Quelle est la différence entre les tableaux contigus et non contigus?
Dans le manuel numpy à propos de la fonction reshape (), il est dit
>>> a = np.zeros((10, 2))
# A transpose make the array non-contiguous
>>> b = a.T
# Taking a view makes it possible to modify the shape without modifying the
# initial object.
>>> c = b.view()
>>> c.shape = (20)
AttributeError: incompatible shape for a non-contiguous array
, Mes questions sont:
- que sont les tableaux continus et non contigus? Est-ce similaire au bloc de mémoire contigu en C comme Qu'est-ce qu'un bloc de mémoire contigu?
- y a-t-il une différence de performance entre ces deux? Quand doit-on utiliser l'un ou l'autre?
- pourquoi transpose rend le tableau non contigu?
- Pourquoi
c.shape = (20)renvoie une erreurincompatible shape for a non-contiguous array?
Merci pour votre réponse!
2 réponses
Un tableau contigu est juste un tableau stocké dans un bloc de mémoire ininterrompu: pour accéder à la valeur suivante dans le tableau, nous passons simplement à l'adresse mémoire suivante.
Considérons le tableau 2D arr = np.arange(12).reshape(3,4). Il ressemble à ceci:
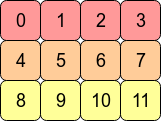
Dans la mémoire de l'ordinateur, les valeurs de arr sont stockés comme ceci:

Cela signifie que arr est un tableau C contigu car les lignes sont stockées sous forme de blocs contigus de la mémoire. L'adresse mémoire suivante contient la valeur de ligne suivante sur cette ligne. Si nous voulons descendre une colonne, il suffit de sauter par-dessus trois blocs (par exemple, sauter de 0 à 4 signifie sauter sur 1,2 et 3).
Transposer le tableau avec arr.T signifie que la contiguïté C est perdue car les entrées de ligne adjacentes ne sont plus dans les adresses mémoire adjacentes. Cependant, arr.T est Fortran contigu puisque les colonnes {[32] } sont dans des blocs contigus de mémoire:
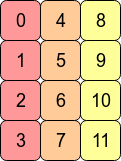
En termes de performances, l'accès aux adresses mémoire les unes à côté des autres est très souvent plus rapide que l'accès aux adresses plus "étalées" (l'extraction d'une valeur à partir de la RAM peut entraîner l'extraction et la mise en cache d'un certain nombre d'adresses voisines pour le CPU.) Cela signifie que les opérations sur des tableaux contigus seront souvent plus rapides.
En raison de la disposition de la mémoire contiguë C, les opérations par ligne sont généralement plus rapides que les opérations en colonne. Par exemple, vous trouverez généralement que
np.sum(arr, axis=1) # sum the rows
Est légèrement plus rapide que:
np.sum(arr, axis=0) # sum the columns
De même, les opérations sur les colonnes seront légèrement plus rapides pour les tableaux contigus Fortran.
Enfin, pourquoi ne pouvons-nous pas aplatir le tableau contigu Fortran en attribuant une nouvelle forme?
>>> arr2 = arr.T
>>> arr2.shape = 12
AttributeError: incompatible shape for a non-contiguous array
Pour que cela soit possible NumPy devrait mettre les lignes de arr.T ensemble comme ceci:

(Réglage L'attribut shape suppose directement l'ordre C - C'est-à-dire NumPy essaie d'effectuer l'opération en ligne.)
, C'est impossible à faire. Pour tout axe, NumPy doit avoir une longueur de foulée constante (le nombre d'octets à déplacer) pour accéder à l'élément suivant du tableau. Aplatir arr.T de cette manière nécessiterait de sauter en avant et en arrière en mémoire pour récupérer des valeurs consécutives du tableau.
Si nous écrivions arr2.reshape(12) à la place, NumPy copierait les valeurs de arr2 dans un nouveau bloc de mémoire (car il ne peut pas retourner une vue sur les données d'origine pour cette forme).
Peut-être que cet exemple avec 12 valeurs de tableau différentes aidera:
In [207]: x=np.arange(12).reshape(3,4).copy()
In [208]: x.flags
Out[208]:
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
...
In [209]: x.T.flags
Out[209]:
C_CONTIGUOUS : False
F_CONTIGUOUS : True
OWNDATA : False
...
Les valeurs C order sont dans l'ordre dans lequel elles ont été générées. Les transposés ne sont pas
In [212]: x.reshape(12,) # same as x.ravel()
Out[212]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
In [213]: x.T.reshape(12,)
Out[213]: array([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11])
Vous pouvez obtenir des vues 1d des deux
In [214]: x1=x.T
In [217]: x.shape=(12,)
La forme de x peut également être modifié.
In [220]: x1.shape=(12,)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-220-cf2b1a308253> in <module>()
----> 1 x1.shape=(12,)
AttributeError: incompatible shape for a non-contiguous array
Mais la forme de la transposition ne peut pas être modifiée. Le data est toujours dans l'ordre 0,1,2,3,4..., qui ne peut pas être accédé comme 0,4,8... dans un tableau 1d.
, Mais une copie de x1 peut être modifié:
In [227]: x2=x1.copy()
In [228]: x2.flags
Out[228]:
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
...
In [229]: x2.shape=(12,)
Regarder strides pourrait aussi aider. Un pas est la distance (en octets) qu'il doit franchir pour arriver à la valeur suivante. Pour un tableau 2d, il y aura 2 valeurs de foulée:
In [233]: x=np.arange(12).reshape(3,4).copy()
In [234]: x.strides
Out[234]: (16, 4)
Pour accéder à la ligne suivante, étape 16 octets, colonne suivante seulement 4.
In [235]: x1.strides
Out[235]: (4, 16)
Transpose juste commute l'ordre des foulées. La ligne suivante est seulement 4 octets-c'est-à-dire le nombre suivant.
In [236]: x.shape=(12,)
In [237]: x.strides
Out[237]: (4,)
Changer la forme change également les foulées - il suffit de passer à travers le tampon 4 octets à la fois.
In [238]: x2=x1.copy()
In [239]: x2.strides
Out[239]: (12, 4)
Même si x2 ressemble à x1, Il a son propre tampon de données, avec les valeurs dans un ordre différent. La colonne suivante est maintenant de 4 octets, alors que la ligne suivante est de 12 (3*4).
In [240]: x2.shape=(12,)
In [241]: x2.strides
Out[241]: (4,)
Et comme avec x, changer la forme à 1d réduit les foulées à (4,).
Pour x1, avec des données dans l'ordre 0,1,2,..., Il n'y a pas de foulée 1d qui donnerait 0,4,8....
__array_interface__ est un autre moyen utile d'afficher le tableau informations:
In [242]: x1.__array_interface__
Out[242]:
{'strides': (4, 16),
'typestr': '<i4',
'shape': (4, 3),
'version': 3,
'data': (163336056, False),
'descr': [('', '<i4')]}
L'adresse du tampon de données x1 sera la même que pour x, avec laquelle elle partage les données. x2 a une adresse tampon différente.
Vous pouvez également expérimenter avec l'ajout d'un order='F' paramètre à la copy et reshape commandes.