Performance étonnamment bonne avec openmp parallèle pour boucle
j'ai édité ma question après des commentaires précédents (en particulier @Zboson) pour une meilleure lisibilité
j'ai toujours agi sur, et observé, la sagesse conventionnelle que le nombre de threads openmp devrait grosso modo correspondre au nombre de hyper-threads sur une machine pour une performance optimale. Cependant, j'observe un comportement étrange sur mon nouvel ordinateur portable avec Intel Core i7 4960HQ, 4 core - 8 threads. (Voir Intel docs ici )
Voici mon code d'essai:
#include <math.h>
#include <stdlib.h>
#include <stdio.h>
#include <omp.h>
int main() {
const int n = 256*8192*100;
double *A, *B;
posix_memalign((void**)&A, 64, n*sizeof(double));
posix_memalign((void**)&B, 64, n*sizeof(double));
for (int i = 0; i < n; ++i) {
A[i] = 0.1;
B[i] = 0.0;
}
double start = omp_get_wtime();
#pragma omp parallel for
for (int i = 0; i < n; ++i) {
B[i] = exp(A[i]) + sin(B[i]);
}
double end = omp_get_wtime();
double sum = 0.0;
for (int i = 0; i < n; ++i) {
sum += B[i];
}
printf("%g %gn", end - start, sum);
return 0;
}
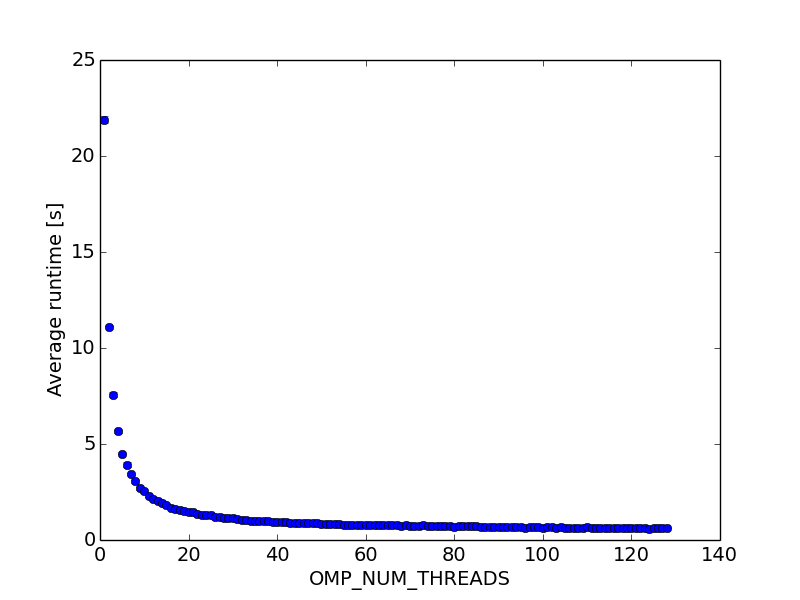
quand je le compile en utilisant gcc 4.9-4.9-20140209 , avec la commande: gcc -Ofast -march=native -std=c99 -fopenmp -Wa,-q je vois la performance suivante quand je change OMP_NUM_THREADS [les points sont une moyenne de 5 passages, les barres d'erreur (qui sont à peine visibles) sont les écarts-types]:
