Qu'est-ce qui pourrait causer un ralentissement global du Tomcat/JVM?
je suis confronté à un problème étrange mais grave d'exécution de plusieurs (environ 15) instances D'applications Web Java EE-ish (Hibernate 4+Spring+Quartz+JSF+Facelets+Richfaces) sur Tomcat 7/Java 7.
le système fonctionne très bien, mais après un temps très variable toutes les instances de l'application en même temps souffrent soudainement de temps de réponse en hausse. Fondamentalement, l'application fonctionne toujours, mais les temps de réponse sont environ trois fois plus élevé.
Ce sont deux diagrammes affichant le temps de réponse de deux actions / flux de travail courts (log in, access list of seminars, ajax-refresh this list, log out; la ligne inférieure est juste le temps de requête pour le rafraîchissement ajax) de deux exemples d'instances de l'application:
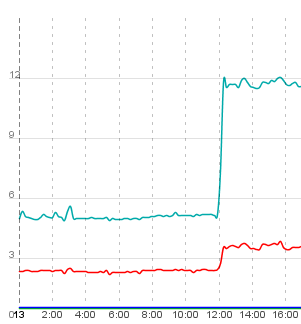
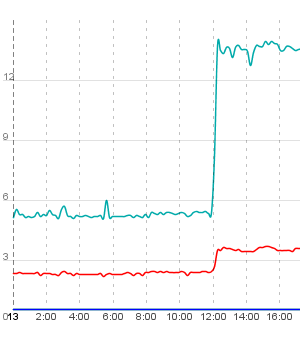
comme vous pouvez le voir, les deux instances de l'application "explosent" au même moment et restent lentes. Après avoir redémarré le serveur, tout est redevenu normal. Tous les exemples de l'application "exploser" simultanément.
nous stockons les données de la session dans une base de données et nous les utilisons pour le regroupement. Nous avons vérifié la taille et le nombre de sessions et les deux sont plutôt bas (ce qui signifie que sur d'autres serveurs avec d'autres applications nous avons parfois plus de sessions). L'autre Tomcat dans le cluster reste généralement rapide pendant quelques heures et après cette quantité aléatoire de temps, il "meurt". Nous avons vérifié la taille des tas avec jconsole et les principaux arrêts de tas entre 2,5 et 1 Go de taille, le pool de connexion db est essentiellement plein de connexions gratuites, ainsi que les pools de thread. La taille de tas Max est de 5 Go, il y a aussi beaucoup d'espace disponible. La charge n'est pas particulièrement élevée; il n'y a qu'environ 5% de charge sur le processeur principal. Le serveur n'a pas de swap. Ce n'est pas non plus un problème de matériel puisque nous avons également déployé les applications sur une VM où les problèmes restent les mêmes.
Je ne sais plus où regarder, je suis à court d'idées. Quelqu'un a une idée où chercher?
2013-02-21 Mise À Jour: Nouvelles Données!
j'ai ajouté deux traces de timing à l'application. En ce qui concerne la mesure: le système de surveillance appelle un servlet qui exécute deux tâches, mesure le temps d'exécution pour chacune sur le serveur et écrit le temps de réponse. Ces valeurs sont enregistrées par le système de surveillance.
j'ai plusieurs faits nouveaux intéressants: Un redéploiement à chaud de l'application provoque cette instance unique sur le Tomcat actuel pour aller de noix. Cela semble aussi affecter la performance du calcul CPU brut (voir ci-dessous). Cette explosion individuelle-contextuelle diffère de l'explosion globale-contextuelle qui se produit de façon aléatoire.
Maintenant, pour certains de données:
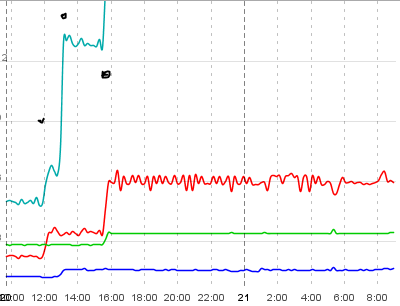
d'Abord les différentes lignes:
- Bleu Clair est le temps total d'exécution d'un petit workflow (détails voir ci-dessus), mesuré sur le client
- Le Rouge est une "partie" du bleu clair et est le temps pris pour effectuer une étape spéciale de ce workflow, mesuré sur le client
- Dark blue est mesuré dans l'application et consiste à lire une liste d'entités de la base de données par hibernation et itération au-dessus de cette liste, allant chercher des collections paresseuses et des entités paresseuses.
