Utiliser opencv pour faire correspondre une image d'un groupe d'images à des fins d'identification en C++
EDIT: j'ai acquis assez de réputation par ce post pour être en mesure de l'éditer avec plus de liens, ce qui m'aidera à obtenir mon point à travers mieux
les gens qui jouent à la reliure d'isaac rencontrent souvent des objets importants sur de petits piédestaux.
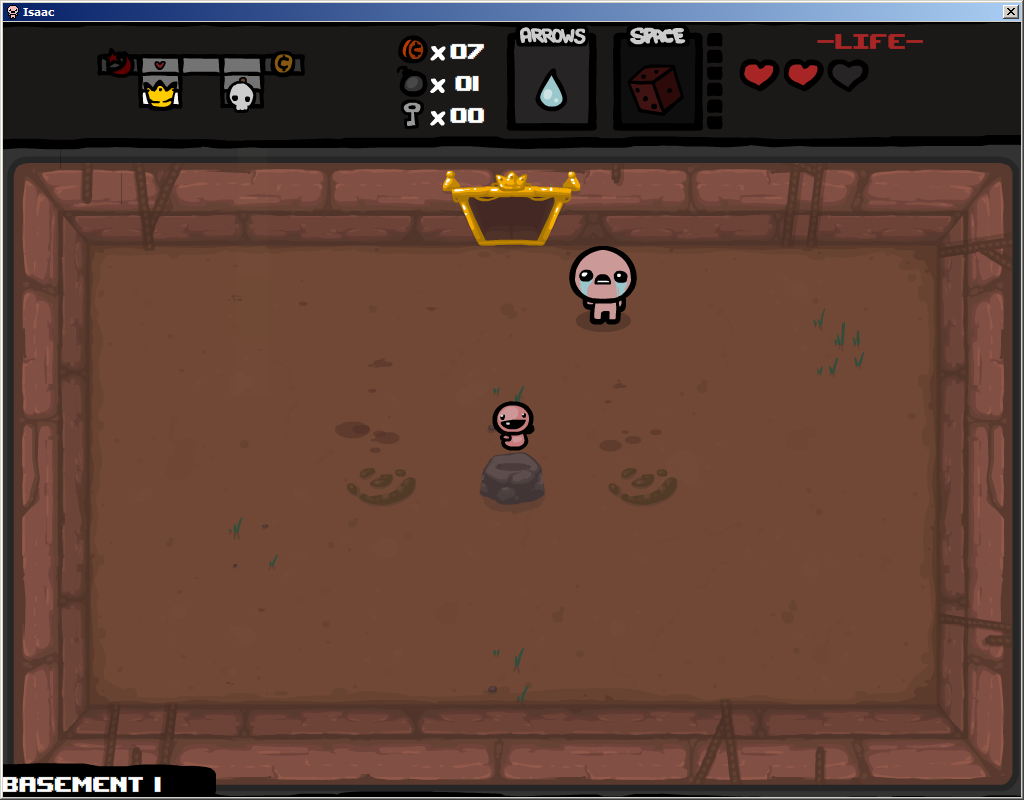
le but est d'avoir un utilisateur confus sur ce qu'un élément est capable d'appuyer sur un bouton qui lui demandera ensuite de "boxer" l'élément(pensez à la boxe Windows desktop). La boîte donne nous la région d'intérêt(le élément réel plus un certain environnement de base) pour comparer à ce qui sera une grille complète d'éléments.
élément théorique encadré
image description here" src="/images/content/14743389/bfbf5fc0f49fac531f87e31ce9aa2a71.png">
grille théorique des éléments(il n'y en a pas beaucoup plus, je viens de l'arracher de la reliure d'isaac wiki)

L'emplacement de la grille d'éléments identifiés comme l'élément de l'utilisateur boîte représenterait une certaine zone sur l'image qui correspond à un lien pour le binding of isaac wiki en donnant des informations sur l'élément.
dans la grille, l'article est la première colonne de la troisième ligne. J'utilise ces deux images de toutes les choses que j'ai essayé ci-dessous
mon but est de créer un programme qui peut prendre une récolte manuelle d'un élément du jeu "The Binding of Isaac", identifier l'élément recadré en comparant l'image à une image d'une table d'éléments dans le jeu, puis afficher la page wiki appropriée.
