Utilisation des instructions du processeur AVX: mauvaise performance sans " / arch: AVX"
mon code C++ utilise SSE et maintenant je veux l'améliorer pour supporter AVX quand il est disponible. Donc je détecte quand AVX est disponible et j'appelle une fonction qui utilise des commandes AVX. J'utilise Win7 SP1 + VS2010 SP1 et un CPU avec AVX.
utiliser AVX, il est nécessaire d'inclure ceci:
#include "immintrin.h"
et ensuite vous pouvez utiliser les fonctions intrinsèques AVX comme _mm256_mul_ps,_mm256_add_ps etc.
Le problème est que par défaut, VS2010 produit du code qui fonctionne très lentement et montre la avertissement:
avertissement C4752: trouvé Intel(R) Advanced Vector Extensions; envisager à l'aide de /arc:AVX
il semble que VS2010 n'utilise pas les instructions AVX, mais les émule. J'ai ajouté /arch:AVX aux options du compilateur et obtenu de bons résultats. Mais cette option indique au compilateur d'utiliser les commandes AVX partout où c'est possible. Donc mon code peut se planter sur CPU qui ne supporte pas AVX!
donc la question Est de savoir comment faire le compilateur VS2010 pour produire du code AVX mais seulement quand je spécifie directement AVX intrinsics. Pour les SSE, cela fonctionne, j'utilise juste les fonctions intrinsèques des SSE et cela produit du code SSE sans aucune option de compilateur comme /arch:SSE. Mais pour AVX, cela ne fonctionne pas pour une raison quelconque.
2 réponses
le comportement que vous voyez est le résultat d'un changement d'état coûteux.
voir page 102 du manuel D'Agner Fog:
http://www.agner.org/optimize/microarchitecture.pdf
chaque fois que vous basculez de façon inappropriée entre les instructions SSE et AVX, vous paierez une pénalité de cycle extrêmement élevée (~70).
quand vous compilez sans /arch:AVX, VS2010 générera des instructions SSE, mais utilisera toujours AVX partout où vous avez AVX intrinsics. Par conséquent, vous obtiendrez le code qui a à la fois les instructions SSE et AVX - qui aura ces pénalités de changement d'état. (VS2010 le sait, donc il émet cet avertissement que vous voyez.)
par conséquent, vous devez utiliser soit all SSE, soit all AVX. En précisant /arch:AVX indique au compilateur d'utiliser tous les AVX.
on dirait que vous essayez de créer plusieurs chemins de code: un pour la SSE, et un pour AVX.
Pour cela, je vous suggère de séparer votre code SSE et AVX en deux unités de compilation différentes. (un compilé avec /arch:AVX et un sans) puis les relier ensemble et faire un répartiteur de choisir basé sur le matériel sur lequel il tourne.
Si vous besoin pour mélanger SSE et AVX, assurez-vous d'utiliser _mm256_zeroupper() ou _mm256_zeroall() de manière appropriée pour éviter les pénalités de changement d'état.
tl;dr
Utiliser _mm256_zeroupper(); ou _mm256_zeroall(); autour des sections de code en utilisant AVX (avant ou après en fonction des arguments de fonction). N'utilisez que l'option /arch:AVX pour les fichiers source avec AVX plutôt que pour un projet entier afin d'éviter de briser le support pour les chemins de code SSE encodés en héritage.
Cause
je pense que la meilleure explication est dans le processeur Intel article, " eviter AVX-SSE Peines De Transition" ( PDF). Les états abstraits:
la transition entre les instructions Intel® AVX de 256 bits et les instructions traditionnelles Intel® SSE d'un programme peut entraîner des pénalités de performance parce que le matériel doit sauvegarder et restaurer les 128 bits supérieurs des registres YMM.
Séparer votre AVX et de l'ESS code dans différentes unités de compilation ne peut PAS aider si vous passez d'un code d'appel à l'autre les fichiers objets compatibles SSE et AVX, car la transition peut se produire lorsque les instructions ou l'assemblage AVX sont mélangés avec n'importe lequel des fichiers (du papier Intel):
- 128 bits intrinsèque instructions
- ESS assembly en ligne
- code à virgule flottante C / C++ compilé en Intel® SSE
- appels vers des fonctions ou des bibliothèques qui incluent l'un des
cela signifie qu'il peut même y avoir des pénalités lors d'un lien avec code externe en utilisant le SSE.