- Green est un petit benchmark CPU utilisant des opérations à virgule flottante et à nombre entier. Pour autant que je ne vois pas d'affectation des objets, donc pas de déchets.
Maintenant, pour les étapes individuelles d'explosion: j'ai marqué chaque image avec trois points noirs. La première est une "petite" explosion dans plus ou moins une seule instance d'application - en Inst1 elle saute (particulièrement visible dans la ligne rouge), alors Qu'en Inst2 plus ou moins reste calme.
après cette petite explosion le" big bang " se produit et toutes les instances d'application sur ce Tomcat explosent (2ème point). Notez que cette explosion affecte toutes les opérations de haut niveau( traitement des requêtes, accès DB), mais la CPU référence. Il reste bas dans les deux systèmes.
après cela J'ai redéployé Inst1 en touchant le contexte.fichier xml. Comme je l'ai dit plus tôt, cette instance passe de exploded à completely devestated now (la ligne bleu clair est hors de la carte - il est à environ 18 secondes). Notez comment a) ce redéploiement n'affecte pas du tout Inst2 et b) comment L'accès brut DB D'Inst1 N'est pas non plus affecté - mais comment le CPU soudainement semble être devenu plus lent!. C'est fou, je dire.
mise à jour de la mise à jour L'auditeur de prévention des fuites de Tomcat ne se plaint pas de Threadlocaux ou de Threads périmés lorsque l'application n'est pas déployée. Il semble évidemment qu'il y ait un problème de nettoyage (qui n'est pas directement lié au Big Bang, je suppose), mais Tomcat n'a pas d'indice pour moi.
2013-02-25 mise à jour: Environnement D'Application et calendrier de Quartz
l'environnement d'application n'est pas très sophistiqué. Réseau mis à part les composants (Je ne les connais pas assez), il y a essentiellement un serveur d'application (Linux) et deux serveurs de bases de données (MySQL 5 et MSSQL 2008). La charge principale est sur le serveur MSSQL, l'autre sert simplement d'un endroit pour stocker les sessions.
le serveur D'application exécute Un Apache comme équilibreur de charge entre deux Tomcats. Nous avons donc deux JVM fonctionnant sur le même matériel (deux Tomcat cas). Nous utilisons cette configuration pour ne pas équilibrer la charge comme le serveur d'application est capable d'exécuter l'application correctement (ce qu'il a fait pendant des années maintenant) mais pour permettre de petites mises à jour de l'application sans temps d'arrêt. L'application web en question est déployée séparément contextes pour différents clients, environ 15 contextes par Tomcat. (Il me semble que j'ai confondu "instances" et "contextes" dans mon message - ici, dans le bureau, ils sont souvent utilisés comme synonymes et nous savons habituellement par magie de quoi parle le collègue. My bad, je suis vraiment désolé.)
Pour clarifier la situation avec une meilleure formulation: les diagrammes que j'ai postés montrent les temps de réponse de deux contextes différents de la même application sur la même JVM. Le Big Bang affecte tous les contextes sur une JVM mais ne se produit pas sur l'autre (l'ordre dans lequel les Tomcats explosent est aléatoire btw). Après un redéploiement à chaud, un contexte sur une instance Tomcat devient fou (avec tous les effets secondaires drôles, comme un CPU apparemment plus lent pour cela). cadre.)
La charge globale sur le système est plutôt faible. Il s'agit d'un logiciel interne lié à l'activité principale avec environ 30 utilisateurs actifs simultanément. Les requêtes spécifiques aux applications (touches du serveur) sont actuellement d'environ 130 par minute. Le nombre de requêtes simples est faible, mais les requêtes elles-mêmes nécessitent souvent plusieurs centaines de sélections dans la base de données, de sorte qu'elles sont assez coûteuses. Mais d'habitude, tout est parfaitement acceptable. L'application ne crée pas non plus grand infini caches-certaines données de recherche sont cachées, mais seulement pour une courte période de temps.
