modèle D'arbre (basé sur un objet) (Arbre de nœuds).
DOM charge le fichier dans la mémoire, puis analyse le fichier.
A des contraintes de mémoire car il charge l'ensemble du fichier XML avant l'analyse.
DOM est en lecture et en écriture (peut insérer ou supprimer des nœuds).
Si le contenu XML est petit, préférez L'analyseur DOM.
Recherche en arrière et en avant est possible pour la recherche des balises et l'évaluation de la informations à l'intérieur des balises. Cela donne donc la facilité de navigation.
Plus lent au moment de l'exécution.
SAX
Analyseur basé sur les événements (séquence d'événements).
SAX analyse le fichier tel qu'il le lit, c'est-à-dire analyse nœud par nœud.
Pas de contraintes de mémoire car il ne stocke pas le contenu XML dans la mémoire.
SAX est en lecture seule c'est à dire ne peut pas insérez ou supprimez le nœud.
Utilisez l'analyseur SAX lorsque le contenu de la mémoire est volumineux.
SAX lit le fichier XML de haut en bas et la navigation vers l'arrière n'est pas possible.
Plus Rapide au moment de l'exécution.
Vous avez raison dans votre compréhension du modèle basé sur DOM. Le fichier XML sera chargé dans son ensemble et tout son contenu sera construit comme une représentation en mémoire de l'arborescence que le document représente. Cela peut prendre du temps et de la mémoire, selon la taille du fichier d'entrée. L'avantage de cette approche est que vous pouvez facilement interroger n'importe quelle partie du document et manipuler librement tous les nœuds de l'arborescence.
L'approche DOM est généralement utilisée pour les petites structures XML (où small dépend de la puissance et de la mémoire de votre plate-forme) qui peuvent avoir besoin d'être modifiés et interrogés de différentes manières une fois qu'ils ont été chargés.
SAX d'autre part est conçu pour gérer L'entrée XML de pratiquement n'importe quelle taille. Au lieu du framework XML, vous devez travailler dur pour déterminer la structure du document et préparer potentiellement beaucoup d'objets pour tous les nœuds, attributs, etc., SAX laisse complètement cela à vous.
Ce qu'il fait est-ce Lire l'entrée du haut et appeler les méthodes de rappel que vous fournissez lorsque certains "événements" se produisent. Un événement peut frapper une balise d'ouverture, un attribut dans la balise, trouver du texte à l'intérieur d'un élément ou rencontrer une balise de fin.
SAX lit obstinément l'entrée et vous indique ce qu'il voit de cette façon. C'est à vous de maintenir toutes les informations d'État dont vous avez besoin. Habituellement, cela signifie que vous allez construire une sorte de machine d'état.
Bien que cette approche du traitement XML soit beaucoup plus fastidieux, il peut être très puissant, aussi. Imaginez que vous voulez simplement extraire les titres des articles de presse d'un flux de blog. Si vous lisez ce XML en utilisant DOM, il chargerait tout le contenu de l'article, toutes les images, etc. qui sont contenus dans le XML en mémoire, même si vous n'êtes même pas intéressé par cela.
Avec SAX, vous pouvez simplement vérifier si le nom de l'élément est (par exemple) "title" chaque fois que votre méthode d'événement "startTag" est appelée. Si c'est le cas, vous savez que vous devez ajouter la prochaine l'événement "elementText" vous offre. Lorsque vous recevez l'appel d'événement" endTag", vous vérifiez à nouveau s'il s'agit de l'élément de fermeture du"title". Après cela, vous ignorez simplement tous les autres éléments, jusqu'à ce que l'entrée se termine, ou qu'un autre "startTag" avec un nom de "title" arrive. Et ainsi de suite...
Vous pouvez lire des mégaoctets et des mégaoctets de XML de cette façon, en extrayant simplement la petite quantité de données dont vous avez besoin.
