Qu'est-ce qu'une programmation reposante?
30 réponses
Un l'architecture de style appelé REST (Representational State Transfer) , préconise que les applications web doivent utiliser le protocole HTTP comme il était le prévu à l'origine . Les recherches doivent utiliser les requêtes GET . PUT , POST , et DELETE demandes doit être utilisé pour mutation, création, et suppression respectivement .
les partisans de REST ont tendance à favoriser les URLs, comme
http://myserver.com/catalog/item/1729
mais l'architecture REST ne nécessite pas ces"belles URLs". Une requête GET avec un paramètre
http://myserver.com/catalog?item=1729
est tout aussi reposant.
gardez à l'esprit que les requêtes GET ne doivent jamais être utilisées pour mettre à jour des informations. Par exemple, une requête GET pour ajouter un article à un panier
http://myserver.com/addToCart?cart=314159&item=1729
ne serait pas approprié. Les requêtes GET doivent être idempotent . C'est, à l'émission d'une demande deux fois ne devrait pas être différent de l'émission une fois. C'est ce qui rend les requêtes accessibles. "Ajouter au panier" la demande n'est pas idempotent de délivrance de deux fois ajoute deux copies de l'article au panier. Une demande de poste est clairement appropriée dans ce contexte. Ainsi, même une application RESTful web a besoin de sa part de demandes de courrier.
extrait de l'excellent livre Core JavaServer faces Livre de David M. Geary.
REST est le principe architectural sous-jacent du web. La chose étonnante sur le web est le fait que les clients (navigateurs) et les serveurs peuvent interagir de manière complexe sans que le client ne sache rien à l'avance sur le serveur et les ressources qu'il héberge. La contrainte principale est que le serveur et le client doivent s'entendre sur le media utilisé, qui dans le cas du web est HTML .
une API qui respecte les principes de REST n'exige pas que le client sache quoi que ce soit sur la structure de l'API. Le serveur doit plutôt fournir toute information dont le client a besoin pour interagir avec le service. Un formulaire HTML en est un exemple: Le serveur spécifie l'emplacement de la ressource et les champs requis. Le navigateur ne sait pas à l'avance où soumettre l'information, et il ne sait pas à l'avance quelle information soumettre. Les deux types d'informations sont entièrement fourni par le serveur. (ce principe est appelé HATEOAS : Hypermedia comme le moteur de L'État D'Application .)
alors, comment cela s'applique-t-il à HTTP , et comment peut-il être mis en œuvre dans la pratique? HTTP est orienté vers les verbes et les ressources. Les deux verbes dans L'usage courant est GET et POST, ce que je pense que tout le monde reconnaîtra. Cependant, le standard HTTP en définit plusieurs autres comme PUT et DELETE. Ces verbes sont ensuite appliqués aux ressources, selon les instructions fournies par le serveur.
par exemple, imaginons que nous ayons une base de données utilisateur gérée par un service web. Notre service utilise un hypermédia personnalisé basé sur JSON, pour lequel nous assignons le type de mime application / json+userdb (il pourrait y avoir aussi une application/xml+userdb et application/whatever+userdb - de nombreux types de médias peuvent être pris en charge). Le client et le serveur ont tous deux été programmés pour comprendre ce format, mais ils ne savent rien l'un de l'autre. Comme Roy Fielding souligne:
une API REST devrait dépenser la quasi-totalité de son effort descriptif en la définition de la type(s) de média utilisé (s) pour représenter les ressources et conduire état de la demande, ou dans la définition des noms de relation étendue et / ou possibilité de balisage hypertexte pour les types de supports standard existants.
Une demande pour les ressources de base, / peut renvoyer à quelque chose comme ceci:
demande
GET /
Accept: application/json+userdb
réponse
200 OK
Content-Type: application/json+userdb
{
"version": "1.0",
"links": [
{
"href": "/user",
"rel": "list",
"method": "GET"
},
{
"href": "/user",
"rel": "create",
"method": "POST"
}
]
}
nous savons par la description de nos médias que nous pouvons trouver des informations sur les ressources connexes à partir de sections appelées"liens". Cela s'appelle Hypermedia controls . Dans ce cas, nous pouvons dire à partir d'une telle section que nous pouvons trouver une liste d'utilisateurs en faisant une autre demande pour /user :
demande
GET /user
Accept: application/json+userdb
réponse
200 OK
Content-Type: application/json+userdb
{
"users": [
{
"id": 1,
"name": "Emil",
"country: "Sweden",
"links": [
{
"href": "/user/1",
"rel": "self",
"method": "GET"
},
{
"href": "/user/1",
"rel": "edit",
"method": "PUT"
},
{
"href": "/user/1",
"rel": "delete",
"method": "DELETE"
}
]
},
{
"id": 2,
"name": "Adam",
"country: "Scotland",
"links": [
{
"href": "/user/2",
"rel": "self",
"method": "GET"
},
{
"href": "/user/2",
"rel": "edit",
"method": "PUT"
},
{
"href": "/user/2",
"rel": "delete",
"method": "DELETE"
}
]
}
],
"links": [
{
"href": "/user",
"rel": "create",
"method": "POST"
}
]
}
nous pouvons en dire beaucoup de cette réponse. Par exemple, nous savons maintenant que nous pouvons créer un nouvel utilisateur en postant à /user :
demande
POST /user
Accept: application/json+userdb
Content-Type: application/json+userdb
{
"name": "Karl",
"country": "Austria"
}
réponse
201 Created
Content-Type: application/json+userdb
{
"user": {
"id": 3,
"name": "Karl",
"country": "Austria",
"links": [
{
"href": "/user/3",
"rel": "self",
"method": "GET"
},
{
"href": "/user/3",
"rel": "edit",
"method": "PUT"
},
{
"href": "/user/3",
"rel": "delete",
"method": "DELETE"
}
]
},
"links": {
"href": "/user",
"rel": "list",
"method": "GET"
}
}
nous savons aussi que nous pouvons changer les données existantes:
demande
PUT /user/1
Accept: application/json+userdb
Content-Type: application/json+userdb
{
"name": "Emil",
"country": "Bhutan"
}
Réponse
200 OK
Content-Type: application/json+userdb
{
"user": {
"id": 1,
"name": "Emil",
"country": "Bhutan",
"links": [
{
"href": "/user/1",
"rel": "self",
"method": "GET"
},
{
"href": "/user/1",
"rel": "edit",
"method": "PUT"
},
{
"href": "/user/1",
"rel": "delete",
"method": "DELETE"
}
]
},
"links": {
"href": "/user",
"rel": "list",
"method": "GET"
}
}
notez que nous utilisons différents verbes HTTP (GET, PUT, POST, DELETE, etc.) pour manipuler ces ressources, et que la seule connaissance que nous présumons de la part des clients est notre définition des médias.
