Quelle est la différence entre Superscaling et pipelining?
Eh bien semble une question trop simple à poser, mais j'ai demandé après avoir traversé quelques PPT sur les deux.
Les deux méthodes augmentent le débit d'instruction. Et Superscaling fait presque toujours usage de pipelining ainsi. Superscaling a plus d'une unité d'exécution et le pipelining aussi ou est-ce que je me trompe ici?
5 réponses
La conception superscalaire implique que le processeur puisse émettre plusieurs instructions en une seule horloge, avec des fonctionnalités redondantes pour exécuter une instruction. Nous parlons d'un seul noyau, rappelez-vous -- le traitement multicœur est différent.
Pipelining divise une instruction en étapes, et puisque chaque étape est exécutée dans une partie différente du processeur, plusieurs instructions peuvent être dans différentes "phases" chaque horloge.
Ils sont presque toujours utilisés ensemble. Cette image de Wikipedia montre les deux concepts utilisés, car ces concepts sont mieux expliqués graphiquement:
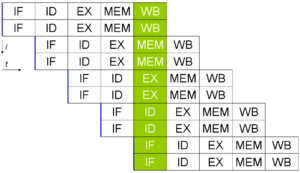
Ici, deux instructions sont exécutées à la fois dans un pipeline en cinq étapes.
Pour le décomposer davantage, compte tenu de votre édition récente:
Dans l'exemple ci-dessus, une instruction passe par 5 étapes à "effectuer". Ce sont des SI (instruction fetch), ID (instruction decode), EX (exécuter), MEM (mise à jour de la mémoire), de la banque mondiale (écriture différée à cache).
Dans une conception de processeur très simple, chaque horloge une étape différente serait terminée donc nous aurions:
- SI
- ID
- EX
- MEM
- BM
Qui ferait une instruction en cinq horloges. Si nous ajoutons ensuite une unité d'exécution redondante et introduisons la conception superscalaire, nous aurions ceci, pour deux instructions A et B:
- SI(A) SI(B)
- ID (A) ID (B)
- EX (A) EX (B)
- MEM(UN) MEM (B)
- WB (A) WB(B)
Deux instructions en cinq horloges -- un gain maximum théorique de 100%.
Pipelining permet aux pièces d'être exécutées simultanément, donc nous finirions avec quelque chose comme (pour dix instructions A à J):
- SI(A) SI(B)
- ID (A) ID (B) IF (C) IF (D)
- EX (A) EX(B) ID (C) ID (D) IF (E) IF (F)
- MEM (A) MEM (B) EX (C) EX (D) ID (E) ID (F) IF (G) IF (H)
- WB(A) WB(B) MEM(C) MEM(D) EX(E) EX (F) ID (G) ID (H) IF (I) IF (J)
- WB (C) WB (D) MEM(E) MEM(F) EX(G) EX(H) ID(I) ID(J)
- WB (E) WB(F) MEM(G) MEM(H) EX(I) EX(J)
- WB (G) WB(H) MEM(I) MEM (J)
- WB (I) WB (J)
En neuf horloges, nous avons exécuté dix instructions -- vous pouvez voir où pipelining déplace vraiment les choses. Et c'est une explication de l'exemple Graphique, pas comment il est réellement implémenté sur le terrain (c'est Black magic).
Les articles de Wikipédia pour Superscalar et Instruction pipeline sont très bonnes.
Il y a longtemps , les processeurs exécutaient une seule instruction machine à la fois. Ce n'est que lorsqu'il a été complètement terminé que le processeur a récupéré l'instruction suivante de la mémoire (ou, plus tard, le cache d'instructions).
Finalement, quelqu'un a remarqué que cela signifiait que la plupart D'un processeur ne faisait rien la plupart du temps, car il y avait plusieurs sous-unités d'exécution (telles que le décodeur d'instructions, l'unité arithmétique entière et L'unité arithmétique FP, etc.) et l'exécution d'une instruction conservée un seul d'entre eux occupé à la fois.
