UK Code Postal Regex (complet))
je suis à la recherche d'un regex qui validera un code postal britannique complexe uniquement dans une chaîne de caractères. Tous les formulaires de code postal peu communs doivent être couverts aussi bien que d'habitude. Par exemple:
Correspond à
- CW3 9SS
- SE5 0EG
- SE50EG
- se5 0eg
- WC2H 7LT
Pas de Match
- aWC2H 7LT
- WC2H 7LTa
- WC2H
y a-t-il des règlements officiels ou même semi-officiels utilisés pour ce genre de choses? D'autres conseils sur le formatage et le stockage dans une base de données?
29 réponses
je recommande de jeter un oeil à la norme de données du gouvernement du Royaume-Uni pour les codes postaux [lien maintenant mort; archive de XML , voir Wikipedia pour la discussion]. Il y a une brève description des données et le schéma xml joint fournit une expression régulière. Il peut ne pas être exactement ce que vous voulez, mais serait un bon point de départ. Le RegEx diffère légèrement du XML, puisqu'un caractère P en troisième position dans le format A9A 9AA est autorisé par le définition qui en est donnée.
L'expression régulière fournie par le Gouvernement du royaume-UNI a été:
([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9][A-Za-z]?))))\s?[0-9][A-Za-z]{2})
comme indiqué sur la discussion de Wikipedia, cela permettra à certains postcodes non-réels (par exemple ceux qui commencent AA, ZY) et ils fournissent un test plus rigoureux que vous pourriez essayer.
on dirait que nous allons utiliser ^(GIR ?0AA|[A-PR-UWYZ]([0-9]{1,2}|([A-HK-Y][0-9]([0-9ABEHMNPRV-Y])?)|[0-9][A-HJKPS-UW]) ?[0-9][ABD-HJLNP-UW-Z]{2})$ , qui est une version légèrement modifiée de celle suggérée par Minglis ci-dessus.
Cependant, nous allons devoir examiner exactement quelles sont les règles, car les différentes solutions énumérées ci-dessus semblent appliquer des règles différentes quant aux lettres qui sont autorisées.
après quelques recherches, nous avons trouvé plus d'informations. Apparemment une page sur ' govtalk.gov.uk ' vous indique un code postal cahier des charges govtalk-codes postaux . Cela renvoie à un schéma XML au schéma XML qui fournit une déclaration "pseudo regex" des règles de code postal.
nous avons pris cela et travaillé dessus un peu pour nous donner l'expression suivante:
^((GIR &0AA)|((([A-PR-UWYZ][A-HK-Y]?[0-9][0-9]?)|(([A-PR-UWYZ][0-9][A-HJKSTUW])|([A-PR-UWYZ][A-HK-Y][0-9][ABEHMNPRV-Y]))) &[0-9][ABD-HJLNP-UW-Z]{2}))$
ceci rend les espaces optionnels, mais vous limite à un espace (remplacer le '&' par '{0,} pour les espaces illimités). Il suppose que tout le texte doit être en majuscule.
si vous voulez autoriser des minuscules, avec n'importe quel nombre d'espaces, utilisez:
^(([gG][iI][rR] {0,}0[aA]{2})|((([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y]?[0-9][0-9]?)|(([a-pr-uwyzA-PR-UWYZ][0-9][a-hjkstuwA-HJKSTUW])|([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y][0-9][abehmnprv-yABEHMNPRV-Y]))) {0,}[0-9][abd-hjlnp-uw-zABD-HJLNP-UW-Z]{2}))$
cela ne couvre pas les territoires d'outre-mer et ne fait que renforcer le format, pas l'existence de différentes zones. Il est fondé sur les règles suivantes:
peut accepter les formats suivants:
- " GIR 0AA "
- A9 9ZZ
- A99 9ZZ
- AB9 9ZZ
- AB99 9ZZ
- A9C 9ZZ
- AD9E 9ZZ
où:
- 9 peut être n'importe quel numéro à un chiffre.
- a peut être n'importe quelle lettre sauf Q, V ou X.
- B peut être n'importe quelle lettre sauf pour I, J ou Z.
- C peut être n'importe quelle lettre sauf I, L, M, N, O, P, Q, R, V, X, Y ou Z.
- D peut être n'importe quelle lettre sauf I, J ou Z.
- E peut être n'importe lequel de A, B, E, H, M, N, P, R, V, W, X ou Y.
- Z peut être n'importe quelle lettre sauf pour C, I, K, M, O ou V.