pour en savoir plus:
- La beaucoup de beaucoup de meilleures réponses sur cette page.
-
comment j'ai expliqué le repos à ma femme . - comment j'ai expliqué le repos à ma femme .
- Martin Fowler's pensées
- de Paypal API a hypermédia contrôles
(cette réponse a fait l'objet de nombreuses critiques pour avoir manqué le point. Pour la plupart, cela a été une critique juste. Ce que j'ai à l'origine décrit était plus en ligne avec la façon dont REST était habituellement mis en œuvre Il ya quelques années lorsque je l'ai écrit pour la première fois, plutôt que sa véritable signification. J'ai révisé la réponse pour mieux représenter le vrai sens.)
- les ressources étant identifiées par un identificateur persistant: les URI sont le choix ubiquiste de l'Identificateur de nos jours
- ressources en cours de manipulation à l'aide d'un ensemble commun de verbes: les méthodes HTTP sont le cas le plus courant - le vénérable
Create,Retrieve,Update,DeletedevientPOST,GET,PUT, etDELETE. Mais le repos ne se limite pas à HTTP, c'est juste le moyen de transport le plus couramment utilisé en ce moment. - la représentation réelle retrouvée pour une ressource dépend de la requête et non de l'identifiant: utilisez les en-têtes Accept pour contrôler si vous voulez XML, HTTP, ou même un objet Java représentant la ressource
- maintien de l'état dans l'objet et représentation de l'état dans la représentation
- représente les relations entre les ressources dans le représentation de la ressource: les liens entre objets sont incorporés directement dans la représentation
- ressources représentations de décrire la façon dont la représentation peut être utilisé et dans quelles circonstances il doit être jeté/refetched de manière cohérente: l'utilisation de HTTP-tête Cache-Control
la dernière est probablement la plus importante en termes de conséquences et d'efficacité globale du repos. Dans l'ensemble, la plupart des Reposante les discussions semblent se concentrer sur HTTP et son utilisation à partir d'un navigateur et ce qui ne l'est pas. Je crois comprendre que R. Fielding a inventé le terme LORSQU'il a décrit l'architecture et les décisions qui mènent à HTTP. Sa thèse porte davantage sur l'architecture et la capacité de cache des ressources que sur HTTP.
si vous êtes vraiment intéressé par ce qu'est une architecture reposante et pourquoi il fonctionne, lire sa thèse à quelques reprises et lire le toute chose pas seulement le Chapitre 5! Regardez ensuite dans pourquoi le DNS fonctionne . Renseignez-vous sur l'organisation hiérarchique du DNS et sur le fonctionnement des aiguillages. Ensuite, lisez et considérez comment fonctionne la mise en cache DNS. Enfin, lisez les spécifications HTTP ( RFC2616 et RFC3040 en particulier) et examinez comment et pourquoi la mise en cache fonctionne comme elle le fait. Finalement, il suffit de cliquez sur. La révélation finale pour moi était quand j'ai vu la similitude entre DNs et HTTP. Après cela, comprendre pourquoi les Interfaces de SOA et de passage de messages sont évolutives commence à cliquer.
je pense que l'astuce la plus importante pour comprendre l'importance architecturale et les implications de performance d'une architecture reposante et rien partagé est d'éviter de se raccrocher aux détails de la technologie et de la mise en œuvre. Concentrez-vous sur qui possède les ressources, qui est responsable de leur création et de leur maintien, etc. Pensez ensuite aux représentations, aux protocoles et aux technologies.
voilà à quoi ça pourrait ressembler.
créer un utilisateur avec trois propriétés:
POST /user
fname=John&lname=Doe&age=25
le serveur répond:
200 OK
Location: /user/123
dans le futur, vous pouvez alors récupérer les informations de l'utilisateur:
GET /user/123
le serveur répond:
200 OK
<fname>John</fname><lname>Doe</lname><age>25</age>
pour modifier l'enregistrement ( lname et age resteront inchangés):
PATCH /user/123
fname=Johnny
pour mettre à jour l'enregistrement (et par conséquent lname et age seront nuls):
PUT /user/123
fname=Johnny
un grand livre sur le repos est le repos dans la pratique .
Doit se lit sont Representational State Transfer (REST) et RESTE Api doit être hypertexte
Voir Martin Fowlers l'article Richardson Modèle de Maturité (RMM) pour une explication sur ce qu'est un service RESTful.