Le côté négatif de cette approche est, bien sûr, que vous devez faire beaucoup plus de tenue de livres vous-même, en fonction des données que vous devez extraire et de la complexité de la structure XML. De plus, vous ne pouvez naturellement pas modifier la structure de L'arborescence XML, car vous ne l'avez jamais en main dans son ensemble.
Donc, en général, SAX est adapté pour passer au peigne fin des quantités potentiellement importantes de données que vous recevez avec une "requête" spécifique à l'esprit, mais n'a pas besoin de modifier, tandis que DOM vise davantage à vous donner une flexibilité totale dans le changement de structure et de contenu, au détriment demande de ressources plus élevée.
Vous comparez les pommes et les poires. SAX est un analyseur qui analyse les structures Dom sérialisées. Il existe de nombreux analyseurs différents, et "basé sur les événements" fait référence à la méthode d'analyse.
Peut-être un petit récapitulatif est dans l'ordre:
Le document object model (DOM) est un modèle de données abstrait qui décrit une structure de document hiérarchique, arborescente; un arbre de document se compose de noeuds , à savoir élément, attribut et noeuds de texte (et quelques autres). Nœud avoir des parents, des frères et sœurs et des enfants et peut être traversé, etc., tout ce que vous avez l'habitude de faire JavaScript (qui n'a d'ailleurs rien à voir avec le DOM).
Une structure DOM peut être sérialisée , c'est-à-dire écrite dans un fichier, en utilisant un langage de balisage comme HTML ou XML. Un fichier HTML ou XML contient donc une version "écrite" ou "aplatie" d'une arborescence de documents abstraits.
Pour qu'un ordinateur manipule, ou même affiche, une arborescence DOM à partir d'un fichier, il doit désérialiser , ou analyser, le fichier et reconstruire l'arbre abstrait en mémoire. C'est là que l'analyse est en.
Maintenant, nous arrivons à la nature des analyseurs. Une façon d'analyser serait à lire dans l'ensemble du document et de manière récursive construire une arborescence dans la mémoire, et enfin d'exposer l'ensemble du résultat à l'utilisateur. (Je suppose que vous pourriez appeler ces analyseurs "parseurs DOM".) Ce serait très pratique pour l'utilisateur (je pense que c'est ce que fait L'analyseur XML de PHP), mais il souffre de problèmes d'évolutivité et devient très coûteux pour les gros documents.
D'autre part, l'analyse basée sur les événements, comme effectuée par SAX, regarde le fichier de manière linéaire et fait simplement call-Back à l'utilisateur chaque fois qu'il rencontre un élément structurel de données, comme "cet élément a commencé", "cet élément s'est terminé", "DU TEXTE ICI", etc. Cela a l'avantage de pouvoir durer éternellement sans se soucier de la taille du fichier d'entrée, mais c'est beaucoup plus bas niveau car exige que l'utilisateur effectue tout le travail de traitement réel (en fournissant des rappels). Pour revenir à votre question initiale, le terme " basé sur des événements "fait référence aux événements d'analyse que l'analyseur soulève lorsqu'il traverse le fichier XML.
L'article Wikipedia contient de nombreux détails sur les étapes de L'analyse Saxo.
Je vais fournir une réponse générale axée sur les questions et réponses à cette question:
Réponse aux Questions
Pourquoi avons-nous besoin D'un analyseur XML?
Nous avons besoin D'un analyseur XML parce que nous ne voulons pas tout faire dans notre application à partir de zéro, et nous avons besoin de programmes ou de bibliothèques "helper" pour faire quelque chose de très bas niveau mais très nécessaire pour nous. Ces choses de bas niveau mais nécessaires incluent la vérification de la bonne forme, la validation du document par rapport à sa DTD ou à son schéma (juste pour valider les analyseurs), résoudre la référence de caractères, comprendre les sections CDATA, etc. Les analyseurs XML sont juste de tels programmes "d'AIDE" et ils feront tous ces travaux. Avec XML parser, nous sommes à l'abri de beaucoup de ces complexités et nous pourrions nous concentrer sur la programmation À haut niveau via les API implémentées par les analyseurs, et ainsi gagner en efficacité de programmation.
