En utilisant Pentaho Kettle, comment charger plusieurs tables à partir d'une seule table tout en conservant l'intégrité référentielle?
Besoin de charger les données d'un seul fichier avec plus de 100 000 enregistrements dans plusieurs tables sur MySQL en maintenant les relations définies dans le fichier/les tables; ce qui signifie que les relations correspondent déjà. La solution devrait fonctionner sur la dernière version de MySQL, et doit utiliser le moteur InnoDB; MyISAM ne prend pas en charge les clés étrangères.
Je suis complètement nouveau à utiliser Pentaho Data Integration (aka Kettle) et tous les pointeurs seraient appréciés.
Je pourrais ajouter que c'est une exigence que les contraintes de clé étrangère ne sont pas désactivées. Comme je comprends que s'il y a quelque chose de mal avec l'intégrité référentielle de la base de données, MySQL ne vérifiera pas l'intégrité référentielle lorsque les contraintes de clé étrangère sont rallumées. SOURCE: 5.1.4. Variables système du serveur -- foreign_key_checks
Toutes les approches devraient inclure une partie de la validation et une stratégie de restauration si un insert échoue ou ne parvient pas à maintenir le référentiel intégrité.
Encore une fois, complètement nouveau à cela, et faire de mon mieux pour fournir autant d'informations que possible, si vous avez des questions, ou une demande de clarification -- faites-le moi savoir.
Si vous êtes capable de poster le XML à partir des fichiers kjb et ktr (jobs/transformations) ce serait SUPER. Peut-être même traquer tous les commentaires / réponses que vous avez tous faits n'importe où et les voter... :-) ...vraiment, il est vraiment important pour moi de trouver une réponse à ce.
Merci!
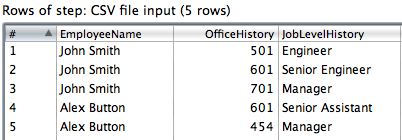
Exemple de données: pour mieux élaborer avec un exemple, supposons que j'essaie de charger un fichier contenant le nom de l'employé, les bureaux qu'ils ont occupés dans le passé et leur historique de titre de poste séparés par un onglet.
Fichier:
EmployeeName<tab>OfficeHistory<tab>JobLevelHistory
John Smith<tab>501<tab>Engineer
John Smith<tab>601<tab>Senior Engineer
John Smith<tab>701<tab>Manager
Alex Button<tab>601<tab>Senior Assistant
Alex Button<tab>454<tab>Manager
NOTE: La base de données de table unique est complètement normalisée (autant qu'une seule table peut l'être) - et par exemple, dans le cas de "John Smith" il n'y a Qu'un seul John Smith; ce qui signifie qu'il n'y a pas doublons qui conduiraient à des conflits dans l'intégrité référentielle.
Le schéma de base de données MyOffice comporte les tables suivantes:
Employee (nId, name)
Office (nId, number)
JobTitle (nId, titleName)
Employee2Office (nEmpID, nOfficeId)
Employee2JobTitle (nEmpId, nJobTitleID)
Donc dans ce cas. les tableaux devraient ressembler à:
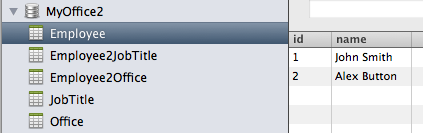
Employee
1 John Smith
2 Alex Button
Office
1 501
2 601
3 701
4 454
JobTitle
1 Engineer
2 Senior Engineer
3 Manager
4 Senior Assistant
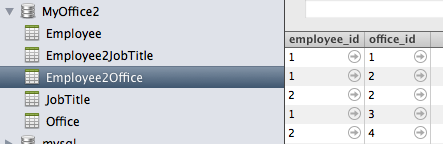
Employee2Office
1 1
1 2
1 3
2 2
2 4
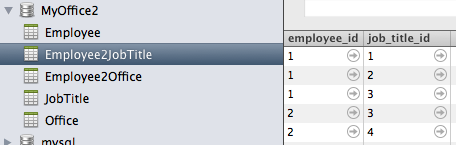
Employee2JobTitle
1 1
1 2
1 3
2 4
2 3
Voici le DDL MySQL pour créer la base de données et les tables:
create database MyOffice2;
use MyOffice2;
CREATE TABLE Employee (
id MEDIUMINT NOT NULL AUTO_INCREMENT,
name CHAR(50) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB;
CREATE TABLE Office (
id MEDIUMINT NOT NULL AUTO_INCREMENT,
office_number INT NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB;
CREATE TABLE JobTitle (
id MEDIUMINT NOT NULL AUTO_INCREMENT,
title CHAR(30) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB;
CREATE TABLE Employee2JobTitle (
employee_id MEDIUMINT NOT NULL,
job_title_id MEDIUMINT NOT NULL,
FOREIGN KEY (employee_id) REFERENCES Employee(id),
FOREIGN KEY (job_title_id) REFERENCES JobTitle(id),
PRIMARY KEY (employee_id, job_title_id)
) ENGINE=InnoDB;
CREATE TABLE Employee2Office (
employee_id MEDIUMINT NOT NULL,
office_id MEDIUMINT NOT NULL,
FOREIGN KEY (employee_id) REFERENCES Employee(id),
FOREIGN KEY (office_id) REFERENCES Office(id),
PRIMARY KEY (employee_id, office_id)
) ENGINE=InnoDB;
Mes Notes en réponse à la réponse sélectionnée:
PRÉPARATION:
- (A) utilisez les exemples de données, créez un fichier CSV en changeant
<TAB>en virgule délimiter. - (B) installez MySQL et créez un exemple de base de données à L'aide de L'exemple MySQL DDL
- (C) installer Kettle (il est basé sur Java et fonctionnera sur tout ce qui fonctionne Java)
- (D) télécharger le fichier KTR
Flux de données par Étape: (Mes Notes)
- ouvrez le fichier KTR dans Kettle et double-cliquez sur "Entrée de fichier CSV" et accédez au fichier CSV que vous avez créé. Le délimiteur doit déjà être défini sur virgule. Puis cliquez sur OK.
- double-cliquez "Insérer des employés" et sélectionnez DB connector puis suivez ces instructions sur création d'une nouvelle connexion à la base de données
1 réponses
J'ai mis en place un exemple de transformation (clic droit et choisissez Enregistrer le lien) en fonction de ce que vous avez fourni. La seule étape sur laquelle je me sens un peu incertain est la dernière entrée de la table. J'écris essentiellement les données de jointure dans la table et les laisse échouer si une relation spécifique existe déjà.
Remarque:
Cette solution ne répond pas vraiment à La " toutes les approches devraient inclure une partie de la validation et une stratégie de restauration si un insert échoue ou ne parvient pas à maintenir intégrité référentielle."critères, même si cela n'échouera probablement pas. Si vous voulez vraiment configurer quelque chose de complexe, nous pouvons le faire, mais cela devrait certainement vous aider à réaliser ces transformations.
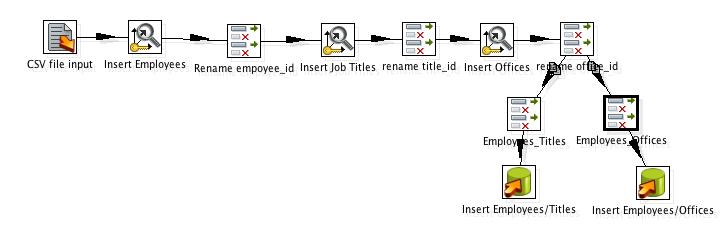
Flux de données par étape
1.{[22] } nous commençons par lire dans votre dossier. Dans mon cas, je l'ai converti en CSV mais tab est très bien aussi.
2.{[22] } maintenant, nous allons insérer les noms des employés dans la table des employés en utilisant un combination lookup/update.
Après l'insertion, nous ajoutons le employee_id à notre flux de données comme id et supprimer le EmployeeName du flux de données.
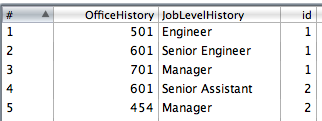
3. Ici, nous utilisons simplement une étape Select Values pour renommer le champ id en employee_id

