Qu'est-ce qu'un index en SQL?
11 réponses
Un index est utilisé pour accélérer la recherche dans la base de données. MySQL ont une bonne documentation sur le sujet (qui est pertinente pour D'autres serveurs SQL ainsi): http://dev.mysql.com/doc/refman/5.0/en/mysql-indexes.html
un index peut être utilisé pour trouver efficacement toutes les lignes correspondant à une colonne dans votre requête et puis marcher à travers seulement ce sous-ensemble de la table pour trouver des Correspondances exactes. Si vous n'avez pas d'index sur une colonne dans le WHERE clause, le serveur SQL doit parcourir la table entière et vérifier chaque ligne pour voir si elle correspond, ce qui peut être une opération lente sur les grandes tables.
l'index peut aussi être un UNIQUE index, ce qui signifie que vous ne pouvez pas avoir des valeurs dupliquées dans cette colonne, ou un PRIMARY KEY qui dans certains moteurs de stockage définit où dans le fichier de base de données la valeur est stockée.
en MySQL vous pouvez utiliser EXPLAIN devant votre énoncé SELECT pour voir si votre requête utilisera un index. C'est un bon début pour la résolution des problèmes de performances. Lire la suite ici:
http://dev.mysql.com/doc/refman/5.0/en/explain.html
Un index cluster est comme le contenu d'un répertoire. Vous pouvez ouvrir le livre à 'Hilditch, David' et trouver toutes les informations pour tous les 'Hilditch est juste à côté de l'autre. Ici les clés de l'index cluster (nom, prénom).
cela rend les index groupés idéal pour extraire des lots de données basées sur des requêtes basées sur la gamme puisque toutes les données sont situées à côté de l'autre.
puisque l'indice clustered est en fait en relation avec la façon dont les données sont stockées, il n'y a qu'un seul d'entre eux possible par table (bien que vous pouvez tricher pour simuler des indices multiples regroupés).
un indice non-groupé est différent en ce que vous pouvez avoir beaucoup d'entre eux et ils pointent ensuite vers les données dans l'indice groupé. Vous pourriez avoir par exemple un index non-clustered à la fin d'un annuaire téléphonique qui est saisi (Ville, Adresse)
imaginez si vous deviez chercher dans l'annuaire pour toutes les personnes qui vivent à "Londres" - avec seulement l'index groupé vous devriez chercher chaque élément dans l'annuaire téléphonique puisque la clé sur l'index groupé est sur (lastname, firstname) et en conséquence les gens qui vivent à Londres sont dispersés au hasard dans l'index.
si vous avez un index non-clustered sur (town) alors ces requêtes peuvent être effectuées beaucoup plus rapidement.
Espère que ça aide!
Une très bonne analogie est de penser à un index de base de données comme un index dans un livre. Si vous avez un livre concernant les pays et que vous cherchez L'Inde, alors pourquoi feuilleter le livre entier – qui est l'équivalent d'un balayage complet de la table dans la terminologie de base de données – quand vous pouvez simplement aller à l'index à la fin du livre, qui vous indiquera les pages exactes où vous pouvez trouver des informations sur L'Inde. De même, comme un index de livres contient un numéro de page, un index de base de données contient un pointeur vers la ligne contenant la valeur que vous recherchez dans votre SQL.
un index est utilisé pour accélérer la performance des requêtes. Il le fait en réduisant le nombre de pages de données de base de données qui doivent être visitées/scannées.
Dans SQL Server, un cluster index détermine l'ordre physique des données dans une table. Il ne peut y avoir qu'un seul indice groupé par table (l'indice groupé est la table). Tous les autres indices sur une table sont appelés non-groupés.
Indices sont tout au sujet de trouver rapidement les données . Index dans une base de données sont analogues aux indices que vous trouverez dans un livre. Si un livre a un indice, et je vous demande de trouver un chapitre dans le livre, vous pouvez rapidement trouver que, avec l'aide de l'index. D'autre part, si le livre n'est pas un index, vous devez passer plus de temps, à la recherche pour le chapitre, en regardant chaque page du début à la fin du livre. De manière similaire, les index dans un base de données, peut aider les requêtes pour trouver des données rapidement. Si vous êtes novice dans les index, les vidéos suivantes peuvent être très utiles. Enfait, j'ai beaucoup appris d'eux.
index Basics
indices groupés et Non groupés
index uniques et Non uniques
avantages et inconvénients des indices
Bien dans l'index général est un B-tree . Il existe deux types d'indices: cluster et le cluster.
Clustered index crée un ordre physique des lignes (il peut être seulement un et dans la plupart des cas, il est aussi une clé primaire - si vous créez la clé primaire sur la table vous créez l'index clustered sur cette table également).
non-clustered index est également un arbre binaire, mais il ne crée pas un physique l'ordre des lignes. Ainsi, les noeuds foliaires de l'index non-clouté contiennent PK (s'il existe) ou row index.
