Utilisation de Mercurial dans une grande organisation
J'utilise Mercurial pour mes propres projets personnels depuis un moment, et je l'adore. Mon employeur envisage de passer de CVS à SVN, mais je me demande si Je ne devrais pas plutôt insister pour Mercurial (ou d'autres DVC).
Un ride avec Mercurial, est qu'il semble être conçu autour de l'idée d'avoir un référentiel unique par "projet". Dans cette organisation, il y a des douzaines d'exécutables, de DLLs et d'autres composants différents dans le CVS actuel. dépôt, hiérarchiquement organisé. Il y a beaucoup de composants génériques réutilisables, mais aussi certains composants spécifiques au client, et des configurations spécifiques au client. Les procédures de compilation actuelles permettent généralement de sortir un certain nombre de sous-zones du dépôt CVS.
si nous passons de CVS à Mercurial, Quelle est la meilleure façon d'organiser le dépôt/les dépôts? Devrions-nous avoir un énorme dépôt mercuriel contenant tout? Si ce n'est pas le cas, combien de grains fins le plus petit les référentiels? Je pense que les gens le trouveront très ennuyeux s'ils doivent tirer et pousser des mises à jour à partir de beaucoup d'endroits différents, mais ils le trouveront également ennuyeux s'ils doivent tirer/pousser l'ensemble de la base de données de l'entreprise.
Quelqu'un a de l'expérience avec ça, ou des conseils?
questions connexes:
3 réponses
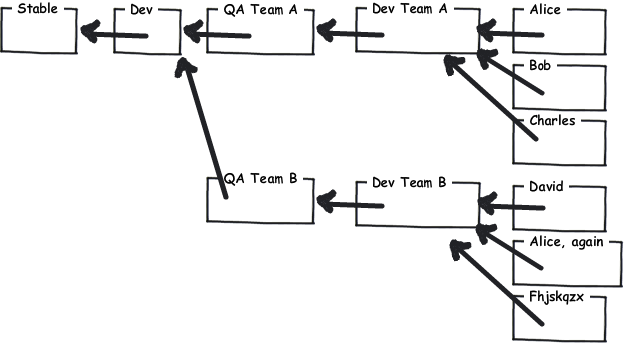
AFAICS la plupart des résistances aux DVCSes viennent de gens qui ne comprennent pas comment les utiliser. L'affirmation souvent répétée selon laquelle "il n'y a pas de dépôt central" est très effrayante pour les personnes qui ont été enfermées dans le modèle CVS/SVN depuis des temps immémoriaux et qui ne peuvent rien imaginer d'autre, particulièrement pour la direction et les développeurs principaux (expérimentés et/ou cyniques) qui veulent un suivi et une reproductibilité solides du code source (et peut-être aussi si vous devez satisfaire certains normes concernant vos processus de développement, comme nous l'avons fait à un endroit où j'ai travaillé). Eh bien, vous pouvez avoir un "bienheureux" repo central; vous n'êtes tout simplement pas enchaîné à elle. Il est facile pour un sous-groupe de mettre en place un repo de terrain de jeu interne sur l'un de leurs postes de travail pendant un certain temps, par exemple.
il y a tellement de façons de dépeindre le chat proverbial qu'il vous coûtera de vous asseoir et de réfléchir soigneusement à votre flux de travail. Pensez à vos pratiques actuelles et le pouvoir que presque libre le clonage et la ramification vous donne. Il est probable que certains de vos travaux actuels auront évolué pour contourner les limites du modèle de type CVS; soyez prêt à briser le moule. Vous aurez probablement besoin de nommer un ou deux champions pour faciliter la transition à tout le monde; avec une grande équipe, vous voudrez probablement penser à restreindre l'accès de commit à blessed .
