Algorithmes De Remplacement De Page De Mémoire Virtuelle
J'ai un projet où on me demande de développer une application pour simuler la performance des différents algorithmes de remplacement de page (avec une taille de jeu de travail variable et une période de stabilité). Mes résultats:
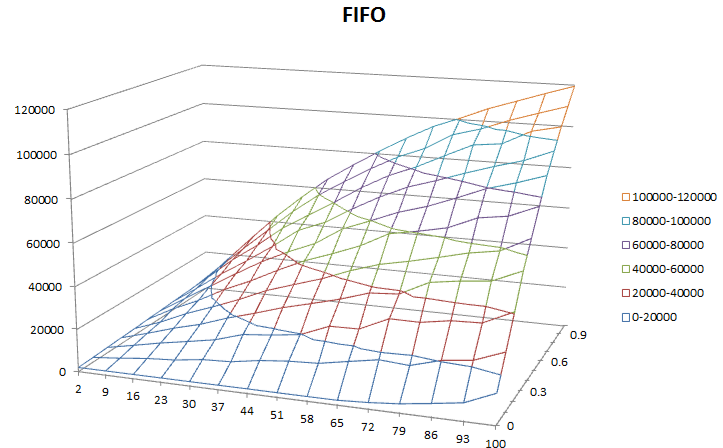
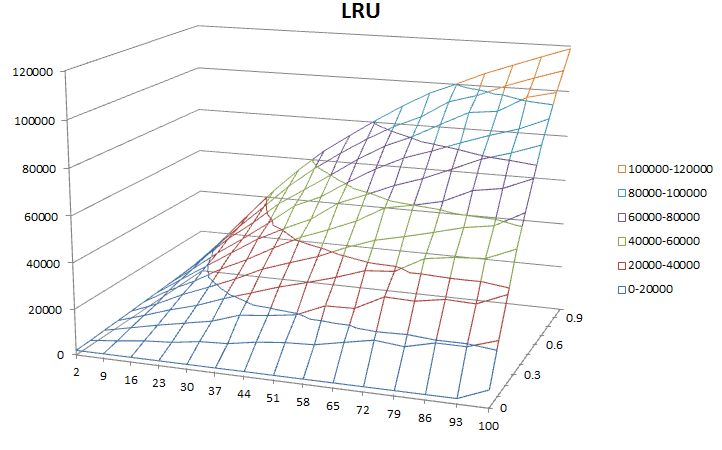
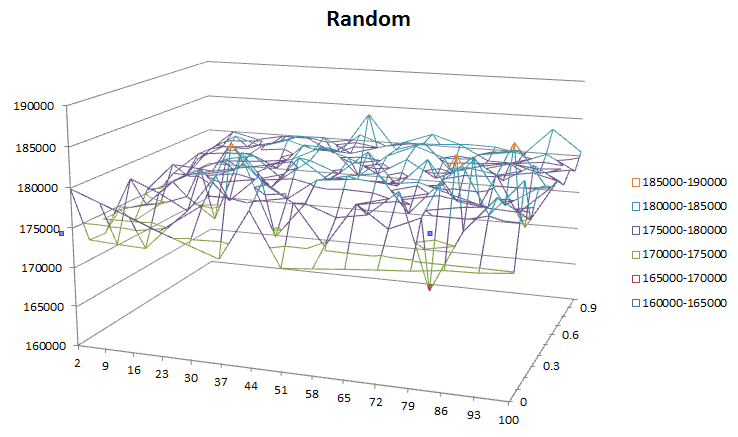
- axe Vertical: défauts de page
- axe Horizontal: ensemble de travail taille
- Profondeur axe: stable période
Mes résultats Sont-ils raisonnables? Je m'attendais à ce que LRU ait de meilleurs résultats que FIFO. Ici, ils sont à peu près les mêmes.
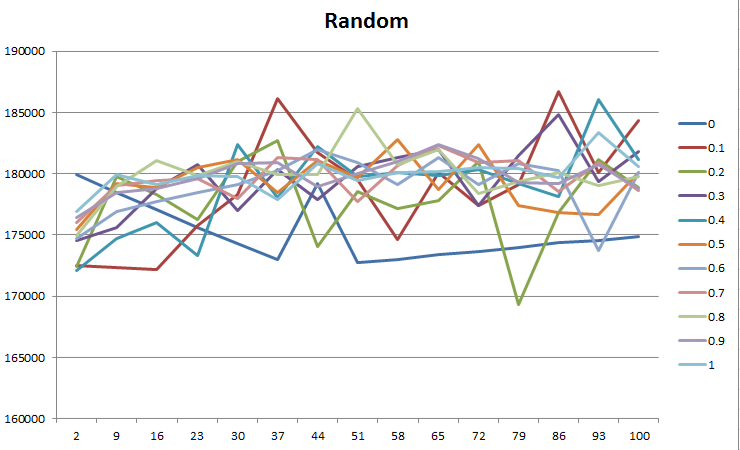
Pour aléatoire, la période de stabilité et la taille de l'ensemble de travail ne semblent pas affecter les performances du tout? Je m'attendais à des graphiques similaires comme FIFO et LRU juste pire performance? Si la chaîne de référence est très stable (petites branches) et a une petite taille de jeu de travail, elle devrait toujours avoir moins de défauts de page qu'une application avec beaucoup de branches et une grande taille de jeu de travail?