ci-dessus, j'ai écrit que les serveurs étaient capables de faire fonctionner l'application pendant plusieurs années. Je sais que la meilleure façon de trouver le problème serait de savoir exactement quand les choses ont mal tourné pour la première fois et de voir ce qui a été changé dans ce délai (dans l'application elle-même, les bibliothèques ou l'infrastructure associée), mais le problème est que nous ne savons pas quand les problèmes d'abord s'est produite. Appelons simplement cette surveillance d'application sous-optimale (dans le sens d'absence)... : -/
nous avons exclu certains aspects, mais l'application a été mise à jour plusieurs fois au cours des derniers mois et nous ne pouvons donc pas simplement déployer une version plus ancienne. La mise à jour la plus importante qui n'a pas été un changement de fonctionnalité a été un passage de JSP à Facelets. Mais tout de même, "quelque chose" doit être la cause de tous les problèmes, pourtant je n'ai aucune idée pourquoi Facelets par exemple devrait influencer la requête pure DB temps.
Quartz
en ce qui concerne le Calendrier Quartz: il y a un total de 8 emplois. La plupart d'entre eux ne fonctionnent qu'une fois par jour et ont à voir avec la synchronisation de grands volumes de données (absolument pas "grand" comme dans "big data large"; c'est juste plus que l'utilisateur moyen voit à travers son travail quotidien habituel). Toutefois, ces emplois fonctionnent bien sûr la nuit et les problèmes se produisent le jour. Je Omets une liste détaillée d'emploi ici (si bénéfique, je peux fournir plus de détails, bien sûr). Emploi' le code source n'a pas été modifié au cours des derniers mois. J'ai déjà vérifié si les explosions concordent avec les travaux - mais les résultats sont au mieux peu concluants. En fait, je dirais qu'ils ne s'alignent pas, mais comme il y a plusieurs jobs qui s'exécutent à chaque minute, je ne peux pas encore l'exclure. Les acutal jobs qui fonctionnent chaque minute sont assez faible à mon avis, ils vérifient généralement si les données sont disponibles (dans différentes sources, DB, systèmes externes, compte e-mail) et si oui, écrivez - le à la DB ou poussez-le à un autre système.
cependant, je suis en train d'activer la journalisation de l'exécution des tâches individuelles pour que je puisse voir exactement l'horodatage de début et de fin de chaque exécution de tâche. Peut-être cela fournit plus de perspicacité.
2013-02-28 mise à jour: Phases et calendrier du JSF
j'ai ajouté manuellement un écouteur JSF phae à l'application. J'ai exécuté un appel d'échantillon (l'Ajax refresh) Et voici ce que j'ai (à gauche: instance Tomcat en cours d'exécution, à droite: instance Tomcat après Big Bang - les nombres ont été pris presque simultanément des deux Tomcats et sont en millisecondes):
- RESTORE_VIEW: 17 vs 46
- APPLY_REQUEST_VALUES: 170 vs 486
- validation des processus: 78 vs 321
- UPDATE_MODEL_VALUES: 75 vs 307
- RENDER_RESPONSE: 1059 vs 4162
le rafraîchissement ajax lui-même appartient à un formulaire de recherche et son résultat de recherche. Il y a aussi un autre délai entre le le filtre de requête extrême de l'application et le flux web commence son travail: il y a un FlowExecutionListenerAdapter qui mesure le temps pris dans certaines phases du flux web. Cet auditeur déclare 1405 ms pour "demande soumise" (ce qui est à ma connaissance le premier événement de flux web) sur un total de 1632 ms pour la demande complète sur un Tomcat Non explosé, donc j'estime à environ 200ms de frais généraux.
Mais sur le Tomcat explosé, il signale 5332 ms pour la demande soumise (ce qui signifie que toutes les phases JSF se produisent dans ces 5 secondes) sur une durée de demande totale de 7105ms, nous sommes donc jusqu'à presque 2 secondes de trop pour tout ce qui est en dehors de la demande de web flow soumise.
Sous mon filtre de mesure, la chaîne de filtrage contient un org.ajax4jsf.webapp.BaseFilter, alors le servlet à ressort est appelé.