Index sont utilisés pour augmenter la vitesse de recherche. Parce que la complexité est de O(log n). Index est un sujet très vaste et intéressant. Je peux dire que créer des index sur de grandes bases de données est une sorte d'art parfois.
INDEXES - pour trouver des données facilement
UNIQUE INDEX - les valeurs en double ne sont pas autorisées
syntaxe pour INDEX
CREATE INDEX INDEX_NAME ON TABLE_NAME(COLUMN);
syntaxe pour UNIQUE INDEX
CREATE UNIQUE INDEX INDEX_NAME ON TABLE_NAME(COLUMN);
INDEX est une technique d'optimisation des performances qui accélère le processus de récupération des données. Il s'agit d'une structure de données persistante associée à une Table (ou à une vue) afin d'augmenter la performance lors de la récupération des données de cette table (ou de cette vue).
recherche indexée est appliquée plus particulièrement lorsque vos requêtes incluent où filtre. Autrement, I. e, une requête sans où-filtre sélectionne des données entières et le processus. La recherche de table entière sans INDEX est appelé scanner de Table.
vous trouverez des informations exactes pour Sql-Indexes de manière claire et fiable: suivez ces liens:
- pour une compréhension correcte: http://dotnetauthorities.blogspot.in/2013/12/Microsoft-SQL-Server-Training-Online-Learning-Classes-INDEX-Overview-and-Optimizations.html
- Pour la mise en œuvre-la compréhension rationnelle: http://dotnetauthorities.blogspot.in/2013/12/Microsoft-SQL-Server-Training-Online-Learning-Classes-INDEX-Creation-Deletetion-Optimizations.html
si vous utilisez SQL Server, l'une des meilleures ressources est ses propres livres en ligne qui vient avec l'installation! C'est le premier endroit auquel je me réfère pour tous les sujets liés à SQL Server.
si c'est pratique, comment faire?"des questions, alors le débordement des piles serait un meilleur endroit pour poser.
aussi, je ne suis pas revenu depuis un moment mais sqlservercentral.com utilisé pour être l'un des principaux sites liés au serveur SQL là-bas.
Un index est utilisé pour plusieurs raisons différentes. La raison principale est d'accélérer la recherche pour que vous puissiez obtenir des lignes ou les trier plus rapidement. Une autre raison est de définir une clé primaire ou un index unique qui garantira qu'aucune autre colonne n'a les mêmes valeurs.
tout d'abord, nous devons comprendre comment la requête normale (sans indexation) fonctionne. Il parcourt fondamentalement chaque ligne une par une et quand il trouve les données qu'il renvoie. Reportez-vous à l'image suivante. (Cette image a été prise à partir de cette vidéo .)
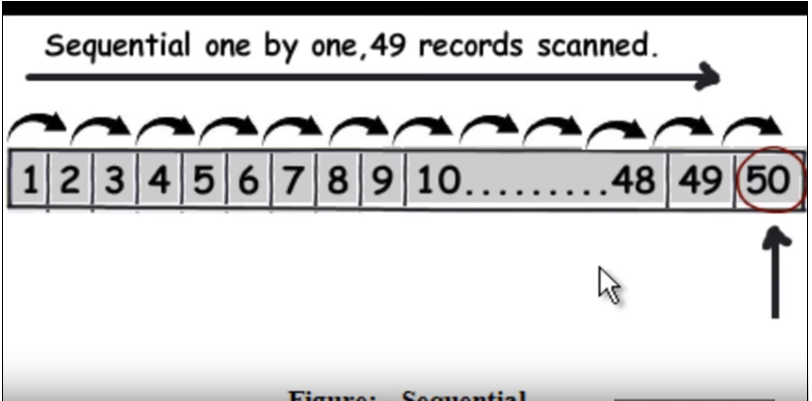 Supposons donc que la requête est de trouver 50, il devra lire 49 enregistrements comme une recherche linéaire.
Supposons donc que la requête est de trouver 50, il devra lire 49 enregistrements comme une recherche linéaire.
reportez-vous à l'image suivante. (Cette image a été tiré de ce vidéo )
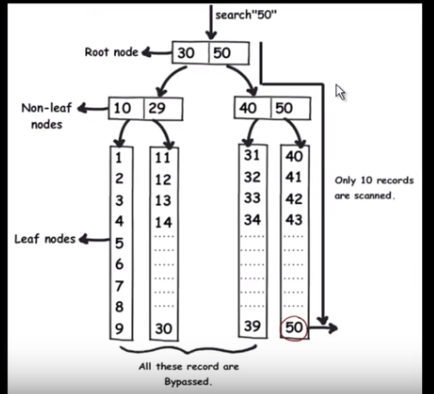
lorsque nous appliquons l'indexation, la requête va rapidement trouver les données sans lire chacune d'elles juste en éliminant la moitié des données dans chaque traversée comme une recherche binaire. Les index mysql sont stockés sous forme d'arbre B où toutes les données sont dans le noeud de feuille.