Ce serait mon premier "vrai projet" dans le sens où il exige une énorme quantité d'apprentissage de bibliothèque pour obtenir ce que je veux faire. Ça a été un peu écrasante.
j'ai testé avec quelques options tout de googler autour. (vous pouvez trouver rapidement les tutoriels que j'ai utilisé en recherchant le nom de la méthode et opencv. mon compte est fortement limité avec lien affichage pour une certaine raison)
à l'aide de bruteforcematcher:
http://docs.opencv.org/doc/tutorials/features2d/feature_description/feature_description.html
#include <stdio.h>
#include <iostream>
#include "opencv2/core/core.hpp"
#include <opencv2/legacy/legacy.hpp>
#include <opencv2/nonfree/features2d.hpp>
#include "opencv2/highgui/highgui.hpp"
using namespace cv;
void readme();
/** @function main */
int main( int argc, char** argv )
{
if( argc != 3 )
{ return -1; }
Mat img_1 = imread( argv[1], CV_LOAD_IMAGE_GRAYSCALE );
Mat img_2 = imread( argv[2], CV_LOAD_IMAGE_GRAYSCALE );
if( !img_1.data || !img_2.data )
{ return -1; }
//-- Step 1: Detect the keypoints using SURF Detector
int minHessian = 400;
SurfFeatureDetector detector( minHessian );
std::vector<KeyPoint> keypoints_1, keypoints_2;
detector.detect( img_1, keypoints_1 );
detector.detect( img_2, keypoints_2 );
//-- Step 2: Calculate descriptors (feature vectors)
SurfDescriptorExtractor extractor;
Mat descriptors_1, descriptors_2;
extractor.compute( img_1, keypoints_1, descriptors_1 );
extractor.compute( img_2, keypoints_2, descriptors_2 );
//-- Step 3: Matching descriptor vectors with a brute force matcher
BruteForceMatcher< L2<float> > matcher;
std::vector< DMatch > matches;
matcher.match( descriptors_1, descriptors_2, matches );
//-- Draw matches
Mat img_matches;
drawMatches( img_1, keypoints_1, img_2, keypoints_2, matches, img_matches );
//-- Show detected matches
imshow("Matches", img_matches );
waitKey(0);
return 0;
}
/** @function readme */
void readme()
{ std::cout << " Usage: ./SURF_descriptor <img1> <img2>" << std::endl; }

donne des résultats pas si utiles. Des résultats plus propres mais tout aussi peu fiables en utilisant flann.
http://docs.opencv.org/doc/tutorials/features2d/feature_flann_matcher/feature_flann_matcher.html
#include <stdio.h>
#include <iostream>
#include "opencv2/core/core.hpp"
#include <opencv2/legacy/legacy.hpp>
#include <opencv2/nonfree/features2d.hpp>
#include "opencv2/highgui/highgui.hpp"
using namespace cv;
void readme();
/** @function main */
int main( int argc, char** argv )
{
if( argc != 3 )
{ readme(); return -1; }
Mat img_1 = imread( argv[1], CV_LOAD_IMAGE_GRAYSCALE );
Mat img_2 = imread( argv[2], CV_LOAD_IMAGE_GRAYSCALE );
if( !img_1.data || !img_2.data )
{ std::cout<< " --(!) Error reading images " << std::endl; return -1; }
//-- Step 1: Detect the keypoints using SURF Detector
int minHessian = 400;
SurfFeatureDetector detector( minHessian );
std::vector<KeyPoint> keypoints_1, keypoints_2;
detector.detect( img_1, keypoints_1 );
detector.detect( img_2, keypoints_2 );
//-- Step 2: Calculate descriptors (feature vectors)
SurfDescriptorExtractor extractor;
Mat descriptors_1, descriptors_2;
extractor.compute( img_1, keypoints_1, descriptors_1 );
extractor.compute( img_2, keypoints_2, descriptors_2 );
//-- Step 3: Matching descriptor vectors using FLANN matcher
FlannBasedMatcher matcher;
std::vector< DMatch > matches;
matcher.match( descriptors_1, descriptors_2, matches );
double max_dist = 0; double min_dist = 100;
//-- Quick calculation of max and min distances between keypoints
for( int i = 0; i < descriptors_1.rows; i++ )
{ double dist = matches[i].distance;
if( dist < min_dist ) min_dist = dist;
if( dist > max_dist ) max_dist = dist;
}
printf("-- Max dist : %f n", max_dist );
printf("-- Min dist : %f n", min_dist );
//-- Draw only "good" matches (i.e. whose distance is less than 2*min_dist )
//-- PS.- radiusMatch can also be used here.