le graphe est plus clair lorsqu'il s'agit de l'accélération par rapport à OMP_NUM_THREADS=1:
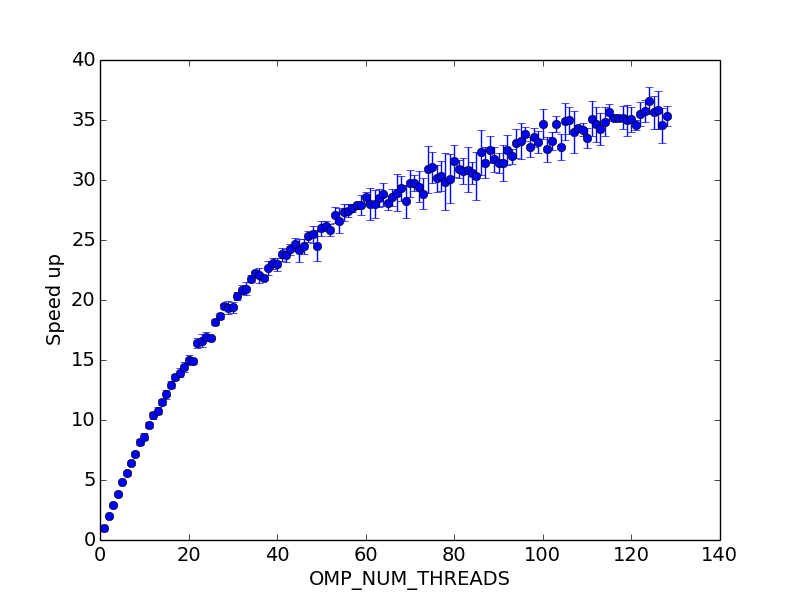
la performance augmente de façon plus ou moins monotone avec le nombre de threads, même lorsque le nombre de threads omp dépasse largement le noyau et aussi le nombre de threads hyper -! Habituellement, la performance devrait baisser quand Trop de threads sont utilisés (au moins dans mon expérience précédente), en raison de la tête de filetage. D'autant plus que le calcul doit être cpu (ou au moins mémoire) lié et n'attend pas sur I / O.
encore plus étrangement, la vitesse est de 35 fois!
quelqu'un Peut-il expliquer cela?
j'ai aussi testé cela avec des tableaux 8192*4 beaucoup plus petits, et voir des performances similaires.
en cas d'importance, je suis sur Mac OS 10.9 et les données de performance ont été obtenues en exécutant (sous bash):
for i in {1..128}; do
for k in {1..5}; do
export OMP_NUM_THREADS=$i;
echo -ne $i $k "";
./a.out;
done;
done > out
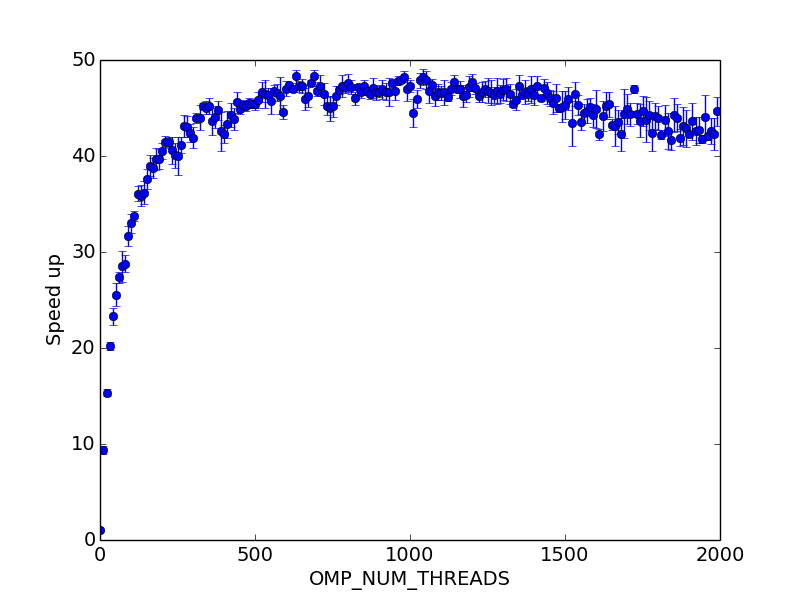
EDIT: par curiosité, j'ai décidé d'essayer un plus grand nombre de fils. Mon OS limite ça à 2000. Les résultats impairs (à la fois la vitesse et faible thread frais généraux) parlent d'eux-mêmes!