Meilleurs vœux
Colin
il n'existe pas d'expression régulière complète de code postal au Royaume-Uni qui soit capable de valider un code postal. Vous pouvez vérifier qu'un code postal est dans le bon format à l'aide d'une expression régulière; pas qu'il existe réellement.
les codes postaux sont arbitrairement complexes et en constante évolution. Par exemple, le code postal W1 n'a pas, et peut ne pas avoir, tous les numéros entre 1 et 99, pour chaque zone de code postal.
vous ne pouvez pas vous attendre à ce que ce qui existe actuellement soit vrai pour toujours. À titre d'exemple, en 1990, le Bureau de poste a décidé Qu'Aberdeen était un peu bondé. Ils ont ajouté un 0 à la fin de AB1-5 ce qui en fait AB10-50 et a ensuite créé un certain nombre de postcodes entre ces deux.
chaque fois qu'une nouvelle rue est construite, un nouveau code postal est créé. Cela fait partie du processus d'obtention de l'autorisation de construire; les autorités locales sont obligées de garder cette mise à jour auprès du Bureau de poste (pas qu'ils le font tous).
en outre, comme l'a noté un certain nombre d'autres utilisateurs, Il ya les codes postaux spéciaux tels que Girobank, GIR 0AA, et celui pour les lettres à Santa, SAN TA1 - vous ne voulez probablement rien poster là-bas, mais il ne semble pas être couvert par une autre réponse.
puis, il y a les codes postaux BFPO, qui sont maintenant en passant à un format plus standard . Les deux formats seront valides. Enfin, il y a le territoires d'outre-mer source Wikipédia .
+----------+----------------------------------------------+ | Postcode | Location | +----------+----------------------------------------------+ | AI-2640 | Anguilla | | ASCN 1ZZ | Ascension Island | | STHL 1ZZ | Saint Helena | | TDCU 1ZZ | Tristan da Cunha | | BBND 1ZZ | British Indian Ocean Territory | | BIQQ 1ZZ | British Antarctic Territory | | FIQQ 1ZZ | Falkland Islands | | GX11 1AA | Gibraltar | | PCRN 1ZZ | Pitcairn Islands | | SIQQ 1ZZ | South Georgia and the South Sandwich Islands | | TKCA 1ZZ | Turks and Caicos Islands | +----------+----------------------------------------------+
ensuite, vous devez prendre en compte que le Royaume-Uni "exporté" son système de code postal à de nombreux endroits dans le monde. Tout ce qui valide un code postal "UK" validera également les codes postaux d'un certain nombre d'autres pays.
si vous voulez valider un code postal britannique la façon la plus sûre de le faire est d'utiliser une recherche de courant postal. Il y a un certain nombre d'options:
-
Ordnance Survey libère Point de Code Ouvert en vertu d'un open data la licence. Ça va être très légèrement en retard mais c'est gratuit. Cela (probablement - Je ne m'en souviens pas) n'inclura pas les données de L'Irlande Du Nord car L'enquête sur les munitions N'y a pas de mandat. La cartographie en Irlande Du Nord est effectuée par L'Ordnance Survey D'Irlande Du Nord et ils ont leur, distinct, payé, pointeur produit. Vous pouvez l'utiliser et ajouter les quelques-uns qui ne sont pas couverts assez facilement.
-
Royal Mail les communiqués de la code Postal de l'Adresse du Fichier (PAF) , cela inclut BFPO dont je ne suis pas sûr de Point de Code Ouvert. Il est mis à jour régulièrement mais coûte de l'argent (et ils peuvent être carrément méchant à ce sujet parfois). PAF inclut l'adresse complète plutôt que seulement les codes postaux et est livré avec son propre Programmeurs Guide . L'Open Data User Group (ODUG) fait actuellement pression pour que PAF soit publié gratuitement, voici une description de leur position .
-
enfin, il y a AddressBase . Il s'agit d'une collaboration entre Ordnance Survey, les autorités locales, Royal Mail et une société de correspondance pour créer un répertoire définitif de toutes les informations sur toutes les adresses au Royaume-Uni (ils ont été assez de succès en tant que bien). C'est payant, mais si vous travaillez avec une autorité locale, un ministère ou un service gouvernemental, c'est gratuit pour eux. Il y a beaucoup plus d'information que juste des codes postaux inclus.
j'ai examiné certaines des réponses ci-dessus et je recommande de ne pas utiliser le modèle de la réponse de @Dan (C. Dec 15 ' 10) , car il signale incorrectement presque 0,4% des codes postaux valides comme invalides, tandis que les autres ne le font pas.
