Quelle est la différence entre la lecture non reproductible et la lecture fantôme?
Quelle est la différence entre la lecture non reproductible et la lecture fantôme?
J'ai lu le Isolement (systèmes de base de données) de l'article de Wikipédia, mais j'ai quelques doutes. Dans l'exemple ci-dessous, que se passera-t-il: lecture non répétable et lecture fantôme?
Transaction ASELECT ID, USERNAME, accountno, amount FROM USERS WHERE ID=1
1----MIKE------29019892---------5000
UPDATE USERS SET amount=amount+5000 where ID=1 AND accountno=29019892;
COMMIT;
SELECT ID, USERNAME, accountno, amount FROM USERS WHERE ID=1
Un autre doute est, dans l'exemple ci-dessus, quel niveau d'isolement doit être utilisé? Et pourquoi?
8 réponses
De Wikipedia (qui a des exemples grands et détaillés pour cela):
Une lecture non répétable se produit lorsque, au cours d'une transaction, une ligne est récupérée deux fois et que les valeurs de la ligne diffèrent entre les lectures.
Et
Une lecture fantôme se produit lorsque, au cours d'une transaction, deux requêtes identiques sont exécutées et que la collection de lignes renvoyées par la seconde requête est différente de la première.
Simple exemples:
- L'Utilisateur a exécute la même requête deux fois.
- entre les deux, L'utilisateur B exécute une transaction et valide.
- lecture non répétable: la ligne A interrogée par l'utilisateur A a une valeur différente la deuxième fois.
- Phantom read: toutes les lignes de la requête ont la même valeur avant et après, mais différentes lignes sont sélectionnées (Car B en a supprimé ou inséré certaines). Exemple:
select sum(x) from table;renverra un résultat différent même si aucune des lignes affectées eux-mêmes ont été mis à jour, si des lignes ont été ajoutées ou supprimées.
Dans l'exemple ci-dessus,quel niveau d'isolement utiliser?
Le niveau d'isolement dont vous avez besoin dépend de votre application. Il y a un coût élevé à un niveau d'isolement "meilleur "(tel que la concurrence réduite).
Dans votre exemple, vous n'aurez pas de lecture fantôme, car vous ne sélectionnez qu'une seule ligne (identifiée par la clé primaire). Vous pouvez avoir des lectures non reproductibles, donc si c'est un problème, vous peut vouloir avoir un niveau d'isolement qui empêche cela. Dans Oracle, la transaction A peut également émettre un SELECT pour la mise à jour, puis la transaction B ne peut pas changer la ligne tant que A n'est pas terminé.
Une façon simple d'y penser est:
Les lectures non répétables et fantômes ont à voir avec les opérations de modification de données d'une transaction différente, qui ont été validées après le début de votre transaction, puis lues par votre transaction.
Les lectures non répétables sont lorsque votre transaction lit validée met à jour à partir d'une autre transaction. La même ligne a maintenant des valeurs différentes de celles du début de votre transaction.
Les lectures fantômes sont similaires mais lors de la lecture à partir de validés, insère et/ou supprime d'une autre transaction. Il y a de nouvelles lignes ou lignes qui ont disparu depuis que vous avez commencé la transaction.
Les lectures Sales sont similaires aux lectures non répétables et fantômes, mais se rapportent à la lecture de données non validées et se produisent lorsqu'une mise à jour, une insertion ou une suppression d'une autre transaction est lue et que L'autre transaction N'a pas encore validé les données. Il lit des données "en cours" , qui peuvent ne pas être complet, et peut ne jamais être réellement commis.
Il existe une différence dans l'implémentation entre ces deux types de niveaux d'isolement.
Pour "lecture non reproductible", le verrouillage de ligne est nécessaire.
Pour "phantom read" ,scoped-verrouillage est nécessaire, même un verrouillage de table.
Nous pouvons implémenter ces deux niveaux en utilisant le protocoleà verrouillage biphasé .
Dirty read: lit les données non validées d'une autre transaction.
Lecture non répétable: lecture des données validées d'une requête de mise à jour d'une autre transaction.
Phantom read: lit les données COMMITED d'une requête INSERT ou DELETE d'une autre transaction.
Notez ici que les mises à jour peuvent être un travail plus fréquent dans certains cas d'utilisation plutôt que l'insertion ou la suppression réelle - dans de tels cas , le danger de lectures non répétables reste seulement-les lectures fantômes ne sont pas possibles dans ces cas. C'est pourquoi les mises à jour sont traitées différemment de INSERT-DELETE et l'anomalie concernée est également nommée différemment.