Plus D'Infos
Mon Code Python | La Question Du Projet
- Longueur de la chaîne de référence (RS): 200 000
- Taille de la mémoire virtuelle (P): 1000
- Taille de la mémoire principale (F): 100
- Nombre de pages référencées (m): 100
- Taille de travail ensemble (e): 2-100
- stabilité (t): 0-1
La Taille de l'ensemble de travail (e ) et la période stable (t) affectent la façon dont la chaîne de référence est générée.
|-----------|--------|------------------------------------|
0 p p+e P-1
Supposons donc ce qui précède la mémoire virtuelle de taille P. pour générer des chaînes de référence, l'algorithme suivant est utilisé:
- répéter jusqu'à ce que la chaîne de référence soit générée
- choisissez
mnombres dans [p,p + e].mSimule ou fait référence au nombre de fois où la page est référencée - choisir un nombre aléatoire, 0
- Si r
- générer un nouveau p
- else (++p)%p
- choisissez
Mise à jour (en réponse à la réponse de @MrGomez)
Cependant, rappelez-vous comment vous avez ensemencé vos données d'entrée: en utilisant aléatoire.aléatoire, vous donnant ainsi une distribution uniforme des données avec votre contrôlable au niveau de l'entropie. Pour cette raison, toutes les valeurs sont également susceptibles de se produire, et parce que vous avez construit cela dans l'espace à virgule flottante, les récidives sont hautement improbables.
J'utilise random, mais ce n'est pas totalement aléatoire non plus, les références sont générées avec une localité bien que l'utilisation de la taille de l'ensemble de travail et de la page nombre référencée les paramètres?
J'ai essayé d'augmenter le numPageReferenced relatif avec numFrames dans l'espoir qu'il référencera une page actuellement en mémoire plus, montrant ainsi l'avantage de performance de LRU sur FIFO, mais cela ne m'a pas donné un résultat clair tho. Juste pour info, j'ai essayé la même application avec les paramètres suivants (le ratio Pages/Frames est toujours le même, j'ai réduit la taille des données pour accélérer les choses).
--numReferences 1000 --numPages 100 --numFrames 10 --numPageReferenced 20
Le résultat est
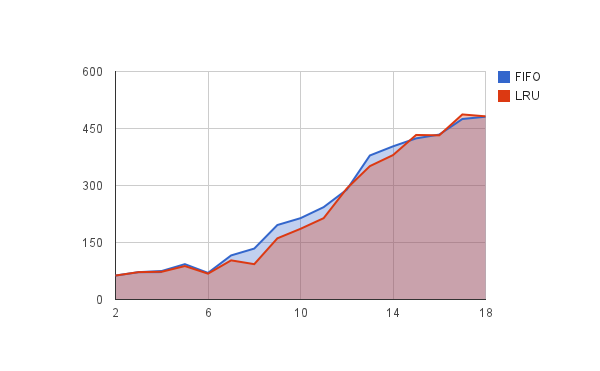
Toujours pas une si grande différence. Être J'ai raison de dire que si j'augmente numPageReferenced par rapport à numFrames, LRU devrait avoir une meilleure performance car il fait référence à des pages en mémoire plus? Ou peut-être que je comprends mal quelque chose?
Pour random, je pense dans le sens de:
- supposons qu'il y ait une grande stabilité et un petit ensemble de travail. Cela signifie que les pages référencées sont très susceptibles d'être en mémoire. Donc, la nécessité pour l'algorithme de remplacement de page à exécuter est plus faible?
Hmm peut-être que je dois y penser ce plus :)
Mise à jour: saccage moins évident sur une stabilité inférieure
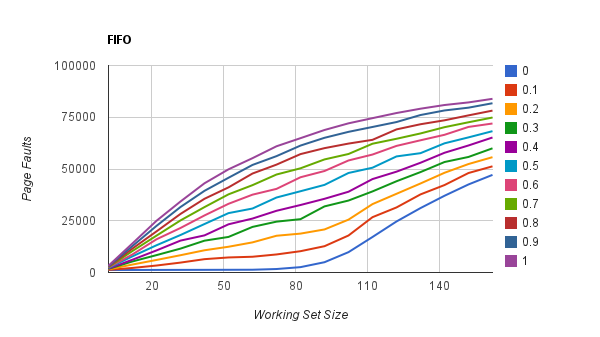
Ici, j'essaie de montrer le saccage car la taille de l'ensemble de travail dépasse le nombre d'images (100) en mémoire. Cependant, le battement de préavis semble moins évident avec une stabilité plus faible (high t), pourquoi cela pourrait-il être? L'explication est-elle que, à mesure que la stabilité devient faible, les défauts de page approchent le maximum, peu importe la taille de l'ensemble de travail?