à mon travail (petite entreprise de logiciels), nous sommes passés de CVS à hg et nous n'avons pas voulu y retourner. Nous l'utilisons principalement centralisée. Convertir notre principal (ancien et très grand) repo était douloureux, mais il sera de toute façon vous allez, et quand il est fait, il est fait - il sera beaucoup plus facile de changer VCS plus tard. (Nous avons trouvé un certain nombre de situations où les outils de conversion CVS ne peuvent tout simplement pas comprendre ce qui s'est passé; où le commit de quelqu'un n'a que partiellement réussi et ils n'ont pas remarqué pendant des jours; résoudre les branches du vendeur; la folie générale et la folie causée par le temps semblant revenir en arrière, pas aidé par commettre des horodateurs dans l'heure locale de fuseaux horaires différents...)
le grand avantage que j'ai trouvé d'un DVCS est la capacité de s'engager tôt et s'engager souvent et seulement pousser quand il est prêt. Au fur et à mesure que j'atteins les différentes étapes du travail en cours, j'aime poser une ligne dans le sable, de sorte que je puisse revenir en arrière si nécessaire-mais il ne s'agit pas d'engagements qui devraient être exposés à l'équipe, car ils sont manifestement incomplets à bien des égards. (Je le fais surtout avec des files d'attente impitoyables. Je n'aurais jamais pu faire ça avec CVS.
je suppose que vous le savez déjà, mais si vous envisagez de vous éloigner de CVS, vous pouvez faire tellement mieux que SVN...
au monolithe, ou au module? Tout changement de paradigme va être délicat, quel que soit le VCS avec lequel vous travaillez, distribué ou non; le modèle CVS est assez spécial dans la façon dont il vous permet de vous engager sur une base fichier par fichier sans vérifier si le reste de la mise à jour est à jour (et ne pas mentionner les maux de tête que les alias de module ont été connus pour causer).
- traiter avec des dépôts monolithiques peut être assez lent. Votre client vcs doit scanner votre copie de l'univers entier pour les changements, par opposition à un seul module. (Si vous travaillez sur Linux, regardez dans L'extension HG inotify si vous ne l'avez pas déjà fait.)
- un repo monolithique provoque aussi conditions de course inutiles lors de la Commission(poussée). C'est comme la vérification CVS mise à jour, mais appliquée à l'ensemble de la mise à jour: si vous avez beaucoup de développeurs actifs, commettant fréquemment, celui-ci va vous mordre.
je suggérerais qu'il vaut la peine de l'effort de rester à l'écart de monolithique, mais méfiez-vous qu'il imposera son propre overhead en termes de complexité ajoutée dans votre système de construction. (Note: si vous trouvez quelque chose de fatigant, automatisez-le! Nous, programmeurs sont paresseux créatures, après tout.) La division de votre dossier en plusieurs modules peut être trop extrême; il peut y avoir une maison de transition à trouver avec des composants connexes regroupés parmi un petit nombre de dépôts. Vous pouvez également trouver utile d'examiner le support du sous - module de mercurial - dépôts imbriqués et le extension de la forêt (tous deux que je devrais essayer d'obtenir ma tête autour).
à un ancien lieu de travail nous avions plusieurs douzaines de composants qui étaient conservés comme des modules CVS indépendants avec une structure assez régulée. Les composants ont déclaré ce dont ils dépendaient et quelles pièces construites devaient être exportées où; le système de construction a écrit automatiquement faire des fragments de sorte que ce que vous travailliez dessus ramasserait ce dont il avait besoin. Il fonctionnait généralement très bien et il était assez rare de ne pas réussir la vérification à jour du CVS. (Il y avait aussi un robot de construction incroyablement compliqué mais extrêmement puissant avec un attitude la moins exigeante à l'égard de la résolution de la dépendance: elle ne reconstruirait pas un composant s'il y en avait déjà un qui répond à vos besoins. Ajoutez à cela les méta-composants qui ont assemblé des installateurs et des images ISO entières, et vous avez une bonne recette pour les constructions début à fin facile et pour les choses allant apprentis sorciers. Quelqu'un devrait écrire un livre sur ce sujet...)
