Quelle est l'adresse d'une fonction dans un programme C++?
Comme la fonction est l'ensemble d'instructions stockées dans un bloc contigu de mémoire.
Et l'adresse d'une fonction (point d'entrée) est l'adresse de la première instruction de la fonction. (à ma connaissance)
Et on peut donc dire que l'adresse de la fonction et l'adresse de la première instruction de la fonction sera la même (Dans ce cas, la première instruction est l'initialisation d'une variable.).
Mais le programme ci-dessous contredit ce qui précède ligne.
Code:
#include<iostream>
#include<stdio.h>
#include<string.h>
using namespace std;
char ** fun()
{
static char * z = (char*)"Merry Christmas :)";
return &z;
}
int main()
{
char ** ptr = NULL;
char ** (*fun_ptr)(); //declaration of pointer to the function
fun_ptr = &fun;
ptr = fun();
printf("n %s n Address of function = [%p]", *ptr, fun_ptr);
printf("n Address of first variable created in fun() = [%p]", (void*)ptr);
cout<<endl;
return 0;
}
Un exemple de sortie est:
Merry Christmas :)
Address of function = [0x400816]
Address of first variable created in fun() = [0x600e10]
Donc, voici l'adresse de la fonction et l'adresse de la première variable de la fonction n'est pas la même. Pourquoi donc?
J'ai cherché sur google mais je ne peux pas trouver la réponse exacte requise et étant nouveau dans cette langue, Je ne peux pas attraper certains contenus sur le net.
10 réponses
Donc, voici l'adresse de la fonction et l'adresse de la première variable de la fonction n'est pas la même. Pourquoi donc?
Pourquoi il en serait ainsi? Un pointeur de fonction est un pointeur qui pointe vers la fonction. Il ne pointe pas vers la première variable à l'intérieur de la fonction, de toute façon.
Pour élaborer, une fonction (ou sous-programme) est une collection d'instructions (y compris la définition de variables et différentes instructions/ opérations) qui effectue un travail spécifique, la plupart du temps plusieurs fois, en tant que de besoin. Ce n'est pas seulement un pointeur vers les éléments présents à l'intérieur de la fonction.
Les variables définies à l'intérieur de la fonction ne sont pas stockées dans la même zone de mémoire que celle du code machine exécutable. En fonction du type de stockage, les variables qui sont présentes à l'intérieur de la fonction sont situées dans une autre partie de la mémoire du programme en cours d'exécution.
Lorsqu'un programme est construit (compilé dans un fichier objet), les différentes partie du programme s'organise d'une manière différente.
Habituellement, la fonction (code exécutable), réside dans un segment séparé appelé segment de code, généralement un emplacement de mémoire en lecture seule.
La variabletemps de compilation alloué , Otoh, est stockée dans le segment de données .
Les variables locales de la fonction, sont généralement remplies sur la mémoire de la pile, au fur et à mesure des besoins.
Donc, il n'y a pas de relation telle qu'une fonction pointeur donnera l'adresse de la première variable présente dans la fonction, comme on le voit dans le code source.
À cet égard, pour citer l'article wiki ,
Au lieu de faire référence à des valeurs de données, un pointeur de fonction pointe vers le code exécutable dans la mémoire.
Donc, TL; DR, l'adresse d'une fonction est un emplacement de mémoire à l'intérieur du segment de code (texte) où résident les instructions exécutables.
L'adresse d'une fonction n'est qu'un moyen symbolique de transmettre cette fonction, comme la passer dans un appel ou autre. Potentiellement, la valeur que vous obtenez pour l'adresse d'une fonction n'est même pas un pointeur vers la mémoire.
Les adresses des fonctionsSont bonnes pour exactement deux choses:
Afin De comparer l'égalité
p==q, etDéréférencer et appel
(*p)()
Tout ce que vous essayez de faire est indéfini, pourrait ou pourrait ne pas fonctionner, et est celui du compilateur décision.