2013-06-05 mise à jour: tout ce qui se passe dans les dernières semaines
une petite mise à jour plutôt tardive... la performance de l'application est toujours nulle après un certain temps et le comportement reste erratique. Le profilage n'a pas encore beaucoup aidé, il a juste généré une énorme quantité de données qui est difficile à disséquer. (Essayez de faire un tour dans les données de performance ou de profiler un système de production... sigh) nous avons effectué plusieurs tests (démontage de certaines parties du logiciel, mise en place d'autres applications, etc. et effectivement eu quelques améliorations qui touchent l'ensemble de l'application. Le mode flush par défaut de notre EntityManagerAUTO et pendant le rendu de vue Beaucoup de fetches et de sélections sont émises, toujours y compris l'vérifiez si le rinçage est nécessaire.
Nous avons donc construit un écouteur de phase JSF qui définit le mode flush à COMMIT cours RENDER_RESPONSE. Cela a amélioré la performance globale beaucoup et semble avoir atténué les problèmes.
pourtant, notre suivi d'application continue de donner des résultats et des performances complètement insensés sur certains contextes sur certaines instances tomcat. Comme une action qui devrait finir en moins d'une seconde (et qui le fait réellement après déploiement) et qui prend maintenant plus de quatre secondes. (Ces nombres sont supportés par le chronométrage manuel dans les navigateurs, donc ce n'est pas la surveillance qui cause les problèmes).
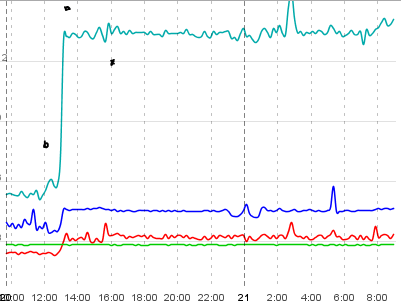
voir l'image suivante par exemple: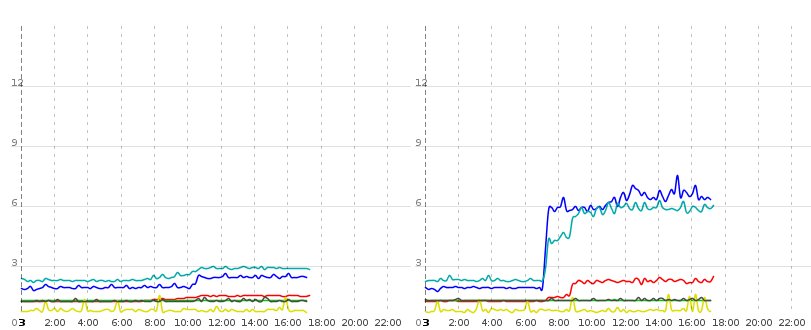
ce diagramme montre deux instances tomcat tournant dans le même contexte (ce qui signifie Même db, même configuration, même jar). De nouveau la ligne bleue est le temps pris par pure DB opérations de lecture (récupérer une liste de entités, itérer sur eux, paresseusement chercher des collections et des données associées). La turquoise-ish et la ligne rouge sont mesurées en rendant plusieurs vues et en faisant un rafraîchissement ajax, respectivement. Les données fournies par deux des requêtes en turquoise-ish et en rouge sont essentiellement les mêmes que celles de la ligne bleue.
maintenant vers 0700 sur l'instance 1 (à droite) il y a cette énorme augmentation du temps de DB pur qui semble affecter les temps de réponse réels de rendu aussi bien, mais seulement sur tomcat 1. Tomcat 0 est en grande partie non affecté par cela, il ne peut donc pas être causé par le serveur ou le réseau DB avec les deux tomcats tournant sur le même matériel physique. Il doit s'agir d'un problème de logiciel dans le domaine Java.
lors de mes derniers tests, j'ai découvert quelque chose d'intéressant: toutes les réponses contiennent l'en-tête "X-Powered-By: JSF/1.2, JSF/1.2". Certains (les réponses de redirection produites par WebFlow) ont même "JSF/1.2" trois fois là-dedans.
