Quelle est l'explication en anglais de la notation" Big O"?
je préférerais une définition aussi peu formelle que possible et des mathématiques simples.
30 réponses
brève note, cela prête presque certainement à confusion grande notation O (qui est une limite supérieure) avec la notation thêta (qui est une limite à deux côtés). D'après mon expérience, cela est en fait typique des discussions dans des milieux non universitaires. Toutes mes excuses pour la confusion causée.
Big O la complexité peut être visualisée à l'aide de ce graphique:
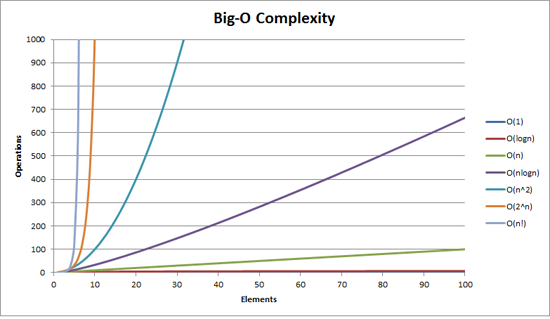
le plus simple définition que je peux donner pour la notation Big-O est celle-ci:
la notation Big-O est une représentation relative de la complexité d'un algorithme.
il y a des mots importants et délibérément choisis dans cette phrase:
- relatif: vous pouvez seulement comparer des pommes à des pommes. Vous ne pouvez pas comparer un algorithme pour faire la multiplication arithmétique à un algorithme qui trie une liste d'entiers. Mais une comparaison de deux algorithmes pour effectuer des opérations arithmétiques (une multiplication, une addition) vous dira quelque chose de significatif;
- représentation: Big-O (dans sa forme la plus simple) réduit la comparaison entre les algorithmes à une seule variable. Cette variable est choisie en fonction d'observations ou d'hypothèses. Par exemple, les algorithmes de tri sont généralement comparés sur la base d'opérations de comparaison (comparer deux noeuds pour déterminer leur ordre relatif). Cela suppose que la comparaison coûte cher. Mais que faire si comparaison n'est pas cher mais la permutation est cher? Il modifie la comparaison; et
- la complexité: si il me faut une seconde pour le tri de 10 000 éléments combien de temps ça va me prendre pour trier un million? Dans ce cas, la complexité est une mesure relative par rapport à autre chose.
Come retournez et relisez ce qui précède quand vous aurez lu le reste.
le meilleur exemple de Big-O est l'arithmétique. Prenez deux numéros (123456 et 789012). Les opérations arithmétiques de base que nous avons appris à l'école étaient:
- ;
- soustraction;
- multiplication; et
- de la division.
chacun de ceux-ci est une opération ou un problème. Une méthode de résolution de ces derniers s'appelle un algorithme .
L'Additionest la plus simple. Vous ligne les nombres (à droite) et ajouter les chiffres dans une colonne écrit le dernier numéro de plus dans le résultat. La partie "dizaines" de ce nombre est reportée à la colonne suivante.
supposons que l'addition de ces numéros est l'opération la plus chère dans ce algorithme. Il va de soi que pour additionner ces deux nombres ensemble nous devons additionner 6 chiffres (et éventuellement porter un 7ème). Si nous additionnons deux nombres de 100 chiffres, nous devons faire 100 additions. Si nous ajoutons deux numéros à 10 000 chiffres, nous devons faire 10 000 ajouts.
vous voyez le motif? Le complexité (étant le nombre d'opérations) est directement proportionnel au nombre de chiffres n dans le plus grand nombre. Nous appelons cela O (n) ou complexité linéaire .
soustraction est similaire (sauf que vous pouvez avoir besoin d'emprunter au lieu de porter).
La Multiplicationest différente. Vous alignez les nombres vers le haut, prenez le premier chiffre dans le nombre inférieur et multipliez-le à tour de rôle contre chaque chiffre dans le nombre supérieur et ainsi de suite à travers chaque chiffre. Pour multiplier nos deux 6 chiffres, nous devons faire 36 multiplication. Nous pouvons avoir besoin de faire autant que 10 ou 11 additions de colonne pour obtenir le résultat final aussi.
si nous avons deux nombres à 100 chiffres, nous devons faire 10 000 multiplications et 200 additions. Pour deux millions de chiffres, il faut faire mille milliards.(10 12 ) multiplications et deux millions d'additions.
comme les échelles de l'algorithme avec n - au carré , c'est O (N 2 ) ou quadratique de la complexité . C'est le bon moment pour introduire un autre concept important:
nous ne nous soucions que de la partie la plus importante de la complexité.
l'astute peut avoir réalisé que nous pourrions exprimer le nombre d'opérations comme: n 2 + 2n. Mais comme vous avez vu de notre exemple avec deux nombres d'un million de chiffres chacun, le deuxième terme (2n) devient insignifiant (représentant 0,0002% du total des opérations à ce stade).
on peut remarquer que nous avons supposé le pire scénario ici. En multipliant les nombres à 6 chiffres si l'un d'eux est à 4 chiffres et l'autre à 6 chiffres, nous n'avons que 24 multiplications. On calcule toujours le pire scénario pour ce "n", I. e lorsqu'il s'agit de numéros à six chiffres. Par conséquent, la notation Big-O est sur le pire scénario d'un algorithme
le Annuaire Téléphonique
le deuxième meilleur exemple que je puisse imaginer est l'annuaire téléphonique, normalement appelé les pages blanches ou similaire, mais il va varier d'un pays à l'autre. Mais je parle de celui qui répertorie les gens par nom de famille et ensuite par initiales ou prénom, éventuellement par adresse et ensuite par numéros de téléphone.
maintenant si vous demandiez à un ordinateur de chercher le numéro de téléphone de "John Smith" dans un annuaire téléphonique qui contient un million de noms, ce qui serait - vous faire? En ignorant le fait que vous pouvez deviner jusqu'où dans les s ont commencé (supposons que vous ne pouvez pas), que feriez-vous?
une implémentation typique pourrait être de s'ouvrir au milieu, prendre le 500,000 th et le comparer à"Smith". Si C'est" Smith, John", on a de la chance. Bien plus probable est que "John Smith" sera avant ou après ce nom. Si c'est après, on divise la dernière moitié de l'annuaire en deux et on répète. Si c'est avant, on divise la première moitié de l'annuaire en deux et on répète. Et ainsi de suite.
cela s'appelle un recherche binaire et est utilisé tous les jours dans la programmation que vous le réalisiez ou non.
donc si vous voulez trouver un nom dans un annuaire d'un million de noms, Vous pouvez en fait trouver n'importe quel nom en faisant cela au plus 20 fois. En comparant les algorithmes de recherche, nous décidons que cette comparaison est notre 'n'.
- pour un annuaire de 3 Noms, il faut 2 comparaisons (au plus).
- pour 7 Il faut au plus 3.
- pour 15 Il faut 4.
- ...
- pour 1 000 000, il faut 20.
c'est stupéfiant, n'est-ce pas?
en gros-o c'est O(log n) ou logarithmique de la complexité . Maintenant, le logarithme en question pourrait être ln (de base e), journal 10 , journal 2 ou une autre base. Il n'a pas d'importance il est encore O(log n) tout comme O(2n 2 ) et O(100n 2 ) sont encore tous les deux O(n 2 ).
il est intéressant à ce point d'expliquer que Big O peut être utilisé pour déterminer trois cas avec un algorithme:
- meilleur cas: dans la recherche par Annuaire téléphonique, le meilleur cas est que nous trouvons le nom dans une comparaison. C'est O(1) ou complexité constante ;
- cas prévu: comme indiqué ci-dessus, ceci est O (log n); et
- Pire des Cas: C'est aussi O(log n).
normalement, on se fiche du meilleur cas. Nous sommes intéressés à l'attendu et le pire cas. Parfois, l'un ou l'autre de ces sera plus important.
Retour à l'annuaire téléphonique.
Que faire si vous avez un numéro de téléphone et que vous voulez trouver un nom? La police a un annuaire téléphonique inversé, mais de telles recherches sont refusées au grand public. Ou sont-ils? Techniquement, vous pouvez chercher un numéro dans un annuaire téléphonique ordinaire. Comment?
vous commencez par le prénom et comparez le nombre. Si c'est une correspondance, Super, sinon, tu passes à la suivante. Vous devez le faire de cette façon parce que l'annuaire téléphonique est unordered (par numéro de téléphone de toute façon).
donc pour trouver un nom donné le numéro de téléphone (recherche inversée):
- Dans Le Meilleur Des Cas: O(1);
- cas prévu: O (n) (pour 500 000); et
- Pire des Cas: O(n) (pour 1 000 000 d').
Le Voyageur De Commerce
C'est un problème connu en informatique et mérite une mention. Dans ce problème, vous avez N villes. Chacune de ces villes est lié à 1 ou plusieurs autres villes par une route d'une certaine distance. Le Le problème du vendeur itinérant est de trouver le tour le plus court qui visite chaque ville.
ça a l'air simple? Réfléchir à nouveau.
si vous avez 3 villes A, B et C avec des routes entre toutes les paires alors vous pouvez aller:
- A → B → C
- A → C → B
- B → C → A
- B → A → C
- C → A → B
- C → B → A
en fait il y a moins que cela parce que certains d'entre eux sont équivalents (A → B → C et C → B → A sont équivalents, par exemple, parce qu'ils utilisent les mêmes routes, juste à l'envers).
en réalité il y a 3 possibilités.
- apportez ceci dans 4 villes et vous avez (iirc) 12 possibilités.
- avec 5 c'est 60.
- 6 devient 360.
C'est une fonction d'une opération mathématique appelée factorielle . En gros:
- 5! = 5 × 4 × 3 × 2 × 1 = 120
- 6! = 6 × 5 × 4 × 3 × 2 × 1 = 720
- 7! = 7 × 6 × 5 × 4 × 3 × 2 × 1 = 5040
- ...
- 25! = 25 × 24 × ... × 2 × 1 = 15,511,210,043,330,985,984,000,000
- ...
- de 50! = 50 × 49 × ... × 2 × 1 = 3.04140932 × 10 64
donc le gros-O du problème du vendeur itinérant est O (N!) ou factorielle ou de la complexité combinatoire .
quand vous arrivez à 200 villes il n'y a pas assez de temps restant dans l'univers de résoudre le problème avec les ordinateurs traditionnels.
quelque chose à quoi penser.
Temps Polynomial
un autre point que je voulais mentionner rapidement est que tout algorithme qui a une complexité de O (n a ) est dit avoir complexité polynomiale ou est soluble dans heure polynomiale .
O(n), O (n 2 ) etc sont tous temps polynomial. Certains problèmes ne peuvent être résolus en temps polynomial. Certaines choses sont utilisés dans le monde à cause de cela. La cryptographie à clé publique en est un excellent exemple. Il est mathématiquement difficile de trouver deux facteurs premiers d'un nombre très grand. Si ce n'était pas le cas, nous ne pourrions pas utiliser les systèmes de clés publiques que nous utilisons.
de toute façon, c'est tout pour mon (j'espère en anglais simple) explication de grande O (révisé).
Il montre comment un algorithme échelles.
O(n 2 ) : connu sous le nom de complexité quadratique
- 1 Article: 1 seconde
- 10 éléments: 100 secondes
- 100 produits: 10000 secondes
notez que le nombre d'articles augmente d'un facteur 10, mais le temps augmente d'un facteur 10 2 . Fondamentalement, n=10 et donc O (N 2 ) nous donne le facteur d'échelle n 2 qui est 10 2 .
O(n) : connu sous le nom de complexité linéaire
- 1 Article: 1 seconde
- 10 éléments: 10 Secondes
- 100 pièces: 100 secondes
This le nombre d'éléments augmente par un facteur de 10, et donc le temps. n=10 et le facteur d'échelle de so O(n) est de 10.
O (1) : connu sous le nom de constante complexité
- 1 Article: 1 seconde
- 10 éléments: 1 seconde
- 100 pièces :1 seconde
le facteur d'échelle de O (1) est toujours 1.
O(log n) : connu sous le nom de complexité logarithmique
- 1 Article: 1 seconde
- 10 éléments: 2 secondes
- 100 pièces: 3 secondes
- 1000 pièces: 4 secondes
- 10000 articles: 5 secondes
Le nombre de calculs est seulement augmenté par un journal de la valeur d'entrée. Donc dans ce cas, en supposant que chaque calcul prend 1 seconde, le log de l'entrée n est le temps requis, donc log n .
c'est l'essentiel. Ils réduisent les maths vers le bas de sorte qu'il pourrait ne pas être exactement n 2 ou ce qu'ils disent qu'il est, mais ce sera le facteur dominant dans la mise à l'échelle.
notation Big-O (également appelé "la croissance asymptotique" notation) est quelles fonctions "ressembler à" quand vous ignorez les facteurs constants et des choses près de l'origine . Nous l'utilisons pour parler de comment les choses échelle .
notions de base
pour "suffisamment" de grandes entrées...