Ordnance Survey fournir un service appelé Point de Code Ouvert qui:
contient une liste de toutes les unités de code postal actuelles en Grande-Bretagne
j'ai comparé chacun des regex ci-dessus avec la liste complète des codes postaux (juil 6 '13) à partir de ces données en utilisant grep :
cat CSV/*.csv |
# Strip leading quotes
sed -e 's/^"//g' |
# Strip trailing quote and everything after it
sed -e 's/".*//g' |
# Strip any spaces
sed -E -e 's/ +//g' |
# Find any lines that do not match the expression
grep --invert-match --perl-regexp "$pattern"
il y a 1 686 202 postcodes au total.
les numéros suivants sont les numéros de codes postaux valides qui font et non correspondent chacun $pattern :
'^([A-PR-UWYZ0-9][A-HK-Y0-9][AEHMNPRTVXY0-9]?[ABEHMNPRVWXY0-9]?[0-9][ABD-HJLN-UW-Z]{2}|GIR 0AA)$'
# => 6016 (0.36%)
'^(GIR ?0AA|[A-PR-UWYZ]([0-9]{1,2}|([A-HK-Y][0-9]([0-9ABEHMNPRV-Y])?)|[0-9][A-HJKPS-UW]) ?[0-9][ABD-HJLNP-UW-Z]{2})$'
# => 0
'^GIR[ ]?0AA|((AB|AL|B|BA|BB|BD|BH|BL|BN|BR|BS|BT|BX|CA|CB|CF|CH|CM|CO|CR|CT|CV|CW|DA|DD|DE|DG|DH|DL|DN|DT|DY|E|EC|EH|EN|EX|FK|FY|G|GL|GY|GU|HA|HD|HG|HP|HR|HS|HU|HX|IG|IM|IP|IV|JE|KA|KT|KW|KY|L|LA|LD|LE|LL|LN|LS|LU|M|ME|MK|ML|N|NE|NG|NN|NP|NR|NW|OL|OX|PA|PE|PH|PL|PO|PR|RG|RH|RM|S|SA|SE|SG|SK|SL|SM|SN|SO|SP|SR|SS|ST|SW|SY|TA|TD|TF|TN|TQ|TR|TS|TW|UB|W|WA|WC|WD|WF|WN|WR|WS|WV|YO|ZE)(\d[\dA-Z]?[ ]?\d[ABD-HJLN-UW-Z]{2}))|BFPO[ ]?\d{1,4}$'
# => 0
bien sûr, ces résultats ne concernent que les codes postaux valides qui sont incorrectement signalé comme invalide. So:
'^.*$'
# => 0
Je ne dis rien au sujet de quel modèle est le meilleur en ce qui concerne le filtrage des codes postaux invalides.
^([A-PR-UWYZ0-9][A-HK-Y0-9][AEHMNPRTVXY0-9]?[ABEHMNPRVWXY0-9]? {1,2}[0-9][ABD-HJLN-UW-Z]{2}|GIR 0AA)$
expression Régulière correspondant valide royaume-UNI postal. Au Royaume-Uni, le système postal ne toutes les lettres sont utilisées dans toutes les positions (idem pour l'immatriculation du véhicule plaques) et il ya diverses règles pour régissent l'utilisation de ce. Cette expression prend en compte de ces règles. Détails de l' règles: première moitié du code postal valide formats [A-Z][A-Z][0-9][A-Z]] [A-Z][A-Z][0-9][0-9] [A-Z][0-9][0-9] [A-Z][A-Z][0-9] [A-Z][A-Z][A-Z] [A-Z][0-9][A-Z] [A-Z][0-9] Exception La Position De La Première. Contrainte - QVX pas Position utilisée-seconde. Contrainte - IJZ non utilisé sauf dans la RGI 0AA Position De Tiers. Contrainte - Aehmnprtvxy uniquement Position utilisée - De suite. Contraint-ABEHMNPRVWXY Second la moitié des formats valides de code postal [0-9][A-Z][A-Z] À L'Exception De La Position - Deuxième et troisième. Contraint-CIKMOV non utilisé
un vieux post mais toujours assez élevé dans les résultats de google donc pensé que je voudrais mettre à jour. CE DoC Oct 14 définit L'expression régulière UK postcode comme:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([**AZ**a-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
de:
le document explique aussi la logique qui le sous-tend. Toutefois, il a une erreur (en gras) et permet aussi de minuscules, qui, bien que légale n'est pas habituel, donc version modifiée:
^(GIR 0AA)|((([A-Z][0-9]{1,2})|(([A-Z][A-HJ-Y][0-9]{1,2})|(([A-Z][0-9][A-Z])|([A-Z][A-HJ-Y][0-9]?[A-Z])))) [0-9][A-Z]{2})$
cela fonctionne avec les nouveaux codes postaux de Londres (par exemple W1D 5LH) que les versions précédentes n'ont pas.
