Que sont les coroutines en C++20?
que sont les coroutines dans c++20 ?
en quoi diffère-t-il de" Parallelism2 "ou/et" Concurrency2 " (voir image ci-dessous)?
l'image ci-dessous est de ISOCPP.
https://isocpp.org/files/img/wg21-timeline-2017-03.png
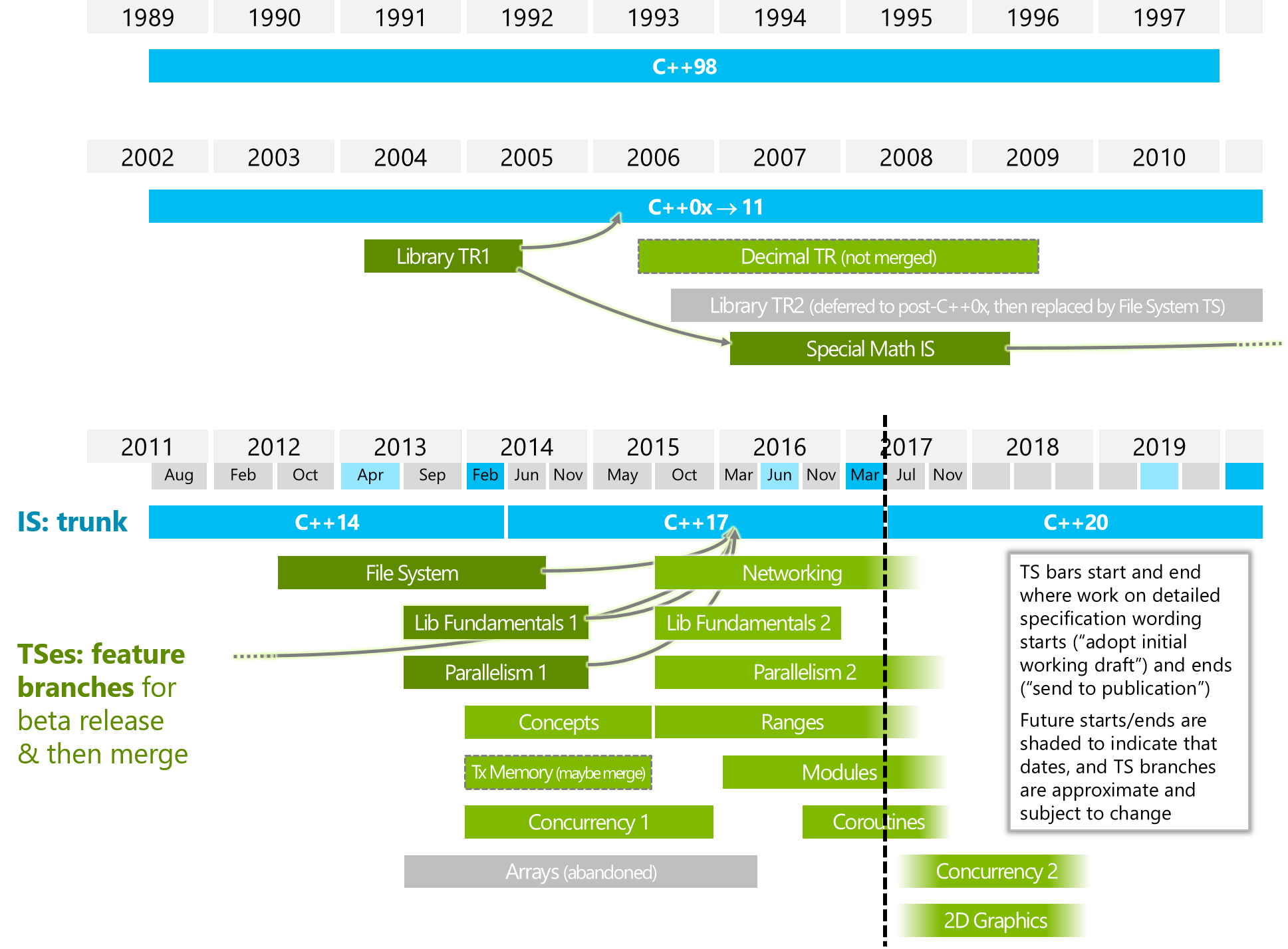{kind=link}
3 réponses
À un niveau abstrait, Coroutines split l'idée d'une exécution à l'état off à l'idée d'avoir un thread d'exécution.