-
f(x) ∈ O(upperbound)signifief"ne pousse pas plus vite que "upperbound -
f(x) ∈ Ɵ(justlikethis)signifief"pousse exactement comme"justlikethis -
f(x) ∈ Ω(lowerbound)signifief"croît pas plus lentement que "lowerbound
big-O de notation ne se soucie pas des facteurs constants: la fonction 9x² est dit "grandir exactement comme" 10x² . Pas plus que big-O asymptotique la notation des soins à propos de non-asymptotique choses " ("les choses près de l'origine" ou "ce qui se passe lorsque la taille du problème est de petite taille"): la fonction 10x² est dit "grandir exactement comme" 10x² - x + 2 .
Pourquoi voulez-vous ignorer les petites parties de l'équation? Parce qu'ils deviennent complètement Nains par les grandes parties de l'équation que vous considérez des échelles de plus en plus grandes; leur contribution devient naine et hors de propos. (Voir l'exemple de la section.)
autrement dit, il s'agit du ratio comme vous allez à l'infini. Si vous divisez le temps réel qu'il prend par la O(...) , vous obtiendrez un facteur constant dans la limite des grandes entrées. intuitivement cela a du sens: fonctions "échelle comme" un autre si vous pouvez multiplier un pour obtenir l'autre. C'est, quand nous disons...
actualAlgorithmTime(N) ∈ O(bound(N))
e.g. "time to mergesort N elements
is O(N log(N))"
... cela signifie que pour des tailles de problème" assez grandes " N (si nous ignorons des choses près de l'origine), il existe une constante (par exemple 2,5, complètement reconstitué) tel que:
actualAlgorithmTime(N) e.g. "mergesort_duration(N) "
────────────────────── < constant ───────────────────── < 2.5
bound(N) N log(N)
il existe de nombreux choix de constante; souvent le" meilleur "choix est connu comme le" facteur constant " de l'algorithme... mais nous l'ignorons souvent comme nous ignorons les Termes non-plus grands (voir la section facteurs constants pour savoir pourquoi ils ne sont pas habituellement question.) Vous pouvez également penser à l'équation ci-dessus comme une limite, en disant " dans le pire des cas, le temps qu'il prend ne sera jamais pire qu'environ N*log(N) , dans un facteur de 2,5 (un facteur constant dont nous ne nous soucions pas beaucoup) ".
en général, O(...) est le plus utile parce que nous nous soucions souvent du comportement du pire. Si f(x) représente quelque chose de "mauvais" comme l'utilisation du processeur ou de la mémoire, alors " f(x) ∈ O(upperbound) " signifie " upperbound est le pire scénario de processeur/mémoire d'utilisation".
les Applications
en tant que construction purement mathématique, la notation big-O ne se limite pas à parler de temps de traitement et de mémoire. Vous pouvez l'utiliser pour discuter de l'asymptotique de n'importe quoi où l'échelle est significative, comme:
- le nombre de, éventuellement, des poignées de main parmi
Nles gens à une partie (Ɵ(N²), spécifiquementN(N-1)/2, mais ce qui importe est qu'il "balance comme "N²) - nombre probable probable de personnes qui ont vu un certain marketing viral en fonction du temps
- comment les échelles de latence de site Web avec le nombre d'unités de traitement dans un CPU ou GPU ou cluster d'ordinateur
- la façon de sortie de chaleur à des échelles sur les CPU meurt comme une fonction de transistor comte, tension, etc.
- combien de temps un algorithme à exécuter, en fonction de la taille de l'image
- combien d'espace un algorithme doit-il Exécuter, en fonction de la taille de l'entrée
exemple
pour l'exemple de poignée de main ci-dessus, tout le monde dans une pièce serre la main de tout le monde. Dans cet exemple, #handshakes ∈ Ɵ(N²) . Pourquoi?
sauvegarder un peu: le nombre de poignées de main est exactement n-choisir-2 ou N*(N-1)/2 (chacun de N personnes serre les mains de N-1 autres personnes, mais ce double compte poignées de main donc diviser par 2):
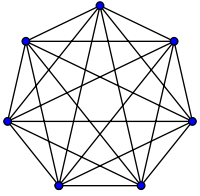
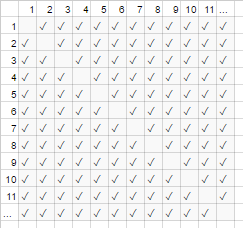
Cependant, pour un très grand nombre de personnes, le terme linéaire N est 0 par rapport au ratio (dans le graphique: la fraction des cases vides sur la diagonale par rapport au total des cases diminue à mesure que le nombre de participants augmente). Par conséquent , le comportement d'échelle est order N² , ou le nombre de poignées de main "croît comme N2".
#handshakes(N)
────────────── ≈ 1/2
N²
c'est comme si les cases vides sur la diagonale de la carte (n*(N-1)/2 coches) n'étaient même pas là (N 2 coches asymptotiquement).
(temporaire digression à partir de "plain English":) Si vous voulais le prouver à vous-même, vous pouvez effectuer de simples de l'algèbre sur le ratio de la scinder en plusieurs termes ( lim signifie "considéré dans la limite d'", juste l'ignorer si vous ne l'avez pas vu, c'est juste une notation pour "et N est vraiment très très grand"):
N²/2 - N/2 (N²)/2 N/2 1/2
lim ────────── = lim ( ────── - ─── ) = lim ─── = 1/2
N→∞ N² N→∞ N² N² N→∞ 1
┕━━━┙
this is 0 in the limit of N→∞:
graph it, or plug in a really large number for N
tl; dr: le nombre de poignées de main 'ressemble à' x2 tellement pour les grandes valeurs, que si nous devions noter le rapport #poignées de main/x2, le fait que nous n'avons pas besoin exactement poignées de main x2 ne serait même pas apparaître dans la décimale pour un grand arbitrairement tandis.
p.ex. pour x=1million, ratio #handshakes / x2: 0.499999...
La Construction De L'Intuition
Cela nous permet de faire des déclarations comme...
"Pour assez grand inputsize=N, quel que soit le facteur constant est, si je double la taille de saisie...
- ... Je double le temps O(N) ("le temps linéaire") algorithme prend."
N → (2N) = 2 ( N )
- ... Je double-carré (quadruple) le temps que prend un algorithme O (N2) ("temps quadratique")." (par exemple, un problème de 100 fois aussi grand prend 1002=10000x plus longtemps... peut-être insoutenable)
N2 → (2N)2 = 4 ( N2 )
- ... Je double-cubed (octuple) le temps O(N3) ("cube") algorithme prend." (par exemple, un problème de 100 fois aussi grand prend 1003=1000000x tant... très peu durable)
cN3 → c(2N)3 = 8 ( cN3 )
- ... J'ajoute une quantité fixe au temps qu'un algorithme O(log(N)) ("temps logarithmique") prend." (pas cher!!!)
C log (N) → C log (2N) = (c log (2))+ ( c log (N) ) = (montant fixe)+ ( C log (N) )
- ... Je ne change pas le temps O(1) ("constante de temps") algorithme prend." (le moins cher!)
c*1 → C*1
- ... I "(basiquement) double" le temps qu'un algorithme O(N log (N)) prend." (assez fréquent)
c'est moins que O(n 1.000001 ), que vous pourriez être prêt à appeler essentiellement linéaire
- ... J'augmente ridiculement le temps que prend un algorithme o (2 N ) ("exponential time")." (vous auriez du double (ou triple, etc.) le temps juste en augmentant le problème en une seule unité)
2 N → 2 2N = (4 N )............mettre une autre manière...... 2 N → 2 N+1 = 2 N 2 1 = 2 2 N
[pour ceux qui sont mathématiquement inclinés, vous pouvez utiliser la souris sur les spoilers pour les notes secondaires mineures]
(avec crédit à https://stackoverflow.com/a/487292/711085 )
(techniquement, le facteur constant pourrait peut-être avoir de l'importance dans certains exemples plus ésotériques, mais j'ai formulé les choses ci-dessus (par exemple dans log(N)) de sorte qu'il n'en a pas)
ce sont le pain et le beurre de commandes de croissance que les programmeurs et les informaticiens spécialisés utilisent comme points de référence. Ils les voient tout le temps. (Donc, alors que vous pourriez techniquement penser " doubler l'entrée rend un algorithme O (√N) 1,414 fois plus lent," il est préférable de penser à lui comme "c'est pire que logarithmique mais mieux que linéaire".)
facteurs constants
Habituellement nous ne nous soucions pas de ce que les facteurs constants spécifiques sont, parce qu'ils n'affecte pas la façon dont la fonction se développe. Par exemple, deux algorithmes peuvent prendre O(N) de temps à compléter, mais l'un peut être deux fois plus lent que l'autre. Nous ne nous soucions généralement pas trop à moins que le facteur soit très grand, car l'optimisation est une affaire délicate ( quand l'optimisation est-elle prématurée? ); aussi le simple fait de choisir un algorithme avec un meilleur big-O améliorera souvent la performance par des ordres de grandeur.
Some les algorithmes supérieurs asymptotiquement (par exemple, une sorte de O(N log(log(N))) sans comparaison) peuvent avoir un facteur constant si important (par exemple, 100000*N log(log(N)) ), ou un effet aérien relativement important comme O(N log(log(N))) avec un + 100*N caché, qu'ils valent rarement la peine d'être utilisés même sur des "données volumineuses".
pourquoi O (N) est parfois le meilleur que vous pouvez faire, i.e. pourquoi nous avons besoin d'infrastructures de données
O(N) les algorithmes sont en quelque sorte le "meilleur" des algorithmes si vous avez besoin de lire toutes vos données. Le très acte de lecture un tas de données est une opération O(N) . Le chargement dans la mémoire est habituellement O(N) (ou plus rapide si vous avez le support matériel, ou pas de temps du tout si vous avez déjà lu les données). Cependant si vous touchez ou même regarder à chaque morceau de données (ou même chaque autre morceau de données), votre algorithme prendra O(N) temps pour effectuer cette recherche. Nomatter combien de temps votre algorithme prend, il sera au moins O(N) parce qu'il passait du temps à regarder toutes les données.
on peut dire la même chose pour le acte même d'écriture . Tous les algorithmes qui impriment N choses prendront N temps, parce que la sortie est au moins que long (par exemple, l'impression de toutes les permutations (façons de réarranger) un ensemble de N cartes à jouer est factoriel: O(N!) ).
cela motive l'utilisation de structures de données : une structure de données ne nécessite la lecture des données qu'une seule fois (habituellement O(N) temps), plus une certaine quantité arbitraire de prétraitement (par exemple O(N) ou O(N log(N)) ou O(N²) ) que nous essayons de garder petit. Par la suite, modifier la structure des données (insertions / suppressions / etc.) et les requêtes sur les données prennent très peu de temps, comme O(1) ou O(log(N)) . Vous procédez alors à faire un grand nombre de requêtes! En général, plus vous êtes prêt à travailler à l'avance, moins vous aurez à le faire plus tard.
par exemple, dites que vous aviez les coordonnées de latitude et de longitude de millions de segments de routes, et que vous vouliez trouver toutes les intersections de rue.
- méthode naïve: si vous aviez les coordonnées d'une intersection de rue, et que vous vouliez examiner les rues voisines, vous auriez à passer par les millions de segmentez chaque fois, et vérifiez chaque fois pour la contiguïté.
- si vous n'avez besoin de faire cela qu'une fois, ce ne serait pas un problème de devoir faire la méthode naïve de
O(N)travailler une seule fois, mais si vous voulez le faire plusieurs fois (dans ce cas,Nfois, une fois pour chaque segment), nous aurions à faireO(N²)travail, ou 10000002=10000000000 opérations. Pas bon (un ordinateur moderne peut effectuer environ un milliard d'opérations par seconde). - si nous utilisez une structure simple appelée une table de hachage (une table de recherche de vitesse instantanée, aussi connu comme hashmap ou Dictionnaire), nous payons un petit coût en prétraitement tout dans
O(N)temps. Par la suite, il ne faut qu'un temps constant en moyenne pour chercher quelque chose par sa clé (dans ce cas, notre clé est la latitude et la longitude coordonnées, arrondies dans une grille; nous recherchons les gridspaces adjacents dont il n'y a que 9, ce qui est une constante). - notre tâche est passée d'un infaisable
O(N²)à un gérableO(N), et tout ce que nous avions à faire était de payer un coût mineur pour faire une table de hachage. - analogie : l'analogie dans ce cas particulier est un puzzle: nous avons créé une structure de données qui exploite une propriété des données. Si nos segments de route sont comme des pièces de puzzle, nous les Groupons en fonction de la couleur et du motif. Nous l'exploitons ensuite pour éviter de faire plus de travail plus tard (comparer des pièces de puzzle de la même couleur pas à toutes les autres pièces du puzzle).