Ainsi, " simple" pipelining {[2] } est né: une fois qu'une instruction a été décodée et a continué vers la sous-unité d'exécution suivante, Pourquoi ne pas déjà récupérer et décoder l'instruction suivante? Si vous aviez 10 "étapes", alors en ayant chaque étape traiter une instruction différente vous pourriez théoriquement augmenter le débit d'instruction de dix fois sans augmenter l'horloge CPU du tout! Bien sûr, cela ne fonctionne parfaitement quand il n'y a pas de sauts conditionnels dans le code (cela a conduit à beaucoup d'efforts supplémentaires pour gérer les sauts conditionnels spécialement).
Plus tard, la loi de Moore continuant à être correcte plus longtemps que prévu, les fabricants de processeurs se sont retrouvés avec toujours plus de transistors à utiliser et ont pensé " pourquoi n'avoir qu'une seule de chaque sous-unité d'exécution?". Ainsi, les processeurs superscalaires avec plusieurs sous-unités d'exécution capables de faire la même chose en parallèle sont nés, et les conceptions de CPU sont devenues beaucoup, beaucoup plus complexe de distribuer des instructions à travers ces unités entièrement parallèles tout en s'assurant que les résultats étaient les mêmes que si les instructions avaient été exécutées séquentiellement.
Une Analogie: Laver Les Vêtements
Imaginez un magasin de nettoyage à sec avec les installations suivantes: un rack pour accrocher des vêtements sales ou propres, une laveuse et une sécheuse (chacune pouvant laver un vêtement à la fois), une table pliante et une planche à repasser.
Le préposé qui fait tout le lavage et le séchage réels est plutôt faible esprit si le propriétaire du magasin, qui prend les commandes de nettoyage à sec, prend un soin particulier à écrire chaque instruction très soigneusement et explicitement.
Un jour typique, ces instructions peuvent être quelque chose du type:
- prenez la chemise du rack
- laver la chemise
- sécher la chemise
- repasser la chemise
- pliez la chemise
- mettez la chemise sur le présentoir
- prenez le pantalon du rack
- laver le pantalon
- sécher le pantalon
- pliez le pantalon
- remettre le pantalon sur le rack
- prenez le manteau de la rack
- laver le manteau
- sécher le manteau
- repasser le manteau
- mettre le manteau sur le présentoir
Le Préposé suit ces instructions au tee, en faisant très attention à ne jamais faire quoi que ce soit hors service. Comme vous pouvez l'imaginer, il faut beaucoup de temps pour obtenir la journée de lessive faite parce qu'il faut beaucoup de temps pour laver, sécher et plier chaque morceau de linge, et il faut le faire un par un.
Cependant, un jour, le préposé se ferme et un nouveau, plus intelligent, préposé est embauché qui remarque que la plupart de l'équipement est inactif à un moment donné au cours de la journée. Pendant que le pantalon séchait, ni la planche à repasser ni la rondelle n'étaient utilisées. Il a donc décidé de faire un meilleur usage de son temps. Ainsi, au lieu de la série d'étapes ci-dessus, il ferait ceci:
- prenez la chemise du rack
- laver la chemise, prendre le pantalon de la grille
- sécher la chemise, laver les pantalon
- fer de la chemise, sécher le pantalon
- pliez la chemise, (prenez le manteau du rack)
- mettez la chemise sur le présentoir, pliez le pantalon, (laver le manteau)
- remettez le pantalon sur le rack, (sécher le manteau)
- (fer le manteau)
- (mettre le manteau sur le présentoir)
C'est le pipelining. séquençage sans rapport activités telles qu'elles utilisent différents composants en même temps. En gardant autant de composants actifs à la fois, vous maximisez l'efficacité et accélérez le temps d'exécution, en réduisant dans ce cas 16 "cycles" à 9, une accélération de plus de 40%.