Lequel est le meilleur, SAX ou DOM ?
Analyseur SAX et DOM ont leurs avantages et leurs inconvénients. Quel est le meilleur devrait dépendre des caractéristiques de votre application (veuillez vous référer à quelques questions ci-dessous).
Quel analyseur peut obtenir de meilleurs analyseurs de vitesse, DOM ou SAX?
L'analyseur SAX peut obtenir une meilleure vitesse.
Quelle est la différence entre L'API basée sur l'arborescence et L'API basée sur les événements?
Une API arborescente est centrée autour d'une structure arborescente et fournit donc des interfaces sur les composants d'une arborescence (qui est un document DOM) tels que L'interface de Document, L'interface de Noeud, l'interface de NodeList, l'interface D'élément, L'interface D'Attr et ainsi de suite. En revanche, une API basée sur des événements fournit des interfaces sur les gestionnaires. Il existe quatre interfaces de gestionnaire, L'interface ContentHandler, L'interface DTDHandler, L'interface EntityResolver et L'interface ErrorHandler.
Quelle est la différence entre un analyseur DOM et un analyseur SAX?
Les analyseurs DOM et SAX fonctionnent de différentes manières:
Un analyseur DOM crée une structure arborescente en mémoire à partir de l'entrée document, puis attend les demandes du client. Mais un analyseur SAX ne crée aucune structure interne. Au lieu de cela, il prend l' occurrences de composants d'un document d'entrée en tant qu'événements, et indique le client ce qu'il lit comme il lit à travers le document d'entrée. Un
DOM parser sert toujours l'application cliente avec l'ensemble document peu importe combien est réellement nécessaire par le client. Mais un Sax parser sert l'application cliente toujours uniquement avec des morceaux de le document à un moment donné.
- avec l'analyseur DOM, la méthode appelle l'application client doit être explicite et forme une sorte de chaîne. Mais avec SAX, certaines méthodes (généralement remplacées par le cient) seront être invoquée automatiquement (implicitement) d'une manière qui est appelé "callback" lorsque certains événements se produisent. Ces méthodes n'ont pas être appelé explicitement par le client, bien que nous puissions appeler ils explicitement.
Comment décider quel analyseur est bon?
Idéalement, un bon analyseur devrait être rapide (efficace dans le temps),efficace dans l'espace, riche en fonctionnalités et facile à utiliser. Mais en réalité, aucun des analyseurs principaux n'a toutes ces fonctionnalités en même temps. Par exemple, un analyseur DOM est riche en fonctionnalités (car il crée une arborescence DOM en mémoire et vous permet d'accéder à n'importe quelle partie du document à plusieurs reprises et vous permet de modifier L'arborescence DOM), mais c'est le cas espace inefficace lorsque le document est énorme, et il faut un peu de temps pour apprendre à travailler avec elle. Un analyseur SAX, cependant, est beaucoup plus efficace dans le cas d'un gros document d'entrée (car il ne crée aucune structure interne). De plus, il s'exécute plus rapidement et est plus facile à apprendre que DOM Parser car son API est vraiment simple. Mais du point de vue de la fonctionnalité, il fournit moins de fonctions qui signifient que les utilisateurs eux-mêmes doivent prendre soin de plus, comme la création de leurs propres données structure. Par la manière, ce qui est un bon analyseur? Je pense que la réponse dépend vraiment des caractéristiques de votre application.
Quelles sont les applications du monde réel où l'utilisation de Sax parser est avantageux que D'utiliser DOM parser et vice versa? Quels sont les habituels application pour un analyseur DOM et pour un analyseur SAX?
Dans les cas suivants, l'utilisation de l'analyseur SAX est avantageuse que L'utilisation de L'analyseur DOM.
