Qu'est-ce que RDD in spark
Définition dit:
CA est immuable distribué collection d'objets
Je ne comprends pas très bien ce que cela signifie. Est-ce que c'est comme des données (objets partitionnés) stockées sur un disque dur si c'est le cas, alors comment se fait-il que les RDD puissent avoir des classes définies par l'utilisateur (telles que java, scala ou python)
A partir de ce lien: https://www.safaribooksonline.com/library/view/learning-spark/9781449359034/ch03.html il mentionne:
les utilisateurs créent des RDDs de deux façons: en chargeant un ensemble de données externes, ou en la distribution d'une collection d'objets (par exemple, une liste ou un ensemble) dans leur programme de pilote
je suis vraiment confus comprendre RDD en général et en relation avec spark et hadoop.
est-ce quelqu'un s'il vous plaît aider.
8 réponses
un RDD est, essentiellement, la représentation Spark d'un ensemble de données, réparties sur plusieurs machines, avec des API pour vous permettre d'agir sur elle. Un RDD peut provenir de n'importe quelle source de données, par exemple des fichiers texte, une base de données via JDBC, etc.
La définition formelle est:
les RDDs sont des structures de données parallèles tolérantes aux pannes qui permettent aux utilisateurs persister explicitement résultats intermédiaires dans la mémoire, contrôler leur partitionnement pour optimiser le placement des données, et de les manipuler à l'aide d'un de nombreux opérateurs.
Si vous souhaitez plus de détails sur ce qu'est un RDD est, lire l'un des principaux Étincelle dans les articles académiques, Résilients Distribué les jeux de données: Une tolérance de Pannes d'Abstraction pour la Mémoire de Clusters de Calcul
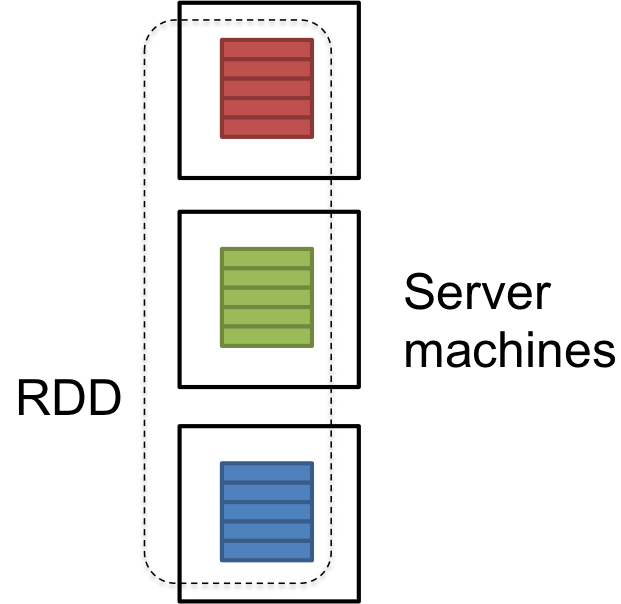
RDD est une référence logique d'un dataset qui est réparti sur de nombreuses machines serveurs dans le cluster. RDDs sont Immuables et sont auto récupéré en cas de panne.
dataset peut être les données chargées à l'extérieur par l'utilisateur. Il peut s'agir d'un fichier json, d'un fichier csv ou d'un fichier texte sans structure de données spécifique.
UPDATE:Ici est un article décrivant RDD internes:
J'espère que cela vous aidera.
officiellement, une DRD est une collection de documents en lecture seule et divisée. Les RDDs ne peuvent être créés que par des opérations déterministes sur (1) des données en stockage stable ou (2) d'autres RDDs.
Les RDDs ont les propriétés suivantes –
immutabilité et partitionnement: RDDs composés d'une collection de documents qui sont partitionnés. La Partition est l'unité de base du parallélisme dans un RDD, et chaque partition est une division logique des données immuable et créé par quelques transformations sur les partitions existantes.L'immutabilité aide à obtenir de la cohérence dans les calculs.
les utilisateurs peuvent définir leurs propres critères pour le partitionnement basé sur des clés sur lesquelles ils veulent rejoindre plusieurs ensembles de données si nécessaire.
opérations à grains grossiers: Les opérations à grains grossiers sont des opérations qui sont appliquées à tous les éléments dans les ensembles de données. Par exemple-une carte, ou un filtre ou une opération groupBy qui sera exécuté sur tous les éléments d'une partition de RDD.
Tolérance De Défaut: Comme les RDDs sont créés au moyen d'un ensemble de transformations , ils enregistrent ces transformations plutôt que les données réelles.Graphique de ces transformations pour produire un RDD est appelé comme graphique de lignée.
Par exemple
firstRDD=sc.textFile("hdfs://...")
secondRDD=firstRDD.filter(someFunction);
thirdRDD = secondRDD.map(someFunction);
result = thirdRDD.count()
dans le cas où nous perdons une partition de RDD , nous pouvons rejouer la transformation sur cette partition dans la lignée de réalisez le même calcul, plutôt que de faire la réplication des données à travers plusieurs noeuds.Cette caractéristique est le plus grand avantage de la RDD, car elle économise beaucoup d'efforts dans la gestion des données et la réplication et permet ainsi des calculs plus rapides.