La morale de l'histoire: une structure de données nous permet d'accélérer les opérations. Des structures de données encore plus avancées peuvent vous permettre de combiner, de retarder ou même d'ignorer des opérations de manière incroyablement intelligente. Des problèmes différents auraient des analogies différentes, mais ils impliqueraient tous d'organiser les données d'une manière qui exploite une structure dont nous nous soucions, ou que nous avons artificiellement imposée pour la comptabilité. Nous n' travailler à l'avance (essentiellement planifier et organiser), et maintenant les tâches répétées sont beaucoup plus faciles!
exemple pratique: visualiser les ordres de croissance tout en codant
la notation asymptotique est, à sa base, tout à fait distincte de la programmation. La notation asymptotique est un cadre mathématique pour réfléchir à l'échelle des choses, et peut être utilisé dans de nombreux domaines différents. Qui a dit... ce est comment vous appliquer notation asymptotique au codage.
Les principes de base: Chaque fois que nous interagir avec tous les éléments dans une collection de taille (par exemple un tableau, un ensemble, toutes les clés d'une carte, etc.), ou effectuer une itération d'une boucle, c'est-à-dire un facteur multiplicatif de taille A. Pourquoi dire "un facteur multiplicatif"?-- parce que les boucles et les fonctions (presque par définition) ont un temps d'exécution multiplicatif: le nombre d'itérations, le temps de travail effectué dans la boucle (ou pour les fonctions: le nombre de fois que vous appelez la fonction, le temps de travail effectué dans la fonction). (Ceci est valable si nous ne faisons rien de fantaisiste, comme sauter des boucles ou quitter la boucle trop tôt, ou changer le flux de contrôle dans la fonction basée sur des arguments, ce qui est très courant.) Voici quelques exemples de techniques de visualisation, accompagnées d'un pseudo-code.
(ici, les x s représentent les unités de travail à temps constant, les instructions du processeur, les opcodes d'interpréteur, tout ce qui)
for(i=0; i<A; i++) // A x ...
some O(1) operation // 1
--> A*1 --> O(A) time
visualization:
|<------ A ------->|
1 2 3 4 5 x x ... x
other languages, multiplying orders of growth:
javascript, O(A) time and space
someListOfSizeA.map((x,i) => [x,i])
python, O(rows*cols) time and space
[[r*c for c in range(cols)] for r in range(rows)]
exemple 2:
for every x in listOfSizeA: // A x ...
some O(1) operation // 1
some O(B) operation // B
for every y in listOfSizeC: // C x ...
some O(1) operation // 1
--> O(A*(1 + B + C))
O(A*(B+C)) (1 is dwarfed)
visualization:
|<------ A ------->|
1 x x x x x x ... x
2 x x x x x x ... x ^
3 x x x x x x ... x |
4 x x x x x x ... x |
5 x x x x x x ... x B <-- A*B
x x x x x x x ... x |
................... |
x x x x x x x ... x v
x x x x x x x ... x ^
x x x x x x x ... x |
x x x x x x x ... x |
x x x x x x x ... x C <-- A*C
x x x x x x x ... x |
................... |
x x x x x x x ... x v
exemple 3:
function nSquaredFunction(n) {
total = 0
for i in 1..n: // N x
for j in 1..n: // N x
total += i*k // 1
return total
}
// O(n^2)
function nCubedFunction(a) {
for i in 1..n: // A x
print(nSquaredFunction(a)) // A^2
}
// O(a^3)
si nous faisons quelque chose de légèrement compliqué, vous pourriez encore être en mesure d'imaginer visuellement ce qui se passe:
for x in range(A):
for y in range(1..x):
simpleOperation(x*y)
x x x x x x x x x x |
x x x x x x x x x |
x x x x x x x x |
x x x x x x x |
x x x x x x |
x x x x x |
x x x x |
x x x |
x x |
x___________________|
ici, le plus petit contour reconnaissable que vous pouvez dessiner est ce qui importe; un triangle est une forme bidimensionnelle (0.5 A^2), tout comme un carré est une forme bidimensionnelle (a^2); la constante le facteur de deux reste ici dans le rapport asymptotique entre les deux, cependant nous l'ignorons comme tous les facteurs... (Il y a quelques nuances malheureuses à cette technique que je n'aborde pas ici; elle peut vous induire en erreur.)
bien sûr, cela ne signifie pas que les boucles et les fonctions sont mauvaises; au contraire, elles sont les éléments constitutifs des langages de programmation modernes, et nous les aimons. Cependant, nous pouvons voir que la façon dont nous tissons boucles et fonctions et conditionnels avec nos données (flux de contrôle, etc.) imite le temps et dans l'espace l'utilisation de notre programme! Si l'utilisation du temps et de l'espace devient un problème, c'est-à-dire lorsque nous recourons à l'intelligence, et trouvons un algorithme facile ou une structure de données que nous n'avions pas envisagé, pour réduire l'ordre de croissance d'une manière ou d'une autre. Néanmoins, ces techniques de visualisation (bien qu'elles ne fonctionnent pas toujours) peuvent vous donner une supposition naïve à un temps de course dans le pire des cas.
Voici une autre chose que nous pouvons reconnaître visuellement:
<----------------------------- N ----------------------------->
x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x
x x x x x x x x x x x x x x x x
x x x x x x x x
x x x x
x x
x
Nous pouvons tout simplement réorganiser cette et voir que c'est O(N):
<----------------------------- N ----------------------------->
x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x
x x x x x x x x x x x x x x x x|x x x x x x x x|x x x x|x x|x
ou peut-être vous faites log(N) passes des données, pour O(N*log(N)) temps total:
<----------------------------- N ----------------------------->
^ x x x x x x x x x x x x x x x x|x x x x x x x x x x x x x x x x
| x x x x x x x x|x x x x x x x x|x x x x x x x x|x x x x x x x x
lgN x x x x|x x x x|x x x x|x x x x|x x x x|x x x x|x x x x|x x x x
| x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x
v x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x
sans détour mais digne d'être mentionné à nouveau: si nous effectuons un hachage (par exemple un dictionnaire / recherche de hachage), c'est un facteur de O(1). C'est assez rapide.
[myDictionary.has(x) for x in listOfSizeA]
\----- O(1) ------/
--> A*1 --> O(A)
Si nous faisons quelque chose de très compliqué, comme avec une fonction récursive ou divide-and-conquer algorithme, vous pouvez utiliser le théorème du Maître (fonctionne généralement), ou dans des cas ridicules le théorème D'Akra-Bazzi (fonctionne presque toujours) vous cherchez le temps de fonctionnement de votre algorithme sur Wikipedia.
mais, les programmeurs ne pensent pas comme cela parce que finalement, l'intuition de l'algorithme devient juste seconde nature. Vous allez commencer à coder quelque chose d'inefficace, et immédiatement penser "est-ce que je fais quelque chose grossièrement inefficace? ". Si la réponse est " oui "et que vous prévoyez qu'elle est importante, alors vous pouvez prendre un peu de recul et penser à diverses astuces pour accélérer les choses (la réponse est presque toujours" utilisez un hashtable", rarement" utilisez un arbre", et très rarement quelque chose d'un peu plus compliqué).
amortissement et complexité moyenne des cas
il y a aussi le concept de "amorti" et / ou de" cas moyen " (notez qu'ils sont différents).
Average Case : ce n'est rien de plus qu'utiliser la notation big-O pour la valeur attendue d'une fonction, plutôt que la fonction elle-même. Dans le cas habituel où vous considérez que tous les intrants sont également probables, le cas moyen est juste la moyenne de la durée de fonctionnement. Par exemple avec quicksort, même si le pire des cas est O(N^2) pour certaines entrées vraiment mauvaises, le le cas moyen est l'habituel O(N log(N)) (les entrées vraiment mauvaises sont très petites en nombre, si peu que nous ne les remarquons pas dans le cas moyen).
Worst-Case amorti : certaines structures de données peuvent avoir une complexité de worst-case qui est grande, mais la garantie que si vous faites beaucoup de ces opérations, la quantité moyenne de travail que vous faites sera meilleure que le worst-case. Par exemple, vous pouvez avoir une structure de données qui prend normalement constante O(1) du temps. Cependant, à l'occasion, il y aura un "hoquet" et le O(N) prendra du temps pour une opération aléatoire, parce que peut-être il a besoin de faire un peu de comptabilité ou de collecte des ordures ou quelque chose... mais il vous promet que s'il fait hoquet, il ne hoquetera pas à nouveau pour N Plus d'opérations. Le coût le plus bas est encore O(N) par opération, mais le coût amorti sur de nombreux passages est O(N)/N = O(1) par opération. Parce que les grandes opérations sont suffisamment rare, la quantité massive de travail occasionnel peut être considérée comme se fondre dans le reste du travail comme un facteur constant. Nous disons que le travail est "amorti" sur un nombre suffisamment important d'appels qu'il disparaît à l'infini.
L'analogie pour amorti analyse:
Vous conduisez une voiture. De temps en temps, vous devez passer 10 minutes aller à la station-service et puis passer 1 minute remplir le réservoir avec gaz. Si vous avez fait cela chaque fois que vous êtes allé n'importe où avec votre voiture (passer 10 minutes en voiture à la station-service, passer quelques secondes à remplir un fraction de gallon), il serait très inefficace. Mais si vous remplissez dans le réservoir une fois tous les quelques jours, les 11 minutes passées à conduire à la la station-service est "amortie" sur un nombre suffisant de trajets, que vous pouvez l'ignorer et prétendre que vos voyages étaient peut-être 5% plus longs.
comparaison entre la moyenne et le pire amorti:
- moyenne-hypothèse: nous faisons certaines hypothèses sur nos entrées; c.-à-d. SI nos entrées ont des probabilités différentes, alors nos sorties/durées d'exécution auront des probabilités différentes (que nous prenons la moyenne de). Habituellement, nous supposons que nos entrées sont toutes également probables( probabilité uniforme), mais si les entrées du monde réel ne correspondent pas à nos hypothèses d ' "entrée moyenne", les calculs de la production moyenne/durée d'exécution peuvent être pas de sens. Si vous prévoyez des entrées aléatoires uniformes cependant, il est utile de réfléchir à cela!
- worst-case amortie: si vous utilisez une structure de données Worst-case amortie, la performance est garantie d'être dans le worst-case amorti... finalement (même si les entrées sont choisies par un démon maléfique qui sait tout et qui essaie de vous tromper). Habituellement, nous l'utilisons pour analyser des algorithmes qui peuvent être très "hachés" dans la performance avec de gros hoquets inattendus, mais au fil du temps tout comme d'autres algorithmes. (Cependant, à moins que votre structure de données n'ait des limites supérieures pour beaucoup de travail exceptionnel qu'elle soit prête à remettre à plus tard, un attaquant diabolique pourrait peut-être vous forcer à rattraper la quantité maximale de travail différé tout-à-la-fois.
cependant, si vous êtes raisonnablement inquiet au sujet d'un attaquant, il y a beaucoup d'autres vecteurs d'attaque algorithmiques à s'inquiéter outre l'amortissement et le cas moyen.)
la boîte moyenne et l'amortissement sont des outils incroyablement utiles pour réfléchir et concevoir en gardant l'échelle à l'esprit.
(voir différence entre le cas moyen et l'analyse amortie si ce sous-sujet vous intéresse.)
multidimensionnel big-O
la plupart du temps, les gens ne réaliser qu'il y a plus d'une variable au travail. Par exemple, dans un algorithme de recherche de chaîne de caractères , votre algorithme peut prendre du temps O([length of text] + [length of query]) , c'est-à-dire qu'il est linéaire dans deux variables comme O(N+M) . D'autres algorithmes plus naïfs peuvent être O([length of text]*[length of query]) ou O(N*M) . Ignorer plusieurs variables est l'une des erreurs les plus courantes que je vois dans l'analyse d'algorithme, et peut vous handicaper lors de la conception d'un algorithme.