- le document d'entrée est trop grand pour Disponible mémoire (en fait dans ce cas SAX est votre seul choix)
- vous pouvez traiter le document en petits morceaux contigus d'entrée. Vous n'avez pas besoin du document entier avant de pouvoir faire un travail utile
- vous voulez juste utiliser l'analyseur pour extraire les informations d'intérêt, et tout votre calcul sera entièrement basé sur les structures de données créées par vous-même. En fait, dans la plupart de nos applications, nous créons nos propres structures de données qui ne sont généralement pas aussi compliquées que Arborescence DOM. De ce sens, je pense que la chance d'utiliser un analyseur DOM est inférieure à celle d'utiliser un analyseur SAX.
Dans les cas suivants, l'utilisation de L'analyseur DOM est avantageuse que l'utilisation de l'analyseur SAX.
- votre application doit accéder à plusieurs parties distinctes du document en même temps.
- votre application peut probablement utiliser une structure de données interne presque aussi compliquée que le document lui-même.
- votre application doit modifier le document à plusieurs reprises.
- votre application doit stocker le document pendant une période significative via de nombreux appels de méthode.
Exemple (utiliser un analyseur DOM ou un analyseur SAX?):
supposons qu'un instructeur dispose d'un document XML contenant toutes les informations personnelles des élèves ainsi que les points que ses élèves ont faits dans sa classe, et il attribue maintenant les notes finales aux élèves à l'aide d'une application. Ce qu'il veut produire, c'est une liste avec le SSN et les notes. Nous supposons également que dans son application, l'instructeur n'utilise aucune structure de données telle que des tableaux pour stocker les informations personnelles de l'étudiant et les points. Si l'instructeur décide de donner des A à ceux qui ont gagné la moyenne de la classe ou plus, et de donner des B aux autres, alors il vaut mieux utiliser un analyseur DOM dans son application. La raison en est qu'il n'a aucun moyen de savoir combien est la moyenne de la classe avant que le document entier ne soit traité. Ce qu'il a probablement besoin de le faire dans son application, est d'abord de regarder à travers tous les points des étudiants et calculer la moyenne, puis regarder à nouveau à travers le document et attribuer la note finale à chaque étudiant en comparant les points qu'il a gagnés à la moyenne de la classe. Si, cependant, l'instructeur adopte une telle politique de notation que les étudiants qui ont obtenu 90 points ou plus se voient attribuer des A et que les autres se voient attribuer des B, il vaudrait probablement mieux utiliser un analyseur SAX. La raison en est, pour attribuer à chaque élève une note finale, il n'a pas besoin pour attendre que le document entier soit traité. Il pourrait immédiatement attribuer une note à un étudiant une fois que l'analyseur SAX lit la note de cet étudiant. Dans l'analyse ci-dessus, nous avons supposé que l'instructeur n'avait créé aucune structure de données propre. Que se passe-t-il s'il crée sa propre structure de données, comme un tableau de chaînes pour stocker le SSN et un tableau d'entiers pour stocker les points ? Dans ce cas, je pense que SAX est un meilleur choix, avant que cela puisse économiser à la fois de la mémoire et du temps, mais obtenir le travail faire. Eh bien, une autre considération sur cet exemple. Que faire si ce que l'instructeur veut faire n'est pas d'imprimer une liste, mais de sauvegarder le document original avec la note de chaque élève mise à jour ? Dans ce cas, un analyseur DOM devrait être un meilleur choix, quelle que soit la Politique de notation qu'il adopte. Il n'a pas besoin de créer sa propre structure de données. Ce qu'il doit faire est de modifier d'abord L'arbre DOM (c'est-à-dire, définir la valeur sur le nœud 'grade'), puis enregistrer l'arbre modifié entier. S'il choisit d' utilisez un analyseur SAX au lieu d'un analyseur DOM, puis dans ce cas, il doit créer une structure de données qui est presque aussi compliquée qu'un arbre DOM avant de pouvoir faire le travail.