Paresseux évaluations: Spark calcule les RDD paresseusement la première fois qu'ils sont utilisés dans une action, de sorte qu'il peut pipeline transformations. Ainsi, dans l'exemple ci-dessus, RDD ne sera évalué que lorsque l'action count() est invoquer.
Persistance: Les utilisateurs peuvent indiquer quels RDDs ils réutiliseront et choisir une stratégie de stockage pour eux (par exemple, stockage en mémoire ou sur disque, etc.).)
ces propriétés des RDDs les rendent utiles pour des calculs rapides.
Résilients Distribué Dataset (RDD) est la façon dont Spark représente les données. Les données peuvent provenir de différentes sources :
- Fichier Texte
- fichier CSV
- fichier JSON
- base de données (via le pilote JBDC)
RDD en relation avec Spark
Spark est simplement une implémentation de RDD.
RDD en relation avec Hadoop
le pouvoir de Hadoop réside en le fait qu'il permet aux utilisateurs d'écrire des calculs en parallèle sans avoir à se soucier de la répartition du travail et de la tolérance aux erreurs. Toutefois, Hadoop est inefficace pour les applications qui réutilisent les résultats intermédiaires. Par exemple, des algorithmes itératifs d'apprentissage machine, tels que PageRank, k-means clustering et régression logistique, réutilisent les résultats intermédiaires.
RDD permet de stocker les résultats intermédiaires à l'intérieur de la mémoire vive. Hadoop devrait l'écrire à un système de stockage externe stable, qui génèrent les entrées/sorties du disque et la sérialisation. Avec RDD, Spark est JUSQU'à 20 fois plus rapide que Hadoop pour les applications itératives.
autres implémentations détails sur Spark
transformations à gros grains
les transformations appliquées à un RDD sont grossières. Cela signifie que les opérations sur un RDD sont appliquées à l'ensemble de données, et non à ses éléments individuels. Par conséquent, les opérations comme map, filter, Group, reduce sont autorisées, mais les opérations comme jeu(je) et get(i) ne le sont pas.
l'inverse du grain grossier est à grain fin. Un système de stockage à grain fin serait une base de données.
Tolérance Aux Défauts
RDD sont tolérants aux défauts, qui est une propriété qui permet au système de continuer à fonctionner correctement en cas de défaillance de l'un de ses composants.
la tolérance aux défauts de L'étincelle est fortement liée à sa nature à grain grossier. La seule façon de mettre en œuvre la tolérance de défaut dans un fine-grained système de stockage est de répliquer ses données ou les mises à jour de journal à travers les machines. Cependant, dans un système à grain grossier comme Spark, seules les transformations sont enregistrées. Si une partition d'un RDD est perdue, le RDD dispose de suffisamment d'informations pour la recalculer rapidement.
stockage de Données
le RDD est "distribué" (séparé) dans les partitions. Chaque partition peut être présente dans la mémoire ou sur le disque d'une machine. Lorsque l'Étincelle veut lancer une tâche sur une partition, il l'envoie pour la machine contenant la partition. Ceci est connu comme "localement au courant de la planification".
Sources : De grands documents de recherche sur l'Étincelle : http://spark.apache.org/research.html
inclure le papier suggéré par Ewan Leith.
CA = Résilient Distribué Dataset
résilient (sens du dictionnaire) = (d'une substance ou d'un objet) capable de se rétracter ou de reprendre forme après avoir plié, étiré ou été comprimé
RDD est défini comme (de LearningSpark-OREILLY): la capacité de toujours recalculer un RDD est en fait la raison pour laquelle les RDDs sont appelés "résilient."En cas de défaillance d'une machine contenant des données RDD, Spark utilise cette possibilité pour recalculer les partitions manquantes, utilisateur.
Cela signifie "données" est sûrement disponible à tout moment. De plus, Spark peut fonctionner sans Hadoop et donc les données ne sont pas répliquées. L'une des meilleures caracteristiques de Hadoop2.0 est "Haute Disponibilité" avec l'aide de Passif Veille Namenode. La même chose est réalisée par RDD dans Spark.
un RDD (données) donné peut s'étendre à travers différents noeuds dans le cluster Spark (comme dans le cluster Hadoop basé).
si un noeud s'écrase, Spark peut recalculer le RDD et charger les données dans un autre noeud, et les données sont toujours disponibles. Spark tourne autour du concept de résilients distribués jeu de données (EDR), qui est une tolérance de panne de la collecte des éléments qui peuvent être exploités en parallèle (http://spark.apache.org/docs/latest/programming-guide.html#resilient-distributed-datasets-rdds)
pour comparer la RDD avec la collection scala, voici quelques différences
- Même, mais fonctionne sur un cluster
- Paresseux dans la nature où scala collections sont strictes
- RDD est toujours immuable i.e., vous ne pouvez pas changer l'état des données dans la collection
- les RDD sont auto-récupérés, c.-à-d. tolérant les défauts
RDD