Détails
il y a 3 états processeurs définis par les instructions AVX, et l'un des États est où tous les YMM les registres sont divisés, permettant à la moitié inférieure d'être utilisée par instructions SSE. Le document Intel "Intel® AVX les Transitions de l'État: la Migration de l'ESS Code AVX " fournit un schéma de ces états:
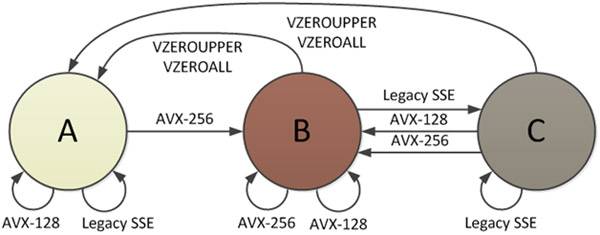
dans l'état B (Mode AVX-256), tous les bits des registres YMM sont utilisés. Lorsqu'une instruction SSE est appelée, une transition vers L'état C doit avoir lieu, et c'est là qu'il y a une pénalité. La moitié supérieure de tous les registres YMM doit être sauvegardée dans un tampon interne avant le démarrage de L'ESS, même s'il s'agit de zéros. Le coût des transitions est de "l'ordre de 50-80 cycles d'horloge sur le matériel de Sandy Bridge". Il y a aussi une pénalité en partant de C -> A, comme le montre la figure 2.
vous pouvez également trouver des détails sur la pénalité de changement d'État à l'origine de ce ralentissement à la page 130, Section 9.12, "Transitions entre VEX et non-VEX modes" dans Agner Brouillard du guide d'optimisation (de la version mise à jour 2014-08-07), référencé dans Mystique de la réponse. Selon son guide, toute transition vers/à partir de cet État prend "environ 70 cycles d'horloge sur Sandy Bridge". Tout comme L'Intel selon le document, il s'agit d'une pénalité de transition évitable.
Résolution
pour éviter les pénalités de transition, vous pouvez soit supprimer tous les anciens codes SSE, demander au compilateur de convertir toutes les instructions SSE à leur forme encodée VEX d'instructions 128 bits (si le compilateur est capable), ou mettre les registres YMM dans un état zéro connu avant de faire la transition entre le code AVX et SSE. Essentiellement, pour maintenir le chemin séparé du code SSE, vous devez zéro sur la 128 bits de toutes les 16 YMM registres (l'émission d'un VZEROUPPER instruction) après tout code qui utilise des instructions AVX. La mise à zéro de ces bits force manuellement une transition vers L'État A, et évite la pénalité coûteuse puisque les valeurs YMM n'ont pas besoin d'être stockées dans un tampon interne par le matériel. L'intrinsèque qui exécute cette instruction est _mm256_zeroupper. La description pour cet intrinsèque est très instructif:
ce intrinsic est utile pour effacer les bits supérieurs des registres YMM lors de la transition entre les instructions Intel® Advanced Vector Extensions (Intel® AVX) et les anciennes instructions Intel® Supplemental SIMD Extensions (Intel® SSE). Il n'y a pas de pénalité de transition si une application efface les bits supérieurs de tous les registres YMM (sets à 0) à l'aide de
VZEROUPPER, l'instruction correspondante pour cette intrinsèque, avant la transition entre Intel® Advanced Vector Extensions (Intel ® AVX) instructions et legacy Intel® Supplemental SIMD Extensions (Intel® SSE) instructions.
Dans Visual Studio 2010+ (peut-être même plus), vous recevez ce intrinsèques avec immintrin.h.
notez que la mise à zéro des bits avec d'autres méthodes n'élimine pas la pénalité - le VZEROUPPER ou VZEROALL les instructions doivent être utilisées.
une solution automatique implémentée par le compilateur Intel est d'insérer un VZEROUPPERà l' début de chaque fonction contenant du code AVX Intel si aucun des arguments n'est un registre YMM ou __m256/__m256d/__m256i type de données, et à la fin de fonctions si la valeur retournée n'est pas un registre YMM ou __m256/__m256d/__m256i type de données.
Dans la nature
VZEROUPPER la solution est utilisée par FFTW pour générer une bibliothèque avec le support SSE et AVX. Voir simd-avx.h:
/* Use VZEROUPPER to avoid the penalty of switching from AVX to SSE.
See Intel Optimization Manual (April 2011, version 248966), Section
11.3 */
#define VLEAVE _mm256_zeroupper
VLEAVE(); est appelée à la fin de tous les fonction utilisant intrinsic pour les instructions AVX.