Un Exemple
Énoncé du Problème: Écrire un programme Java pour extraire tous les informations sur les cercles qui sont des éléments dans un document XML donné. Nous supposons que chaque élément de cercle a trois éléments enfants (c.-À-D., x, y et rayon), ainsi qu'un attribut de couleur. Échantillon le document est donné ci-dessous:
<?xml version="1.0"?>
<!DOCTYPE shapes [
<!ELEMENT shapes (circle)*>
<!ELEMENT circle (x,y,radius)>
<!ELEMENT x (#PCDATA)>
<!ELEMENT y (#PCDATA)>
<!ELEMENT radius (#PCDATA)>
<!ATTLIST circle color CDATA #IMPLIED>
]>
<shapes>
<circle color="BLUE">
<x>20</x>
<y>20</y>
<radius>20</radius>
</circle>
<circle color="RED" >
<x>40</x>
<y>40</y>
<radius>20</radius>
</circle>
</shapes>
Programme avec DOMparser
import java.io.*;
import org.w3c.dom.*;
import org.apache.xerces.parsers.DOMParser;
public class shapes_DOM {
static int numberOfCircles = 0; // total number of circles seen
static int x[] = new int[1000]; // X-coordinates of the centers
static int y[] = new int[1000]; // Y-coordinates of the centers
static int r[] = new int[1000]; // radius of the circle
static String color[] = new String[1000]; // colors of the circles
public static void main(String[] args) {
try{
// create a DOMParser
DOMParser parser=new DOMParser();
parser.parse(args[0]);
// get the DOM Document object
Document doc=parser.getDocument();
// get all the circle nodes
NodeList nodelist = doc.getElementsByTagName("circle");
numberOfCircles = nodelist.getLength();
// retrieve all info about the circles
for(int i=0; i<nodelist.getLength(); i++) {
// get one circle node
Node node = nodelist.item(i);
// get the color attribute
NamedNodeMap attrs = node.getAttributes();
if(attrs.getLength() > 0)
color[i]=(String)attrs.getNamedItem("color").getNodeValue();
// get the child nodes of a circle node
NodeList childnodelist = node.getChildNodes();
// get the x and y value
for(int j=0; j<childnodelist.getLength(); j++) {
Node childnode = childnodelist.item(j);
Node textnode = childnode.getFirstChild();//the only text node
String childnodename=childnode.getNodeName();
if(childnodename.equals("x"))
x[i]= Integer.parseInt(textnode.getNodeValue().trim());
else if(childnodename.equals("y"))
y[i]= Integer.parseInt(textnode.getNodeValue().trim());
else if(childnodename.equals("radius"))
r[i]= Integer.parseInt(textnode.getNodeValue().trim());
}
}
// print the result
System.out.println("circles="+numberOfCircles);
for(int i=0;i<numberOfCircles;i++) {
String line="";
line=line+"(x="+x[i]+",y="+y[i]+",r="+r[i]+",color="+color[i]+")";
System.out.println(line);
}
} catch (Exception e) {e.printStackTrace(System.err);}
}
}
Programme avec SAXparser
import java.io.*;
import org.xml.sax.*;
import org.xml.sax.helpers.DefaultHandler;
import org.apache.xerces.parsers.SAXParser;
public class shapes_SAX extends DefaultHandler {
static int numberOfCircles = 0; // total number of circles seen
static int x[] = new int[1000]; // X-coordinates of the centers
static int y[] = new int[1000]; // Y-coordinates of the centers
static int r[] = new int[1000]; // radius of the circle
static String color[] = new String[1000]; // colors of the circles
static int flagX=0; //to remember what element has occurred
static int flagY=0; //to remember what element has occurred