SIMD (single instruction multiple data) a plusieurs "threads of execution" mais un seul État d'exécution (il ne fonctionne que sur plusieurs données). Sans doute des algorithmes parallèles sont un peu comme cela, en ce que vous avez un "programme" courir sur des données différentes.
"1519260920 Threading" a plusieurs "threads d'exécution" et plusieurs États d'exécution. Vous avez plus d'un programme, et plus d'un fil d'exécution.Coroutines a plusieurs États d'exécution, mais ne possède pas de fil d'exécution. Vous avez un programme, et le programme a l'état, mais il n'a pas l'exécution du thread.
l'exemple le plus facile de coroutines sont des générateurs ou des énumérables d'autres langues.
en pseudo code:
function Generator() {
for (i = 0 to 100)
produce i
}
le Generator est appelé, et la première fois qu'il est appelé il retourne 0 . Son état est rappelé (combien l'état varie avec la mise en œuvre des coroutines), et la prochaine fois que vous l'appelez il continue là où il s'est arrêté. Donc il retourne 1 La prochaine fois. Puis 2.
enfin il atteint la fin de la boucle et tombe de la fin de la fonction; la coroutine est terminée. (Ce qui se passe ici varie en fonction de la langue que nous parlons sur; en python, il déclenche une exception).
Coroutines apportent cette capacité à C++.
il y a deux sortes de coroutines: empilées et sans empilements.
Un stackless coroutine stocke uniquement les variables locales dans son état et son lieu d'exécution.
une corotine empilée stocke une pile entière (comme un fil).
coroutines Stackless peut être extrêmement léger. La dernière proposition que j'ai lu concernait essentiellement réécrire votre fonction en quelque chose un peu comme une lambda; toutes les variables locales vont dans l'état d'un objet, et les étiquettes sont utilisées pour sauter à/de l'endroit où la coroutine "produit" des résultats intermédiaires.
le processus de production d'une valeur est appelé" yield", car les coroutines sont un peu comme des multithreading coopératives; vous rendez le point d'exécution à l'appelant.
Boost a un implementaiton de stackful coroutines; il vous permet d'appeler une fonction de rendement pour vous. Les coroutines empilées sont plus puissantes, mais aussi plus chères.
il y a plus à coroutines qu'un simple générateur. Vous pouvez attendre une coroutine dans une coroutine, qui vous permet de composer des coroutines de manière utile.
Coroutines, comme si, boucles et appels de fonction, sont un autre type de "goto structuré" qui vous permet d'exprimer certaines caractéristiques utiles (comme les machines d'état) d'une façon plus naturelle.
l'implémentation spécifique des Coroutines en C++ est un peu intéressante.
à son niveau le plus élémentaire, il ajoute quelques mots clés à C++: co_return co_await co_yield , avec certains types de bibliothèques qui travaillent avec eux.
Une fonction devient une coroutine en ayant un de ces dans son corps. Donc, à partir de leur déclaration il est impossible de les distinguer des fonctions.
lorsque l'un de ces trois mots clés est utilisé dans un corps de fonction, un examen obligatoire standard du type de retour et des arguments se produit et la fonction est transformée en une coroutine. Cet examen indique au compilateur où stocker la fonction de l'état lorsque la fonction est suspendue.
la plus simple coroutine est un générateur:
generator<int> get_integers( int start=0, int step=1 ) {
for (int current=start; current+= step)
co_yield current;
}
co_yield suspend l'exécution des fonctions, stocke l'état dans le generator<int> , puis renvoie la valeur de current par le generator<int> .
vous pouvez faire une boucle sur les entiers retournés.
