Comprendre Le Kéras LSTMs
j'essaie de concilier ma compréhension de LSTMs et a souligné ici dans ce post de Christopher Olah mis en œuvre dans Keras. Je suis le blog écrit par Jason Brownlee pour le tutoriel Keras. Ce qui me trouble le plus, c'est
- la refonte de La série
[samples, time steps, features]et, - La dynamique LSTMs
vous Permet de se concentrer sur les deux questions ci-dessus en se référant au code collé ci-dessous:
# reshape into X=t and Y=t+1
look_back = 3
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# reshape input to be [samples, time steps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], look_back, 1))
testX = numpy.reshape(testX, (testX.shape[0], look_back, 1))
########################
# The IMPORTANT BIT
##########################
# create and fit the LSTM network
batch_size = 1
model = Sequential()
model.add(LSTM(4, batch_input_shape=(batch_size, look_back, 1), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(100):
model.fit(trainX, trainY, nb_epoch=1, batch_size=batch_size, verbose=2, shuffle=False)
model.reset_states()
Note: create_dataset prend une séquence de longueur N et renvoie un tableau N-look_back dont chaque élément est une séquence de longueur look_back .
Qu'est-ce que les étapes et les caractéristiques du temps?
comme on peut le voir TrainX est un tableau 3-D avec Time_steps et Feature étant les deux dernières dimensions respectivement (3 et 1 dans ce particulier code.) En ce qui concerne l'image ci-dessous, cela signifie-t-il que nous considérons le cas many to one , où le nombre de boîtes roses est de 3? Ou cela signifie-t-il littéralement la longueur de la chaîne est de 3 (c.-à-d. seulement 3 boîtes vertes considérées). 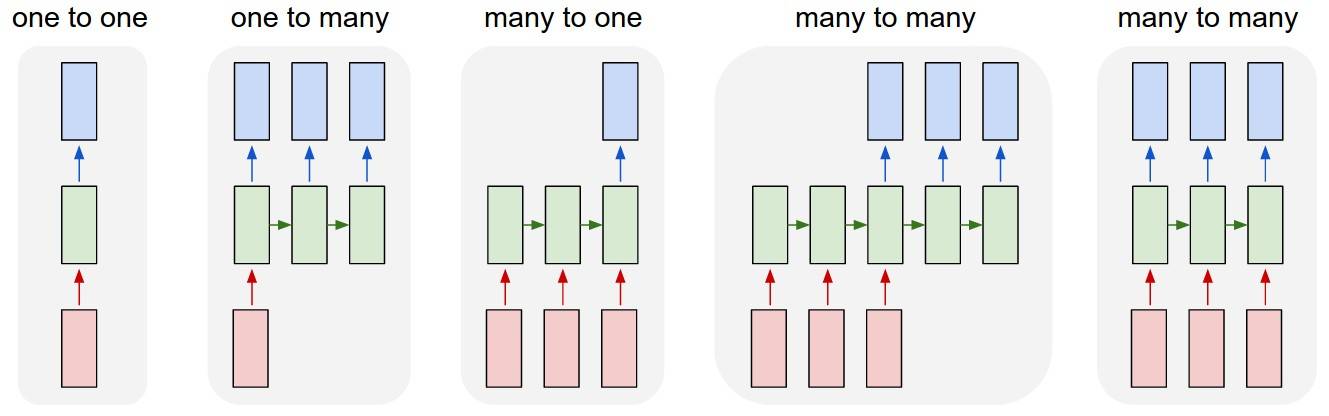
l'argument fonctionnalités devenir pertinent lorsque l'on considère multivariée de la série? par exemple, modéliser simultanément deux stocks financiers?