L'ensemble histoire
gardez à l'esprit que big-O n'est pas toute l'histoire. Vous pouvez accélérer drastiquement certains algorithmes en utilisant la mise en cache, en les rendant cache-oublieux, en évitant les goulots d'étranglement en travaillant avec RAM au lieu de disque, en utilisant la parallélisation, ou en faisant du travail à l'avance -- ces techniques sont souvent indépendant de l'ordre de croissance "big-O" notation, bien que vous verrez souvent le nombre de cœurs dans le big-O notation de parallèle algorithme.
gardez également à l'esprit qu'en raison des contraintes cachées de votre programme, vous pourriez ne pas vraiment vous soucier du comportement asymptotique. Vous pouvez travailler avec un délimitée nombre de valeurs, par exemple:
- si vous triez quelque chose comme 5 éléments, vous ne voulez pas utiliser le quicksort rapide
O(N log(N)); vous voulez utiliser le tri d'insertion, qui se trouve à bien fonctionner sur les petites entrées. Ces situations souvent dans les algorithmes de diviser pour mieux régner, où vous divisez le problème en sous-problèmes de plus en plus petits, tels que le tri récursif, les transformées de Fourier rapides, ou la multiplication de matrice. - si certaines valeurs sont effectivement limitées en raison d'un fait caché (par exemple, le nom humain moyen est faiblement limité à peut-être 40 Lettres, et l'âge humain est faiblement limité à environ 150). Vous pouvez également imposer des limites à vos entrées pour rendre effectivement les Termes constants.
dans la pratique, même parmi les algorithmes qui ont la même performance asymptotique ou similaire, leur mérite relatif peut en fait être motivé par d'autres choses, telles que: d'autres facteurs de performance (quicksort et mergesort sont à la fois O(N log(N)) , mais quicksort profite des caches CPU); des considérations de non-performance, comme la facilité de mise en œuvre; si une bibliothèque est disponible, et comment la réputation et la maintenance de la Bibliothèque est.
seront également plus lents sur un ordinateur de 500MHz vs 2GHz. Nous ne considérons pas vraiment cela comme faisant partie des limites des ressources, parce que nous pensons à l'échelle en termes de ressources machine (par exemple par cycle d'Horloge), pas par seconde réelle. Cependant, il existe des choses similaires qui peuvent "secrètement" affecter les performances, comme si vous êtes sous émulation, ou si le code du compilateur est optimisé ou non. Ils peuvent rendre certaines opérations de base plus longues (même par rapport à l'autre), ou même accélérer ou ralentir certains opérations asymptotiquement (même par rapport à l'autre). L'effet peut être faible ou important selon la mise en œuvre et/ou l'environnement. Est-ce que vous changez de langue ou de machine pour faire ce petit travail supplémentaire? Cela dépend d'une centaine d'autres raisons (nécessité, compétences, collaborateurs, productivité du programmeur, la valeur monétaire de votre temps, familiarité, solutions de rechange, pourquoi pas montage ou GPU, etc...), qui peuvent être plus importants que les performances.
Les questions ci-dessus, comme le langage de programmation, ne sont presque jamais considérés comme faisant partie du facteur constant (ni devraient-ils l'être); pourtant, il faut en être conscient, parce que parfois (bien que rarement) ils peuvent affecter les choses. Par exemple, dans cpython, l'implémentation de la file d'attente native est asymptotiquement non optimale ( O(log(N)) plutôt que O(1) pour votre choix d'insertion ou de find-min); utilisez-vous une autre implémentation? Probablement pas, puisque la mise en œuvre de C est probablement plus rapide, et il y a probablement d'autres problèmes similaires ailleurs. Il y a des compromis; parfois ils sont importants et parfois ils ne le sont pas.
( modifier : l'explication "en anglais simple" se termine ici.)
Addenda Math
par souci d'exhaustivité, la définition précise de la notation big-O est la suivante: f(x) ∈ O(g(x)) signifie que " f est asymptotiquement limite supérieure par const*g": en ignorant tout en dessous d'une certaine valeur finie de x, il existe une constante telle que |f(x)| ≤ const * |g(x)| . (Les autres symboles sont les suivants: tout comme O signifie ≤, Ω signifie ≥. Il existe des variantes en bas de page: o signifie <, Et ω signifie >.) f(x) ∈ Ɵ(g(x)) signifie à la fois f(x) ∈ O(g(x)) et f(x) ∈ Ω(g(x)) (limites supérieure et inférieure de g): il existe certaines constantes telles que f se situera toujours dans la "bande" entre const1*g(x) et const2*g(x) . C'est la déclaration asymptotique la plus forte que vous pouvez faire et à peu près équivalent à == . (Désolé, j'ai choisi de retarder la mention des symboles de valeur absolue jusqu'à maintenant, pour des raisons de clarté; surtout parce que je n'ai jamais vu des valeurs négatives apparaître dans un contexte informatique.)
les Gens utilisent souvent = O(...) , qui est peut-être le plus correct "comp-sci" de notation, et tout à fait légitimes à utiliser... mais il faut savoir que = n'est pas utilisé comme égalité; c'est une notation composée qui doit être lue comme un idiome. On m'a appris à utiliser le plus rigoureux ∈ O(...) . ∈ signifie "est un élément de". O(N²) est en fait une classe d'équivalence , c'est-à-dire un ensemble de choses que nous considérons comme identiques. Dans ce cas particulier, O(N²) contient des éléments comme { 2 N² , 3 N² , 1/2 N² , 2 N² + log(N) , - N² + N^1.9 ,...} et est infiniment grand, mais c'est toujours un jeu. La notation = est peut-être la plus courante, et elle est même utilisée dans des articles par des informaticiens de renommée mondiale. De plus, il arrive souvent que dans un contexte occasionnel, les gens disent O(...) alors qu'ils signifient Ɵ(...) ; c'est techniquement vrai puisque l'ensemble des choses Ɵ(exactlyThis) est un sous-ensemble de O(noGreaterThanThis) ... et c'est plus facile à taper. ;- )
EDIT: remarque, ce n'est presque certainement source de confusion Big O la notation (qui est une limite supérieure) avec Theta notation (qui est à la fois supérieure et inférieure). D'après mon expérience, cela est en fait typique des discussions dans des milieux non universitaires. Toutes mes excuses pour la confusion causée.
En une phrase: Comme la taille de votre travail, combien beaucoup plus de temps faut-il pour le faire?
évidemment que c'est seulement en utilisant la taille" les entrées et "temps" que la sortie - la même idée s'applique si vous voulez parler de l'utilisation de la mémoire etc.
voici un exemple où nous avons N T-shirts que nous voulons sécher. Nous allons supposer il est incroyablement rapide de les obtenir dans la position de séchage (c.-à-d. l'interaction humaine est négligeable). Ce n'est pas le cas dans la vraie vie, bien sûr...
-
utilisation d'une ligne de lavage à l'extérieur: cour arrière infiniment grande, le lavage sèche en O (1) Temps. Quelle que soit la quantité que vous en avez, il aura le même soleil et l'air frais, de sorte que la taille n'affecte pas le temps de séchage.
-
utilisation d'un sèche-linge: vous mettez 10 chemises dans chaque charge, puis ils sont faits une heure plus tard. (Ignorez les chiffres réels ici - ils ne sont pas pertinents.) Donc le séchage de 50 chemises prend environ 5 fois aussi longtemps que le séchage de 10 chemises.
-
mettre tout dans un placard aéré: si nous mettons tout dans une grande pile et laissons simplement la chaleur générale le faire, il faudra beaucoup de temps pour que les chemises du milieu deviennent sèches. Je ne voudrais pas deviner le détail, mais je pense que c'est au moins O(N^2) - comme vous augmentez la charge de lavage, le temps de séchage augmente plus rapidement.
un aspect important de la notation" big O "est qu'elle ne dit pas l'algorithme sera plus rapide pour une taille donnée. Prenez un hashtable (clé de chaîne, valeur entière) vs Un tableau de paires (chaîne, entier). Est-ce plus rapide de trouver une clé dans le hashtable ou un élément dans le tableau, basé sur une chaîne? (c'est à dire pour le tableau, "trouver le premier élément sur lequel la partie de chaîne correspond à la clé donnée.") Les Hashtables sont généralement amortisés (~="en moyenne") O (1) - Une fois qu'ils sont installés, il devrait prendre à peu près le même temps pour trouver une entrée dans une table de 100 entrées comme dans une table de 1.000.000 entrée. Trouver un élément dans un tableau (basé sur le contenu plutôt que sur l'index) est linéaire, i.e. O(N) en moyenne, vous allez avoir à regarder la moitié des entrées.
est-ce que cela rend un hashtable plus rapide qu'un tableau de recherche? Pas nécessairement. Si vous avez une très petite collection d'entrées, un tableau peut être plus rapide - vous pouvez être en mesure de vérifier toutes les chaînes dans le temps qu'il faut pour simplement calculer le hashcode de celui que vous regardez. Comme l'ensemble de données grandit, cependant, la table de hachage finalement battre le tableau.
Big O décrit une limite supérieure sur le comportement de croissance d'une fonction, par exemple la durée d'exécution d'un programme, lorsque les entrées deviennent importantes.
exemples:
-
O(n): Si je double la taille d'entrée, l'exécution double
-
O (N 2 ): si la taille d'entrée double les quadruples d'exécution
-
O (log n): Si la la taille d'entrée double les augmentations de durée d'exécution d'un
"
-
O (2 n ): si la taille d'entrée augmente d'un, l'exécution double
la taille d'entrée est habituellement l'espace en bits nécessaire pour représenter l'entrée.
notation Big O est le plus souvent utilisé par les programmeurs comme une mesure approximative de combien de temps un calcul (algorithme) prendra pour compléter exprimé en fonction de la taille de l'ensemble d'entrée.
Big O est utile pour comparer la façon dont deux algorithmes vont augmenter le nombre d'entrées au fur et à mesure que le nombre d'entrées augmente.
plus précisément notation Big O est utilisé pour exprimer le comportement asymptotique d'une fonction. Cela signifie que la façon dont le la fonction se comporte comme il approche de l'infini.
Dans de nombreux cas, le "O" d'un algorithme de tomber dans l'un des cas suivants:
- O(1) - le temps à remplir est le même quelle que soit la taille de l'ensemble d'entrées. Un exemple est l'accès à un élément de tableau par index.
- O(Log n) - le temps pour compléter les augmentations à peu près en ligne avec le log2(n). Par exemple 1024 articles prend environ deux fois plus longtemps que 32 éléments, parce que Log2(1024) = 10 et Log2(32) = 5. Un exemple est de trouver un article dans un arbre de recherche binaire (BST).
- O(N) - temps nécessaire pour compléter cette échelle linéairement avec la taille de l'ensemble d'entrée. En d'autres termes, si vous doublez le nombre d'éléments de l'ensemble d'entrée, l'algorithme prend environ deux fois plus de temps. Un exemple est le comptage du nombre d'éléments dans une liste chaînée.
- O(N Log n) - le temps pour compléter les augmentations par le nombre d'articles multiplié par le résultat du Log2(N). Un exemple de ceci est tas de tri et tri rapide .
- O (N^2) - le temps à remplir est à peu près égal au carré du nombre d'articles. Un exemple de cela est bulle de sorte .
- O (N!) - Pour la factorielle du jeu de données d'entrée. Un exemple de cela est le problème de vendeur itinérant brute-solution de force .
Big O ignore les facteurs qui ne contribuent pas de manière significative à la courbe de croissance d'une fonction lorsque la taille de l'input augmente vers l'infini. Cela signifie que les constantes qui sont ajoutés ou multiplié par la fonction sont tout simplement ignorés.
Big O est juste un moyen de" S'exprimer "d'une manière commune," combien de temps / d'espace faut-il pour exécuter mon code?".
vous pouvez souvent voir O(n), O(N 2 ), O(nlogn) et ainsi de suite, tous ces sont juste des façons de montrer; comment un algorithme change-t-il?
O (n) signifie Grand O est n, et maintenant vous pourriez penser, "ce qui est n!?"Bien" n " est la quantité d'éléments. Imagerie vous voulez rechercher un élément dans un tableau. Vous avez à regarder sur chaque élément et comme "Êtes-vous le bon élément/article?"dans le pire des cas, l'élément est au dernier indice, ce qui signifie qu'il a fallu autant de temps qu'il y a des éléments dans la liste, afin d'être générique, nous disons "oh, hey, n est une juste quantité donnée de valeurs!".
alors vous pourriez comprendre ce que "n 2 " signifie, Mais pour être encore plus précis, jouer avec la pensée que vous avez un simple, le plus simple des algorithmes de tri; bubblesort. Cet algorithme doit regardez toute la liste, pour chaque article.