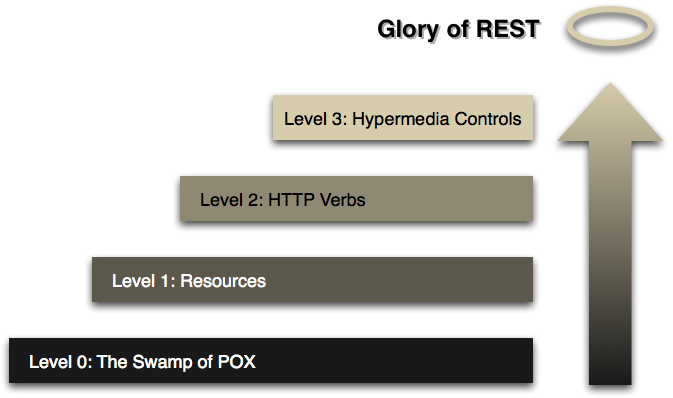
pour rester un Service a besoin de remplir L'hypermédia comme le moteur de L'État D'Application. (HATEOAS) , c'est-à-dire qu'il doit atteindre le niveau 3 dans le RMM, lire l'article pour plus de détails ou le glisse de la QCon talk .
la contrainte HATEOAS est un acronyme pour Hypermédia comme Moteur de L'État De L'Application. Ce principe est la clé de la différenciation entre un RESTE et la plupart des autres formes de serveur client système.
...
un client D'une application reposant besoin ne connaître qu'une seule URL fixe pour accéder il. Toutes les actions futures devraient être a découvrir dynamiquement à partir de hypermédia liens inclus dans le les représentations des ressources sont retournés à partir de cette URL. Les types de supports standardisés sont également prévu pour être compris par tout client qui pourrait utiliser une API RESTful. (De Wikipédia, l'encyclopédie libre)
REST Litmus Test for Web Frameworks est un test de maturité similaire pour les Web frameworks.
Approche de pur REPOS: Apprentissage de l'amour HATEOAS est une bonne collection de liens.
REST versus SOAP for the Public Cloud examine les niveaux actuels d'utilisation du repos.
REST and versioning discute extensibilité, Versioning, Evolvability, etc. par Modifiabilité
Qu'est-ce que le repos?
reste signifie transfert D'État de représentation. (Il est parfois épelé "repos".) Il s'appuie sur un serveur client-stateless, cachable protocole de communication -- et dans pratiquement tous les cas, le HTTP le protocole est utilisé.
REST est un style d'architecture pour la conception d'applications réseau. L'idée est que, plutôt que d'utiliser des mécanismes complexes tels que CORBA, RPC ou SOAP pour se connecter entre machines, HTTP simple est utilisé pour faire appels entre machines.
à bien des égards, le World Wide Web lui-même, basé sur HTTP, peut être consulté comme une architecture basée sur le repos. Les applications RESTful utilisent des requêtes HTTP pour afficher des données (créer et / ou mettre à jour), lire des données (par exemple, faire des requêtes), et de suppression des données. Ainsi, REST utilise HTTP pour les quatre CRUDS (Créer/Lire/mettre à jour/Supprimer)
repose est un poids léger alternative à des mécanismes tels que le RPC (Remote Procédure D'appel) et les Services Web (SOAP, WSDL, et al.). Plus tard, nous allons voyez comme le repos est simple.
en dépit d'être simple, le repos est entièrement-featured; Il y a essentiellement rien que vous pouvez faire dans les Services Web qui ne peut être fait avec un Reposful architecture. Le REPOS n'est pas un "standard". Il n'y aura jamais de W3C recommendataion pour le REPOS, par exemple. Et tant QU'il y a du repos cadres de programmation, travailler avec le repos est si simple que vous pouvez souvent "roulez votre propre" avec des fonctionnalités de bibliothèque standard dans des langues comme Perl, Java, ou C#.
L'une des meilleures références que j'ai trouvées quand j'ai essayé de trouver le sens réel simple du repos.
reste utilise les différentes méthodes HTTP (principalement GET/PUT / DELETE) pour manipuler les données.
plutôt que d'utiliser une URL spécifique pour supprimer une méthode (disons, /user/123/delete ), vous enverriez une demande de suppression à L'URL /user/[id] , pour modifier un utilisateur, pour récupérer des informations sur un utilisateur que vous envoyez une demande GET à /user/[id]
par exemple, à la place un ensemble D'URLs qui pourrait ressembler à certains des suivants..
GET /delete_user.x?id=123
GET /user/delete
GET /new_user.x
GET /user/new
GET /user?id=1
GET /user/id/1
vous utilisez le HTTP "verbes" et ont..
GET /user/2
DELETE /user/2
PUT /user
c'est la programmation où l'architecture de votre système correspond au REST style présenté par Roy Fielding dans sa thèse . Puisque c'est le style architectural qui décrit le web (plus ou moins), beaucoup de gens sont intéressés.
réponse Bonus: non. Sauf si vous étudiez l'architecture logicielle comme un universitaire ou la conception de services web, il n'y a vraiment aucune raison d'avoir entendu le terme.
je dirais que la programmation RESTful serait sur la création de systèmes (API) qui suivent le style architectural REST.
j'ai trouvé ce tutoriel fantastique, court et facile à comprendre sur le repos par le Dr. M. Elkstein et citant la partie essentielle qui répondrait à votre question pour la plupart:
apprendre le repos: un tutoriel
REST est un style d'architecture pour la conception d'applications réseau. L'idée est que, plutôt que d'utiliser des mécanismes complexes tels que CORBA, RPC ou SOAP pour se connecter entre machines, HTTP simple est utilisé pour faire appels entre machines.
"151900920 de" repos applications utilisent des requêtes HTTP pour publier des données (créer et/ou mise à jour), lire données (par exemple, faire des requêtes), et supprimer des données. Ainsi, le REPOS utilise HTTP pour les quatre opérations CRUD (Create/Read/Update/Delete).
- à bien des égards, le World Wide Web lui-même, basé sur HTTP, peut être considéré comme une architecture reposant.