Maintenant, le petit magasin de nettoyage à sec a commencé à gagner plus d'argent parce qu'ils pouvaient travailler beaucoup plus vite, alors le propriétaire a acheté une laveuse, une sécheuse, une planche à repasser, une station de pliage et a même embauché un autre préposé. Maintenant les choses sont encore plus rapides, au lieu de ce qui précède, vous avez: -
- prenez la chemise du rack, prenez le pantalon du rack
- laver la chemise, laver le pantalon, (prendre le manteau de la baie)
- sécher la chemise, sécher le pantalon, (laver le manteau)
- fer de la chemise, pliez le pantalon, (sec la robe)
- pliez la chemise, remettez le pantalon sur le rack, (repassez le manteau)
- mettez la chemise sur le présentoir, (mettre le manteau sur le présentoir)
C'est le design superscalaire. plusieurs sous-composants capables de faire la même tâche simultanément, mais le processeur décidant comment le faire. Dans ce cas, cela a entraîné une augmentation de la vitesse de près de 50% (en 18 "cycles", la nouvelle architecture pourrait passer par 3 itérations de ce "programme" alors que l'architecture précédente ne pouvait passer que par 2).
Plus ancien les processeurs, tels que le 386 ou le 486, sont de simples processeurs scalaires, ils exécutent une instruction à la fois dans exactement l'ordre dans lequel elle a été reçue. Processeurs grand public modernes depuis le PowerPC / Pentium sont pipelined et superscalar. Un processeur Core2 est capable d'exécuter le même code qui a été compilé pour un 486 tout en profitant du parallélisme au niveau des instructions car il contient sa propre logique interne qui analyse le code machine et détermine comment le réorganiser et l'exécuter (ce qui peut être exécuter en parallèle, ce qui ne peut pas, etc.) C'est l'essence du design superscalaire et pourquoi il est si pratique.
En revanche, un processeur parallèle vectoriel effectue des opérations sur plusieurs éléments de données à la fois (un vecteur). Ainsi, au lieu de simplement ajouter x et y un processeur vectoriel ajouterait, disons, x0,x1,x2 à y0,y1, y2 (résultant en z0, z1, z2). Le problème avec cette conception est qu'elle est étroitement couplée au degré spécifique de parallélisme du processeur. Si vous exécutez du code scalaire sur un vecteur processeur (en supposant que vous pourriez) vous ne verriez aucun avantage de la parallélisation vectorielle car elle doit être explicitement utilisée, de même si vous vouliez profiter d'un processeur vectoriel plus récent avec plus d'unités de traitement parallèles (par exemple capable d'ajouter des vecteurs de 12 nombres au lieu de seulement 3) vous auriez besoin de recompiler votre code. Les conceptions de processeurs vectoriels étaient populaires dans la plus ancienne génération de super ordinateurs car ils étaient faciles à concevoir et il y a de grandes classes de problèmes dans la science et l'ingénierie avec beaucoup de parallélisme naturel.
Les processeurs superscalaires peuvent également avoir la capacité d'effectuer une exécution spéculative. Plutôt que de laisser les unités de traitement inactives et d'attendre qu'un chemin de code se termine avant de brancher un processeur peut faire une meilleure estimation et commencer à exécuter du code après la branche avant que le code précédent ait terminé le traitement. Lors de l'exécution du code précédent rattrape le point de branchement le processeur peut alors comparer la succursale avec la conjecture de branche et continuez si la conjecture était correcte (déjà bien en avance sur l'endroit où elle aurait été en attendant) ou elle peut invalider les résultats de l'exécution spéculative et exécuter le code pour la branche correcte.
Pipelining est ce qu'une entreprise automobile fait dans la fabrication de ses voitures. Ils décomposent le processus de mise en place d'une voiture en étapes et effectuer les différentes étapes à différents points le long d'une chaîne de montage fait par des personnes différentes. Le résultat net est que la voiture est fabriquée exactement à la vitesse de l'étage le plus lent seul.
Dans les processeurs, le processus de pipelining est exactement le même. Une "instruction" est décomposée en différentes étapes d'exécution, généralement quelque chose comme 1. chercher de l'instruction, 2. récupérer les opérandes (registres ou valeurs de mémoire qui sont lus), 2. effectuer le calcul, 3. Ecrire les résultats (dans la mémoire ou les registres). Le plus lent de ceci pourrait être la partie de calcul, auquel cas la vitesse de débit globale des instructions à travers ce pipeline est juste la vitesse de la partie de calcul (comme si les autres parties étaient "libres".)