Ma liste
- 1
- 6
- 3
Le flux de ici serait:
- comparez 1 et 6, lequel est le plus grand? Ok 6 est dans la bonne position, on avance!
- comparez 6 et 3, oh, 3 c'est moins! Passons, Ok la liste changé, nous devons commencer à partir de la début maintenant!
C'est O n 2 parce que, vous devez examiner tous les éléments de la liste, il y a "n" éléments. Pour chaque article, vous regardez tous les articles une fois de plus, pour comparer, c'est aussi "n", Donc pour chaque article, vous regardez" n "fois signification n*n = n 2
j'espère que c'est aussi simple que vous le souhaitez.
mais rappelez-vous, Big O est juste un moyen d'expérimenter vous - même dans la manière de temps et de l'espace.
Big O décrit la nature fondamentale de l'échelle d'un algorithme.
il y a beaucoup d'informations que Big O ne vous dit pas sur un algorithme donné. Il coupe à l'os et ne donne que des informations sur la nature de mise à l'échelle d'un algorithme, en particulier comment l'utilisation de la ressource (penser le temps ou la mémoire) d'un algorithme se balance en réponse à la "taille d'entrée".
considérer la différence entre une machine à vapeur et un fusée. Ce ne sont pas simplement des variétés différentes de la même chose (comme, disons, un moteur Prius contre un moteur Lamborghini), mais ce sont des systèmes de propulsion radicalement différents, à leur base. Un moteur à vapeur peut être plus rapide qu'une fusée jouet, mais aucun moteur à pistons à vapeur ne pourra atteindre les vitesses d'un lanceur orbital. Cela est dû au fait que ces systèmes ont des caractéristiques d'échelle différentes en ce qui concerne la relation entre le carburant requis ("utilisation des ressources") pour atteindre une vitesse donnée. ("taille").
Pourquoi est-ce si important? Parce que le logiciel traite des problèmes qui peuvent différer en taille par des facteurs allant jusqu'à mille milliards. Considère que, pour un moment. Le rapport entre la vitesse nécessaire pour voyager vers la Lune et la vitesse de marche humaine est moins de 10.000:1, et qui est absolument minuscule par rapport à la gamme de tailles d'entrée que le logiciel peut faire face. Et parce que le logiciel peut faire face à une gamme astronomique dans les tailles d'entrée il y a le potentiel pour la grande o complexité d'un algorithme, c'est la nature fondamentale de l'échelle, pour surpasser tous les détails de mise en œuvre.
prenons l'exemple du tri canonique. Le "Bubble-sort" est O(N 2 ) tandis que le "merge-sort" est O (N log n). Supposons que vous ayez deux applications de tri, l'application a qui utilise le tri en bulles et l'application b qui utilise le tri en fusion, et supposons que pour des tailles d'entrée d'environ 30 éléments, l'application a est 1000 fois plus rapide que l'application B au tri. Si vous n'avez jamais à trier plus de 30 éléments, alors il est évident que vous devez préférer Une application, comme il est beaucoup plus rapide à ces tailles. Cependant, si vous trouvez que vous pourriez avoir à trier dix millions d'articles, alors ce que vous attendez est que l'application b finit par être des milliers de fois plus rapide que l'application A dans ce cas, entièrement en raison de la façon dont chaque échelle de l'algorithme.
Voici Le Bestiaire anglais simple que j'ai tendance à utiliser pour expliquer les variétés communes de Big-O
dans tous les cas, préfèrent les algorithmes plus élevés de la liste à ceux plus bas de la liste. Toutefois, le coût du passage à une classe de complexité plus coûteuse varie considérablement.
O (1):
Pas de croissance. Peu importe la taille du problème, vous pouvez le résoudre dans le même temps. C'est un peu comme la radiodiffusion où il faut la même quantité d'énergie pour diffuser sur une distance donnée, peu importe le nombre de personnes qui se trouvent dans la zone de diffusion.
O (log n ):
cette complexité est la même que O(1) sauf que c'est juste un peu pire. À toutes fins pratiques, vous pouvez considérer cela comme une très grande échelle constante. Le la différence de travail entre le traitement de mille et un milliard d'articles est seulement un facteur six.
O ( n ):
le coût de la résolution du problème est proportionnel à l'ampleur du problème. Si votre problème double en taille, alors le coût de la solution double. Comme la plupart des problèmes doivent être scannés dans l'ordinateur d'une manière ou d'une autre, comme la saisie de données, les lectures de disque, ou le trafic de réseau, il s'agit généralement abordable facteur d'échelle.
O ( n log n ):
cette complexité est très similaire à O ( n ) . À toutes fins pratiques, les deux sont équivalents. Ce niveau de complexité serait généralement considéré comme évolutif. En modifiant les hypothèses quelques O( n journal n ) algorithmes peuvent être transformés en o ( n ) algorithmes. Par exemple, limiter la taille des clés réduit le tri de O( n log n ) à O( n ) .
O ( n 2 ):
Se développe comme un carré, où n est la longueur du côté du carré. Il s'agit du même taux de croissance que l ' "effet réseau", où tout le monde dans un réseau pourrait connaître tout le monde dans le réseau. La croissance est cher. La plupart des solutions évolutives ne peuvent pas utiliser d'algorithmes avec ce niveau de complexité sans faire de gymnastique significative. Ceci s'applique généralement à toutes les autres complexités polynomiales - O ( n k ) - aussi.
O (2 n ):
Ne pas l'échelle. Vous n'avez aucun espoir de résoudre un problème de taille non triviale. Utile pour savoir ce qu'il faut éviter, et pour les experts de trouver des algorithmes approximatifs qui sont dans O( n k ) .
Big O est une mesure du temps/espace qu'un algorithme utilise par rapport à la taille de son entrée.
Si un algorithme est O(n), alors le temps/espace augmentera au même rythme que son entrée.
si un algorithme est O(n 2 ) alors le temps/espace augmente à la vitesse de son entrée au carré.
et ainsi de suite.
il est très difficile de mesurer la vitesse des logiciels, et quand nous essayons, les réponses peuvent être très complexes et remplies avec des exceptions et des cas spéciaux. C'est un gros problème, parce que toutes ces exceptions et ces cas spéciaux sont distrayants et inutiles quand nous voulons comparer deux programmes différents les uns avec les autres pour découvrir ce qui est "le plus rapide".
en raison de toute cette complexité inutile, les gens essaient de décrire la vitesse des programmes logiciels utiliser les expressions (mathématiques) les plus petites et les moins complexes possibles. Ces expressions sont des approximations très rudimentaires: bien que, avec un peu de chance, elles captent "l'essence" de la rapidité ou de la lenteur d'un logiciel.
parce qu'il s'agit d'approximations, nous utilisons la lettre" O " (Grand Oh) dans l'expression, comme convention pour signaler au lecteur que nous faisons une simplification grossière. (Et assurez-vous que personne ne pense à tort que le l'expression n'est en aucune façon précise).
si vous lisez le" Oh "comme signifiant" sur l'ordre de "ou" approximativement " vous n'irez pas trop loin. (Je pense que le choix du Big-Oh aurait pu être une tentative d'humour).
la seule chose que ces expressions" Big-Oh " essaient de faire est de décrire combien le logiciel ralentit alors que nous augmentons la quantité de données que le logiciel doit traiter. Si nous doublons la quantité de données qui doit être traitée, le logiciel le besoin de deux fois plus de temps pour finir le travail? Dix fois plus longtemps? Dans la pratique, il y a un nombre très limité d'expressions de grand-Oh que vous rencontrerez et dont vous devez vous soucier:
Le bon:
-
O(1)constante : le programme prend le même temps d'exécution, quelle que soit la taille de l'entrée. -
O(log n)logarithmique : le programme run-time augmente lentement, même avec de grandes augmentations dans la taille de l'entrée.
La mauvaise:
-
O(n)linéaire : le temps d'exécution du programme augmente proportionnellement à la taille de l'entrée. -
O(n^k)Polynomial : - le temps de traitement croît de plus en plus vite - comme une fonction polynomiale - que la taille de l'entrée augmente.
... et le laid:
-
O(k^n)exponentielle le temps d'exécution du programme augmente très rapidement avec même des augmentations modérées de la taille du problème - il est seulement pratique de traiter de petits ensembles de données avec des algorithmes exponentiels. -
O(n!)factoriel la durée du programme sera plus longue que ce que vous pouvez vous permettre d'attendre pour tout sauf le plus petit et le plus trivial-semblant ensembles de données.
Quelle est l'explication anglaise de Big O? Avec aussi peu de définition formelle que possible et mathématiques simples.
Un anglais simple Explication de la Besoin pour un Big-O Notation:
quand nous programmons, nous essayons de résoudre un problème. Ce que nous codons s'appelle un algorithme. La notation Big O nous permet de comparer les pires performances de nos algorithmes dans un manière normalisée. Les spécifications du matériel varient avec le temps et les améliorations apportées au matériel peuvent réduire le temps d'exécution des algorithmes. Mais remplacer le matériel ne signifie pas que notre algorithme est meilleur ou amélioré avec le temps, car notre algorithme est toujours le même. Donc, pour nous permettre de comparer différents algorithmes, pour déterminer si l'un est meilleur ou pas, nous utilisons la notation Big O.
Un anglais simple Explication de Ce Big O la Notation est:
tous les algorithmes ne fonctionnent pas dans le même temps, et peuvent varier en fonction du nombre d'éléments dans l'entrée, que nous appellerons n . Sur la base de ce qui précède, nous considérons que l'analyse de cas la plus défavorable, ou une limite supérieure du temps d'exécution comme n devient de plus en plus grand. Nous devons être conscients de ce qu'est n , parce que beaucoup de grandes organisations s'y réfèrent.
une réponse simple et directe peut être:
Big O représente le pire temps/espace possible pour cet algorithme. L'algorithme ne jamais prendre plus d'espace/temps au-dessus de cette limite. Le grand O représente la complexité temps / espace dans le cas extrême.
Ok, mes 2cents.
Big-O, est taux d'accroissement de ressources consommées par programme, w.r.t. problème d'une instance de taille
ressource: peut être totale-temps CPU, peut être L'espace RAM maximum. Par défaut renvoie au temps CPU.
Dire que le problème est "la somme",
int Sum(int*arr,int size){
int sum=0;
while(size-->0)
sum+=arr[size];
return sum;
}
problème instance= {5,10,15} ==> problème d'une instance de taille = 3, itérations dans la boucle= 3
problème instance= {5,10,15,20,25} ==> problème d'une instance de taille = 5 itérations dans la boucle = 5
pour l'entrée de taille" n "le programme croît à la vitesse de" n " itérations dans le tableau. Par conséquent, Big-O n'est pas exprimé en O (n)
dites que le problème est "trouver la combinaison",
void Combination(int*arr,int size)
{ int outer=size,inner=size;
while(outer -->0) {
inner=size;
while(inner -->0)
cout<<arr[outer]<<"-"<<arr[inner]<<endl;
}
}
problème instance= {5,10,15} ==> problème d'une instance size = 3 sur un total d'itérations = 3*3 = 9
problème-instance= {5,10,15,20,25} = = > problème-instance-taille = 5, total-itérations= 5*5 = 25
pour l'entrée de taille " n "le programme croît à la vitesse de" n*n " itérations dans le tableau. Par conséquent, Big-O est n 2 exprimé en O(n 2 )
Big O la notation est une façon de décrire la limite supérieure d'un algorithme en termes d'espace ou de temps d'exécution. Le n est le nombre d'éléments dans le problème (I. e taille d'un tableau, nombre de noeuds dans un arbre, etc.) Nous sommes intéressés à décrire le temps de fonctionnement comme n devient grand.
quand nous disons qu'un algorithme est O(f(n)), Nous disons que le temps d'exécution (ou l'espace requis) par cet algorithme est toujours inférieur à certains temps constants f(n).
dire que la recherche binaire a un temps d'exécution de O(logn) c'est dire qu'il existe une constante c que vous pouvez multiplier log(n) Par qui sera toujours plus grand que le temps d'exécution de la recherche binaire. Dans ce cas, vous aurez toujours un facteur constant de comparaisons log(n).
En d'autres termes, où g(n) est le temps d'exécution de notre algorithme, nous disons que g(n) = O(f(n)) g(n) <= c*f(n) lorsque n > k, où c et k sont des constantes.