Je ne pense pas que vous devriez vous sentir stupide de ne pas entendre parler de repos à L'extérieur du débordement de la pile..., Je serais dans la même situation!; les réponses à cette autre question ainsi sur pourquoi le repos devient grand maintenant pourrait soulager certains sentiments.
Je m'excuse si Je ne réponds pas directement à la question, mais il est plus facile de comprendre tout cela avec des exemples plus détaillés. Fielding n'est pas facile à comprendre en raison de toute l'abstraction et de la terminologie.
il y a un assez bon exemple ici:
expliquer le repos et L'hypertexte: Spam-e le Robot de nettoyage de Spam
et encore mieux, il y a une explication claire avec des exemples simples ici (le powerpoint est plus complet, mais vous pouvez obtenir la plupart dans la version html):
http://www.xfront.com/REST.ppt ou http://www.xfront.com/REST.html
après avoir lu les exemples, je peux comprendre pourquoi Ken dit que le repos est basé sur l'hypertexte. Je ne suis pas vraiment sûr qu'il ait raison, parce que / user / 123 est une URI qui pointe vers une ressource, et il n'est pas clair pour moi que c'est inattendu juste parce que le client est au courant."
ce document xfront explique la différence entre le repos et le savon, et c'est vraiment utile aussi. Quand Fielding dit C'est RPC. Il crie RPC. ", il est clair que RPC n'est pas reposant, il est donc utile de voir les raisons exactes de cela. (SOAP est un type de RPC.)
Qu'est-ce que le repos?
repos en termes officiels, le repos est un style architectural construit sur certains principes en utilisant les bases actuelles "Web". Il y a 5 fondamentaux de base du web qui sont exploités pour créer des services de repos.
- Principe 1: Tout est une ressource Dans le reste du style architectural, les données et les fonctionnalités sont considérées comme des ressources et sont accessibles à l'aide D'identificateurs de ressources Uniformes( URIs), généralement des liens sur Web.
- Principe 2: chaque ressource est identifiée par un identificateur unique (URI)
- Principe 3: Utiliser des Interfaces simples et uniformes
- Principe 4: la Communication se fait par représentation
- Principe 5: Être Apatride
je vois un tas de réponses que dire mettre tout sur l'utilisateur 123 à des ressources "/user/123" est Reposant.
Roy Fielding, qui a inventé le terme, dit les API de repos doivent être basées sur l'hypertexte . En particulier, "une API REST ne doit pas définir de noms ou de hiérarchies de ressources fixes".
donc si votre chemin" /user/123 " est codé en dur sur le client, ce n'est pas vraiment reposant. Une bonne utilisation de HTTP, peut-être, peut-être pas. Mais pas de tout repos. Il a venir de l'hypertexte.
la réponse est très simple, il y a une dissertation écrite par Roy Fielding.] 1 Dans cette thèse, il définit le RESTE principes. Si une demande satisfait à tous ces principes, il s'agit d'une demande REST.
le terme RESTful a été créé parce que ppl a épuisé le mot REST en appelant leur application non-REST comme REST. après cela le terme RESTful a été également épuisé. de nos jours nous parlons D'API Web et D'API hypermédia , parce que la plupart des applications dites REST ne remplissaient pas la partie HATEO de la contrainte d'interface uniforme.
les autres contraintes sont les suivantes:
-
architecture client-serveur
donc il ne fonctionne pas avec par exemple PUB/Sub sockets, il est basé sur REQ/REP.
-
apatrides communication
ainsi le serveur ne maintient pas les états des clients. Cela signifie que vous ne pouvez pas utiliser un serveur de stockage de session et que vous devez authentifier chaque requête. Vos clients peuvent éventuellement envoyer des en-têtes d'auth de base par une connexion cryptée. (Par grandes applications il est difficile de maintenir beaucoup de sessions.)
-
utilisation de cache si vous pouvez
donc vous ne pas avoir à servir les mêmes requêtes encore et encore.
-
interface uniforme communes de contrat entre le client et le serveur
Le contrat entre le client et le serveur n'est pas géré par le serveur. En d'autres termes, le client doit être découplée de la mise en œuvre du service. Vous pouvez atteindre cet état en utilisant des solutions standard, comme la norme IRI (URI) pour identifier les ressources, la norme HTTP pour échanger messages, types MIME standard pour décrire le format de sérialisation du corps, métadonnées (éventuellement vocabs RDF, microformats, etc.) pour décrire la sémantique des différentes parties du corps du message. Pour découpler la structure IRI du client, vous devez envoyer des hyperliens aux clients dans des formats hypermédia comme (HTML, JSON-LD, HAL, etc.). Ainsi, un client peut utiliser les métadonnées (éventuellement les relations de lien, RDF vocabs) affectées aux hyperliens pour naviguer dans la machine d'état de l'application à travers le des transitions d'état appropriées afin d'atteindre son objectif actuel.
Par exemple, lorsqu'un client veut envoyer une commande à une boutique en ligne, alors il faut vérifier les liens hypertexte dans les réponses envoyées par la boutique en ligne. En vérifiant les liens qu'il crée un Décrit avec le http://schema.org/OrderAction . Le client connaît schema.org vocab, donc il comprend qu'en activant cet hyperlien il enverra la commande. Donc il active l'hyperlien et envoie un
POST https://example.com/api/v1/ordermessage avec le corps approprié. Après cela le service traite le message et répond avec le résultat ayant l'en-tête D'état HTTP approprié, par exemple201 - createdpar le succès. Pour annoter les messages avec des métadonnées détaillées la solution standard d'utiliser un format RDF, par exemple JSON-LD avec un Vocab REST, par exemple Hydra et des vocabs spécifiques au domaine comme schema.org ou toute autre liée données vocab et peut-être un vocab spécifique à l'application si nécessaire. Maintenant, ce n'est pas facile, c'est pourquoi la plupart des ppl utilisent HAL et d'autres formats simples qui ne fournissent généralement QU'un vocab REST, mais pas de support de données liées. -
construire un système stratifié pour augmenter l'évolutivité
le système REST est composé de couches hiérarchiques. Chaque couche contient des composants qui utilisent les services de composants qui se trouvent dans les calque de dessous. Vous pouvez donc ajouter de nouvelles couches et de nouveaux composants sans effort.
par exemple, il y a une couche client qui contient les clients et, en dessous, il y a une couche service qui contient un seul service. Maintenant, vous pouvez ajouter un cache côté client entre eux. Après cela, vous pouvez ajouter une autre instance de service et un équilibreur de charge, et ainsi de suite... Le code client et le code de service ne changeront pas.