la plupart des réponses ici n'ont pas fonctionné pour tous les codes postaux que j'ai dans ma base de données. J'en ai finalement trouvé un qui valide avec tous, en utilisant le nouveau regex fourni par le gouvernement:
il n'est dans aucune des réponses précédentes donc je le poste ici au cas où ils prennent le lien vers le bas:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
mise à JOUR: mise à Jour de regex comme indiqué par Jamie Bull. Je ne suis pas sûr que ce soit ma copie d'erreur ou une erreur dans le regex du gouvernement, le lien est en bas maintenant...
mise à jour: comme ctwheels trouvé, ce regex fonctionne avec la saveur JavaScript regex. Voir son commentaire pour un qui fonctionne avec la saveur pcre (php).
selon cette table Wikipédia
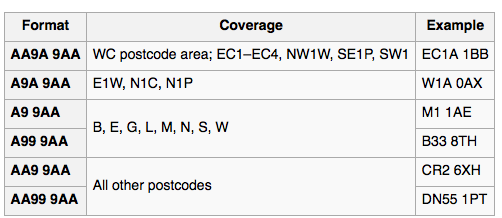
ce schéma couvre tous les cas
(?:[A-Za-z]\d ?\d[A-Za-z]{2})|(?:[A-Za-z][A-Za-z\d]\d ?\d[A-Za-z]{2})|(?:[A-Za-z]{2}\d{2} ?\d[A-Za-z]{2})|(?:[A-Za-z]\d[A-Za-z] ?\d[A-Za-z]{2})|(?:[A-Za-z]{2}\d[A-Za-z] ?\d[A-Za-z]{2})
Lors de l'utilisation sur Android\Java \\d
les codes postaux sont sujets à changement, et la seule vraie façon de valider un code postal est d'avoir la liste complète des codes postaux et de voir s'il est là.
mais les expressions régulières sont utiles car elles:
- sont faciles à utiliser et à mettre en œuvre
- sont courts
- sont prompts à exécuter
- sont assez faciles à tenir à jour (par rapport à une liste complète de codes postaux)
- toujours capter la plupart des erreurs d'entrée
mais les expressions régulières ont tendance à être difficiles à maintenir, surtout pour quelqu'un qui ne l'a pas inventé en premier lieu. Il doit en être ainsi:
- aussi facile à comprendre que possible
- relately future proof
cela signifie que la plupart des expressions régulières dans cette réponse ne sont pas assez bonnes. E. g. Je peux voir que [A-PR-UWYZ][A-HK-Y][0-9][ABEHMNPRV-Y] va correspondre à une zone de code postal de la forme AA1A - mais il va être une douleur dans le cou si et quand une nouvelle zone de code postal est ajoutée, parce qu'il est difficile de comprendre quelles zones de code postal il correspond.
je veux aussi que mon expression régulière corresponde à la première et à la deuxième moitié du code postal comme correspondances entre parenthèses.
alors j'ai trouvé ceci:
(GIR(?=\s*0AA)|(?:[BEGLMNSW]|[A-Z]{2})[0-9](?:[0-9]|(?<=N1|E1|SE1|SW1|W1|NW1|EC[0-9]|WC[0-9])[A-HJ-NP-Z])?)\s*([0-9][ABD-HJLNP-UW-Z]{2})
en format PCRE il peut être écrit comme suit:
/^
( GIR(?=\s*0AA) # Match the special postcode "GIR 0AA"
|
(?:
[BEGLMNSW] | # There are 8 single-letter postcode areas
[A-Z]{2} # All other postcode areas have two letters
)
[0-9] # There is always at least one number after the postcode area
(?:
[0-9] # And an optional extra number
|
# Only certain postcode areas can have an extra letter after the number
(?<=N1|E1|SE1|SW1|W1|NW1|EC[0-9]|WC[0-9])
[A-HJ-NP-Z] # Possible letters here may change, but [IO] will never be used
)?