std::vector< DMatch > good_matches;
for( int i = 0; i < descriptors_1.rows; i++ )
{ if( matches[i].distance < 2*min_dist )
{ good_matches.push_back( matches[i]); }
}
//-- Draw only "good" matches
Mat img_matches;
drawMatches( img_1, keypoints_1, img_2, keypoints_2,
good_matches, img_matches, Scalar::all(-1), Scalar::all(-1),
vector<char>(), DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS );
//-- Show detected matches
imshow( "Good Matches", img_matches );
for( int i = 0; i < good_matches.size(); i++ )
{ printf( "-- Good Match [%d] Keypoint 1: %d -- Keypoint 2: %d n", i, good_matches[i].queryIdx, good_matches[i].trainIdx ); }
waitKey(0);
return 0;
}
/** @function readme */
void readme()
{ std::cout << " Usage: ./SURF_FlannMatcher <img1> <img2>" << std::endl; }

l'observation des Templiers a été ma meilleure méthode jusqu'à présent. du 6 méthodes, elle varie que de 0-4 identifications correctes bien.
http://docs.opencv.org/doc/tutorials/imgproc/histograms/template_matching/template_matching.html
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include <iostream>
#include <stdio.h>
using namespace std;
using namespace cv;
/// Global Variables
Mat img; Mat templ; Mat result;
char* image_window = "Source Image";
char* result_window = "Result window";
int match_method;
int max_Trackbar = 5;
/// Function Headers
void MatchingMethod( int, void* );
/** @function main */
int main( int argc, char** argv )
{
/// Load image and template
img = imread( argv[1], 1 );
templ = imread( argv[2], 1 );
/// Create windows
namedWindow( image_window, CV_WINDOW_AUTOSIZE );
namedWindow( result_window, CV_WINDOW_AUTOSIZE );
/// Create Trackbar
char* trackbar_label = "Method: n 0: SQDIFF n 1: SQDIFF NORMED n 2: TM CCORR n 3: TM CCORR NORMED n 4: TM COEFF n 5: TM COEFF NORMED";
createTrackbar( trackbar_label, image_window, &match_method, max_Trackbar, MatchingMethod );
MatchingMethod( 0, 0 );
waitKey(0);
return 0;
}
/**
* @function MatchingMethod
* @brief Trackbar callback
*/
void MatchingMethod( int, void* )
{
/// Source image to display
Mat img_display;
img.copyTo( img_display );
/// Create the result matrix
int result_cols = img.cols - templ.cols + 1;
int result_rows = img.rows - templ.rows + 1;
result.create( result_cols, result_rows, CV_32FC1 );
/// Do the Matching and Normalize
matchTemplate( img, templ, result, match_method );
normalize( result, result, 0, 1, NORM_MINMAX, -1, Mat() );
/// Localizing the best match with minMaxLoc
double minVal; double maxVal; Point minLoc; Point maxLoc;
Point matchLoc;
minMaxLoc( result, &minVal, &maxVal, &minLoc, &maxLoc, Mat() );
/// For SQDIFF and SQDIFF_NORMED, the best matches are lower values. For all the other methods, the higher the better
if( match_method == CV_TM_SQDIFF || match_method == CV_TM_SQDIFF_NORMED )
{ matchLoc = minLoc; }
else
{ matchLoc = maxLoc; }
/// Show me what you got
rectangle( img_display, matchLoc, Point( matchLoc.x + templ.cols , matchLoc.y + templ.rows ), Scalar::all(0), 2, 8, 0 );
rectangle( result, matchLoc, Point( matchLoc.x + templ.cols , matchLoc.y + templ.rows ), Scalar::all(0), 2, 8, 0 );
imshow( image_window, img_display );
imshow( result_window, result );
return;
}
http://imgur.com/pIRBPQM,h0wkqer,1JG0QY0,haLJzRF, CmrlTeL,DZuW73V#3
des 6 l'échec,pass,fail,passe,passe,passe
C'était une sorte de meilleur résultat de cas cependant. Le point suivant que j'ai essayé était
 et a abouti à l'échec,échec,échec,échec,échec,échec
et a abouti à l'échec,échec,échec,échec,échec,échec
à partir de un élément à l'ensemble de ces méthodes qui fonctionnent bien et d'autres qui ne terriblement
alors je me pose la question: Est-ce que templatematching est mon meilleur pari ou y a-t-il une méthode que je ne considère pas qui sera mon saint Graal?