Stateful LSTMs
est-ce que les LSTM statiques signifient que nous sauvegardons les valeurs de la mémoire cellulaire entre les séries de lots? Si c'est le cas, batch_size en est un, et la mémoire est réinitialisée entre les parcours d'entraînement donc à quoi bon dire qu'elle était stateful. Je suppose que c'est lié au fait que les données d'entraînement ne sont pas mélangées, mais je ne sais pas comment.
une idée? Référence de l'Image: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Edit 1:
un peu confus sur le commentaire de @van sur l'égalité des boîtes rouge et verte. Donc juste pour confirmer, les appels API suivants correspondent-ils aux diagrammes déroulés? En particulier en notant le deuxième diagramme ( batch_size a été arbitrairement choisi.):
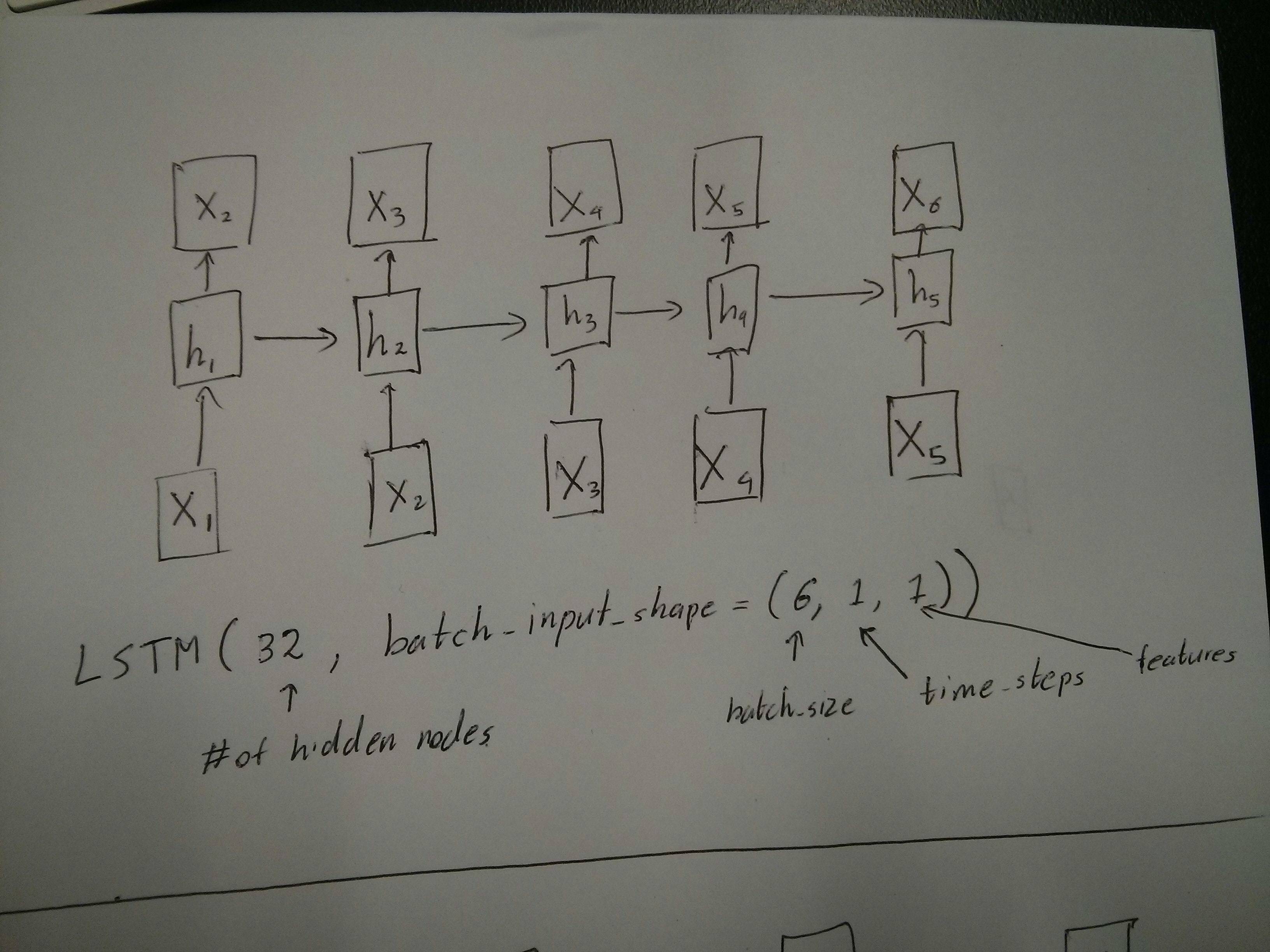
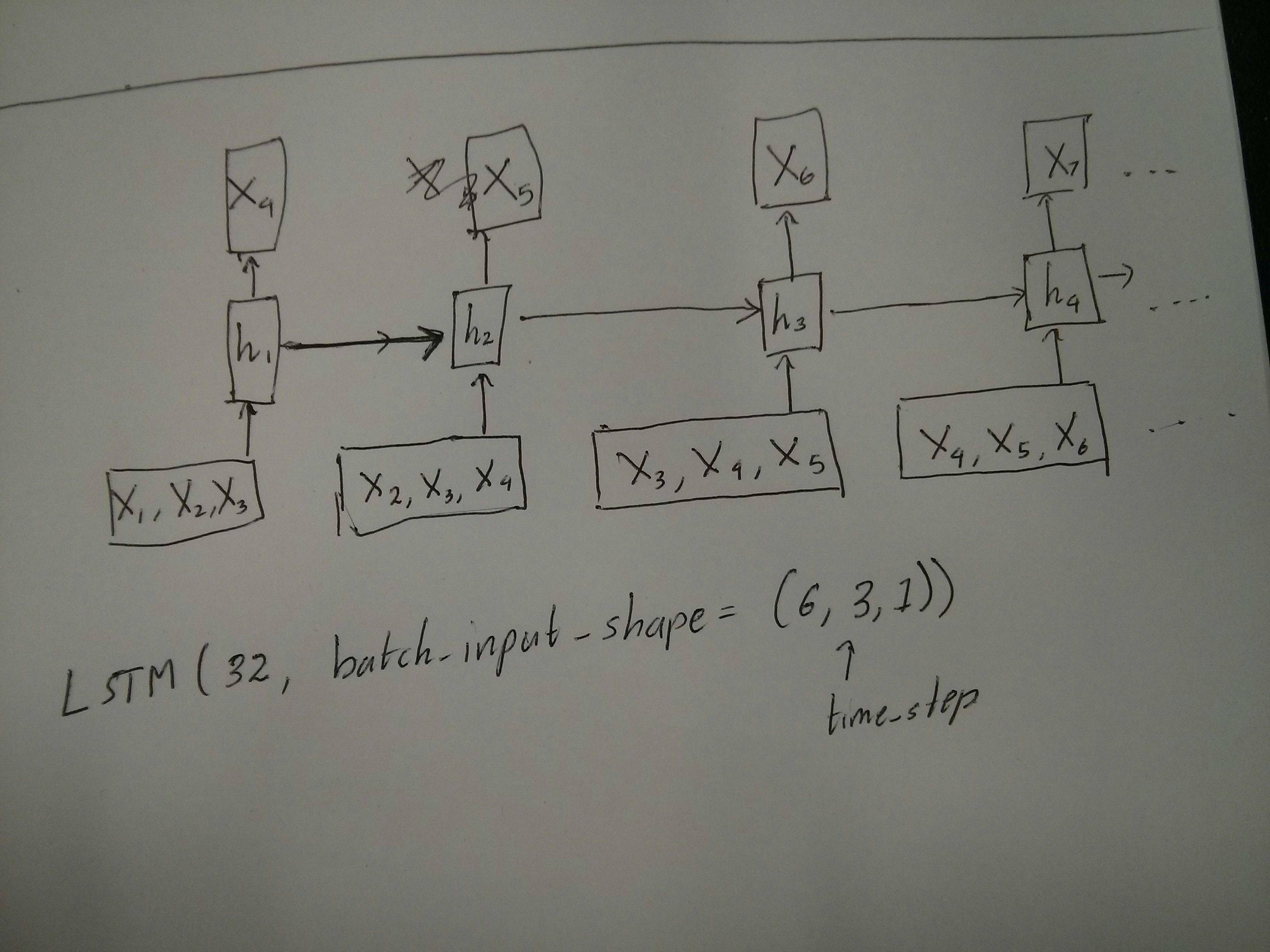
Edit 2:
pour les personnes qui ont suivi le cours de formation approfondie D'Udacity et qui sont encore confuses au sujet de l'argument time_step, regardez la discussion suivante: https://discussions.udacity.com/t/rnn-lstm-use-implementation/163169
mise à jour:
Il s'avère que model.add(TimeDistributed(Dense(vocab_len))) était ce que je cherchais. Voici un exemple: https://github.com/sachinruk/ShakespeareBot
Update2:
j'ai résumé la plupart de ma compréhension de LSTMs ici: https://www.youtube.com/watch?v=ywinX5wgdEU
3 réponses
tout d'abord, vous choisissez de grands tutoriels( 1 , 2 ) pour commencer.