Il y a aussi un coût de traitement supplémentaire associé à la gestion des INSERT-DELETES, plutôt que de simplement gérer les mises à jour.
Le niveau D'isolement TRANSACTION_READ_UNCOMMITTED n'empêche rien. Son zéro niveau d'isolation.
Le niveau D'isolement TRANSACTION_READ_COMMITTED en empêche un seul, c'est-à-dire. Lectures incorrectes.
Niveau D'isolement TRANSACTION_REPEATABLE_READ empêche deux anomalies: les lectures sales et les lectures non répétables.
Le niveau D'isolement TRANSACTION_SERIALIZABLE empêche les trois anomalies: lectures Sales, lectures non répétables et lectures fantômes.
Alors pourquoi ne pas simplement définir la transaction sérialisable à tout moment ??
Eh bien , la réponse à la question ci-dessus est : le paramètre sérialisable rend les transactions très lentes , ce que nous ne voulons pas encore.
En fait, la consommation de temps de transaction est dans le taux suivant:
SERIALIZABLE > REPEATABLE_READ > READ_COMMITTED > READ_UNCOMMITTED .
Le paramètre READ_UNCOMMITTED est donc le plus rapide .
En fait, nous devons analyser le usecase et décider d'un niveau d'isolement afin d'optimiser le temps de transaction et d'éviter la plupart des anomalies.
Notez que les bases de données ont par défaut le paramètre REPEATABLE_READ.
Comme expliqué dans Cet article , l'anomalie non reproductible lue ressemble à ceci:

- Alice et Bob commencent deux transactions de base de données.
- Bob lit l'enregistrement post et la valeur de la colonne titre est Transactions.
- Alice modifie le titre d'un enregistrement post donné à la valeur ACID.
- Alice valide sa transaction de base de données.
- Si Bob relit L'enregistrement post, il observera une version différente de cette ligne de table.
Dans cet article sur Fantôme Lire, vous pouvez voir que cette anomalie peut se produire comme suit:
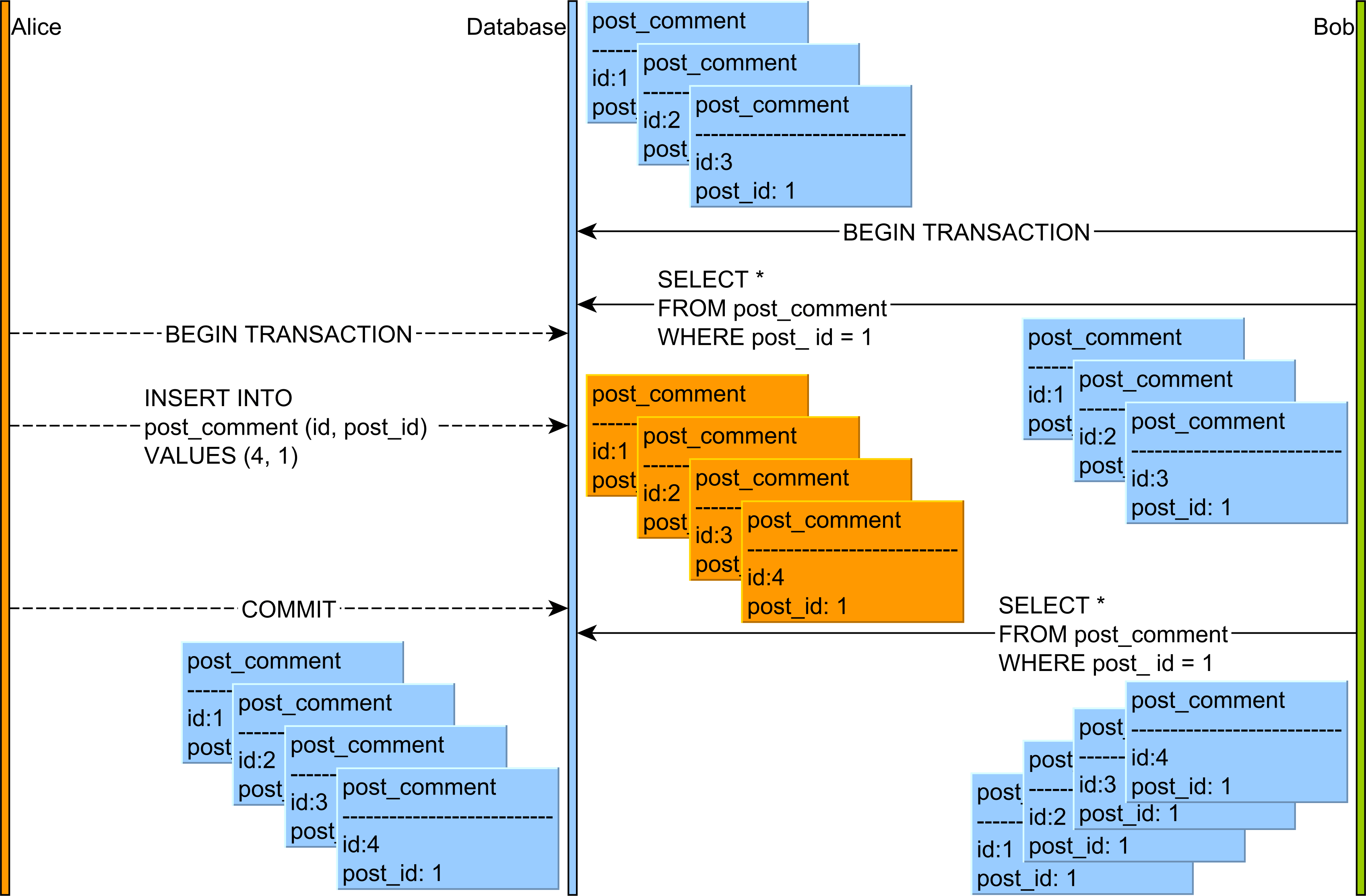
- Alice et Bob commencent deux transactions de base de données.
- Bob lit tous les enregistrements post_comment associés à la ligne post avec la valeur d'identifiant 1.
- Alice ajoute un nouvel enregistrement post_comment qui est associé à la ligne post ayant la valeur d'identifiant 1.
- Alice valide sa transaction de base de données.
- Si Bob re-lit les enregistrements post_comment ayant la valeur de colonne post_id égale à 1, il observera une version différente de ce jeu de résultats.