Divulgation: C'est un cross post à partir d'un autre thread qui a été porté autour de git, mais j'ai fini par recommander mercurial de toute façon. Il traite avec DVCS dans un contexte d'entreprise en général, donc j'espère que le cross posting il est très bien. Je l'ai un peu modifié pour mieux répondre à cette question:
à L'encontre de l'opinion commune, je pense que l'utilisation D'un DVCS est un choix idéal dans un contexte d'entreprise parce qu'il permet très des flux de travail flexibles. Je parlerai d'abord de L'utilisation d'un CVC ou D'un CVC, puis des pratiques exemplaires, puis de l'EIG en particulier.
DVCS vs CVC dans le contexte des entreprises:
Je ne parlerai pas ici des avantages et inconvénients généraux, mais plutôt de votre contexte. La conception commune est que l'utilisation d'un DVCS nécessite une équipe plus disciplinée que l'utilisation d'un système centralisé. C'est parce qu'un système centralisé qui vous fournit un moyen facile pour appliquer votre flux de travail, en utilisant un système décentralisé nécessite plus de communication et la discipline de s'en tenir aux conventions établies. Bien que cela puisse sembler induire des frais généraux, je vois des avantages dans la communication accrue nécessaire pour en faire un bon processus. Votre équipe devra communiquer sur le code, sur les changements et sur l'état d'avancement du projet en général.
une autre dimension dans le contexte de la discipline encourage les ramifications et les expériences. Voici une citation de Martin Fowlers récente entrée bliki sur les outils de contrôle de Version , il a trouvé une description très concise de ce phénomène.
DVCS encourage la ramification rapide pour expérimentation. Vous pouvez faire des branches dans Subversion, mais le fait qu'ils sont visibles à tous les décourage les gens de l'ouverture d'une branche pour le travail expérimental. De même, les DVCS encourage vérifier le pointage de travail: commettre incomplète des changements, peut même pas compiler ou passer des tests, à votre dépôt local. Encore une fois, vous pourriez faites ceci sur une branche de développeur dans Subversion, mais le fait que les branches sont dans l'espace partagé fait les personnes moins susceptibles de le faire.
DVCS permettent des flux de travail flexibles parce qu'ils fournissent le suivi des changements par des identificateurs uniques globalement dans un graphique acyclique dirigée (DAG) au lieu de texte simple diffs. Cela leur permet de suivre de manière transparente l'origine et l'histoire d'un ensemble de changements, ce qui peut être très important.
flux de travail:
Larry Osterman (un Microsoft dev travaillant sur L'équipe Windows) a un grand blog post sur le flux de travail qu'ils emploient à L'équipe Windows. Ils ont notamment:
- Un nettoyage de haute qualité seulement le code du tronc (master repo)
- tous les développements se produisent sur les branches caractéristiques
- les équipes spéciales ont des repos d'équipe
- ils fusionnent régulièrement les dernières modifications du tronc dans leur branche feature ( forward Integrate )
- caractéristiques Complètes doivent passer plusieurs postes de qualité, par exemple, l'examen, la couverture de test, Q&r (repos sur leur propre)
- si une caractéristique est terminée et a une qualité acceptable, il est fusionné dans le coffre ( "151990920 Inversée" Intégrer )
comme vous pouvez le voir, ayant chacun de ces dépôts vivent sur leur propre vous pouvez découpler différentes équipes avançant à des rythmes différents. En outre, la possibilité de mettre en œuvre un système flexible de gestion de la qualité distingue les DVCS des CVCS. Vous pouvez résoudre vos problèmes d'autorisation à ce niveau aussi. Seule une poignée de personnes devrait avoir accès au master repo. Pour chaque niveau de la hiérarchie, avoir un repo séparé avec les politiques d'accès correspondantes. En effet, cette approche peut être très souple au niveau de l'équipe. Vous devez laisser à chaque équipe pour décider s'ils veulent partager leur équipe de pensions entre eux ou si ils veulent un plus hiérarchique approche où seul le chef d'équipe peut s'engager à l'équipe des pensions.
