Unpivot spark-sql/pyspark
j'ai un énoncé de problème à portée de main dans lequel je veux débiter la table spark-sql/pyspark. J'ai parcouru la documentation et j'ai pu voir qu'il n'y avait de soutien que pour pivot, mais pas pour un-pivot jusqu'à présent. Est-il un moyen que je peux accomplir cela?
que ma table initiale ressemble à ceci:
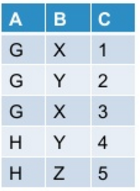
quand je pivote dans pyspark en utilisant la commande mentionnée ci-dessous:
df.groupBy("A").pivot("B").sum("C")
j'obtiens ce que la sortie:
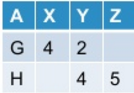
maintenant je veux débrancher la table à pivot. En général, cette opération peut/peut ne pas donner la table originale basée sur la façon dont j'ai pivoté la table originale.
Spark-sql que, désormais, ne fournit pas de support pour unpivot. Est-il un moyen que je peux accomplir cela?
1 réponses
vous pouvez utiliser la fonction stack intégrée, par exemple dans Scala:
scala> val df = Seq(("G",Some(4),2,None),("H",None,4,Some(5))).toDF("A","X","Y", "Z")
df: org.apache.spark.sql.DataFrame = [A: string, X: int ... 2 more fields]
scala> df.show
+---+----+---+----+
| A| X| Y| Z|
+---+----+---+----+
| G| 4| 2|null|
| H|null| 4| 5|
+---+----+---+----+
scala> df.select($"A", expr("stack(3, 'X', X, 'Y', Y, 'Z', Z) as (B, C)")).where("C is not null").show
+---+---+---+
| A| B| C|
+---+---+---+
| G| X| 4|
| G| Y| 2|
| H| Y| 4|
| H| Z| 5|
+---+---+---+
ou en pyspark:
In [1]: df = spark.createDataFrame([("G",4,2,None),("H",None,4,5)],list("AXYZ"))
In [2]: df.show()
+---+----+---+----+
| A| X| Y| Z|
+---+----+---+----+
| G| 4| 2|null|
| H|null| 4| 5|
+---+----+---+----+
In [3]: df.selectExpr("A", "stack(3, 'X', X, 'Y', Y, 'Z', Z) as (B, C)").where("C is not null").show()
+---+---+---+
| A| B| C|
+---+---+---+
| G| X| 4|
| G| Y| 2|
| H| Y| 4|
| H| Z| 5|
+---+---+---+