Ce Que Time-step signifie : Time-steps==3 en forme de X. (décrivant la forme des données) signifie qu'il y a trois boîtes roses. Depuis dans Keras chaque étape nécessite une entrée, donc le nombre de cases vertes devraient généralement égal au nombre de cases rouges. À moins que vous ne Hacker la structure.
beaucoup à beaucoup vs. beaucoup à un : dans keras, il y a un paramètre return_sequences lorsque vous initialisez LSTM ou GRU ou SimpleRNN . Lorsque return_sequences est False (par défaut), alors il est beaucoup à un comme indiqué sur l'image. Sa forme de retour est (batch_size, hidden_unit_length) , qui représentent le dernier état. Quand return_sequences est True , alors il est beaucoup à beaucoup . Sa forme de retour est (batch_size, time_step, hidden_unit_length)
est-ce que l'argument des caractéristiques devient pertinent : l'argument des caractéristiques signifie "Quelle est la taille de votre boîte rouge" ou Quelle est la dimension d'entrée à chaque étape. Si vous voulez prédire à partir de, disons, 8 types d'informations de marché, alors vous pouvez générer vos données avec feature==8 .
Stateful : vous pouvez rechercher le code source . Lors de l'initialisation de l'état, si stateful==True , alors que l'état de la dernière formation sera utilisé comme état initial, sinon il va générer un nouvel état. Je n'ai pas encore allumé stateful . Cependant, je ne suis pas d'accord avec le fait que le batch_size ne peut être que 1 lorsque stateful==True .
Actuellement, vous produisez vos données avec des données collectées. L'Image de votre information de stock arrive en flux, plutôt que d'attendre un jour pour recueillir tous les séquentiels, vous souhaitez générer des données d'entrée en ligne pendant la formation / la prévision avec le réseau. Si vous avez 400 stocks partageant un même réseau, alors vous pouvez définir batch_size==400 .
en complément de la réponse acceptée, cette réponse montre les comportements de keras et comment réaliser chaque image.
Général Keras comportement
le traitement interne standard de keras est toujours de beaucoup à beaucoup comme dans l'image suivante (où j'ai utilisé features=2 , pression et température, juste comme un exemple):
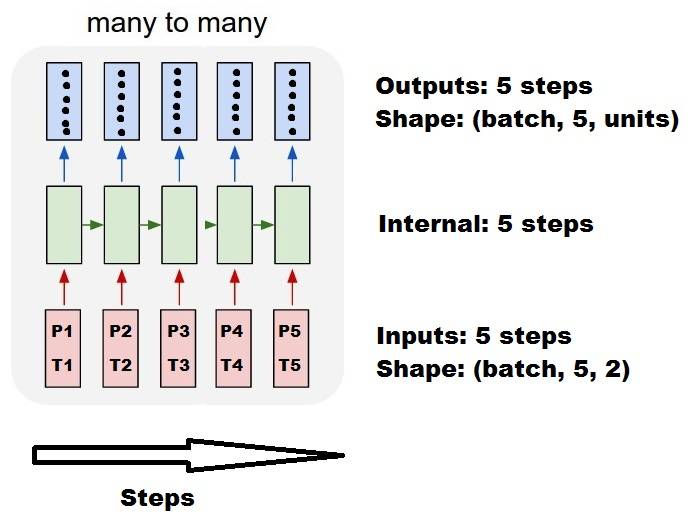
dans ce image, j'ai augmenté le nombre d'étapes à 5, pour éviter la confusion avec les autres dimensions.
pour cet exemple:
- Nous avons N réservoirs d'huile
- Nous avons passé 5 heures à prendre des mesures à l'heure (pas de temps)
- Nous avons mesuré deux caractéristiques:
- Pression P
- Température T
Notre tableau d'entrées devrait alors être quelque chose en forme de (N,5,2) :
[ Step1 Step2 Step3 Step4 Step5
Tank A: [[Pa1,Ta1], [Pa2,Ta2], [Pa3,Ta3], [Pa4,Ta4], [Pa5,Ta5]],
Tank B: [[Pb1,Tb1], [Pb2,Tb2], [Pb3,Tb3], [Pb4,Tb4], [Pb5,Tb5]],
....