Ainsi, alors que la lecture non répétable s'applique à une seule ligne, la lecture Fantôme {[4] } correspond à une plage d'enregistrements qui satisfont à un critère de filtrage de requête donné.
Dans un système avec des lectures non répétables, le résultat de la deuxième requête de la Transaction A reflétera la mise à jour dans la Transaction B - il verra le nouveau montant.
Dans un système qui autorise les lectures fantômes, si la Transaction b devait Insérer Une nouvelle ligne avec ID = 1, la Transaction a verra la nouvelle ligne lorsque la deuxième requête sera exécutée; c'est-à-dire que les lectures fantômes sont un cas particulier de lecture non répétable.
La réponse acceptée indique surtout que la soi-disant distinction entre les deux n'est en fait pas significative du tout.
Si "une ligne est récupérée deux fois et que les valeurs dans la ligne diffèrent entre les lectures", alors elles ne sont pas la même ligne (pas le même tuple dans le langage RDB correct) et c'est alors aussi par définition que "la collection de lignes renvoyées par la deuxième requête est différente de la première".
Quant à la question "quel niveau d'isolement devrait être utilisé", plus vos données sont d'une importance vitale pour quelqu'un, quelque part, plus il sera le cas que sérialisable est votre seule option raisonnable.
Je pense qu'il y a une différence entre la lecture non répétable et la lecture fantôme.
Le Non-répétable signifie qu'il y a la transaction de remorquage A & B. Si B peut remarquer la modification de A, alors peut-être se produire sale-lire, donc nous laissons b Remarque La modification de A Après un engagement.
Il y a un nouveau problème: nous laissons B remarquer la modification de A Après un commit, cela signifie A modifier une valeur de ligne que le B tient, parfois B Lira la ligne à nouveau, donc B obtiendra une nouvelle valeur différent avec la première fois que nous obtenons, nous l'appelons Non reproductible, pour traiter le problème, nous laissons le B se souvenir de quelque chose(parce que je ne sais pas encore ce qui sera rappelé) quand B commence.
Pensons à la nouvelle solution, nous pouvons remarquer qu'il y a aussi un nouveau problème, car nous laissons B se souvenir de quelque chose, donc quoi qu'il se soit passé dans A, Le B ne peut pas être affecté, mais si B veut insérer des données dans la table et b vérifier la table pour s'assurer qu'il n'y peut-être se produire à l'erreur. Nous l'appelons Phantom-lire.