J'ai tracé les parties du code qui ont placé ces en-têtes et la première fois que cet en-tête est défini, il est provoqué par cette pile:
... at org.ajax4jsf.webapp.FilterServletResponseWrapper.addHeader(FilterServletResponseWrapper.java:384)
at com.sun.faces.context.ExternalContextImpl.<init>(ExternalContextImpl.java:131)
at com.sun.faces.context.FacesContextFactoryImpl.getFacesContext(FacesContextFactoryImpl.java:108)
at org.springframework.faces.webflow.FlowFacesContext.newInstance(FlowFacesContext.java:81)
at org.springframework.faces.webflow.FlowFacesContextLifecycleListener.requestSubmitted(FlowFacesContextLifecycleListener.java:37)
at org.springframework.webflow.engine.impl.FlowExecutionListeners.fireRequestSubmitted(FlowExecutionListeners.java:89)
at org.springframework.webflow.engine.impl.FlowExecutionImpl.resume(FlowExecutionImpl.java:255)
at org.springframework.webflow.executor.FlowExecutorImpl.resumeExecution(FlowExecutorImpl.java:169)
at org.springframework.webflow.mvc.servlet.FlowHandlerAdapter.handle(FlowHandlerAdapter.java:183)
at org.springframework.webflow.mvc.servlet.FlowController.handleRequest(FlowController.java:174)
at org.springframework.web.servlet.mvc.SimpleControllerHandlerAdapter.handle(SimpleControllerHandlerAdapter.java:48)
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:925)
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:856)
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:920)
at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:827)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:641)
... several thousands ;) more
La deuxième fois cet en-tête est défini par
at org.ajax4jsf.webapp.FilterServletResponseWrapper.addHeader(FilterServletResponseWrapper.java:384)
at com.sun.faces.context.ExternalContextImpl.<init>(ExternalContextImpl.java:131)
at com.sun.faces.context.FacesContextFactoryImpl.getFacesContext(FacesContextFactoryImpl.java:108)
at org.springframework.faces.webflow.FacesContextHelper.getFacesContext(FacesContextHelper.java:46)
at org.springframework.faces.richfaces.RichFacesAjaxHandler.isAjaxRequestInternal(RichFacesAjaxHandler.java:55)
at org.springframework.js.ajax.AbstractAjaxHandler.isAjaxRequest(AbstractAjaxHandler.java:19)
at org.springframework.webflow.mvc.servlet.FlowHandlerAdapter.createServletExternalContext(FlowHandlerAdapter.java:216)
at org.springframework.webflow.mvc.servlet.FlowHandlerAdapter.handle(FlowHandlerAdapter.java:182)
at org.springframework.webflow.mvc.servlet.FlowController.handleRequest(FlowController.java:174)
at org.springframework.web.servlet.mvc.SimpleControllerHandlerAdapter.handle(SimpleControllerHandlerAdapter.java:48)
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:925)
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:856)
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:920)
at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:827)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:641)
je n'ai aucune idée si cela pourrait indiquer un problème, mais je n'ai pas remarqué cela avec d'autres applications sont en cours d'exécution sur un de nos serveurs, donc cela pourrait ainsi fournir quelques indications. Je n'ai vraiment aucune idée de ce que fait ce code-cadre (il est vrai que je n'y ai pas encore réfléchi)... peut-être quelqu'un a une idée? Ou suis-je en train de tomber sur un mort fin?
Annexe
mon code de Référence CPU se compose d'une boucle qui calcule les maths.tan et utilise la valeur de résultat pour modifier certains champs sur l'instance servlet (aucun volatile/synchronisé), et effectue ensuite plusieurs Calculs entiers bruts. Ce n'est pas sévèrement sophistiqué, je sais, mais bon... il semble montrer quelque chose dans les graphiques, mais je ne suis pas sûr ce qu'il montre. Je fais les mises à jour sur le terrain pour empêcher HotSpot d'optimiser tout mon précieux code ;)
long time2 = System.nanoTime();
for (int i = 0; i < 5000000; i++) {
double tan = Math.tan(i);
if (tan < 0) {
this.l1++;
} else {
this.l2++;
}
}
for (int i = 1; i < 7500; i++) {
int n = i;
while (n != 1) {
this.steps++;
if (n % 2 == 0) {
n /= 2;
} else {
n = n * 3 + 1;
}
}
}
// This execution time is written to the client.
time2 = System.nanoTime() - time2;
7 réponses
Solution
augmenter la taille maximale du Cache de Code:
-XX:ReservedCodeCacheSize=256m
Background
nous utilisons ColdFusion 10 qui tourne sur Tomcat 7 et Java 1.7.0_15. Nos symptômes étaient similaires aux vôtres. De temps en temps, les temps de réponse et L'utilisation CPU sur le serveur augmentaient considérablement sans raison apparente. Il semble que le processeur soit devenu plus lent. La seule solution était de redémarrer ColdFusion (et Tomcat).