(la photo a été volée dans de Joel Spolsky) hginit.com .)
une chose reste à dire à ce stade, même si les DVCS fournissent de grandes capacités de fusion, c'est jamais un remplacement pour l'utilisation de L'Intégration Continue. Même à ce moment-là, vous disposez d'une grande flexibilité: CI pour le trunk repo, CI pour les team repos, Q&A repos etc.
Mercurial dans le contexte des entreprises:
Je ne veux pas lancer une guerre de guet contre hg ici, vous êtes déjà sur la bonne voie en envisageant de passer aux DVCS. Voici quelques raisons d'utiliser Mercurial au lieu de git:
- toutes les plateformes qui tournent python sont supportées
- Grands outils d'interface graphique sur tous les grands plattforms (win/linux/OS X), la première classe de fusion/vdiff intégration d'un outil de
- interface très cohérente, transition facile pour les utilisateurs de svn
- peut faire la plupart des choses que git peut faire aussi, mais fournit une abstraction plus propre. Les opérations dangereuses sont sont toujours explicites. Les fonctionnalités avancées sont fournies via des extensions qui doivent être explicitement activées.
- support Commercial est disponible de selenic.
bref, quand on utilise des DVCS dans une entreprise, je pense qu'il est important de choisir un outil qui introduit le moins de friction. Pour que la transition soit réussie, il est particulièrement important de considérez les différentes compétences entre les développeurs (en ce qui concerne VCS).
il y a quelques ressources que j'aimerais vous indiquer à la fin. Joel Spolsky a récemment écrit un article défaisant beaucoup d'arguments soulevés contre DVCS. Il faut mentionner que d'autres ont découvert ces contradictions bien avant. Une autre bonne ressource est Eric Sinks blog, où il a écrit un article sur Obstacles à une entreprise DVCS .
tout d'abord, quelques discussions récentes sur l'utilisation D'un DVCS dans les grands projets sont pertinentes:
le contrôle de version Distribué pour les grands projets - est-il possible?
Un ride avec Mercurial, est qu'il semble être conçu autour de l'idée d'avoir un référentiel unique par "projet".
oui, alors que la norme avec Subversion est d'avoir un dépôt monolithique contenant plusieurs projets, avec un DVCS il est préférable d'avoir plus de dépôts granulaires, avec un par composante. Subversion dispose de la fonctionnalité svn:externals pour regrouper plusieurs arbres sources au moment de la sortie (qui a ses propres problèmes logistiques et techniques). Le Mercurial et le Git ont tous deux une caractéristique similaire, appelée subrepos en hg.
l'idée avec des sous-repos est que vous avez un rapport par composant, et un produit diffusable (comprenant plusieurs composants réutilisables) se référera simplement à ses repos dépendants. Lorsque vous clonez le produit repo, il apporte les composants dont il a besoin.
devrions-nous avoir un énorme dépôt mercuriel contenant tout? Si non, comment fine devrait les petits dépôts être? Je pense que les gens le trouveront très ennuyeux s'ils doivent tirer et pousser des mises à jour à partir de beaucoup d'endroits différents, mais ils le trouveront également ennuyeux s'ils doivent tirer / pousser l'ensemble l'entreprise de la base de code.
il est certainement possible d'avoir un dépôt monolithique (et vous pouvez même le partager sur la piste si vous en avez besoin). Les problèmes avec cette approche sont plus susceptibles de venir à la libération des horaires, et la façon dont vous gérez différentes versions de différents composants. Si vous avez plusieurs produits avec leurs propres calendriers de publication partageant des composants communs, vous seriez probablement mieux avec une approche plus granulaire, pour faciliter gestion de la configuration.
Une mise en garde est que le subrepo soutien est relativement récente fonctionnalité, et n'est pas aussi complet que d'autres fonctionnalités. Plus précisément, toutes les commandes hg ne connaissent pas les sous-commandes, bien que les plus importantes le sachent.
je vous suggère d'effectuer un test de conversion, et d'expérimenter avec le support subrepo, l'organisation des produits et des composants dépendants, etc. Je suis en train de faire la même chose, et cela semble être la façon dont aller.