4. insérez les titres de travail comme nous l'avons fait pour les employés et ajoutez l'id de titre à notre flux de données en supprimant également le JobLevelHistory du flux de données.
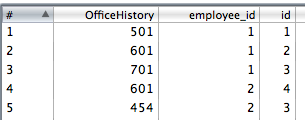
5. renommer simplement l'id de titre en title_id(voir étape 3)
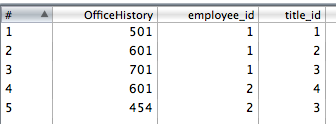
6. insérez des bureaux, obtenez des id, supprimez OfficeHistory du flux.

7. renommer simplement l'ID office en office_id (voir étape 3)
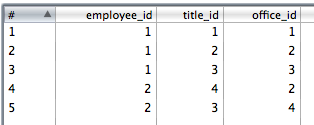
8. Copiez les données de la dernière étape dans deux flux avec les valeurs employee_id,office_id et employee_id,title_id respectivement.

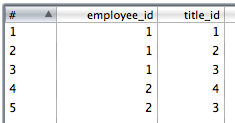
9. utilisez un insert de table pour insérer les données de jointure. Je l'ai sélectionné pour ignorer les erreurs d'insertion comme il pourrait le faire être doublons et les contraintes PK feront échouer certaines lignes.
Tableaux De Sortie