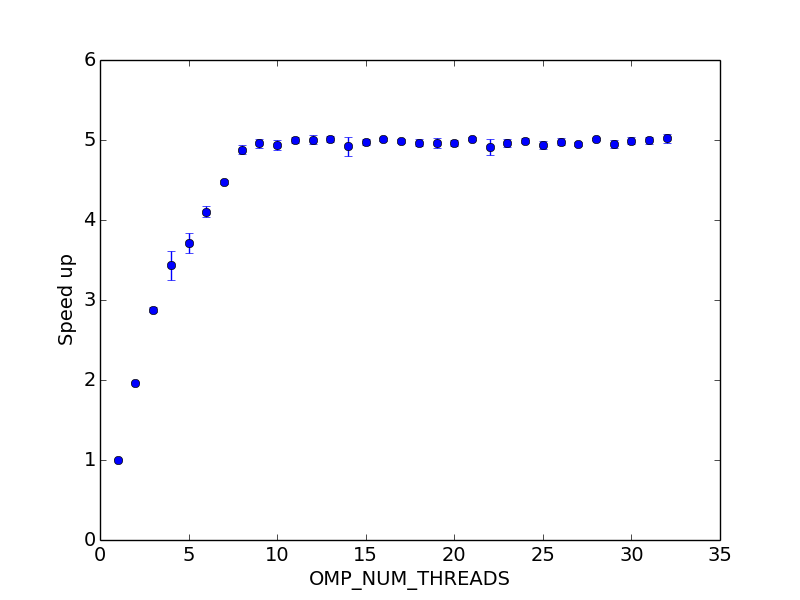
EDIT: j'ai essayé @Zboson dernière suggestion dans leur réponse, c.-à-d. mettre VZEROUPPER avant chaque fonction mathématique dans la boucle, et il a corrigé le problème d'échelle! (Il a également envoyé le code fileté unique de 22 s à 2 s!):
1 réponses
le problème est probablement dû à la fonction clock() . Il ne retourne pas le temps de mur sur Linux. Vous devez utiliser la fonction omp_get_wtime() . Il est plus précis que l'horloge et fonctionne sur GCC, ICC, et MSVC. En fait, je l'utilise pour le code de synchronisation même quand je n'utilise pas OpenMP.
j'ai testé votre code ici http://coliru.stacked-crooked.com/a/26f4e8c9fdae5cc2
Modifier : Une autre chose à considérer qui peut être à l'origine de votre problème est que les fonctions exp et sin que vous utilisez sont compilées sans support AVX. Votre code est compilé avec le support AVX (en fait AVX2). Vous pouvez le voir à partir de GCC explorer avec votre code si vous compilez avec -fopenmp -mavx2 -mfma chaque fois que vous appelez une fonction sans support AVX à partir du code AVX vous devez zéro la partie supérieure du registre YMM ou payer une grosse pénalité. Vous pouvez le faire avec l'intrinsèque _mm256_zeroupper (VZEROUPPER). Clang le fait pour vous, mais la dernière fois que J'ai vérifié GCC ne le fait pas donc vous devez le faire vous-même (voir les commentaires à cette question fonctions mathématiques prend plus de cycles après l'exécution de n'importe quelle fonction AVX intel et aussi la réponse ici en utilisant les instructions du processeur AVX: mauvaise performance sans "/arch:AVX" ). Donc chaque itération que vous êtes a un grand retard dû au fait de ne pas appeler VZEROUPPER. Je ne sais pas pourquoi, c'est ce qui compte avec plusieurs threads mais si GCC fait cela à chaque fois qu'il démarre un nouveau thread alors il pourrait aider à expliquer ce que vous voyez.
#include <immintrin.h>
#pragma omp parallel for
for (int i = 0; i < n; ++i) {
_mm256_zeroupper();
B[i] = sin(B[i]);
_mm256_zeroupper();
B[i] += exp(A[i]);
}
Edit une façon plus simple de tester faire ceci est de ne pas définir l'Arc ( gcc -Ofast -std=c99 -fopenmp -Wa ) ou d'utiliser SSE2 ( gcc -Ofast -msse2 -std=c99 -fopenmp -Wa ) au lieu de compiler avec -march=native .
Modifier GCC 4.8 a une option -mvzeroupper qui peut être la plus solution pratique.
cette option Demande à GCC d'émettre une instruction vzeroupper avant un transfert du flux de contrôle hors de la fonction pour minimiser la pénalité de transition AVX-SSE ainsi que supprimer les intrinsèques zeroupper inutiles.