analyse Initiale
je j'ai commencé par examiner l'utilisation de la mémoire et le registre du collecteur d'ordures. Il n'y avait rien qui pourrait expliquer nos problèmes.
ma prochaine étape a été de programmer une décharge de tas toutes les heures et d'effectuer régulièrement des échantillonnages à L'aide de VisualVM. L'objectif était d'obtenir des données avant et après un ralentissement de sorte qu'il pourrait être comparé. J'ai réussi à obtenir le réaliser.
il y avait une fonction dans l'échantillonnage qui s'est distinguée: get() dans coldfusion.Runtime.Concordentreferencehashmap. Un beaucoup de temps a été consacré à après le ralentissement par rapport à très peu avant. J'ai passé un certain temps à comprendre comment la fonction fonctionnait et développé une théorie que peut-être il y avait un problème avec la fonction de hachage résultant en quelques énormes seaux. En utilisant les dumps tas j'ai pu voir que les plus grands seaux ne contenaient que 6 éléments donc j'ai écarté cette théorie.
Cache De Code
j'ai finalement pris la bonne voie lorsque J'ai lu "Java Performance: The Definitive Guide". Il y a un chapitre sur le compilateur JIT qui parle du Cache de Code dont je n'avais pas entendu parler auparavant.
Compilateur désactivé
en surveillant le nombre de compilations effectuées (surveillées avec jstat) et la taille du Cache de Code (surveillées avec le plugin de Pools de mémoire de VisualVM) j'ai vu que la taille a augmenté jusqu'à la taille maximale (qui est de 48 Mo par défaut dans notre environnement -- la valeur par défaut varie selon la version Java et le compilateur Java). Quand le Cache de Code devenu le Compilateur JIT a été désactivée. J'ai lu que "CodeCache est plein. Compilateur a été désactivé."doit être imprimé lorsque cela se produit, mais je n'ai pas vu ce message, peut-être que la version que nous utilisons n'ont pas ce message. Je sais que le compilateur a été désactivé parce que le nombre de compilations effectuées cessé d'augmenter.
la Désoptimisation continue
le compilateur JIT peut désoptimiser des fonctions déjà compilées qui vont caler la fonction être à nouveau exécuté par l'interpréteur (à moins que la fonction ne soit remplacée par une compilation améliorée). La fonction désoptimisée peut être récupérée pour libérer de l'espace dans le Cache de Code.
pour une raison quelconque, les fonctions ont continué à être désoptimisées même si rien n'a été compilé pour les remplacer. De plus en plus de mémoire serait disponible dans le Cache de Code mais le compilateur JIT n'a pas été redémarré.
Je n'ai jamais EU-XX:+PrintCompilation activée en cas de ralentissement mais je suis tout à fait sûr que j'aurais vu L'un ou L'autre Concordentreferencehashmap.get (), ou une fonction dont elle dépend, soit désoptimisée à ce moment-là.
Résultat
nous n'avons pas vu de ralentissement depuis que nous avons augmenté la taille maximale du Cache de Code à 256 Mo et nous avons également vu une amélioration générale des performances. Il y a actuellement 110 Mo dans notre Cache de Code.
tout d'abord, permettez-moi de dire que vous avez fait un excellent travail accaparant détaillé faits à propos du problème; j'aime vraiment la façon dont vous expliquez clairement ce que vous savez et ce que vous spéculez - cela aide vraiment.
EDIT 1 Massif modifier après la mise à jour sur le contexte de la contre exemple
Nous pouvons exclure:
- GCs (qui aurait une incidence sur le CPU benchmark thread de service et spike le PROCESSEUR principal)
- Quartz jobs (qui affecterait à la fois Tomcats ou le benchmark CPU)
- La base de données (qui aurait une incidence sur les deux Matous)
- Réseau de paquets tempêtes et similaires (ce qui aurait une incidence sur les deux Matous)
je crois que vous souffrez d'une augmentation de latence quelque part dans votre JVM. La latence est l'endroit où un thread attend (de façon synchrone) une réponse de quelque part - cela augmente le temps de réponse de votre servlet mais sans aucun coût pour le CPU. Typique les latences sont causés par:
- appels Réseau, y compris
- JDBC
- EJB ou RMI
- JNDI
- DNS
- partages de Fichiers
- lecture et écriture sur disque
- Filetage
- Lecture à partir de (et parfois écrit) les files d'attente
synchronizedméthode ou de bloquerfuturesThread.join()Object.wait()Thread.sleep()
Confirmer que le problème est le temps de latence
je suggère d'utiliser un outil de profilage commercial. I like [JProfiler] (http://www.ej-technologies.com/products/jprofiler/overview.html, version d'essai de 15 jours disponible) mais YourKit est également recommandé par la communauté StackOverflow. Dans ce discussion j'utiliserai la terminologie de JProfiler.
