Quelle est la différence entre cache et persist?
en termes de RDD persistance, quelles sont les différences entre cache() et persist() en spark ?
4 réponses
avec cache() , vous n'utilisez que le niveau de stockage par défaut MEMORY_ONLY .
Avec persist() , vous pouvez spécifier le niveau de stockage que vous voulez,( rdd-persistance ).
D'après les documents officiels:
- vous pouvez marquer un
RDDà être persisté en utilisant les méthodespersist() oucache() sur elle.- chacun persisté
RDDpeut être stocké en utilisant un autrestorage level- la méthode
cache() est un raccourci pour utiliser le niveau de stockage par défaut, qui estStorageLevel.MEMORY_ONLY(stocker des objets désérialisés en mémoire).
utilisez persist() si vous voulez attribuer un niveau de stockage autre que MEMORY_ONLY au RDD ( quel niveau de stockage choisir )
la mise en Cache ou la persévérance sont des techniques d'optimisation pour (itératif et interactif) Étincelle calculs. Ils permettent d'économiser les résultats partiels provisoires afin qu'ils puissent être réutilisés dans les étapes ultérieures. Ces résultats intermédiaires comme RDD s sont donc conservés en mémoire (par défaut) ou plus de stockage solide comme le disque et/ou répliqué.
RDD s peut être mis en cache en utilisant l'opération cache . Ils peuvent également être maintenus en utilisant l'opération persist .
persist,cacheCes fonctions peuvent être utilisées pour ajuster le niveau de stockage d'un
RDD. Lors de la libération de la mémoire, Spark utilisera l'identifiant du niveau de stockage pour décider quelles cloisons doivent être conservées. Le paramètre moins les variantespersist() etcache() ne sont que des abréviations pourpersist(StorageLevel.MEMORY_ONLY).Avertissement : Une Fois le niveau de stockage a été modifié, il ne peut plus être modifié!
avertissement-Cache judicieusement... voir ( (Pourquoi) devons-nous appeler cache ou persister sur un RDD )
ce n'est pas parce que vous pouvez mettre en mémoire un RDD que vous devez le faire aveuglément. Selon combien de fois le jeu de données est accessible et la quantité de travail que cela comporte, recalcul peut être plus rapide que le prix payé par la pression de mémoire accrue.
il va sans dire que si vous ne lisez un ensemble de données qu'une fois qu'il n'y a aucun intérêt à le cacher, cela rendra votre travail plus lent. La taille des ensembles de données en cache peut être vue à partir de la coquille Spark..
Liste Des Variantes...
def cache(): RDD[T]
def persist(): RDD[T]
def persist(newLevel: StorageLevel): RDD[T]
* Voir exemple ci-dessous: *
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), 2)
c.getStorageLevel
res0: org.apache.spark.storage.StorageLevel = StorageLevel(false, false, false, false, 1)
c.cache
c.getStorageLevel
res2: org.apache.spark.storage.StorageLevel = StorageLevel(false, true, false, true, 1)
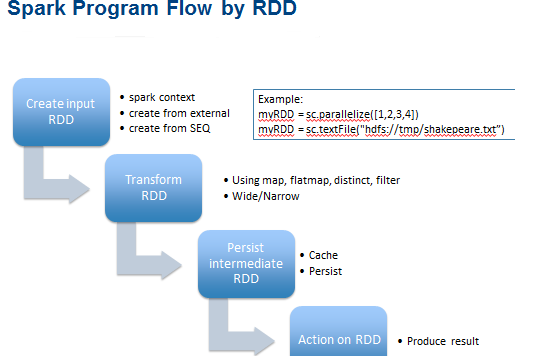
la différence entre les opérations
cacheetpersistest purement syntaxique. cache est synonyme de persist ou persist (MEMORY_ONLY), i.e.cacheest simplementpersistavec le niveau de stockage par défautMEMORY_ONLY
voir plus visuellement ici....