Très bien, ça va être amusant. Nous arrivons à passer du concept extrêmement abstrait de ce qu'est un pointeur de fonction en C++ jusqu'au niveau du code d'assemblage, et grâce à certaines des confusions particulières que nous avons, nous arrivons même à discuter des piles!
Commençons par le côté très abstrait, parce que c'est clairement le côté des choses que vous commencez. vous avez une fonction char** fun() avec laquelle vous jouez. Maintenant, à ce niveau d'abstraction, nous pouvons regarder ce les opérations sont autorisées sur les pointeurs de fonction:
- , Nous pouvons tester si deux pointeurs de fonction sont égaux. Deux pointeurs de fonction sont égaux s'ils pointent sur la même fonction.
- Nous pouvons faire des tests d'inégalité sur ces pointeurs, nous permettant de faire le tri de ces pointeurs.
- Nous pouvons déférer un pointeur de fonction, ce qui entraîne un type "Fonction" avec lequel travailler est vraiment déroutant, et je choisirai de l'Ignorer pour l'instant.
- On peut "appeler" un pointeur de fonction, en utilisant la notation que vous avez utilisée:
fun_ptr(). La signification de ceci est identique à appeler n'importe quelle fonction est pointée.
C'est tout ce qu'ils font au niveau abstrait. En dessous de cela, les compilateurs sont libres de l'implémenter comme bon leur semble. Si un compilateur voulait avoir un FunctionPtrType qui est en fait un index dans une grande table de chaque fonction du programme, ils pourraient.
Cependant, ce n'est généralement pas la façon dont il est implémenté. Lors de la compilation C++ vers l'assemblage / machine code, nous avons tendance à tirer parti d'autant d'astuces spécifiques à l'architecture que possible, pour économiser l'exécution. Sur les ordinateurs réels, il y a presque toujours une opération de "saut indirect", qui lit une variable (généralement un registre), et saute pour commencer à exécuter le code stocké à cette adresse mémoire. C'est presque universel que les fonctions sont compilées en blocs contigus d'instructions, donc si jamais vous passez à la première instruction du bloc, cela a pour effet logique d'appeler cela fonction. L'adresse de la première instruction satisfait chacune des comparaisons requises par le concept abstrait de C++d'un pointeur de fonction et Il se trouve être exactement la valeur dont le matériel a besoin pour utiliser un saut indirect pour appeler la fonction! C'est tellement pratique, que pratiquement tous les compilateurs choisissent de l'implémenter de cette façon!
Cependant, lorsque nous commençons à parler de la raison pour laquelle le pointeur que vous pensiez regarder était le même que le pointeur de fonction, nous avoir à entrer dans quelque chose d'un peu plus nuancé: segments.
Les variables statiques sont stockées séparément du code. Il ya quelques raisons pour cela. L'un est que vous voulez que votre code soit aussi serré que possible. Vous ne voulez pas que votre code soit moucheté avec les espaces mémoire pour stocker les variables. Ce serait inefficace. Vous auriez à sauter sur toutes sortes de choses, plutôt que de simplement arriver à labourer à travers elle. Il y a aussi une raison plus moderne: la plupart des ordinateurs vous permettent de marquer de la mémoire comme " exécutable" et certains " inscriptible."Cela aide énormément à faire face à des astuces de hacker vraiment maléfiques. Nous essayons de ne jamais marquer quelque chose à la fois comme exécutable et inscriptible en même temps, au cas où un pirate trouverait intelligemment un moyen de tromper notre programme en écrasant certaines de nos fonctions avec les leurs!