" qu'est Ce qu'un anglais simple explication de Big O? Avec aussi peu formelle définition possible et mathématique simple. "
une question aussi magnifiquement simple et courte semble mériter au moins une réponse tout aussi courte, comme un élève pourrait recevoir pendant le tutorat.
la notation Big O indique simplement combien de temps* un algorithme peut s'exécuter, en termes de seule la quantité de données d'entrée **.
( *dans un merveilleux, unité libre sens du temps!)
(**ce qui importe, parce que les gens toujours veulent plus , qu'ils vivent aujourd'hui ou demain)
Eh bien, qu'y a-t-il de si merveilleux dans la notation Big O Si c'est ce qu'elle fait?
-
pratiquement parlant, L'analyse de Big O est si utile et important parce que Big O met l'accent carrément sur l'algorithme propre complexité et complètement ignore tout ce qui est simplement une constante de proportionnalité-comme un moteur JavaScript, la vitesse d'un CPU, votre connexion Internet, et toutes ces choses qui deviennent rapidement aussi ridiculement obsolètes qu'un modèle t . Gros o se concentre sur la performance seulement de la manière qui importe tout autant aux personnes vivant dans le présent ou dans le futur.
-
Big O notation brille également un projecteur directement sur le principe le plus important de la programmation informatique/ingénierie, le fait qui inspire tous les bons programmeurs pour continuer à penser et à rêver: la seule façon d'atteindre des résultats au-delà de la marche en avant lente de la technologie est de inventer un meilleur algorithme .
exemple D'algorithme (Java):
// given a list of integers L, and an integer K
public boolean simple_search(List<Integer> L, Integer K)
{
// for each integer i in list L
for (Integer i : L)
{
// if i is equal to K
if (i == K)
{
return true;
}
}
return false;
}
Description de L'algorithme:
-
cet algorithme recherche une liste, article par article, à la recherche d'une clé,
-
itérer sur chaque élément de la liste, si c'est la clé alors retourner True,
-
si la boucle est terminée sans que la clé, retourne False.
Big-O notation représentent la limite supérieure de la Complexité (Temps, Espace, ..)
pour trouver la Grande-o sur la complexité de temps:
-
Calculez combien de temps (en ce qui concerne la taille de l'entrée) le pire des cas prend:
-
Pire-Cas: la clé n'existe pas dans la liste.
-
le Temps(dans le Pire des Cas) = 4n+1
-
de Temps: O(4n+1) = O(n) | en Big-O, les constantes sont négligées
-
O(n) ~ Linear
il y a aussi Big-Omega, qui représentent la complexité du meilleur cas:
-
dans le Meilleur des Cas: la clé est le premier élément.
-
Le Temps(Dans Le Meilleur Des Cas) = 4
-
Temps: Ω(4) = O(1) ~ Instantanée\Constant
Big O
f (x) = O( g (x)) lorsque x va à a (par exemple, a = +∞) signifie qu'il y a une fonction k telle que:
-
f (x) = k (x) g (x)
-
k est bornée dans un voisinage de a (si a = + ∞ , cela signifie qu'il y a des nombres N et M tels que pour chaque x > N, | k (x)| < M).
en d'autres termes, en anglais simple: f (x) = O ( g (x)), x → a, signifie que dans un voisinage de a, f se décompose dans le produit de g et une certaine fonction bornée.
Petit o
soit dit en passant, voici à titre de comparaison la définition de petit O.
f (x) = o ( g (x)) lorsque x va à un moyen qu'il y a une fonction k telle que:
-
f (x) = k (x) g (x)
-
k (x) tend vers 0 lorsque x tend vers un.
exemples
-
sin x = O(x) quand x → 0.
-
sin x = O(1) Quand x → +∞,
-
x 2 + x = O(x) quand x → 0,
-
x 2 + x = O(x 2 ) quand x → +∞,
-
ln(x) = o(x) = O(x) quand x → +∞.
Attention! La notation avec le signe égal "=" utilise une "fausse de l'égalité": il est vrai que o(g(x)) = O(g(x)), mais fausse, que O(g(x)) = o(g(x)). De même, il est correct d'écrire "ln(x) = o(x) lorsque x → +∞", mais la formule "o(x) = ln(x)" n'aurait aucun sens.
autres exemples
-
O(1) = O(n) = O(n 2 ) lorsque n → + ∞ (mais pas l'inverse, l'égalité est "fausse"),
-
O(n) + O(n 2 ) = O(n 2 ) lorsque n → + ∞
-
O(O(n 2 )) = O (N 2 ) lorsque n → + ∞
-
O(n 2 ) O(n 3 ) = O (n 5 ) lorsque n → +∞
Voici L'article de Wikipedia: https://en.wikipedia.org/wiki/Big_O_notation
la notation Big O est une façon de décrire la vitesse d'exécution d'un algorithme avec un nombre arbitraire de paramètres d'entrée, que nous appellerons "n". Il est utile en informatique parce que les différentes machines fonctionnent à des vitesses différentes, et simplement dire qu'un algorithme prend 5 secondes ne vous dit pas grand chose car alors que vous pouvez être en train d'exécuter un système avec un processeur octo-core de 4.5 Ghz, je peux être en train d'exécuter un système de 800 Mhz vieux de 15 ans, qui pourrait prendre plus longtemps indépendamment de l'algorithme. Ainsi, au lieu de spécifier la vitesse d'exécution d'un algorithme en termes de temps, nous disons sa vitesse d'exécution en termes de nombre de paramètres d'entrée, ou "n". En décrivant les algorithmes de cette façon, nous sommes en mesure de comparer les vitesses des algorithmes sans avoir à prendre en compte la vitesse de l'ordinateur lui-même.
Je ne suis pas sûr de contribuer davantage au sujet, mais j'ai quand même pensé que je partagerais: j'ai une fois trouvé ce billet de blog pour avoir quelques très utiles (bien que très basiques) des explications et des exemples sur Big O:
grâce à des exemples, cela a aidé à mettre les bases dans mon crâne en écaille de tortue, donc je pense que c'est une belle descente 10 minutes Lire pour vous diriger dans la bonne direction.
Vous voulez savoir tout ce qu'il ya à savoir d'O? Moi aussi.
donc pour parler de big O, je vais utiliser des mots qui n'ont qu'un temps en eux. Un son par mot. Petits mots sont rapides. Vous connaissez ces mots, et moi aussi.nous utiliserons les mots avec un seul son. Ils sont de petite taille. Je suis sûr que vous connaissez tous les mots que nous allons utiliser!
parlons travail. La plupart du temps, je n'aime pas le travail. Aimez-vous travailler? Il est peut-être le cas ce que vous faites, mais je suis sûr que je n'ai pas.
je n'aime pas aller au travail. Je n'aime pas passer du temps au travail. Si j'avais mon mot à dire, j'aimerais juste jouer, et faire des choses amusantes. Vous sentez-vous la même chose que moi?
Parfois, je dois aller travailler. C'est triste, mais vrai. Donc, quand je suis au travail, j'ai une règle: j'essaie de faire moins de travail. Comme près à aucun travail que je peux. Puis-je aller jouer!
alors voici la grande nouvelle: Le Grand O peut m'aider ne pas faire le travail! Je peux jouer plus souvent, si je connais big O. moins de travail, plus de jeu! C'est ce que big O m'aide à faire.
maintenant j'ai du travail. J'ai cette liste: un, deux, trois, quatre, cinq, six. Je dois ajouter tout ce qui est dans cette liste.
Wow, je déteste le travail. Mais bon, je dois le faire. Donc ici, je vais.
un plus deux font trois... plus trois font six... et de quatre est... Je ne sais pas. Je me suis perdu. C'est trop dur pour moi de le faire dans ma tête. Je n'aime pas beaucoup ce genre de travail.
alors ne faisons pas le travail. Disons que vous et moi juste de penser combien il est difficile. Combien de travail devrais-je faire, pour ajouter six numéros?
eh Bien, voyons. Je dois ajouter un et deux, et puis Ajouter ça à trois, et puis Ajouter ça à quatre... en tout, je compte six additions. Je dois faire six additions pour résoudre ça.
voici big O, pour nous dire à quel point ce calcul est difficile.
Big O dit: nous devons faire six additions pour résoudre cela. Un add, pour chaque chose de un à six. Six petits bouts de travail... chaque morceau de travail est un add.
eh Bien, je ne vais pas faire le travail pour ajouter maintenant. Mais je sais à quel point il serait. Ce serait six additions.
Oh non, maintenant j'ai plus de travail. Sheesh. Qui fabrique ce genre de choses?!
Maintenant, ils me demandent d'ajouter de un à dix! Pourquoi ferais-je cela? Je n'ai pas envie d'ajouter un à six. Pour ajouter de un à dix... eh bien... ce serait encore plus dur!
ce serait encore plus dur? Combien de travail devrais-je encore faire? Ai-je besoin de plus ou moins de pas?
Eh bien, je suppose que je devrais faire dix additions... un pour chaque chose de un à dix. Dix, c'est plus que six. Je dois travailler beaucoup plus pour ajouter de un à dix, de un à six!
Je ne veux pas ajouter maintenant. Je veux juste penser à comment dur, il pourrait être d'ajouter que beaucoup. Et, je l'espère, à jouer dès que je peux.
pour ajouter de un à six, c'est du travail. Mais voyez-vous, pour ajouter de un à dix, c'est plus de travail?
Big O est votre ami et le mien. Big O nous aide à réfléchir à tout le travail que nous avons à faire pour pouvoir planifier. Et, si nous sommes amis avec un grand O, il peut nous aider à choisir un travail qui n'est pas si difficile!
Maintenant, nous devons faire un nouveau travail. Oh, non. Je n'aime pas ce travail chose.
le nouveau travail est: ajouter toutes choses d'un à N.
attendez! Qu'est-ce que n? J'ai pu rater ça? Comment puis-je ajouter de un à n Si vous ne me dites pas ce qu'est n?
Je ne sais pas ce que c'est. Je n'ai pas dit. Avez-vous été? Pas? Oh bien. On ne peut donc pas faire le travail. Ouf.
mais bien que nous ne ferons pas le travail maintenant, nous pouvons deviner combien il serait difficile, si nous savions N. Il faudrait additionner n choses, non? Bien sûr!
maintenant voici big O, et il va nous dire à quel point ce travail est dur. Il dit: ajouter toutes choses d'un à N, un à un, C'est O(n). Pour ajouter toutes ces choses, [je sais que je dois ajouter des fois.] [1] c'est big O! Il nous dit combien il est difficile de faire un travail quelconque.
pour moi, je pense à big O comme un grand, lent, patron. Il pense au travail, mais il ne le fait pas. Il pourrait dire, " ce travail est rapide."Ou, pourrait-il dire, est si lent et dur!"Mais il ne fait pas le travail. Il regarde juste le travail, et ensuite il nous dit combien de temps cela pourrait prendre.
je me soucie beaucoup de big O. pourquoi? Je n'aime pas travailler! Personne n'aime travailler. C'est pourquoi nous aimons tous big O! Il nous dit à quelle vitesse nous pouvons travailler. Il nous aide à penser à comment dur travail est.
plus de travail. Maintenant, essayons de ne pas faire le travail. Mais, faisons un plan pour le faire, pas à pas.
ils ont donné nous un pont de dix cartes. Ils sont tous mélangés: sept, quatre, deux, six... pas tout à tous. Et maintenant... notre travail est de les trier.
Ergh. Cela ressemble à beaucoup de travail!
Comment peut-on trier ce pont? J'ai un plan.
je vais regarder chaque paire de cartes, paire par paire, à travers le pont, du premier au dernier. Si la première carte dans une paire est grande et la prochaine carte dans cette paire est petite, je les Échange. Autre chose, je suis aller à la prochaine paire, et ainsi de suite et ainsi de suite... et bientôt, le pont est fait.
quand le jeu est terminé, je demande: est-ce que j'ai échangé les cartes dans cette passe? Si oui, je dois le faire une fois de plus, à partir du haut.
à un moment, à un moment, il n'y aura pas d'échange, et notre sorte de pont sera fait. Trop de travail!
eh Bien, comment beaucoup de travail, de trier les cartes avec ces règles?
j'ai dix cartes. Et, la plupart du temps -- c'est, si je n'ai pas beaucoup de chance: je dois passer par le pont jusqu'à dix fois, jusqu'à dix carte de swaps à chaque fois par le pont.
Big O, Aidez-moi!
Big O arrive et dit: pour un jeu de n cartes, de sorte qu'il sera fait en O(N au carré).
pourquoi dit-il n au carré?