co_await en attendant, vous permet de coller une coroutine sur une autre. Si vous êtes dans une coroutine et vous avez besoin des résultats d'une chose awaitable (souvent une coroutine) avant de progresser, vous co_await sur elle. Si ils sont prêts, vous procéder immédiatement; si non, vous suspendez jusqu'à ce que l'attendu que vous attendez soit prêt.
std::future<std::expected<std::string>> load_data( std::string resource )
{
auto handle = co_await open_resouce(resource);
while( auto line = co_await read_line(handle)) {
if (std::optional<std::string> r = parse_data_from_line( line ))
co_return *r;
}
co_return std::unexpected( resource_lacks_data(resource) );
}
load_data est une coroutine qui génère un std::future lorsque la ressource nommée est ouverte et que nous parvenons à analyser au point où nous avons trouvé les données demandées.
open_resource et read_line s sont probablement des coroutines syncynques qui ouvrent un fichier et en lisent les lignes. Le co_await relie l'état de suspension et prêt de load_data à leurs progrès.
C++ sont beaucoup plus flexibles que cela, car elles ont été implémentées comme un ensemble minimal de fonctionnalités linguistiques en plus des types d'espace utilisateur. Les types d'espace utilisateur définissent effectivement ce que co_return co_await et co_yield signifie -- j'ai vu des gens l'utiliser pour mettre en œuvre des expressions optionnelles monadiques telles qu'un co_await sur un optionnel vide propose automatiquement l'état vide à l'optionnel externe:
modified_optional<int> add( modified_optional<int> a, modified_optional<int> b ) {
return (co_await a) + (co_await b);
}
au lieu de
std::optional<int> add( std::optional<int> a, std::optional<int> b ) {
if (!a) return std::nullopt;
if (!b) return std::nullopt;
return *a + *b;
}
une coroutine est comme une fonction C qui a plusieurs instructions de retour et lorsqu'elle est appelée une 2ème fois ne commence pas l'exécution Au début de la fonction mais à la première instruction après le retour exécuté précédent. Cet emplacement d'exécution est sauvegardé avec toutes les variables automatiques qui vivraient sur la pile dans des fonctions non coroutine.
une précédente mise en œuvre expérimentale de coroutine de Microsoft a utilisé des piles copiées de sorte que vous pouvez même retourner de fonctions profondément imbriquées. Mais cette version a été rejetée par le comité C++. Vous pouvez obtenir cette implémentation par exemple avec la bibliothèque de fibres Boosts.
coroutines sont censés être (en C++) des fonctions qui sont en mesure d ' "attendre" qu'une autre routine se termine et de fournir tout ce qui est nécessaire pour la suspension, la pause, l'attente, la routine pour continuer. la caractéristique la plus intéressante pour les gens de C++ est que les coroutines ne prendraient idéalement pas d'espace de pile...C# peut déjà faire quelque chose comme ça avec wait and yield mais C++ pourrait devoir être reconstruit pour l'avoir.
concurrence est fortement axée sur la séparation des préoccupations si un problème est une tâche que le programme est censé remplir. cette séparation des préoccupations peut être réalisé par un certain nombre de moyens...généralement délégation de quelque sorte. l'idée de la simultanéité est qu'un certain nombre de processus pourraient fonctionner indépendamment (séparation des préoccupations) et qu'un "auditeur" dirigerait tout ce qui est produit par ces préoccupations séparées vers l'endroit où il est censé aller. c'est très dépendante d'une sorte de gestion asynchrone. Il y a un certain nombre de approches de la concurrence, y compris la programmation axée sur les aspects et d'autres. C # A l'opérateur 'delegate' qui fonctionne très bien.
le parallélisme ressemble à de la concurrence et peut être impliqué, mais il s'agit en fait d'une construction physique impliquant de nombreux processeurs organisés de façon plus ou moins parallèle avec un logiciel capable de diriger des portions de code vers différents processeurs où il sera exécuté et les résultats seront reçus de manière synchrone.