Persistent dans la mémoire et le disque:
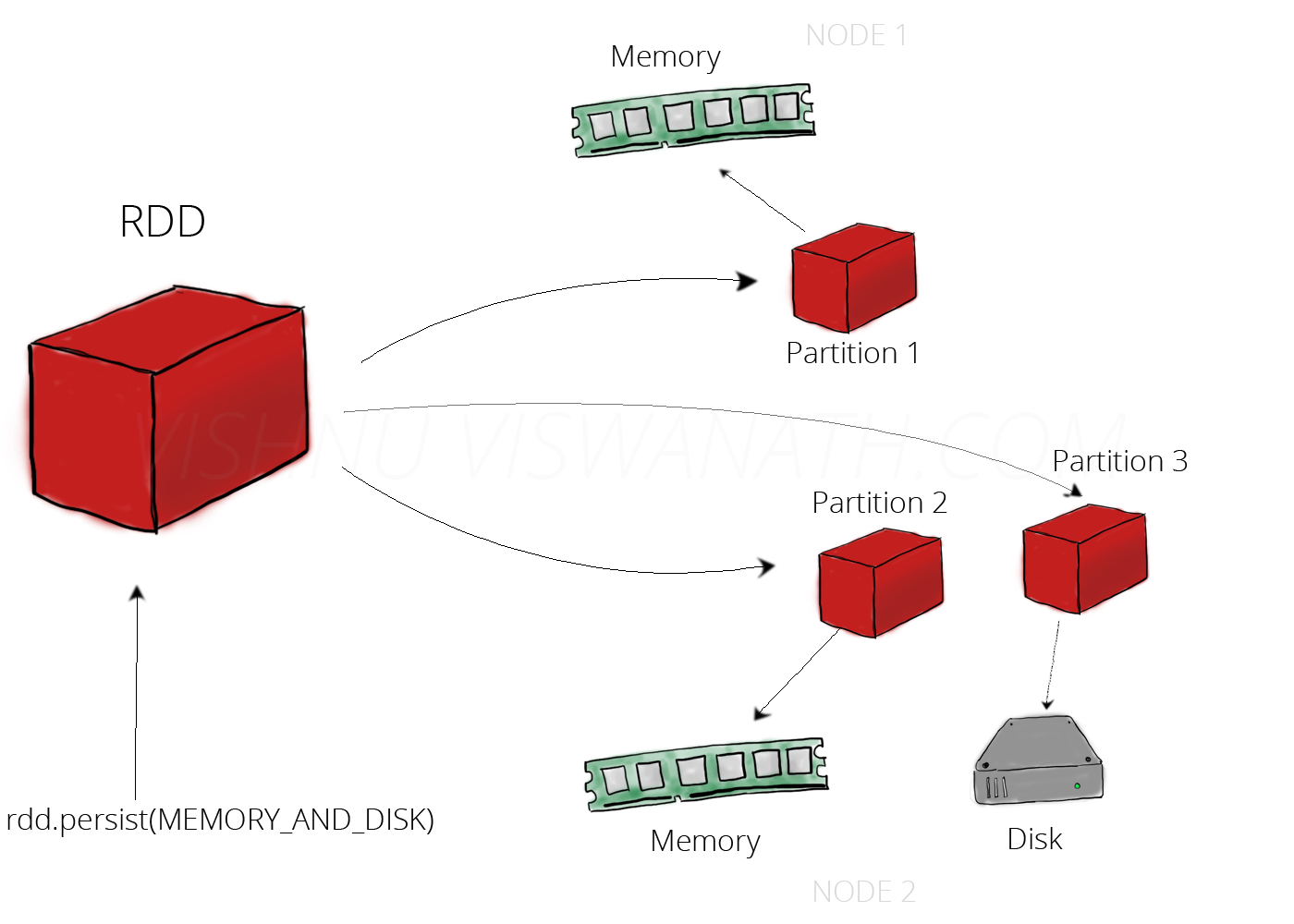
Cache
La mise en cachepeut améliorer les performances de votre application dans une large mesure. Source

Il n'y a pas de différence. De RDD.scala .
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def cache(): this.type = persist()
Spark donne 5 types de niveau de stockage
-
MEMORY_ONLY -
MEMORY_ONLY_SER -
MEMORY_AND_DISK -
MEMORY_AND_DISK_SER -
DISK_ONLY
cache() utilisera MEMORY_ONLY . Si vous voulez utiliser autre chose, utilisez persist(StorageLevel.<*type*>) .
par défaut persist() sera
stocker les données dans le tas JVM comme la désérialisation des objets.