se fixer au processus Tomcat pendant qu'il exécute fine et obtenir une sensation de ce qu'il ressemble dans des conditions normales. En particulier, utilisez les sondes de haut niveau JDBC, JPA, JNDI, JMS, servlet, socket et file pour voir combien de temps prennent les opérations JDBC, JMS, etc (démo. Exécutez ceci de nouveau lorsque le serveur affiche des problèmes et comparez. J'espère que vous verrez ce qui précisément a été ralentie. Dans le produit capture d'écran ci-dessous, vous pouvez voir le SQL timings à l'aide de l'APC de la Sonde:
{kind=link}
cependant, il est possible que les sondes n'aient pas isolé le problème - par exemple, il pourrait s'agir d'un problème de filetage. Allez dans la vue Threads pour l'application; cela affiche un graphique des états de chaque thread, et si elle est exécutée sur le CPU, dans un Object.wait(), est en attente d'entrer un synchronized bloquez ou attendez sur l'entrée/sortie du réseau . Lorsque vous savez quel thread ou threads présente le problème, allez dans les vues CPU, sélectionnez le thread et utilisez le sélecteur d'états de thread pour aller immédiatement jusqu'aux méthodes coûteuses et à leurs piles d'appels. [Vidéo]((démo). Vous serez en mesure de percer dans votre code d'application.
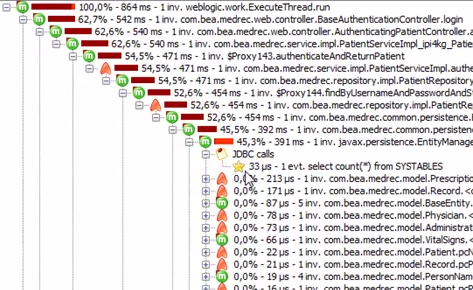
ceci est une pile d'appels pour le temps d'exécution:
Et c'est le même, mais en montrant de la latence du réseau:
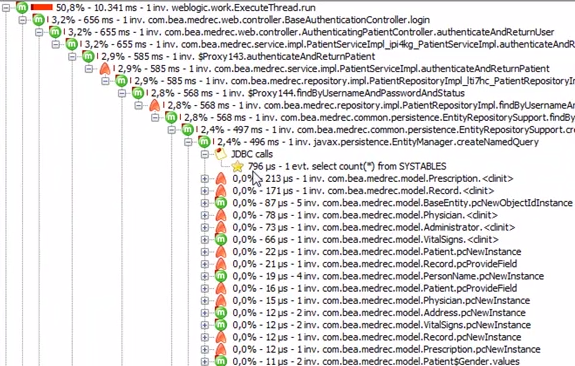
Quand vous savez bloque, j'espère que le chemin vers la résolution sera plus clair.
nous avons eu le même problème, avec Java 1.7.0_u101 (une des versions prises en charge par Oracle, puisque la dernière version publique JDK/JRE 7 est 1.7.0_u79), fonctionnant sur collecteur d'ordures G1. Je ne peux pas dire si le problème apparaît dans D'autres versions de Java 7 ou avec d'autres GCs.
notre procédé était Tomcat running Liferay Portal (je crois que la version exacte de Liferay n'est pas d'intérêt ici).