Eh bien, vous savez que n au carré est n fois N. Maintenant, je comprends: n Cartes vérifié, jusqu'à ce que pourrait être n fois par le pont. C'est-à deux boucles, chaque n étapes. C'est n carré beaucoup de travail à faire. Beaucoup de travail, pour sûr!
maintenant quand big O dit qu'il faudra O (n au carré) travail, il ne signifie pas n au carré ajoute, sur le nez. Il pourrait être un peu moins, pour certains cas. Mais dans le pire des cas, il sera près de n carrés des étapes de travail pour trier le pont.
voilà où big O est notre ami.
Big O souligne ceci: comme n devient grand, quand nous trions les cartes, le travail devient beaucoup plus difficile que l'ancien juste-ajouter-ces-choses travail. Comment le savons-nous?
Eh bien, si n devient vraiment grand, nous ne nous soucions pas de ce que nous pourrions ajouter à n ou n au carré.
pour grand n, n au carré est plus grand que N.
Big O nous dit qu'il est plus difficile de trier les choses que de les ajouter. O(N au carré) est plus que O (N) pour big N. Cela signifie: Si n devient vraiment grand, pour trier un pont mixte de n Les choses doivent prendre plus de temps que de simplement ajouter des choses mélangées.
Big O ne résout pas le travail pour nous. Big O nous dit combien le travail est dur.
j'ai un jeu de cartes. J'ai fait le tri. Vous a aidé. Grâce.
Est-il plus rapide façon de trier les cartes? Big O Peut nous aider?
Oui, il y a de plus rapide! Il faut un certain temps pour apprendre, mais il fonctionne... et ça marche très vite. Vous pouvez l'essayer aussi, mais prenez votre temps avec chaque pas et ne perdez pas votre place.
dans cette nouvelle façon de trier un deck, nous ne vérifions pas les paires de cartes comme nous l'avons fait il y a un moment. Voici vos nouvelles règles pour trier ce deck:
: je choisis une carte dans la partie du pont, nous travaillons maintenant sur. Vous pouvez en choisir un pour moi si vous le souhaitez. (La première fois que nous faisons cela, "la partie du pont sur laquelle nous travaillons maintenant" est l'ensemble du pont, bien sûr.)
deux: je éclabousse le le pont sur la carte que vous avez choisi. Qu'est-ce que cela s'écartent; comment puis-je s'écartent? Eh bien, je vais de la carte de départ en bas, un par un, et je cherche une carte qui est plus haute que la carte splay.
trois: je vais de la carte finale vers le haut, et je cherche une carte qui est plus bas que la carte splay.
une Fois j'ai trouvé ces deux cartes, je les échange, et d'aller chercher plus de cartes à échanger. C'est, je reviens à l'étape Deux, et s'écrasent sur la carte que vous avez choisi un peu plus.
à un moment donné, cette boucle (de deux à trois) se terminera. Il se termine lorsque les deux moitiés de cette recherche se rencontrent à la carte splay. Ensuite, nous venons d'étaler le jeu avec la carte que vous avez choisie dans la première étape. Maintenant, toutes les cartes près du départ sont plus basses que la carte splay; et les cartes près de la fin sont plus hautes que la carte splay. Truc génial!
quatre (et c'est la partie amusante): j'ai deux petits ponts maintenant, un plus bas que la carte d'éclaboussure, et un plus haute. Maintenant, je vais à la première étape, sur chaque petit pont! C'est-à-dire que je commence à partir de la première étape sur le premier petit pont, et lorsque ce travail est terminé, je commence à partir de la première étape sur le prochain petit pont.
je casse le pont en morceaux, et trier chaque partie, plus petit et plus petit, et à un moment donné je n'ai plus de travail à faire. Cela peut sembler lent, avec toutes les règles. Mais croyez-moi, il n'est pas lent du tout. Il est beaucoup moins de travail que la première façon d'arranger les choses!
comment s'appelle ce genre? Il est appelé Tri Rapide! Ce tri a été fait par un homme appelé C. A. R. Hoare et il l'a appelé le tri rapide. Maintenant, Tri Rapide est utilisé tout le temps!
Sort rapide brise les grands ponts dans les petits. C'est-à-dire qu'il divise les grandes tâches en petites tâches.
Hmmm. Il peut y avoir une règle, je pense. Pour faire de grandes tâches, les casser.
ce genre est assez rapide. Comment rapide? Big O nous dit: ce type a besoin de(n log n) Travail à faire, dans le cas moyen.
Est-il plus ou moins rapide que le premier tri? Big O, à l'aide!
la première sorte était O(N au carré). Mais le tri rapide est O (N log n). Tu sais que n log n est moins que n au carré, pour big n, Non? C'est comme ça qu'on sait que le Quick Sort est rapide!
si vous devez trier un pont, Quelle est la meilleure façon? Eh bien, vous pouvez fais ce que tu veux, mais je choisirais le rapide.
Pourquoi choisir le tri rapide? Je n'aime pas travailler, bien sûr! Je veux le travail fait dès que je peux le faire faire.
Comment savoir Qu'un tri rapide est moins de travail? Je sais que O (n log n) est inférieur à O(n au carré). Les O sont plus petits, donc le tri rapide est moins de travail!
Maintenant vous connaissez mon ami, Big O. Il nous aide à faire moins de travail. Et si vous connaissez un grand O, vous pouvez faire moins de travail!
tu as appris tout ça avec moi! Vous êtes si intelligent! Merci beaucoup!
Maintenant que le travail est fait, allons jouer!
[1]: Il y a une façon de tricher et d'ajouter toutes les choses d'un à n, tout à la fois. Un gamin du nom de Gauss a découvert ça quand il avait 8 ans. Je ne suis pas si intelligent, si ne me demandez pas comment il a fait .
suppose que nous parlons d'un algorithme A , qui devrait faire quelque chose avec un ensemble de données de taille n .
puis O( <some expression X involving n> ) signifie, en anglais simple:
si vous êtes malchanceux lors de l'exécution de A, Il pourrait prendre opérations X(n) à compléter.
comme il arrive, Il ya certaines fonctions (pensez-y comme mises en œuvre de X(n) ) qui ont tendance à se produire assez souvent. Elles sont bien connues et faciles à comparer (exemples: 1 , Log N , N , N^2 , N! , etc..)
en comparant ces derniers en parlant de A et d'autres algorithmes, il est facile de classer les algorithmes en fonction du nombre d'opérations qu'ils mai (le pire des cas) nécessitent de compléter.
en général, notre objectif sera de trouver ou de structurer un algorithme A d'une manière telle qu'il aura une fonction X(n) qui retourne un nombre aussi bas que possible.
j'ai une façon plus simple de comprendre la complexité du temps a métrique la plus courante pour calculer la complexité du temps est la notation Big O. Cela supprime tous les facteurs constants de sorte que la durée de fonctionnement peut être estimée en relation avec N alors que N approche l'infini. En général, vous pouvez le penser comme ceci:
statement;
est constant. La durée de la déclaration ne changera pas par rapport à N
for ( i = 0; i < N; i++ )
statement;
est linéaire. Le temps d'exécution de la boucle est directement proportionnelle à N. lorsque N double, il en va de même pour le temps de fonctionnement.
for ( i = 0; i < N; i++ )
{
for ( j = 0; j < N; j++ )
statement;
}
est quadratique. Le temps de fonctionnement des deux boucles est proportionnel au carré de N. lorsque N double, le temps de fonctionnement augmente de N * N.
while ( low <= high )
{
mid = ( low + high ) / 2;
if ( target < list[mid] )
high = mid - 1;
else if ( target > list[mid] )
low = mid + 1;
else break;
}
est logarithmique. Le temps d'exécution de l'algorithme est proportionnelle au nombre de fois que N peut être divisé par 2. C'est parce que l'algorithme divise la zone de travail de moitié à chaque itération.
void quicksort ( int list[], int left, int right )
{
int pivot = partition ( list, left, right );
quicksort ( list, left, pivot - 1 );
quicksort ( list, pivot + 1, right );
}
est n * log ( N ). Le temps d'exécution se compose de n boucles (itératives ou récursives) qui sont logarithmiques, donc l'algorithme est une combinaison de linéaire et logarithmique.
en général, faire quelque chose avec chaque élément dans une dimension est linéaire, faire quelque chose avec chaque élément dans deux dimensions est quadratique, et diviser la zone de travail en deux est logarithmique. Il y a d'autres mesures de Grand O comme cubique, exponentielle, et carré racine, mais ils ne sont pas aussi commun. La notation Big O est décrite comme O () où est la mesure. L'algorithme de quicksort serait décrit comme O ( N * log (N ) ).
Note: rien de tout cela n'a tenu compte des mesures les meilleures, moyennes et les pires cas. Chacune aurait sa propre notation Big O. Notez également qu'il s'agit d'une explication très simpliste. Big O est le plus commun, mais c'est aussi plus complexe que j'ai montré. Il y a aussi d'autres notations comme big omega, little o, et les grandes thêta. Vous ne les rencontrerez probablement pas en dehors d'un cours d'analyse d'algorithme.
- voir plus à: ici
dites que vous commandez Harry Potter: collection complète de 8 films [Blu-ray] D'Amazon et télécharger la même collection de films en ligne en même temps. Vous voulez tester quelle méthode est la plus rapide. La livraison prend environ une journée pour arriver et le téléchargement terminé environ 30 minutes plus tôt. Grand! C'est donc une course serrée.
et si je commandais plusieurs films Blu-ray comme le Seigneur des anneaux, Twilight, La Trilogie Dark Knight, etc. et télécharger tous les films en ligne à l' même temps? Cette fois, la livraison prend encore un jour, mais le téléchargement en ligne prend 3 jours pour terminer. Pour les achats en ligne, le nombre d'articles achetés (entrée) n'affecte pas le délai de livraison. La sortie est constante. Nous l'appelons O (1) .
pour le téléchargement en ligne, le temps de téléchargement est directement proportionnel à la taille des fichiers vidéo (entrée). Nous l'appelons O(n) .
D'après les expériences, nous sachez que les achats en ligne balance mieux que le téléchargement en ligne. Il est très important de comprendre la notation big O parce qu'elle vous aide à analyser la évolutivité et efficacité des algorithmes.
Note: la notation "Big O" représente le le pire scénario d'un algorithme. Supposons que O(1) et O(n) sont les pire des cas de l'exemple ci-dessus.
référence : http://carlcheo.com/compsci
si vous avez une notion appropriée de l'infini dans votre tête, alors il y a une description très brève:
la notation Big O vous indique le coût de la résolution d'un problème infiniment grand.
et en outre
les facteurs constants sont négligeables
si vous mettez à jour vers un ordinateur qui peut exécuter votre algorithme deux fois plus vite, la notation big O ne sera pas notez que. Les améliorations constantes des facteurs sont trop petites pour être remarquées dans l'échelle avec laquelle la notation big O fonctionne. Notez qu'il s'agit d'une partie intentionnelle de la conception de la notation big O.
bien que tout ce qui est "plus grand" qu'un facteur constant puisse être détecté, cependant.
lorsque intéressé à faire des calculs dont la taille est" grande " assez pour être considéré comme environ l'infini, alors Grande o notation est environ le coût de la résolution de votre problème.
si ce qui précède n'a pas de sens, alors vous n'avez pas une notion intuitive compatible de l'infini dans votre tête, et vous devriez probablement ne pas tenir compte de tout ce qui précède; la seule façon que je sais pour rendre ces idées rigoureuses, ou pour les expliquer si elles ne sont pas déjà intuitivement utiles, est de vous enseigner d'abord la notation big O ou quelque chose de similaire. (bien que, une fois que vous comprenez bien la notation big O dans le futur, il peut être intéressant de revoir ces idées)
la façon la plus simple de le regarder (en anglais)
nous essayons de voir comment le nombre de paramètres d'entrée, affecte la durée d'exécution d'un algorithme. Si le temps d'exécution de votre application est proportionnelle au nombre de paramètres d'entrée, puis il est dit en Grand O de n.
la déclaration ci-dessus est un bon début mais pas tout à fait vrai.
une explication plus précise (mathématique)
Supposons que
n = nombre de paramètres d'entrée
T(n)= La fonction qui exprime le temps d'exécution de l'algorithme en fonction de n
C = une constante
f(n)= Une fonction d'approximation qui exprime le temps d'exécution de l'algorithme en fonction de n
alors en ce qui concerne Big O, l'approximation F (n) est considéré comme Assez bon tant que la condition ci-dessous est vrai.
lim T(n) ≤ c×f(n)
n→∞
l'équation se lit comme suit: Lorsque n approche de l'infini, T de n, est inférieur ou égal à c fois f de N.
en notation big O ceci est écrit comme
T(n)∈O(n)
ceci est lu comme T de n est dans big O de N.
retour à l'anglais
Basé sur la définition mathématique ci-dessus, si vous supposons que votre algorithme est un grand O de n, cela signifie qu'il est une fonction de n (nombre de paramètres d'entrée) ou plus rapide . Si votre algorithme est grand O de n, Alors il est aussi automatiquement le Grand o de n carré.