Tank N: [[Pn1,Tn1], [Pn2,Tn2], [Pn3,Tn3], [Pn4,Tn4], [Pn5,Tn5]],
]
entrées pour fenêtres coulissantes
souvent, les couches LSTM sont censées traiter les séquences entières. Diviser les fenêtres n'est peut-être pas la meilleure idée. La couche a des états internes sur la façon dont une séquence évolue au fur et à mesure qu'elle progresse. Windows élimine la possibilité d'apprendre de longues séquences, limitant toutes les séquences à la taille de la fenêtre.
In fenêtres, chaque fenêtre est partie d'une longue séquence d'origine, mais par Keras ils seront vus comme une séquence autonome:
[ Step1 Step2 Step3 Step4 Step5
Window A: [[P1,T1], [P2,T2], [P3,T3], [P4,T4], [P5,T5]],
Window B: [[P2,T2], [P3,T3], [P4,T4], [P5,T5], [P6,T6]],
Window C: [[P3,T3], [P4,T4], [P5,T5], [P6,T6], [P7,T7]],
....
]
notez que dans ce cas, vous n'avez initialement qu'une seule séquence, mais vous la divisez en plusieurs séquences pour créer windows.
Le concept de "qu'est ce qu'une séquence" est abstrait. Les parties importantes sont:
- vous pouvez avoir des lots avec de nombreuses séquences individuelles
- ce qui fait que les séquences sont des séquences, c'est qu'elles évoluent par étapes (généralement par étapes)
réalisation de chaque cas avec "couches simples"
la Réalisation de standard plusieurs à plusieurs:
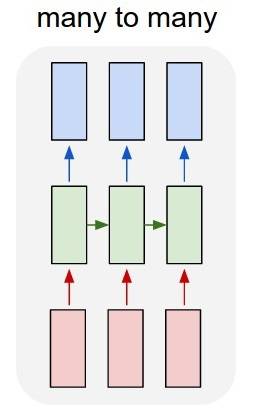
vous pouvez réaliser beaucoup à beaucoup avec une couche LSTM simple, en utilisant return_sequences=True :
outputs = LSTM(units, return_sequences=True)(inputs)
#output_shape -> (batch_size, steps, units)
la Réalisation de nombreux à un:
en utilisant exactement la même couche, keras fera exactement le même prétraitement interne, mais lorsque vous utilisez return_sequences=False (ou ignorez simplement cet argument), keras rejettera automatiquement les étapes antérieures à la dernière:
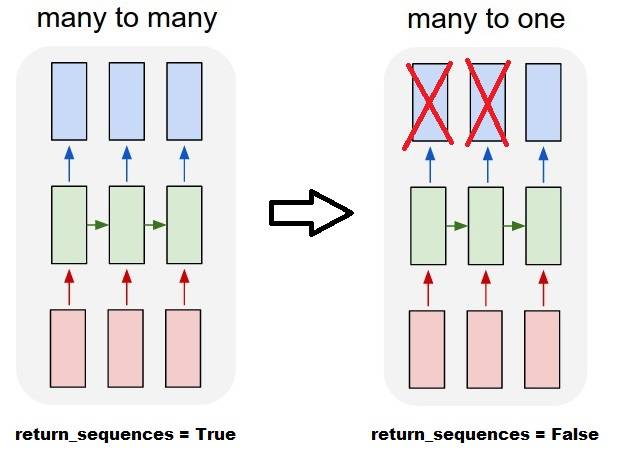
outputs = LSTM(units)(inputs)
#output_shape -> (batch_size, units) --> steps were discarded, only the last was returned
la Réalisation de l'un à plusieurs
maintenant, ce n'est pas supporté par keras LSTM couches seul. Vous devrez créer votre propre stratégie pour multiplier les étapes. Il y a deux bonnes approches:
- créer une entrée constante en plusieurs étapes en répétant un tenseur
- utilisez un
stateful=Truepour prendre de façon récurrente la sortie d'un pas et le servir comme entrée de la prochaine étape (besoinsoutput_features == input_features)
Un-à-plusieurs avec la répétition vecteur