-
code sur demande pour étendre le client fonctionnalité
cette contrainte est facultative. Par exemple, vous pouvez envoyer un analyseur pour un type de média spécifique au client, et ainsi de suite... Pour ce faire, vous pourriez avoir besoin d'un standard chargeur de plugin système dans le client, ou votre client sera couplé au plugin loader solution.
RESTE les contraintes de résultat très évolutive système où les clients sont découplées de la mise en œuvre des services. Donc les clients peut être réutilisable, général tout comme les navigateurs sur le web. Les clients et les services partagent les mêmes normes et vocabs, de sorte qu'ils peuvent se comprendre les uns les autres malgré le fait que le client ne connaît pas les détails de la mise en œuvre du service. Cela permet de créer des clients automatisés qui peuvent trouver et utiliser des services de repos pour atteindre leurs objectifs. À long terme, ces clients peuvent communiquer entre eux et se confier des tâches, comme le font les humains. Si nous ajoutons l'apprentissage modèles pour ces clients, puis le résultat sera un ou plusieurs IA en utilisant le web de machines au lieu d'un parc de serveur unique. Ainsi, à la fin, le rêve de Berners Lee: la toile sémantique et l'intelligence artificielle seront la réalité. Donc, en 2030, nous finissons avec le Skynet. Jusqu'à ce moment ... ;- )
"151910920 de" repos (Representational state transfer) de l'API de programmation est l'écriture d'applications web dans un langage de programmation par suite de 5 logiciels de base l'architecture de style principes:
- de Ressources (données, informations).
- identificateur mondial Unique (toutes les ressources sont uniques et identifiées par URI ).
- Uniform interface - utiliser l'interface simple et standard (HTTP).
- représentation-toute communication se fait par représentation (par exemple XML / JSON )
- Stateless (chaque requête se déroule en isolation complète, il est plus facile de mettre en cache et d'équilibrer le chargement),
en d'autres termes, vous écrivez un réseau point à point simple applications sur HTTP qui utilise des verbes tels que GET, POST, PUT ou DELETE en mettant en œuvre l'architecture RESTful qui propose la standardisation de l'interface chaque "ressource" expose. Ce n'est rien que d'utiliser les fonctionnalités actuelles du web d'une manière simple et efficace (architecture très réussie, éprouvée et distribuée). Il s'agit d'une alternative à des mécanismes plus complexes comme SOAP , CORBA et RPC .
la programmation RESTful est conforme à la conception de l'architecture Web et, si elle est correctement mise en œuvre, elle vous permet de profiter pleinement de l'infrastructure Web évolutive.
si je devais réduire la dissertation originale sur le repos à seulement 3 phrases courtes, je pense que le suivant capture son essence:
Les ressources- sont demandées via des URLs. Les protocoles
- sont limités à ce que vous pouvez communiquer en utilisant des URLs.
- les métadonnées sont passées en tant que paires nom-valeur (Paramètres post data et chaîne de requête).
après cela, il est facile de tomber dans les débats sur les adaptations, les conventions de codage et les pratiques exemplaires.
fait intéressant, il n'y a aucune mention D'opérations HTTP POST, GET, DELETE, ou PUT dans la dissertation. Ce doit être l'interprétation ultérieure d'une " pratique exemplaire "pour une"interface uniforme".
en ce qui concerne les services web, il semble que nous ayons besoin d'une manière ou d'une autre de distinguer les architectures WSDL et SOAP qui ajoutent des frais généraux considérables et sans doute beaucoup de complexité inutile à la interface. Ils nécessitent également des cadres et des outils de développement supplémentaires pour être mis en œuvre. Je ne suis pas sûr que REST soit le meilleur terme pour distinguer entre interfaces de bon sens et interfaces trop conçues telles que WSDL et SOAP. Mais nous avons besoin de quelque chose.
Voici mon schéma de base du repos. J'ai essayé de démontrer la pensée derrière chacun des composants dans une architecture reposante de sorte que la compréhension du concept est plus intuitive. Espérons que cela aide à démystifier le repos pour certaines personnes!
REST (Representational State Transfer) est une architecture de conception qui décrit comment les ressources réseau (c'est à dire les nœuds qui partagent de l'information) sont conçus et réglés. En général, une architecture reposante fait en sorte que le le client (la machine requérante) et le serveur (la machine répondante) peuvent demander à lire, écrire et mettre à jour des données sans que le client ait à savoir comment le serveur fonctionne et le serveur peut le transmettre sans avoir besoin de savoir quoi que ce soit sur le client. OK, cool...mais comment faire en pratique?
-
l'exigence la plus évidente est qu'il doit y avoir un langage universel de sorte que le serveur puisse dire au client ce qu'il est essayer de faire avec la demande et de réponse du serveur.