En conséquence, il existe généralement un segment .code (en utilisant cette notation pointillée simplement parce que c'est un moyen populaire de le noter dans de nombreuses architectures). Dans ce segment, vous trouverez tous du code. Les données statiques iront quelque part comme .bss. Vous pouvez donc trouver votre chaîne statique stockée assez loin du code qui l'utilise (généralement au moins 4 Ko, car la plupart des matériels modernes vous permettent de définir des autorisations d'exécution ou d'écriture au niveau de la page: les pages sont 4 Ko dans beaucoup de systèmes modernes)
Maintenant, la dernière pièce... pile. Vous avez mentionné stocker des choses sur la pile d'une manière confuse, ce qui suggère qu'il peut être utile de lui donner un rapide retour. Laisser je fais une fonction récursive rapide, car ils sont plus efficaces pour démontrer ce qui se passe dans la pile.
int fib(int x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return fib(x-1)+fib(x-2);
}
Cette fonction calcule la séquence de Fibonacci en utilisant une manière plutôt inefficace mais claire de le faire.
, Nous avons une fonction, fib. Cela signifie que &fib est toujours un pointeur vers le même endroit, mais nous appelons clairement fib plusieurs fois, donc chacun a besoin de son propre espace non?
Sur la pile, nous avons ce qu'on appelle des "cadres de."Les cadres sont pas {[38] } les fonctions elles-mêmes, mais plutôt ce sont des sections de mémoire que cette invocation particulière de la fonction est autorisée à utiliser. Chaque fois que vous appelez une fonction, comme fib, vous allouez un peu plus d'espace sur la pile pour son cadre (ou, plus pédantiquement, il l'allouera après l'appel).
, Dans notre cas, fib(x) a clairement besoin de stocker le résultat de fib(x-1) lors de l'exécution de fib(x-2). Il ne peut pas stocker cela dans la fonction elle-même, ou même dans le segment .bss parce que nous ne savons pas combien de fois il va être récursif. Au lieu de cela, il alloue de l'espace sur la pile pour stocker sa propre copie du résultat de fib(x-1) tandis que fib(x-2) Fonctionne dans son propre cadre (en utilisant exactement la même fonction et la même adresse de fonction). Lorsque fib(x-2) retourne, fib(x) charge simplement cette ancienne valeur, dont il est certain qu'elle n'a été touchée par personne d'autre, Ajoute les résultats et la renvoie!
Comment fait-il cela? Pratiquement tous les processeurs là-bas a certains prise en charge d'une pile dans le matériel. Sur x86, ceci est connu comme le registre ESP (pointeur de pile étendue). Les programmes acceptent généralement de traiter cela comme un pointeur vers l'endroit suivant de la pile où vous pouvez commencer à stocker des données. Vous êtes invités à déplacer ce pointeur pour vous construire de l'espace pour un cadre et à vous déplacer. Lorsque vous avez terminé l'exécution, vous êtes censé tout déplacer en arrière.
, En fait, sur la plupart des plates-formes, la première instruction dans votre fonction est pas la première instruction dans la version finale compilée. Les compilateurs injectent quelques ops supplémentaires pour gérer ce pointeur de pile pour vous, de sorte que vous n'avez même jamais à vous en soucier. Sur certaines plateformes, comme x86_64, ce comportement est souvent même obligatoire et spécifié dans l'ABI!
, Donc dans tout ce que nous avons:
-
.codesegment - où les instructions de votre fonction sont stockées. Le pointeur de fonction pointera vers la première instruction ici. Ce segment est généralement marqué " exécuter / lecture seule," empêcher votre programme de l'écrire après qu'il a été chargé. -
.bsssegment-où vos données statiques seront stockées, car elles ne peuvent pas faire partie du segment "execute only".codesi elles veulent être des données. - la pile - où vos fonctions peuvent stocker des cadres, qui gardent une trace des données nécessaires juste pour cette instanciation, et rien de plus. (La plupart des plates-formes l'utilisent également pour stocker les informations sur l'endroit où retourner à après une fonction finitions)
- le tas-cela n'apparaît pas dans cette réponse, car votre question n'inclut aucune activité de tas. Cependant, pour être complet, je l'ai laissé ici afin que cela ne vous surprenne pas plus tard.
Dans le texte de votre question, vous dites:
Et on peut donc dire que l'adresse de la fonction et l'adresse de la première instruction de la fonction sera la même (Dans ce cas, la première instruction est l'initialisation d'une variable.).