1 réponses
Ces résultats sont raisonnables compte tenu de votre mise en œuvre actuelle. les raisons qui sous-tendent cela, cependant, mérite une discussion.
Lorsque l'on considère les algorithmes en général, il est très important de considérer les propriétés des algorithmes actuellement en cours d'inspection. Plus précisément, notez leur cas d'angle et les meilleures et les pires conditions. Vous êtes probablement déjà familier avec cette méthode laconique d'évaluation, donc c'est surtout pour le bénéfice de ceux qui lisent ici qui ne peuvent pas avoir un fond algorithmique.
Décomposons votre question par algorithme et explorons leurs propriétés de composants dans leur contexte:
-
FIFO affiche une augmentation des défauts de page à mesure que la taille de votre ensemble de travail (axe de longueur) augmente.
C'est un comportement correct, cohérent avec l'anomalie de Bélády pour le remplacement de FIFO. Comme la taille de votre jeu de pages de travail augmente, le nombre de défauts de page devrait également augmenter.
-
FIFO montre une augmentation des défauts de page comme la stabilité du système (axe 1 - Profondeur) diminue .
En notant votre algorithme pour l'ensemencement de la stabilité (
if random.random() < stability), vos résultats deviennent moins stables à mesure que la stabilité (S ) approche 1. Lorsque vous augmentez fortement l'entropie dans vos données, le nombre de défauts de page augmente également fortement et propage l'anomalie de Bélády.Jusqu'à présent, donc Bien.
-
LRU montre la cohérence avec FIFO. Pourquoi?
Notez votre algorithme d'ensemencement. norme LRU est le plus optimal lorsque vous avez des demandes de pagination structurées en trames opérationnelles plus petites. Pour les recherches ordonnées et prévisibles, il améliore FIFO en vieillissant les résultats qui n'existent plus dans le cadre d'exécution actuel, qui est une propriété très utile pour l'exécution par étapes et l'opération modale encapsulée. Encore une fois, de sorte ici, tout va bien.
Cependant, rappelez-vous comment vous avez ensemencé vos données d'entrée: en utilisant
random.random, vous donnant ainsi un distribution uniforme de données avec votre niveau d'entropie contrôlable. Pour cette raison, toutes les valeurs sont également susceptibles de se produire, et parce que vous l'avez construit dans espace à virgule flottante, les récurrences sont hautement improbables.Par conséquent, votre LRU perçoit chaque élément comme se produisant un petit nombre de fois, puis comme étant complètement ignoré lorsque la valeur suivante a été calculée. Il pagine donc correctement chaque valeur lorsqu'elle tombe hors de la fenêtre, vous donnant des performances exactement comparables à FIFO. Si votre système tenait correctement compte de la récurrence ou d'un espace de caractères compressé, vous verriez des résultats nettement différents.
-
Pour random, la période de stabilité et la taille de l'ensemble de travail ne semblent pas du tout affecter les performances. Pourquoi voyons - nous ce gribouillage sur tout le graphique au lieu de nous donner un relativement collecteur lisse ?
Dans le cas d'un schéma de pagination aléatoire, vous vieillissez hors de chaque entrée stochastique. Soi-disant, cela devrait nous donner une forme de collecteur lié à l'entropie et à la taille de notre ensemble de travail... droit?
Ou devrait-il? Pour chaque ensemble d'entrées, vous attribuez aléatoirement un sous-ensemble à la page en fonction du temps. Cela devrait donner des performances de pagination relativement égales, indépendamment de la stabilité et indépendamment de votre ensemble de travail, comme longtemps que votre profil d'accès est à nouveau uniformément aléatoire.
Donc, en fonction des conditions que vous vérifiez, c'est un comportement tout à fait correct compatible avec ce que nous attendons de. Vous obtenez une performance de pagination uniforme qui ne se dégrade pas avec d'autres facteurs (mais, inversement, n'est pas améliorée par eux) qui convient à une charge élevée, un fonctionnement efficace. Pas mal, mais pas ce à quoi vous pourriez vous attendre intuitivement.
Donc, en un mot, c'est la panne que votre projet est actuellement appliquée.
Comme un exercice pour explorer davantage les propriétés de ces algorithmes dans le contexte de différentes dispositions et distributions de données d'entrée, je recommande fortement de creuser dans scipy.stats pour voir ce que, par exemple, une distribution gaussienne ou logistique pourrait faire à chaque graphique. Ensuite, je reviendrais à les attentes documentées de chaque algorithme et les projets de cas où chacun est unique le plus et le moins approprié.
Dans l'ensemble, je pensez que votre professeur sera fier. :)