-
mais pour trouver une ressource donnée et ensuite dire au client où cette ressource vit, il doit y avoir une façon universelle de pointer les ressources. C'est là que les identificateurs de ressources universels (URI) entrent en jeu; Ce sont essentiellement des adresses uniques pour trouver les ressources.
mais l'architecture REST ne s'arrête pas là! Alors que le ci-dessus remplit les besoins de base de ce que nous voulons, nous voulons aussi avoir une architecture qui prend en charge le trafic à haut volume puisque n'importe quel serveur gère habituellement les réponses d'un certain nombre de clients. Ainsi, nous ne voulons pas surcharger le serveur en lui faisant mémoriser des informations sur des requêtes précédentes.
-
par conséquent, nous imposons la restriction que chaque paire requête-réponse entre le client et le serveur est indépendante, ce qui signifie que le serveur n'a pas à souvenez-vous de tout ce qui concerne les requêtes précédentes (états précédents de l'interaction client-serveur) pour répondre à une nouvelle requête. Cela signifie que nous voulons que nos interactions d'être apatride.
-
pour alléger davantage la pression sur notre serveur de refaire des calculs qui ont déjà été faits récemment pour un client donné, REST permet également la mise en cache. Fondamentalement, la mise en cache signifie prendre un instantané de la réponse initiale fournie au client. Si le client fait l' même requête encore une fois, le serveur peut fournir au client le snapshot plutôt que de refaire tous les calculs nécessaires pour créer la réponse initiale. Cependant, comme il s'agit d'un snapshot, si le snapshot n'est pas expiré--le serveur fixe un délai d'expiration à l'avance--et que la réponse a été mise à jour depuis le cache initial (c'est-à-dire que la requête donnerait une réponse différente de la réponse mise en cache), le client ne verra pas les mises à jour jusqu'à ce que le cache expire (ou que le cache soit effacé).) et la réponse est rendue à partir de zéro à nouveau.
-
la dernière chose que vous trouverez souvent ici à propos des architectures reposantes est qu'elles sont en couches. En fait, nous avons déjà discuté implicitement de cette exigence dans notre discussion sur l'interaction entre le client et le serveur. Fondamentalement, cela signifie que chaque couche dans notre système interagit seulement avec les couches adjacentes. Ainsi, dans notre discussion, la couche client interagit avec la couche serveur (et vice versa), mais il peut y avoir d'autres couches de serveur qui aident le serveur principal à traiter une requête avec laquelle le client ne communique pas directement. Plutôt, le serveur transmet la demande.
maintenant, si tout cela semble familier, alors grand. Le protocole de transfert hypertexte (HTTP), qui définit le protocole de communication via le World Wide Web est une implémentation de la notion abstraite d'architecture RESTful (ou une instance de la classe de repos si vous êtes un fanatique OOP comme moi). Dans cette implémentation de REST, le client et le serveur interagissent via GET, POST, PUT, DELETE, etc., qui font partie du langage universel et les ressources peuvent être pointées à l'aide D'URLs.
REST est un modèle architectural et le style de l'écriture distribuées applications. Ce n'est pas un style de programmation au sens étroit du terme.
dire que vous utilisez le style repos est similaire à dire que vous avez construit une maison dans un style particulier: par exemple Tudor ou victorienne. Le repos en tant que style logiciel et le Tudor ou le style victorien en tant que style maison peuvent être définis par les qualités et les contraintes qui les composent. Par exemple, REST doit avoir une séparation du Serveur Client où les messages se décrivent d'eux-mêmes. Les maisons de style Tudor ont des pignons qui se chevauchent et des toits à pente raide avec des pignons faisant face à l'avant. Vous pouvez lire la dissertation de Roy pour en savoir plus sur les contraintes et les qualités qui composent le reste.
repos contrairement aux styles de maison a eu du mal à être appliqué de façon uniforme et pratique. Cela peut avoir été intentionnel. Laissant au concepteur le soin de sa mise en œuvre. Vous êtes donc libre de faire ce que vous voulez tant que vous respectez les contraintes énoncées dans la dissertation vous créez des systèmes de repos.
Bonus:
le web entier est basé sur le repos (ou le repos était basé sur le web). Par conséquent, en tant que développeur web, vous voudrez peut-être au courant de cela, bien qu'il ne soit pas nécessaire d'écrire de bonnes applications web.
je pense que le point de repos est le séparation de l'état dans une couche supérieure tout en faisant usage de l'internet (protocole) comme un couche de transport apatride . La plupart des autres approches confondent les choses.
il a été la meilleure approche pratique pour gérer les changements fondamentaux de la programmation dans l'ère internet. En ce qui concerne les changements fondamentaux, Erik Meijer a une discussion sur show ici: http://www.infoq.com/interviews/erik-meijer-programming-language-design-effects-purity#view_93197 . Il le résume comme les cinq effets, et présente une solution en concevant la solution dans un langage de programmation. La solution, pourrait également être réalisée au niveau de la plate-forme ou du système, quelle que soit la langue. Le repos peut être vu comme l'une des solutions qui a été très efficace dans la pratique actuelle.
avec le style reposant, vous obtenez et manipuler l'état de l'application à travers un internet fiable. S'il ne réussit pas l'opération courante pour obtenir l'état correct et courant, il a besoin du principe de Zero-validation pour aider l'application à continuer. S'il échoue à manipuler l'état, il utilise généralement plusieurs étapes de confirmation pour garder les choses correctes. En ce sens, rest n'est pas lui-même une solution complète, il a besoin des fonctions dans une autre partie de la pile d'applications web pour soutenir son fonctionnement.
Étant donné ce point de vue, le style rest n'est pas vraiment lié à internet ou à l'application web. C'est une solution fondamentale à de nombreuses situations de programmation. Il n'est pas simple non plus, il rend juste l'interface vraiment simple, et s'adapte avec d'autres technologies étonnamment bien.
juste mon 2c.