, Mais dans le code que vous n'obtenez pas l'adresse de la première instruction de la fonction, mais l'adresse d'une variable locale déclarée dans la fonction.
Une fonction est du code, une variable est des données. Ils sont stockés dans différentes zones de mémoire; ils ne résident même pas dans le même bloc de mémoire. En raison des restrictions de sécurité imposées par les systèmes d'exploitation de nos jours, le code est stocké dans des blocs de mémoire marqués en lecture seule.
, autant Que je sache, le langage C ne fournit pas de moyen d'obtenir l'adresse d'une instruction dans la mémoire. Même s'il fournirait un tel mécanisme, le début de la fonction (l'adresse de la fonction en mémoire) n'est pas la même que l'adresse du code machine généré à partir du premier C déclaration.
Avant le code généré à partir de la première instruction C, le compilateur génère un function prolog qui (au moins) enregistre la valeur actuelle du pointeur de pile et fait de la place pour les variables locales de la fonction. Cela signifie plusieurs instructions d'assemblage avant tout code généré à partir de la première instruction de la fonction C.
Comme vous le dites, l'adresse de la fonction peut être (ça dépend du système) l'adresse de la première instruction de la fonction.
C'est la réponse. Instruction ne partagera pas l'adresse avec des variables dans un environnement typique dans lequel le même espace d'adressage est utilisé pour les instructions et les données.
S'ils partagent la même adresse, l'instruction sera détruite en assignant aux variables!
Quelle est exactement l'adresse d'une fonction dans un programme c++?
Comme les autres variables, une adresse d'une fonction est l'espace qui lui est alloué. En d'autres termes, c'est l'emplacement de mémoire où les instructions (Code machine) pour l'opération effectuée par la fonction sont stockées.
Pour comprendre cela, jetez un oeil profond sur la disposition de la mémoire d'un programme.
Les variables et le code/les instructions exécutables d'un programme sont stockés dans différents segments de mémoire (RAM). Les Variables vont à L'un des segments STACK, HEAP, DATA et BSS tandis que le code exécutable va au segment de CODE. Regardez la disposition générale de la mémoire d'un programme
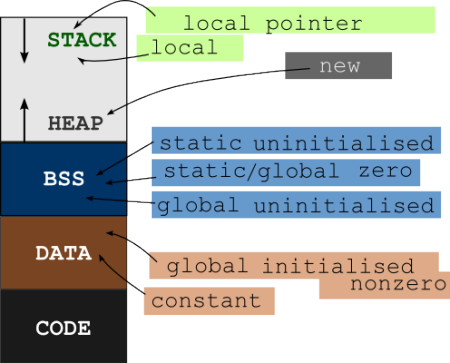
Maintenant, vous pouvez voir qu'il existe différents segments de mémoire pour les variables et les instructions. Ils sont stockés à différents emplacements de mémoire. L'adresse de la fonction est l'adresse située au niveau du segment de CODE.
Donc, vous confondez le terme première déclaration avec première instruction exécutable. Lorsque l'appel de fonction est invoqué, le compteur de programme est mis à jour avec l'adresse de la fonction. Par conséquent, le pointeur de fonction pointe vers la première instruction de la fonction stockée en mémoire.
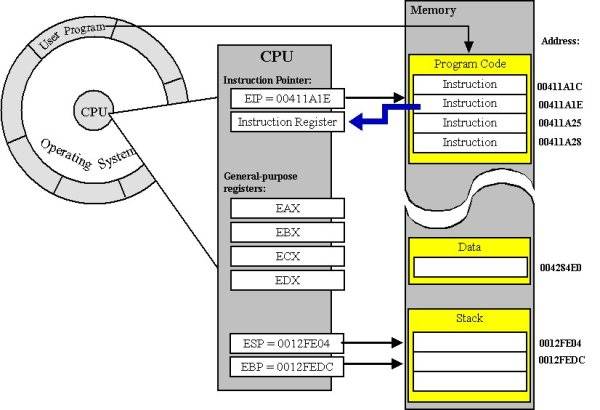
L'adresse d'une fonction normale est l'endroit où les instructions commencent (s'il n'y a pas de vTable impliqué).