Grand O de n signifie mon algorithme s'exécute au moins aussi rapide que cela. Vous ne pouvez pas regarder la notation Big O de votre algorithme et dire son lent. Vous pouvez seulement dire rapide.
Vérifier ce pour une vidéo tutoriel sur Big O de UC Berkley. C'est un concept simple. Si vous entendez le professeur Shewchuck (dit Professeur de niveau divin) l'expliquer, vous direz "Oh, c'est tout!".
Quelle est l'explication en anglais de la notation" Big O"?
Note Très Rapide:
O "Big O" se réfère à "l'Ordre"(ou plus précisément "afin de")
donc, vous pourriez obtenir son idée littéralement qu'il est utilisé pour commander quelque chose à comparer.
-
"Big O" fait deux choses:
- estime combien d'étapes de la méthode votre ordinateur applique pour accomplir une tâche.
- Faciliter le processus de comparer avec d'autres afin de déterminer si c'est bon ou pas?
- "Big O" obtient deux ci-dessus avec standardisé
Notations.
-
il y a sept notations les plus utilisées
- O(1), signifie que votre ordinateur obtient une tâche fait avec
1étape, il est excellent, commandé n ° 1 - O (logN), signifie votre ordinateur accomplir une tâche avec
logNsteps, son bon, commandé n ° 2 - O (N), terminer une tâche avec
Nsteps, its fair, Order No .3 - O (NlogN), termine une tâche avec
O(NlogN)steps, it's not good, Order No .4 - O (N^2), faire une tâche avec
N^2pas, c'est mauvais, Arrêté No 5 - O(2^N), d'obtenir une tâche faite avec
2^Nles étapes, c'est horrible, l'Ordonnance n ° 6 - O (N!), d'obtenir une tâche faite avec
N!les étapes, c'est terrible, l'Ordonnance n ° 7
- O(1), signifie que votre ordinateur obtient une tâche fait avec
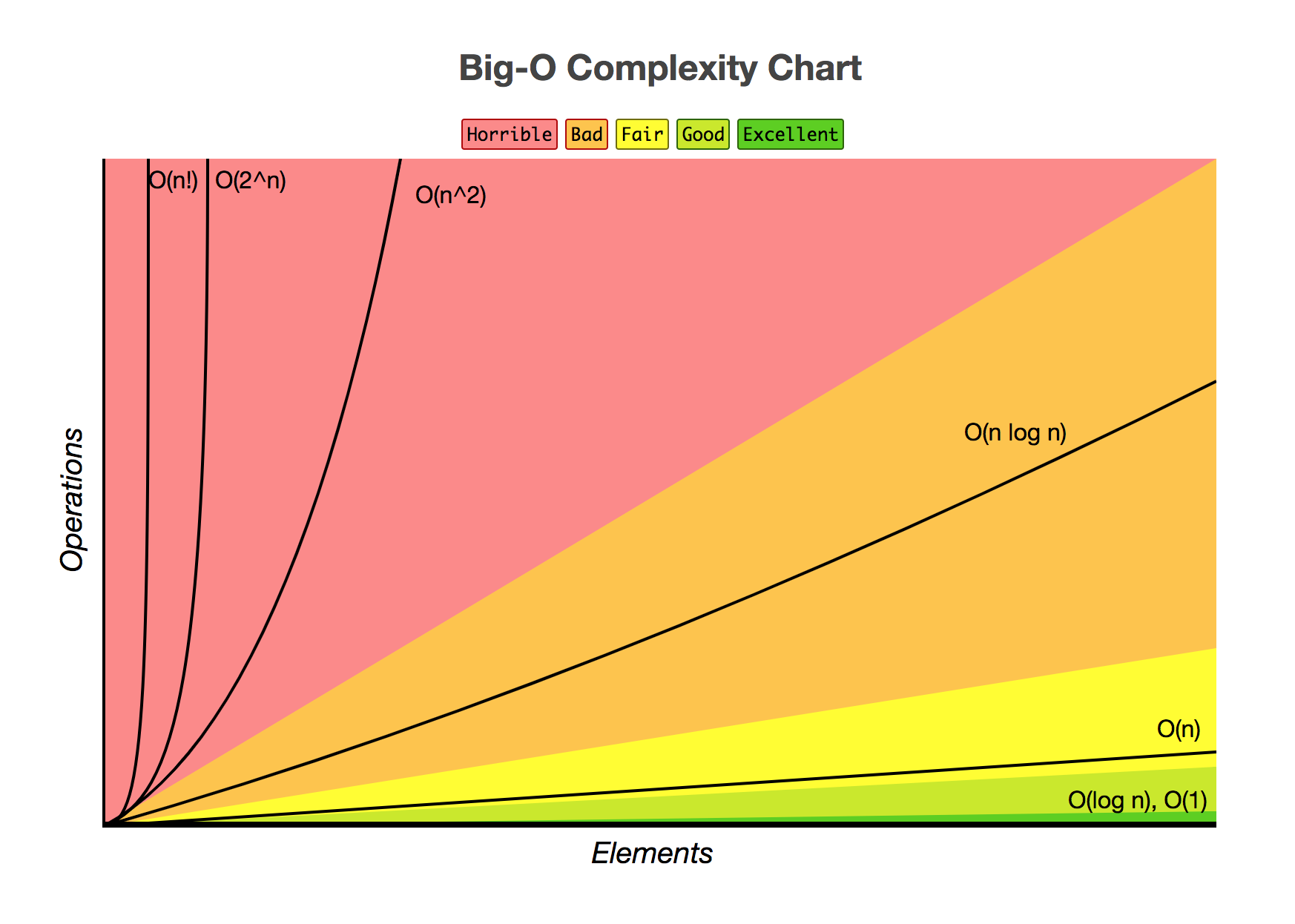
supposez que vous obtenez notation O(N^2) , non seulement vous êtes clair la méthode prend n*n étapes pour accomplir une tâche, aussi vous voir qu'il n'est pas bon comme O(NlogN) de son classement.
s'il vous plaît noter la commande à la fin de la ligne, juste pour votre meilleure compréhension.Il y a plus de 7 notes si toutes les possibilités sont considérées.
dans CS, l'ensemble des étapes pour accomplir une tâche est appelé algorithmes.
En terminologie, la notation Big O est utilisée pour décrire la performance ou la complexité d'un algorithme.
en plus, Big O établit le cas le plus défavorable ou mesure les étapes supérieures.
Vous pouvez vous référer à Big-Ω (Big-Omega) pour le meilleur cas.
Big-Ω (Big-Omega) notation (article) / Khan Academy
-
résumé
"Big O" décrit la performance de l'algorithme et l'évalue.ou adressez-vous formellement, " Big O" classifie les algorithmes et normalise le processus de comparaison.
c'est une explication très simplifiée, mais j'espère qu'elle couvre les détails les plus importants.
disons que votre algorithme traitant du problème dépend de certains "facteurs", par exemple disons n et X.
selon N et X, votre algorithme nécessitera quelques opérations, par exemple dans le pire des cas c'est des opérations 3(N^2) + log(X) .
depuis Big-O ne se soucie pas trop de facteur constant (alias 3), Le Big-O de votre algorithme est O(N^2 + log(X)) . Il traduit essentiellement "la quantité d'opérations dont votre algorithme a besoin pour les échelles du pire cas avec ceci".
définition :- la notation Big O est une notation qui indique comment la performance d'un algorithme fonctionnera si l'entrée de données augmente.
Lorsqu'on parle d'algorithmes , il y a trois piliers importants: L'entrée, la sortie et le traitement de l'algorithme. Big O est une notation symbolique qui indique si l'entrée de données est augmentée dans quelle vitesse la performance variera du traitement de l'algorithme.
je voudrais encouragez-vous à voir cette vidéo sur youtube qui explique notation Big O en profondeur avec des exemples de code.
ainsi, par exemple, supposons qu'un algorithme prend 5 enregistrements et le temps nécessaire pour les traiter est de 27 secondes. Si on augmente les enregistrements à 10, l'algorithme prend 105 secondes.
en termes simples le temps pris est carré de le nombre d'enregistrements. Nous pouvons le dénoter par O(N ^ 2) . Cette représentation symbolique est appelée notation Big O.
maintenant s'il vous plaît noter que les unités peuvent être n'importe quoi dans les entrées il peut être bytes , bits nombre d'enregistrements , la performance peut être mesurée dans n'importe quelle unité comme seconde , minutes , jours et ainsi de suite. Donc ce n'est pas l'unité exacte mais plutôt la relation.
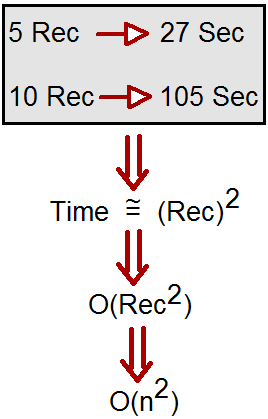
par exemple, regardez la fonction ci-dessous" Function1 " qui prend une collection et fait le traitement sur le premier enregistrement. Maintenant pour cette fonction la performance sera la même indépendamment que vous mettiez 1000 , 10000 ou 100000 enregistrements. Nous pouvons donc le désigner par O (1) .
void Function1(List<string> data)
{
string str = data[0];
}
voir maintenant la fonction ci-dessous"Function2 ()". Dans ce cas, le temps de traitement augmente avec le nombre d'enregistrements. Nous pouvons dénoter cette performance de l'algorithme en utilisant O(n) .
void Function2(List<string> data)
{
foreach(string str in data)
{
if (str == "shiv")
{
return;
}
}
}
quand nous voyons une grosse notation O pour n'importe quel algorithme nous pouvons les classer dans trois catégories de performance: -
- du Journal et de la constante de la catégorie :- à Tous les développeurs aimeraient voir leur algorithme de performances dans cette catégorie.
- Linéaire :- Développeur n'aurez pas envie de voir des algorithmes dans cette catégorie , jusqu'à sa dernière option ou la seule option qui reste.
- exponentielle: - C'est là que nous ne voulons pas voir nos algorithmes et qu'il faut retravailler.
ainsi, en regardant la notation Big O, nous catégorisons les bonnes et les mauvaises zones pour les algorithmes.
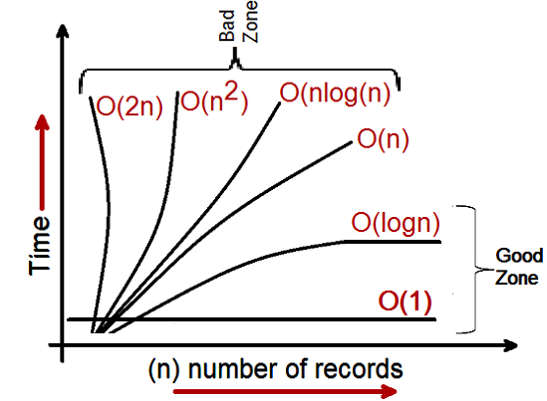
je vous recommande de regarder cette vidéo de 10 minutes qui discute de Big O avec un exemple de code
si je veux expliquer ceci à un enfant de 6 ans, je vais commencer à dessiner quelques fonctions f(x) = x et f(x) = x^2 par exemple et demander à un enfant quelle fonction sera la fonction supérieure sur le haut de la page. Ensuite, nous allons procéder avec le dessin et voir que x^2 gagne. "Qui gagne" est en fait la fonction qui croît plus rapidement lorsque x tend vers l'infini. Ainsi, "la fonction x est en grand O de x^2" signifie que x croît plus lentement que x^2 Quand x tend vers l'infini. La même chose peut être faite quand x tend à 0. Si nous tirons ces deux fonctions pour x de 0 à 1 x seront la fonction supérieure, donc "la fonction x^2 est en grand O de x pour x tend à 0". Lorsque l'enfant vieillit, j'ajoute que vraiment Big O peut être une fonction qui croît pas plus vite, mais de la même manière que la fonction. De plus constante est écartée. Donc 2x est en gros O de X.