Edit: deux autres aspects importants:
-
apatridie est trompeur. C'est sur L'API restful, pas l'application ou le système. Le système doit être dynamique. Restful design consiste à concevoir un système stateful basé sur une API apatride. Quelques citations d'un autre QA :
- reste, fonctionne sur des représentations de ressources, chacune identifiée par une URL. Ce ne sont généralement pas des objets de données, mais abstractions d'objets complexes .
- RESTE " est synonyme de "représentation transfert d'état", ce qui signifie qu'il s'agit de communiquer et de modifier l'état d'une ressource dans un système.
c'est étonnamment long" discussion " et pourtant tout à fait déroutant pour dire le moins.
OMI:
1) Il n'y a pas de programme reposant, sans un gros joint et beaucoup de bière:)
2) REST (Representational State Transfer) est un style architectural spécifié dans la thèse de Roy Fielding . Il comporte un certain nombre de contraintes. Si votre service / Client les respecte, alors c'est Reposant. C'est ici.
vous pouvez résumer (de manière significative) les contraintes à:
- apatrides communication
- respecter les spécifications HTTP (si HTTP est utilisé)
- communique clairement les formats de contenu transmis
- utiliser hypermedia comme moteur de l'état d'application
Il y a un autre très bon post , qui explique les choses bien.
beaucoup de réponses copient/collent des informations valides en les mélangeant et en ajoutant de la confusion. Les gens parlent ici de niveaux, D'URIs reposants (il n'y a pas une telle chose!), apply HTTP methods GET,POST, PUT ... Le REPOS n'est pas à propos de ça, ou pas seulement.
par exemple des liens-il est agréable d'avoir une API à la belle apparence mais à la fin le client/serveur ne se soucie pas vraiment de la les liens que vous obtenez/envoyer c'est le contenu qui importe.
À la fin tout Reposant client doit être en mesure de consommer à tout service RESTful tant que le contenu format est connu.
REST signifie transfert D'état représentatif .
il repose sur un protocole de communication stateless, client-server, cacheable -- et dans pratiquement tous les cas, le protocole HTTP est utilisé.
REST est souvent utilisé dans les applications mobiles, les sites de réseaux sociaux, les outils mashup et les processus d'affaires automatisés. Le style REST souligne que les interactions entre les clients et les services amélioré par un nombre limité d'opérations (verbes). La flexibilité est assurée en assignant des ressources (noms) à leurs propres indicateurs universels de ressources (URI).
parler est plus que simplement échanger des informations . Un protocole est en fait conçu de sorte qu'aucune conversation ne doit avoir lieu. Chaque partie sait ce travail particulier est parce qu'il est spécifié dans le protocole. Les protocoles permettent l'échange pur d'informations aux dépens d'avoir n'importe quels changements dans les actions possibles. En revanche, le fait de parler permet à une partie de demander quelles autres mesures elle peut prendre. Ils peuvent même poser la même question deux fois pour obtenir deux réponses différentes, depuis l'Etat de l'autre partie peut avoir changé dans l'intervalle. Parler le repos de l'architecture . La thèse de Fielding précise l'architecture que l'on devrait suivre si l'on voulait permettre aux machines de parler l'un à l'autre plutôt que simplement communiquer .
Il n'y a pas la notion de "repos programmation" en soi. Il vaudrait mieux parler de paradigme reposant ou encore d'architecture reposant. Il n'est pas un langage de programmation. C'est un paradigme.
En informatique, REST (representational state transfer) est un style architectural utilisé pour le développement web.
Vieille question, newish manière de répondre. Il y a beaucoup d'idées fausses à propos de ce concept. J'essaie toujours de me souvenir:
- URLs structurées et méthodes Http/verbes ne sont pas la définition de une programmation reposante.
- JSON n'est pas reposante programmation "151930920 de" repos de la programmation n'est pas pour les Api
je définir reposant programmation
une application est restful si elle fournit des ressources (c'est-à-dire la combinaison de données + contrôles de transition d'état) dans un type de média que le client comprend
pour être un programmeur reposant, vous devez essayer de construire des applications qui permettent aux acteurs de faire des choses. Pas seulement exposer la base de données.
les contrôles de transition D'État n'ont de sens que si le client et le serveur s'entendent sur une représentation de type média de la ressource. Autrement il n'y a aucun moyen de savoir ce qui est un contrôle et ce qui ne l'est pas et comment exécuter un contrôle. C'est-à-dire que si les navigateurs ne connaissaient pas les balises html, il n'y aurait rien à soumettre à l'état de transition dans votre navigateur.
Je ne cherche pas à promouvoir moi-même, mais je développe ces idées à grande profondeur dans mon discours http://techblog.bodybuilding.com/2016/01/video-what-is-restful-200.html .
REST = = = l'analogie HTTP N'est pas correcte tant que vous n'insistez pas sur le fait qu'elle "doit" être HATEOAS driven.
Roy lui-même l'a nettoyé ici .
une API REST doit être entrée sans aucune connaissance préalable au-delà de L'URI initiale (marque-page) et de l'ensemble des types de supports normalisés qui sont appropriés pour le public visé (c.-à-d. que l'on s'attend à ce qu'ils soient compris par tout client qui pourrait utiliser l'API). À partir de ce moment, toutes les transitions d'état d'application doivent être pilotées par la sélection par le client des choix fournis par le serveur qui sont présents dans les représentations reçues ou sous-entendues par la manipulation par l'utilisateur de ces représentations. Les transitions peuvent être déterminées (ou limitées) par la connaissance qu'a le client des types de médias et des mécanismes de communication des ressources, qui peuvent tous deux être améliorés à la volée (p. ex., code à la demande).
[Défaut ici implique que out-of-band l'information stimule l'interaction plutôt que l'hypertexte.]