Pour les variables Cela dépend:
- Les variables statiques sont stockées à un autre endroit.
- paramètres sont poussés sur la pile ou conservés dans les registres.
- Les variables locales sont également poussées sur la pile ou conservée dans des registres.
Sauf si la fonction est en ligne ou optimisé loin.
Si Je ne me trompe pas, un programme se charge en deux emplacements en mémoire. Le premier est l'exécutable compiles comprenant des fonctions et des variables prédéfinies. Cela commence avec la mémoire la plus basse que l'application occupe. Avec certains systèmes d'exploitation modernes, c'est 0x00000 car le gestionnaire de mémoire les traduira au besoin. La deuxième partie du code est le tas d'applications où la date allouée à l'exécution, telle que les pointeurs, réside, toute mémoire d'exécution aura un emplacement différent dans mémoire
D'autres réponses ici expliquent déjà ce qu'est un pointeur de fonction et ne l'est pas. je vais spécifiquement expliquer pourquoi votre test ne teste pas ce que vous pensiez qu'il a fait.
Et l'adresse d'une fonction (point d'entrée) est l'adresse de la première instruction de la fonction. (à ma connaissance)
Ce n'est pas nécessaire (comme d'autres réponses l'expliquent), mais c'est commun, et c'est généralement une bonne intuition aussi.
(Dans ce cas, la première instruction est l'initialisation d'un variable.).
Ok.
printf("\n Address of first variable created in fun() = [%p]", (void*)ptr);
Ce que vous imprimez ici est l'adresse de la variable. Pas l'adresse de l'instruction qui définit la variable.
Ce ne sont pas les mêmes. En fait, ils ne peuvent pas être les mêmes.
L'adresse de La variable existe dans une série particulière de la fonction. Si la fonction est appelée plusieurs fois pendant l'exécution du programme, la variable peut être à des adresses différentes à chaque fois. Si la fonction appelle elle-même récursivement, ou plus généralement si la fonction appelle une autre fonction qui appelle ... qui appelle la fonction d'origine, alors chaque invocation de la fonction a sa propre variable, avec sa propre adresse. Il en va de même dans un programme multithread si plusieurs threads invoquent cette fonction à un moment donné.
En revanche, l'adresse de la fonction est toujours la même. Il existe indépendamment du fait que la fonction est actuellement appelée: après tout le point d'utiliser un le pointeur de fonction est généralement d'appeler la fonction. Appeler la fonction plusieurs fois ne changera pas son adresse: lorsque vous appelez une fonction, vous n'avez pas à vous soucier de savoir si elle est déjà appelée.
Puisque l'adresse de la fonction et l'adresse de sa première variable ont des propriétés contradictoires, elles ne peuvent pas être identiques.
(Note: il est possible de trouver un système où ce programme pourrait imprimer les mêmes deux numéros, bien que vous puissiez facilement passer par une carrière de programmation sans rencontrer un. Il existe des architectures Harvard , où le code et les données sont stockés dans des mémoires différentes. Sur ces machines, le nombre lorsque vous imprimez un pointeur de fonction est une adresse dans le code de la mémoire, et le numéro lorsque vous imprimer un pointeur est une adresse dans la mémoire de données. Les deux chiffres pourrait être le même, mais ce serait une coïncidence, et sur un autre appel à la même fonction le pointeur de fonction serait la même, mais l'adresse de la variable changement.)
Les Variables déclarées dans une fonction ne sont pas allouées là où vous voyez dans le code automatic variables (variables définies localement dans une fonction) reçoit une place appropriée dans la mémoire de la pile lorsque la fonction est sur le point d'être appelée , ceci est fait pendant la compilation par le compilateur, ainsi l'adresse de la première instruction n'a rien à voir avec les variables Il s'agit des instructions exécutables