Comment puis-je obtenir un utilisateur pour créer la récolte manuellement? La documentation d'Opencv sur ce sujet est vraiment mauvaise et les exemples que je trouve en ligne sont extrêmement vieux cpp ou c.
merci de votre aide. Cette entreprise a été une expérience intéressante à ce jour. J'ai eu à enlevez tous les liens qui montreraient mieux comment tout s'est passé, mais le site dit que je poste plus de 10 liens même si Je ne le suis pas.
quelques exemples des éléments tout au long du jeu:
la roche est un objet rare et l'un des rares qui peut être "n'importe où" sur l'écran. les articles comme la roche sont la raison pour laquelle le recadrage de l'article par l'utilisateur est la meilleure façon d'isoler l'article, sinon leurs positions ne sont que dans un couple des lieux spécifiques.
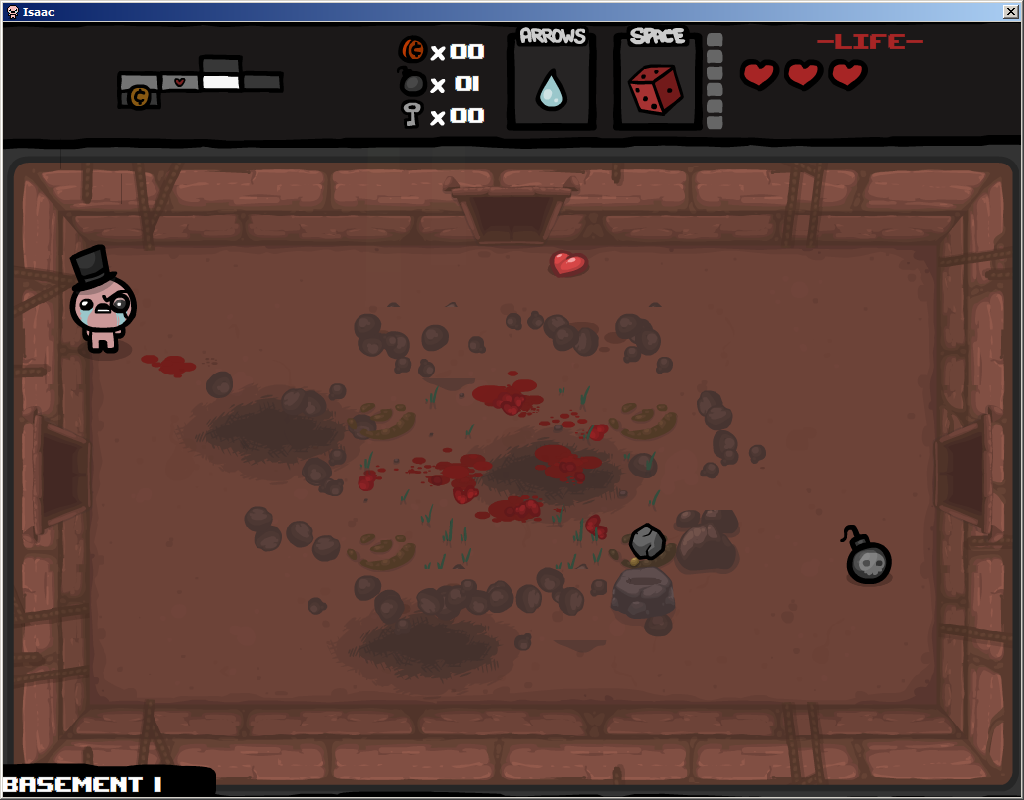

un objet après une bagarre de boss, beaucoup de choses partout et de la transparence au milieu. J'imagine que c'est l'un des plus durs pour fonctionner correctement