REST est un style architectural basé sur les standards Web et le protocole HTTP (introduit en 2000).
dans une architecture reposant, tout est une ressource(utilisateurs, commandes, commentaires). Une ressource est accessible via une interface commune basée sur les méthodes standard HTTP(GET, PUT, PATCH, DELETE, etc.).
dans une architecture basée sur le repos vous avez un serveur de repos qui fournit l'accès aux ressources. Un client REST peut accéder et modifier le reste ressources.
chaque ressource doit supporter les opérations communes HTTP. Les ressources sont identifiées par des identificateurs globaux (qui sont généralement des URI).
reste permet que les ressources aient des représentations différentes, par exemple, texte, XML, JSON etc. Le client REST peut demander une représentation spécifique via le protocole HTTP (négociation de contenu).
méthodes HTTP:
les méthodes PUT, GET, POST et DELETE sont typiques utilisées dans les architectures basées sur REST. Le tableau suivant donne une explication de ces opérations.
- GET définit un accès de lecture de la ressource sans effets secondaires. La ressource n'est jamais changée via une requête GET, par exemple, la requête n'a aucun effet secondaire (idempotent).
- PUT crée une nouvelle ressource. Il doit également être idempotent.
- Supprimer supprime les ressources. Les opérations sont idempotents. Ils peuvent être répétés sans conduire à des résultats différents.
- Post met à jour une ressource existante ou crée une nouvelle ressource.
le point de repos est que si nous acceptons d'utiliser un langage commun pour les opérations de base (les verbes http), l'infrastructure peut être configurée pour les comprendre et les optimiser correctement, par exemple, en utilisant des en-têtes de mise en cache pour implémenter la mise en cache à tous les niveaux.
avec une opération restful GET correctement implémentée, cela ne devrait pas avoir d'importance si les informations proviennent de la base de données de votre serveur, de memcache de votre serveur, D'un CDN, de la cache d'un proxy, de la cache de votre navigateur ou le stockage local de votre navigateur. La source à jeun la plus facilement disponible et à jour peut être utilisée.
dire que Rest est juste un changement syntaxique de l'utilisation des requêtes GET avec un paramètre d'action à l'utilisation des verbes http disponibles Le fait paraître comme il n'a pas d'avantages et est purement esthétique. Le point est d'utiliser un langage qui peut être compris et optimisé par chaque partie de la chaîne. Si votre opération GET a une action avec des effets secondaires, vous devez sauter tous les HTTP cachez ou vous finirez avec des résultats incohérents.
REST définit 6 contraintes architecturales qui font de n'importe quel service web – un véritable API RESTful .
- interface Uniforme
- Client-serveur
- apatride
- Cachable
- Système À Couches
- Code à la demande (facultatif)
Qu'est-ce que API Testing ?
API testing utilise la programmation pour envoyer des appels à L'API et obtenir le rendement. It testing considère le segment à l'essai comme une boîte noire. L'objectif des tests API est de confirmer la bonne exécution et le traitement erroné de la partie précédant sa coordination dans une application.
REST API
reste: Transfert D'État Représentatif.
- c'est un ensemble de fonctions sur lesquelles les testeurs exécutent des requêtes et reçoivent des réponses. Dans REST, les interactions API se font via le protocole HTTP. Le
- permet également la communication entre ordinateurs sur un réseau.
- pour l'envoi et la réception de messages, il implique L'utilisation de méthodes HTTP, et il ne nécessite pas une définition de message stricte, contrairement au Web service. Les messages
- acceptent souvent le formulaire soit en format XML, soit en Notation objet JavaScript (JSON).
4 méthodes API couramment utilisées: -
- OBTENIR: – Il fournit un accès en lecture seule à une ressource.
- POSTE: – Il est utilisé pour créer ou mettre à jour une nouvelle ressource.
- PUT – - il est utilisé pour mettre à jour ou remplacer un de ressources ou de créer une nouvelle ressource.
- Supprimer: - il est utilisé pour supprimer une ressource.
étapes pour tester L'API manuellement: -
pour utiliser L'API manuellement, nous pouvons utiliser les plugins REST API basés sur le navigateur.
- Installer FACTEUR(Chrome) et de REPOS(Firefox) le plugin
- entrez L'URL de L'API
- sélectionner la méthode REST
- sélectionner content-Header
- Enter Request JSON (POST)
- cliquez sur Envoyer
- Ce sera le retour de la réaction de production
Ceci est beaucoup moins mentionné partout mais le modèle de maturité de Richardson est l'une des meilleures méthodes pour juger réellement comment Restful est son API. Pour en savoir plus:
REST est un style d'architecture logicielle de systèmes distribués (tels que WWW), vous pouvez imaginer qu'il s'agit d'une application Web bien conçue règles: un groupe de pages Web Internet (une machine d'état virtuel), dans lequel hyperlien en cliquant lien (transition d'état), le résultat est la page Web suivante (qui signifie l'état suivant de l'application).
reste décrit le système de réseau se compose de trois parties:
- éléments de données (ressources, l'identificateur de ressource de la représentation)
- connecteurs (client, serveur, cache, résolveur, tunnel)
- composants (serveur d'origine, de passerelle, de proxy, de l'agent utilisateur)
RESTE strictement respecter les conditions suivantes:
- Statut de la fonctionnalité de l'application est divisée en ressources
- chaque ressource utilisée comme syntaxe de positionnement des hyperliens (ie, dans L'URI WWW)
- toutes les ressources partagent une interface uniforme entre le client et l'état de transition des ressources, y compris:
- un ensemble limité d'opérations bien définies (C'est-à-dire dans HTTP GET / POST / PUT / DELETE)
- un ensemble limité de types de contenu de format de contenu, qui peut inclure le code exécutable (c'est-à-dire, dans le JavaScript WWW)