pour s'adapter à keras comportement standard, Nous avons besoin d'entrées par étapes, donc, nous répétons simplement les entrées pour la longueur que nous voulons:
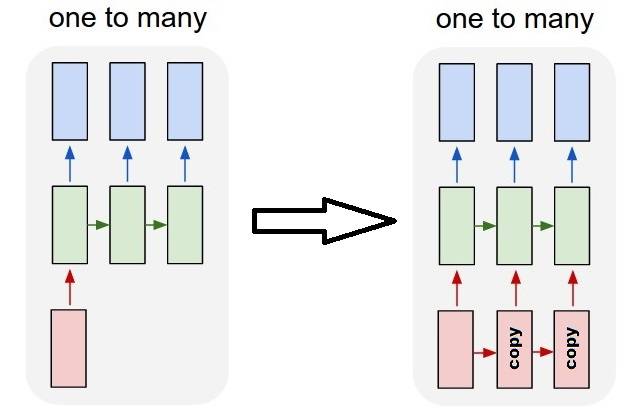
outputs = RepeatVector(steps)(inputs) #where inputs is (batch,features)
outputs = LSTM(units,return_sequences=True)(outputs)
#output_shape -> (batch_size, steps, units)
Comprendre la dynamique = True
vient maintenant l'une des utilisations possibles de stateful=True (en plus d'éviter de charger des données qui ne peuvent pas s'adapter à la mémoire de votre ordinateur à la fois)
permet de saisir des "parties" de les séquences dans les stades. La différence est:
- dans
stateful=False, le second lot contient des séquences entièrement nouvelles, indépendantes du premier lot - Dans
stateful=True, le deuxième lot, poursuit le premier lot, prolongeant les mêmes séquences.
C'est comme diviser les séquences dans windows aussi, avec ces deux différences principales:
- ces fenêtres font ne pas superposer!!
-
stateful=Trueverra ces fenêtres connectés comme une seule longue séquence
dans stateful=True , chaque nouveau lot sera interprété comme continuant le lot précédent (jusqu'à ce que vous appeliez model.reset_states() ).
- la séquence 1 du deuxième lot continuera la séquence 1 du premier lot.
- la séquence 2 du deuxième lot continuera la séquence 2 du premier lot. La séquence
- n du deuxième lot continuera la séquence n du premier lot.
exemple d'entrées, le lot 1 contient les étapes 1 et 2, le lot 2 contient les étapes 3 à 5:
BATCH 1 BATCH 2
[ Step1 Step2 | [ Step3 Step4 Step5
Tank A: [[Pa1,Ta1], [Pa2,Ta2], | [Pa3,Ta3], [Pa4,Ta4], [Pa5,Ta5]],
Tank B: [[Pb1,Tb1], [Pb2,Tb2], | [Pb3,Tb3], [Pb4,Tb4], [Pb5,Tb5]],
.... |
Tank N: [[Pn1,Tn1], [Pn2,Tn2], | [Pn3,Tn3], [Pn4,Tn4], [Pn5,Tn5]],
] ]
noter l'alignement des citernes du lot 1 et du lot 2! C'est pourquoi nous avons besoin de shuffle=False (à moins que nous n'utilisions une seule séquence, bien sûr).
Vous pouvez avoir n'importe quel nombre de lots, indéfiniment. (Pour avoir des longueurs variables dans chaque lot, utilisez input_shape=(None,features) .
Un à plusieurs avec état=True
Pour notre cas ici, nous allons utiliser seulement 1 étape par lot, parce que nous voulons obtenir une sortie de l'étape et de faire une entrée.
s'il vous Plaît notez que le comportement de l'image n'est pas "causé par" stateful=True . Nous allons forcer ce comportement dans une boucle manuelle ci-dessous. Dans cet exemple, stateful=True est ce qui "permet" d'arrêter la séquence, de manipuler ce que nous vouloir, et continuer d'où nous nous sommes arrêtés.
