Quelle est la différence entre les interfaces CrudRepository et JpaRepository dans Spring Data JPA?
Quelle est la différence entre les interfaces CrudRepository et JpaRepository dans Spring Data JPA?
Quand je vois les exemples sur le web, Je les vois utilisés de manière interchangeable. Quelle est la différence entre eux? Pourquoi voudriez-vous utiliser l'un sur l'autre?
3 réponses
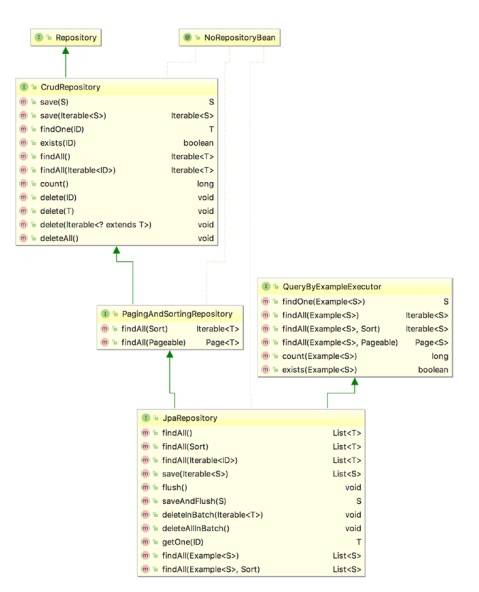
JpaRepository étend PagingAndSortingRepository, qui à son tour s'étend CrudRepository.
Leurs principales fonctions sont:
- CrudRepository fournit principalement des fonctions CRUD.
- PagingAndSortingRepository fournit des méthodes pour effectuer la pagination et le tri des enregistrements.
- JpaRepository fournit certaines méthodes liées à JPA telles que le vidage du contexte de persistance et la suppression d'enregistrements dans un lot.
À Cause de l'héritage mentionné ci-dessus, JpaRepository aurez toutes les fonctions de CrudRepository et PagingAndSortingRepository. Donc, si vous n'avez pas besoin du référentiel avoir les fonctions fournies par JpaRepository et PagingAndSortingRepository , utiliser CrudRepository.
La réponse de Ken est fondamentalement juste, mais j'aimerais intervenir sur le " pourquoi voudriez-vous utiliser l'un sur l'autre?"une partie de votre question.
Notions de base
, L'interface de base que vous choisissez pour votre référentiel a deux objectifs principaux. Tout d'abord, vous autorisez L'infrastructure de référentiel de données Spring à trouver votre interface et à déclencher la création de proxy afin d'injecter des instances de l'interface dans les clients. Le deuxième but est de tirer autant de fonctionnalités que nécessaire dans le interface sans avoir à déclarer des méthodes supplémentaires.
Les interfaces communes
La bibliothèque Spring Data core est livrée avec deux interfaces de base qui exposent un ensemble de fonctionnalités dédié:
-
CrudRepository- Méthodes CRUD -
PagingAndSortingRepository- méthodes de pagination et de tri (extendsCrudRepository)
Interfaces spécifiques au magasin
Les modules de magasin individuels (par exemple pour JPA ou MongoDB) exposent les extensions spécifiques au magasin de ces interfaces de base à autoriser l'accès à des fonctionnalités spécifiques au magasin comme le rinçage ou le traitement par lots dédié qui prennent en compte certaines spécificités du magasin. Un exemple pour ceci est deleteInBatch(…) de JpaRepository qui est différent de delete(…) car il utilise une requête pour supprimer les entités données qui est plus performante mais qui a pour effet secondaire de ne pas déclencher les cascades définies par JPA (comme la spécification le définit).
Nous recommandons généralement Pas d'utiliser ces interfaces de base car elles exposent la persistance sous-jacente technologie aux clients et ainsi resserrer le couplage entre eux et le référentiel. De plus, vous vous éloignez un peu de la définition originale d'un référentiel qui est essentiellement "une collection d'entités". Donc, si vous le pouvez, restez avec PagingAndSortingRepository.
Interfaces de base de référentiel personnalisées
L'inconvénient de dépendre directement de l'une des interfaces de base fournies est double. Les deux peuvent être considérés comme théoriques mais je pense qu'ils sont importants pour être conscients de:
-
selon une interface de référentiel de données Spring, votre interface de référentiel est couplée à la bibliothèque. Je ne pense pas que ce soit un problème particulier car vous utiliserez probablement des abstractions comme
PageouPageabledans votre code de toute façon. Les données de printemps ne sont pas différentes de toute autre bibliothèque à usage général comme commons-lang ou Goyave. Tant qu'il fournit un avantage raisonnable, c'est très bien. -
en étendant par exemple
CrudRepository, vous exposez un ensemble complet de persistance méthode à la fois. C'est probablement bien dans la plupart des circonstances, mais vous pourriez rencontrer des situations où vous souhaitez obtenir un contrôle plus fin sur les méthodes exposées, par exemple pour créer unReadOnlyRepositoryqui n'inclut pas les méthodessave(…)etdelete(…)deCrudRepository.
La solution à ces deux inconvénients est de créer votre propre interface de référentiel de base ou même un ensemble d'entre eux. Dans beaucoup d'applications, nous avons vu quelque chose comme ceci:
interface ApplicationRepository<T> extends PagingAndSortingRepository<T, Long> { }
interface ReadOnlyRepository<T> extends Repository<T, Long> {
// Al finder methods go here
}
Le premier dépôt l'interface est une interface de base à usage général qui ne corrige en fait que le point 1 mais lie également le type D'ID à Long pour plus de cohérence. La deuxième interface a généralement toutes les méthodes find…(…) copiées à partir de CrudRepository et PagingAndSortingRepository mais n'expose pas celles qui manipulent. En savoir plus sur cette approche dans la documentation de référence .
Résumé-tl; dr
L'abstraction du référentiel vous permet de choisir le référentiel de base totalement piloté par vous architectural et fonctionnel besoin. Utilisez ceux fournis hors de la boîte si elles conviennent, créez vos propres interfaces de base de référentiel si nécessaire. Restez à l'écart des interfaces de référentiel spécifiques au magasin, sauf si cela est inévitable.
Résumé:
-
PagingAndSortingRepository étend CrudRepository
-
JpaRepository étend PagingAndSortingRepository
L'interfaceCrudRepository fournit des méthodes pour les opérations CRUD, de sorte qu'elle vous permet de créer, lire, mettre à jour et supprimer des enregistrements sans avoir à définir vos propres méthodes.
Le PagingAndSortingRepository fournit des méthodes supplémentaires pour récupérer entités utilisant la pagination et le tri.
Enfin, le JpaRepository ajoute des fonctionnalités spécifiques à JPA.