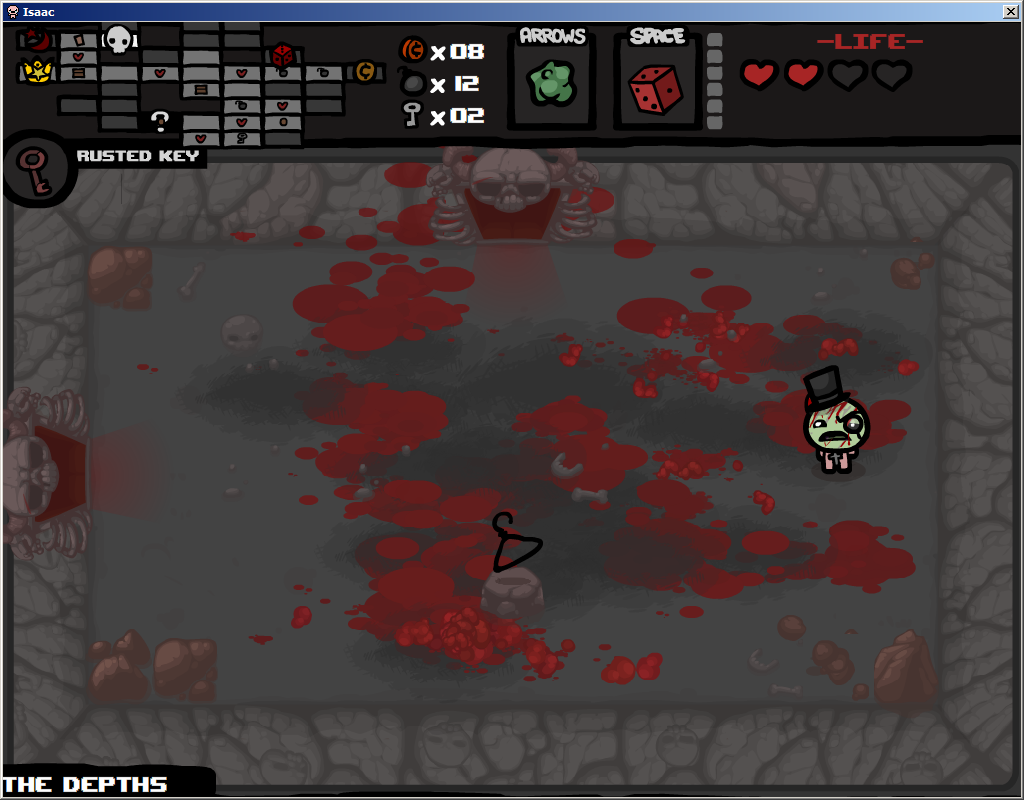

Rare pièce. arrière-plan simple. aucun article transparence.

voici les deux tables de tous les éléments dans le jeu.. Je finirai par en faire une image, mais pour l'instant, elles ont été prises directement sur le wiki d'isaac.


2 réponses
Un détail important ici est que vous avez l'image pure de chaque élément dans votre table. Vous connaissez la couleur de l'arrière-plan et peut détacher l'élément du reste de l'image. Par exemple, en plus de la matrice, représentant l'image elle-même, vous pouvez stocker matrice de 1-s et 0 - s de la même taille, où ceux correspondent à la zone de l'image et zéros-à l'arrière-plan. Appelons cette matrice " masque "et image pure de l'élément - "motif".
il y a 2 façons de comparer les images: l'image avec le modèle et correspond au motif avec l'image. Ce que vous avez décrit correspond à l'image avec le modèle - vous avez une certaine image recadrée et que vous voulez trouver le modèle similaire. Au lieu de cela, pensez à recherche de motif sur l'image.