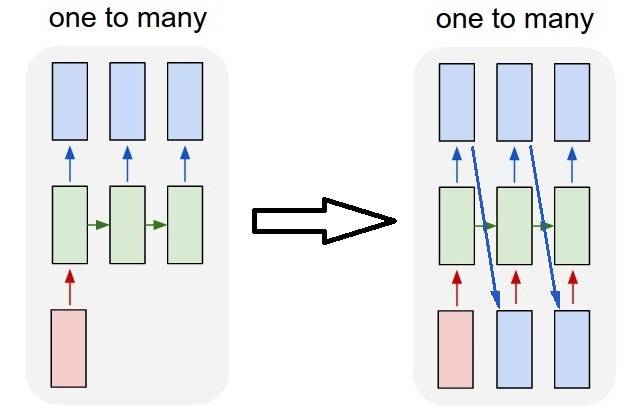
honnêtement, l'approche de répétition est probablement un meilleur choix pour ce cas. Mais puisque nous examinons stateful=True , c'est un bon exemple. La meilleure façon d'utiliser ceci est le prochain cas "beaucoup à beaucoup".
couche:
outputs = LSTM(units=features,
stateful=True,
return_sequences=True, #just to keep a nice output shape even with length 1
input_shape=(None,features))(inputs)
#units = features because we want to use the outputs as inputs
#None because we want variable length
#output_shape -> (batch_size, steps, units)
maintenant, nous allons avoir besoin d'une boucle manuelle pour les prédictions:
input_data = someDataWithShape((batch, 1, features))
#important, we're starting new sequences, not continuing old ones:
model.reset_states()
output_sequence = []
last_step = input_data
for i in steps_to_predict:
new_step = model.predict(last_step)
output_sequence.append(new_step)
last_step = new_step
#end of the sequences
model.reset_states()
plusieurs-à-Plusieurs avec état=True
maintenant, ici, nous obtenons une application très agréable: étant donné une séquence d'entrée, essayer de prédire ses étapes futures inconnues.
nous utilisons la même méthode que dans le" one to many "ci-dessus, avec la différence que:
- nous allons utiliser la séquence elle-même pour être les données cibles, un pas d'avance
- nous connaissons une partie de la séquence (si nous écartons cette partie des résultats).
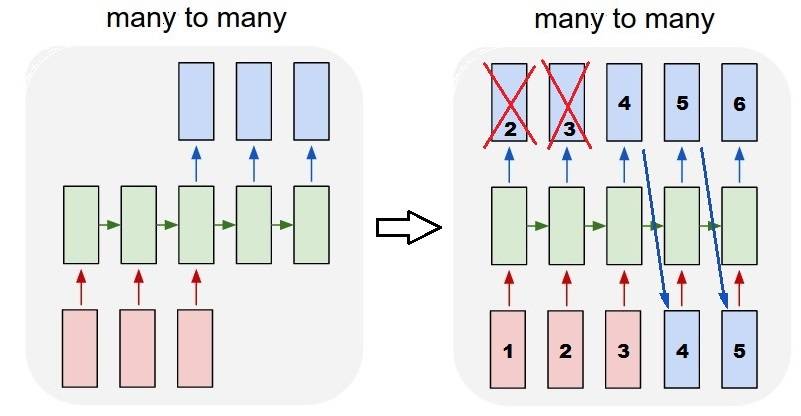
couche (même que ci-dessus):
outputs = LSTM(units=features,
stateful=True,
return_sequences=True,
input_shape=(None,features))(inputs)
#units = features because we want to use the outputs as inputs
#None because we want variable length
#output_shape -> (batch_size, steps, units)
formation:
nous allons former notre modèle pour prédire la prochaine étape des séquences:
totalSequences = someSequencesShaped((batch, steps, features))
#batch size is usually 1 in these cases (often you have only one Tank in the example)
X = totalSequences[:,:-1] #the entire known sequence, except the last step
Y = totalSequences[:,1:] #one step ahead of X
#loop for resetting states at the start/end of the sequences:
for epoch in range(epochs):
model.reset_states()
model.train_on_batch(X,Y)
prévision:
la première étape de notre prédiction consiste à"ajuster les États". C'est pourquoi nous allons de nouveau prédire la séquence entière, même si nous connaissons déjà cette partie de celle-ci:
model.reset_states() #starting a new sequence
predicted = model.predict(totalSequences)
firstNewStep = predicted[:,-1:] #the last step of the predictions is the first future step
Maintenant, nous allons à la boucle, comme dans celui de nombreux cas. Mais ne réinitialisez pas les États ici! . Nous voulons que le modèle sache à quelle étape de la séquence il se trouve (et il sait que c'est à la première nouvelle étape en raison de la prédiction que nous venons de faire ci-dessus)
output_sequence = [firstNewStep]
last_step = firstNewStep
for i in steps_to_predict:
new_step = model.predict(last_step)
output_sequence.append(new_step)
last_step = new_step
#end of the sequences
model.reset_states()
Cette approche a été utilisée dans ces réponses et fichier:
- prédiction d'un pas de temps multiple en avant d'une série temporelle en utilisant LSTM
- comment utiliser le modèle Keras pour prévoir des dates ou des événements futurs?