Super-scalaire dans les microprocesseurs se réfère à la capacité d'exécuter plusieurs instructions à partir d'un seul flux d'exécution à une fois en parallèle. Donc, si une entreprise automobile a couru deux chaînes de montage alors évidemment ils pourraient produire deux fois plus de voitures. Mais si le processus de mise d'un numéro de série sur la voiture était à la dernière étape et devait être fait par une seule personne, alors ils devraient alterner entre les deux pipelines et garantir qu'ils pourraient se faire chacun dans la moitié du temps de l'étape la plus lente afin d'éviter de devenir l'étape la plus lente
Super-scalaire dans les microprocesseurs est similaire mais habituellement a beaucoup plus de restrictions. Ainsi, l'étape de récupération d'instructions produira généralement plus d'une instruction au cours de son étape-c'est ce qui rend le super-scalaire dans les microprocesseurs possible. Il y aurait alors deux étapes de récupération, deux étapes d'exécution et deux étapes d'écriture. Cela se généralise évidemment à plus de deux pipelines.
Tout cela est bien et dandy, mais du point de vue de l'exécution sonore, les deux techniques pourraient entraîner des problèmes si elles sont faites aveuglément. Pour corriger l'exécution d'un programme, il est supposé que les instructions sont exécutées complètement l'un après l'autre dans l'ordre. Si deux instructions séquentielles ont des calculs interdépendants ou utilisent les mêmes registres, il peut y avoir un problème, L'instruction ultérieure doit attendre que l'écriture de l'instruction précédente se termine avant de pouvoir effectuer l'étape d'extraction de l'opérande. Ainsi, vous devez bloquer la deuxième instruction de deux étapes avant qu'elle ne soit exécutée, ce qui va à l'encontre du but de ce qui était gagné par ces techniques en premier lieu.
Il existe de nombreuses techniques utilisées pour réduire le problème de décrochage qui sont un peu compliquées à décrire mais je vais les énumérer: 1. enregistrez l'expédition, (stockez également pour charger l'expédition) 2. renommage de registre, 3. score-embarquement, 4. out-of-exécution de l'ordre. 5. Exécution spéculative avec rollback (et retrait) tous les processeurs modernes utilisent à peu près toutes ces techniques pour implémenter super-scalaire et pipelining. Cependant, ces techniques ont tendance à avoir des rendements décroissants par rapport au nombre de pipelines dans un processeur avant que les stalles ne deviennent inévitables. En pratique, aucun fabricant de CPU ne fabrique plus de 4 pipelines dans un seul noyau.
Multi-core n'a rien à voir avec l'une de ces techniques. Cela consiste essentiellement à éperonner deux micro-processeurs ensemble pour implémenter le multitraitement symétrique sur une seule puce et à ne Partager que les composants qui ont du sens à partager (généralement le cache L3 et les e/s). Cependant une technique qui Intel appelle "hyperthreading" est une méthode d'essayer d'implémenter virtuellement la sémantique de multi-core dans le cadre super-scalaire d'un seul cœur. Ainsi, une seule micro-architecture contient les registres de deux (ou plus) cœurs virtuels et récupère les instructions de deux (ou plus) Flux d'exécution différents, mais en s'exécutant à partir d'un système super-scalaire commun. L'idée est que parce que les registres ne peuvent pas interférer les uns avec les autres, il y aura tendance à être plus parallélisme conduisant à moins de stalles. Donc, plutôt que de simplement exécuter deux flux d'exécution de base virtuels à la moitié de la vitesse, c'est mieux en raison de la réduction globale des stands. Cela semble suggérer qu'Intel pourrait augmenter le nombre de pipelines. Cependant, cette technique a été trouvée pour être quelque peu manquant dans les mises en œuvre pratiques. Comme il fait partie intégrante des techniques super-scalaires, cependant, je l'ai mentionné de toute façon.
Pipelining est l'exécution simultanée de différentes étapes de plusieurs instructions au même cycle. Il est basé sur la division du traitement des instructions en étapes et ayant des unités spécialisées pour chaque étape et des registres pour stocker les résultats intermédiaires.
Superscaling distribue plusieurs instructions (ou microinstructions) à plusieurs unités d'exécution existantes dans le processeur. Il est donc basé sur des unités redondantes dans CPU.
Bien sûr, cette approche peut compléter chaque autre.