commençons par définir la fonction match() qui prend, du masque et de l'image de la même taille et vérifie si la zone sur le patron sous le masque est exactement le même que dans l'image (pseudo-code):
def match(pattern, mask, image):
for x = 0 to pattern.width:
for y = 0 to pattern.height:
if mask[x, y] == 1 and # if in pattern this pixel is not part of background
pattern[x, y] != image[x, y]: # and pixels on pattern and image differ
return False
return True
mais les tailles des motifs et l'image recadrée peut différer. La solution Standard pour cela (utilisée, par exemple, dans le classificateur cascade) est d'utiliser fenêtre coulissante - il suffit de déplacer le motif "fenêtre" à travers l'image et de vérifier si le motif correspond à la région sélectionnée. C'est à peu près comme ça que fonctionne la détection d'image dans OpenCV.
bien sûr, cette solution n'est pas très robuste - recadrage, redimensionnement ou toute autre transformation d'image peut changer certains pixels, et dans ce cas la méthode match() retournera toujours false. Surmonter ceci, au lieu de la réponse booléenne vous pouvez utiliser distance entre l'image et le motif. Dans ce cas, la fonction match() doit retourner une valeur de similarité, disons, entre 0 et 1, où 1 signifie "exactement le même", tandis que 0 pour "complètement différent". Ensuite, vous pouvez soit définir le seuil de similitude (par exemple, l'image doit être au moins 85% similaire au modèle), ou tout simplement sélectionner le modèle avec la plus haute valeur de similitude.
puisque les éléments dans le jeu sont des images artificielles et leur variation est très faible, cette approche devrait être suffisant. Cependant, pour les cas plus compliqués, vous aurez besoin d'autres fonctionnalités que simplement des pixels sous le masque. Comme je l'ai déjà suggéré dans mon commentaire, des méthodes comme Eigenfaces, cascade classifier utilisant des caractéristiques de type Haar ou même des modèles D'apparence Active peuvent être plus efficaces pour ces tâches. En ce qui concerne le SURF, pour autant que je sache, il est mieux adapté pour les tâches avec un angle et une taille d'objet variables, mais pas pour les différents milieux et toutes ces choses.
je suis venu sur votre question en essayant de comprendre mon propre problème de correspondance de modèle, et maintenant je suis de retour pour partager ce que je pense pourrait être votre meilleur pari basé sur ma propre expérience. Tu as probablement abandonné ça depuis longtemps, mais quelqu'un d'autre pourrait être dans les mêmes chaussures un jour.
aucun des éléments que vous avez partagé n'est un rectangle solide, et depuis l'appariement des modèles dans opencv ne peut pas fonctionner avec un masque vous comparerez toujours votre image de référence avec ce que je doit supposer est au moins plusieurs arrière-plans différents (sans mentionner les éléments qui se trouvent dans des endroits variés sur des arrière-plans différents, ce qui rend le modèle de correspondance encore pire).
il sera toujours comparer les pixels de fond et confonds your match moins que vous pouvez collecter une culture de chaque situation où l'image de référence peut être trouvé. Si les décalques de sang/etc introduire encore plus de variabilité dans les milieux autour des éléments trop alors l'appariement des modèles ne donnera probablement pas de bons résultats.
donc les deux choses que j'essaierais si j'étais vous dépendent de quelques détails:
- Si possible, culture un modèle de référence de chaque situation où l'élément est trouvé (ce ne sera pas un bon moment), puis comparez la zone spécifiée par l'utilisateur avec chaque modèle de chaque élément. Prenez le meilleur résultat de ces comparaisons et vous aurez, Si vous avez de la chance, une correspondance correcte.
- le exemple les captures d'écran que vous avez partagées n'ont pas de lignes noires/noires sur l'arrière-plan,de sorte que les contours de tous les éléments se démarquent. Si c'est cohérent tout au long du jeu, vous pouvez trouver les bords à l'intérieur de l'utilisateur-zone spécifiée et détecter les contours extérieurs. Avant le temps, vous auriez traité les contours extérieurs de chaque élément de référence et stocké ces contours. Ensuite, vous pouvez comparer votre(s) contour (s) dans la récolte de l'utilisateur par rapport à chaque contour dans votre base de données, prendre le meilleur match comme réponse.
je suis sûr que l'un ou l'autre pourrait fonctionner pour vous, selon que le jeu est bien représenté par vos screenshots.
Remarque: Le contour correspondant sera beaucoup, beaucoup plus rapide que le modèle correspondant. Assez rapide pour fonctionner en temps réel et à nier la nécessité pour l'utilisateur de recadrer n'importe quoi, peut-être.