static int flagR=0; //to remember what element has occurred
// main method
public static void main(String[] args) {
try{
shapes_SAX SAXHandler = new shapes_SAX (); // an instance of this class
SAXParser parser=new SAXParser(); // create a SAXParser object
parser.setContentHandler(SAXHandler); // register with the ContentHandler
parser.parse(args[0]);
} catch (Exception e) {e.printStackTrace(System.err);} // catch exeptions
}
// override the startElement() method
public void startElement(String uri, String localName,
String rawName, Attributes attributes) {
if(rawName.equals("circle")) // if a circle element is seen
color[numberOfCircles]=attributes.getValue("color"); // get the color attribute
else if(rawName.equals("x")) // if a x element is seen set the flag as 1
flagX=1;
else if(rawName.equals("y")) // if a y element is seen set the flag as 2
flagY=1;
else if(rawName.equals("radius")) // if a radius element is seen set the flag as 3
flagR=1;
}
// override the endElement() method
public void endElement(String uri, String localName, String rawName) {
// in this example we do not need to do anything else here
if(rawName.equals("circle")) // if a circle element is ended
numberOfCircles += 1; // increment the counter
}
// override the characters() method
public void characters(char characters[], int start, int length) {
String characterData =
(new String(characters,start,length)).trim(); // get the text
if(flagX==1) { // indicate this text is for <x> element
x[numberOfCircles] = Integer.parseInt(characterData);
flagX=0;
}
else if(flagY==1) { // indicate this text is for <y> element
y[numberOfCircles] = Integer.parseInt(characterData);
flagY=0;
}
else if(flagR==1) { // indicate this text is for <radius> element
r[numberOfCircles] = Integer.parseInt(characterData);
flagR=0;
}
}
// override the endDocument() method
public void endDocument() {
// when the end of document is seen, just print the circle info
System.out.println("circles="+numberOfCircles);
for(int i=0;i<numberOfCircles;i++) {
String line="";
line=line+"(x="+x[i]+",y="+y[i]+",r="+r[i]+",color="+color[i]+")";
System.out.println(line);
}
}
}
En pratique: livre.xml
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
</bookstore>
- DOM présente le document xml comme une arborescence suivante en mémoire.
- DOM est la norme W3C.
- DOM parser fonctionne sur le modèle D'objet de Document.
- DOM occupe plus de mémoire, préféré pour les petits documents XML
- DOM est facile à naviguer vers l'avant ou vers l'arrière.
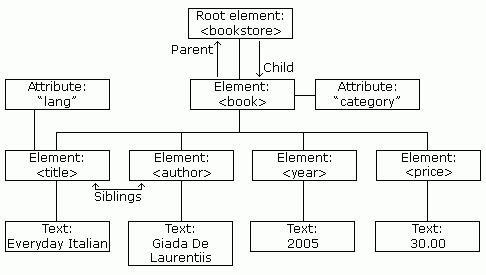
- SAX présente le document xml comme basé sur des événements comme
start element:abc,end element:abc. - SAX n'est pas la norme W3C, il a été développé par un groupe de développeurs.
- SAX n'utilise pas de mémoire, préféré pour les documents XML volumineux.
- la navigation vers L'arrière n'est pas possible car elle traite séquentiellement les documents.
- L'événement arrive à un nœud / élément et il donne tous les sous-nœuds (Nodus latins ‘ 'noeud').
Ce document XML, lorsqu'il est passé par un analyseur SAX, génère une séquence d'événements comme:
start element: bookstore
start element: book with an attribute category equal to cooking
start element: title with an attribute lang equal to en
Text node, with data equal to Everyday Italian
....
end element: title
.....