c'est le comportement que nous avons observé: en utilisant a-Xmx de 5 Go, la taille du pool de Cache du Code inital est bonne après le démarrage a varié à environ 40MB. Après un certain temps, il est tombé à environ 30 Mo (ce qui est un peu normal, car il y a beaucoup de code qui tourne au démarrage et qui ne sera plus jamais exécuté, donc on s'attend à ce qu'il soit expulsé du cache après un certain temps). Nous avons observé qu'il y avait une certaine activité JIT, de sorte que la JIT a réellement peuplé le cache (en comparant aux tailles que je mentionne plus tard, il semble que la petite taille du cache par rapport à la taille globale du tas place des exigences strictes sur la JIT, et cela fait que ces derniers expulsent la cache avec nervosité). Cependant, au bout d'un certain temps, les compilations n'ont plus jamais eu lieu, et la JVM est devenue douloureusement lente. Nous avons dû tuer nos Tomcats de temps en temps pour obtenir une performance adéquate, et comme nous avons ajouté plus de code à notre portail, le problème a empiré (depuis le Cache de Code est devenu saturé plus rapidement, je suppose).
Il semble qu'il y a plusieurs bugs dans le JDK 7 JVM qui en sont la cause de ne pas redémarrer le JIT (regardez ce post de blog: https://blogs.oracle.com/poonam/entry/why_do_i_get_message), même en JDK 7, après une chasse d'urgence (le blog mentionne les bogues Java 8006952, 8012547, 8020151 et 8029091).
c'est pourquoi augmenter manuellement le Cache de Code à un niveau où un flush d'urgence est peu susceptible de se produire "corrige" le problème (je suppose que c'est le cas avec JDK 7).
dans notre cas, au lieu d'essayer d'ajuster la taille du cache de code, nous avons choisi de passer à Java 8. Cela semble ont résolu le problème. De plus, le Cache de Code semble maintenant être beaucoup plus grand (la taille de démarrage est d'environ 200 Mo, et la taille de croisière est d'environ 160 Mo). Comme il est prévu, après un certain temps de ralenti, la taille du pool de cache baisse, pour se réveiller à nouveau si un utilisateur (ou un robot, ou autre) parcourt notre site, provoquant plus de code à exécuter.
j'espère que vous trouverez ci-dessus des données utiles.
oublié de dire: j'ai trouvé l'exposition, les données à l'appui, la logique d'infering et la conclusion de ce post très, très utile. Merci, vraiment!
quelqu'un A une idée où chercher?
la question pourrait être hors de Tomcat / JVM - avez-vous un travail par lot qui s'enclenche et qui met l'accent sur la ressource(s) partagée (s) comme une base de données commune?
prenez un thread dump et voyez ce que les processus java font quand le temps de réponse de l'application explose?
Si vous utilisez Linux, utilisez un outil comme strace et vérifiez ce qu'est le processus java faire.
avez-vous vérifié JVM GC times? Certains algorithmes GC peuvent "interrompre" les threads de l'application et augmenter le temps de réponse.
Vous pouvez utiliser jstat utilitaire pour surveiller la collecte des ordures statistiques:
jstat -gcutil <pid of tomcat> 1000 100
la commande ci-dessus imprimerait des statistiques GC toutes les 1 seconde pendant 100 fois. Regardez les colonnes CGF/CGY, si le nombre continue à augmenter, il y a quelque chose qui ne va pas avec vos options de GC.
vous pourriez vouloir passer à CMS GC si vous voulez garder le temps de réponse faible:
-XX:+UseConcMarkSweepGC
vous pouvez vérifier plus d'options de GC ici.
que se passe-t-il après que votre application fonctionne lentement pendant un certain temps, est-ce que cela revient à bien fonctionner? Si c'est le cas, je vérifierais s'il y a une activité qui n'est pas liée à votre application qui a lieu en ce moment. Quelque chose comme un scanner antivirus ou une sauvegarde système/db.
si ce n'est pas le cas, je suggère de l'exécuter avec un profileur (JProfiler, yourkit, etc.) ces outils peuvent vous indiquer vos points chauds très facilement.
vous utilisez du Quartz, qui gère les processus chronométrés, et cela semble se produire à des moments précis.
affichez votre horaire de Quartz et faites-nous savoir si cela s'aligne, et si oui, vous pouvez déterminer quel processus de demande interne pourrait être en train de démarrer pour consommer vos ressources.
alternativement, il est possible qu'une partie de votre code d'application ait finalement été activée et décide de charger des données dans la mémoire cache. Vous utilisez Hibernate; vérifiez les appels à votre base de données et voir si tout coïncide.