- https://github.com/danmoller/TestRepo/blob/master/TestBookLSTM.ipynb
réalisation de configurations complexes
Dans tous les exemples ci-dessus, j'ai montré le comportement de "une couche".
vous pouvez, bien sûr, empiler plusieurs couches les unes sur les autres, pas nécessairement toutes suivant le même modèle, et créer vos propres modèles.
Un exemple intéressant qui apparaît est le "autoencoder" qui a "beaucoup à un encodeur", suivi par "un à plusieurs" décodeur:
"15191980920 de l'Encodeur":
inputs = Input((steps,features))
#a few many to many layers:
outputs = LSTM(hidden1,return_sequences=True)(inputs)
outputs = LSTM(hidden2,return_sequences=True)(outputs)
#many to one layer:
outputs = LSTM(hidden3)(outputs)
encoder = Model(inputs,outputs)
"15191980920 Décodeur":
utilisant la méthode de" répétition";
inputs = Input((hidden3,))
#repeat to make one to many:
outputs = RepeatVector(steps)(inputs)
#a few many to many layers:
outputs = LSTM(hidden4,return_sequences=True)(outputs)
#last layer
outputs = LSTM(features,return_sequences=True)(outputs)
decoder = Model(inputs,outputs)
Autoencoder:
inputs = Input((steps,features))
outputs = encoder(inputs)
outputs = decoder(outputs)
autoencoder = Model(inputs,outputs)
Train avec fit(X,X)
lorsque vous avez return_sequences dans votre dernière couche de RNN, vous ne pouvez pas utiliser une simple couche Dense au lieu d'utiliser TimeDistributed.
voici un exemple de code qui pourrait aider les autres.
mots = keras.couche.D'entrée(batch_shape=(None, auto.maxSequenceLength), name = "input")
# Build a matrix of size vocabularySize x EmbeddingDimension
# where each row corresponds to a "word embedding" vector.
# This layer will convert replace each word-id with a word-vector of size Embedding Dimension.
embeddings = keras.layers.embeddings.Embedding(self.vocabularySize, self.EmbeddingDimension,
name = "embeddings")(words)
# Pass the word-vectors to the LSTM layer.
# We are setting the hidden-state size to 512.
# The output will be batchSize x maxSequenceLength x hiddenStateSize
hiddenStates = keras.layers.GRU(512, return_sequences = True,
input_shape=(self.maxSequenceLength,
self.EmbeddingDimension),
name = "rnn")(embeddings)
hiddenStates2 = keras.layers.GRU(128, return_sequences = True,
input_shape=(self.maxSequenceLength, self.EmbeddingDimension),
name = "rnn2")(hiddenStates)
denseOutput = TimeDistributed(keras.layers.Dense(self.vocabularySize),
name = "linear")(hiddenStates2)
predictions = TimeDistributed(keras.layers.Activation("softmax"),
name = "softmax")(denseOutput)
# Build the computational graph by specifying the input, and output of the network.
model = keras.models.Model(input = words, output = predictions)
# model.compile(loss='kullback_leibler_divergence', \
model.compile(loss='sparse_categorical_crossentropy', \
optimizer = keras.optimizers.Adam(lr=0.009, \
beta_1=0.9,\
beta_2=0.999, \
epsilon=None, \
decay=0.01, \
amsgrad=False))