end element: book
end element: bookstore
DOM signifie Document Object Model et représente un Document XML au format arborescence dont chaque élément représente des branches arborescentes. DOM Parser crée une représentation arborescente en mémoire du fichier XML, puis l'analyse, de sorte qu'il nécessite plus de mémoire et il est conseillé d'avoir une taille de tas accrue pour DOM parser afin d'éviter Java.lang.OutOfMemoryError: espace de tas java . L'analyse du fichier XML à L'aide de DOM parser est assez rapide si le fichier XML est petit mais si vous essayez de lire un fichier XML volumineux en utilisant DOM parser il y a plus de chances que cela prenne beaucoup de temps ou même ne puisse pas le charger complètement simplement parce qu'il nécessite beaucoup de mémoire pour créer un arbre DOM XML. Java prend en charge L'analyse DOM et vous pouvez analyser les fichiers XML en Java à L'aide de DOM parser. Les classes DOM sont dans le paquet w3c. dom tandis que DOM Parser pour Java est dans le paquet JAXP (Java API for XML Parsing).
Analyseur XML SAX en Java
SAX signifie API Simple pour L'analyse XML. Il s'agit d'une analyse XML basée sur des événements et analyser le fichier XML étape par étape tellement approprié pour les gros fichiers XML. L'analyseur XML SAX déclenche un événement lorsqu'il rencontre une balise, un élément ou un attribut d'ouverture et l'analyse fonctionne en conséquence. Il est recommandé d'utiliser l'analyseur XML SAX pour analyser de gros fichiers xml en Java, car il ne nécessite pas de charger un fichier XML entier en Java et il peut lire un gros fichier XML en petites parties. Java fournit un support pour l'analyseur SAX et vous pouvez analyser n'importe quel fichier xml en Java en utilisant L'analyseur SAX, j'ai couvert exemple de lecture de fichier xml en utilisant L'analyseur SAX ici. Un inconvénient de l'utilisation de L'analyseur SAX en java est que la lecture D'un fichier XML en Java à l'aide de L'analyseur SAX nécessite plus de code par rapport à L'analyseur DOM.
Différence entre L'analyseur XML DOM et SAX
Voici quelques différences de haut niveau entre L'analyseur DOM et L'analyseur SAX en Java:
1) DOM parser charge tout le document xml en mémoire tandis que SAX ne charge qu'une petite partie du fichier XML en mémoire.
2) L'analyseur DOM est plus rapide que SAX car il accède au XML entier document en mémoire.
3) L'analyseur SAX en Java est mieux adapté pour les gros fichiers XML que L'analyseur DOM car il ne nécessite pas beaucoup de mémoire.
4) L'analyseur DOM fonctionne sur le modèle D'objet de Document tandis que SAX est un analyseur xml basé sur des événements.
Lire la suite: http://javarevisited.blogspot.com/2011/12/difference-between-dom-and-sax-parsers.html#ixzz2uz1bJQqZ
SAX et DOM sont utilisés pour analyser le document XML. Les deux ont des avantages et des inconvénients et peuvent être utilisés dans notre programmation en fonction de la situation
SAX:
Analyse de nœud en nœud
-
Ne stocke pas le XML en mémoire
Nous ne pouvons pas insérer ou supprimer un nœud
-
De haut en bas en traversant
DOM
Stocke l'ensemble du document XML en mémoire avant traitement
Occupe plus de mémoire
On peut insérer ou supprimer des nœuds
Traverser dans n'importe quelle direction.
Si nous avons besoin de trouver un nœud et n'a pas besoin d'insérer ou de supprimer, nous pouvons aller avec SAX lui-même sinon DOM à condition que nous ayons plus de mémoire.
1) DOM parser charge tout le document XML en mémoire tandis que SAX ne charge qu'une petite partie du fichier XML en mémoire.
2) L'analyseur DOM est plus rapide que SAX car il accède à tout le document XML en mémoire.
3) L'analyseur SAX en Java est mieux adapté pour les gros fichiers XML que L'analyseur DOM car il ne nécessite pas beaucoup de mémoire.
4) L'analyseur DOM fonctionne sur le modèle D'objet de Document tandis que SAX est un analyseur XML basé sur des événements.
Lire la suite: http://javarevisited.blogspot.com/2011/12/difference-between-dom-and-sax-parsers.html#ixzz498y3vPFR