)
\s*
([0-9][ABD-HJLNP-UW-Z]{2}) # The last two letters cannot be [CIKMOV]
$/x
pour moi, c'est le juste équilibre entre la validation autant que possible, tout en maintenant l'épreuve de l'avenir et en permettant un entretien facile.
j'ai été à la recherche D'un regex de code postal britannique pour le dernier jour environ et est tombé sur ce fil. J'ai fait mon chemin à travers la plupart des suggestions ci-dessus et aucun d'eux n'a travaillé pour moi donc je suis venu avec mon propre regex qui, pour autant que je sache, capture tous les codes postaux Britanniques valides à partir de Jan '13 (selon la dernière littérature du Royal Mail).
le regex et quelques codes postaux simples vérifiant le code PHP sont affichés ci-dessous. NOTE: - il permet d'en bas ou en majuscules postcodes et l'anomalie GIR 0AA mais pour traiter la présence, plus que probable, d'un espace au milieu d'un postcode entré, il fait également usage d'un str_replace simple pour enlever l'espace avant de tester contre le regex. Toute divergence au-delà de cela et le Royal Mail eux-mêmes ne les mentionnent même pas dans leur littérature (voir http://www.royalmail.com/sites/default/files/docs/pdf/programmers_guide_edition_7_v5.pdf et commencez à lire à partir de la page 17)!
Note: dans la propre littérature du Royal Mail (lien ci-dessus) il y a une légère ambiguïté entourant les 3e et 4e positions et les exceptions en place si ces caractères sont des lettres. J'ai contacté Royal Mail directement pour le clarifier et dans leurs propres mots "une lettre dans la 4ème position du code Outward avec le format Aana NAA n'a pas d'exceptions et les exceptions de la 3ème position s'appliquent seulement à la dernière lettre du Code Outward avec le format ANA naa." Droit de la bouche des chevaux!
<?php
$postcoderegex = '/^([g][i][r][0][a][a])$|^((([a-pr-uwyz]{1}([0]|[1-9]\d?))|([a-pr-uwyz]{1}[a-hk-y]{1}([0]|[1-9]\d?))|([a-pr-uwyz]{1}[1-9][a-hjkps-uw]{1})|([a-pr-uwyz]{1}[a-hk-y]{1}[1-9][a-z]{1}))(\d[abd-hjlnp-uw-z]{2})?)$/i';
$postcode2check = str_replace(' ','',$postcode2check);
if (preg_match($postcoderegex, $postcode2check)) {
echo "$postcode2check is a valid postcode<br>";
} else {
echo "$postcode2check is not a valid postcode<br>";
}
?>
j'espère que cela aidera n'importe qui d'autre qui tombe sur ce fil à la recherche d'une solution.
C'est le regex que Google sert sur leur i18napis.appspot.com domaine:
GIR[ ]?0AA|((AB|AL|B|BA|BB|BD|BH|BL|BN|BR|BS|BT|BX|CA|CB|CF|CH|CM|CO|CR|CT|CV|CW|DA|DD|DE|DG|DH|DL|DN|DT|DY|E|EC|EH|EN|EX|FK|FY|G|GL|GY|GU|HA|HD|HG|HP|HR|HS|HU|HX|IG|IM|IP|IV|JE|KA|KT|KW|KY|L|LA|LD|LE|LL|LN|LS|LU|M|ME|MK|ML|N|NE|NG|NN|NP|NR|NW|OL|OX|PA|PE|PH|PL|PO|PR|RG|RH|RM|S|SA|SE|SG|SK|SL|SM|SN|SO|SP|SR|SS|ST|SW|SY|TA|TD|TF|TN|TQ|TR|TS|TW|UB|W|WA|WC|WD|WF|WN|WR|WS|WV|YO|ZE)(\d[\dA-Z]?[ ]?\d[ABD-HJLN-UW-Z]{2}))|BFPO[ ]?\d{1,4}
voici un regex basé sur le format spécifié dans les documents qui sont liés à la réponse de marcj:
/^[A-Z]{1,2}[0-9][0-9A-Z]? ?[0-9][A-Z]{2}$/
la seule différence entre cela et les spécifications est que les 2 derniers caractères ne peuvent pas être dans [CIKMOV] selon les spécifications.
Edit: Voici une autre version qui teste les limites des caractères de fuite.
/^[A-Z]{1,2}[0-9][0-9A-Z]? ?[0-9][A-BD-HJLNP-UW-Z]{2}$/
certaines des règles ci-dessus sont un peu restrictives. Remarque le véritable code postal: "W1K 7AA" serait un échec compte tenu de la règle de la "Position 3 - AEHMNPRTVXY seulement utilisés" ci-dessus comme "K" serait refusé.
la regex:
^(GIR 0AA|[A-PR-UWYZ]([0-9]{1,2}|([A-HK-Y][0-9]|[A-HK-Y][0-9]([0-9]|[ABEHMNPRV-Y]))|[0-9][A-HJKPS-UW])[0-9][ABD-HJLNP-UW-Z]{2})$
semble un peu plus précis, voir l'article Wikipedia intitulé 'Postcodes in the United Kingdom' .
notez que ce regex ne requiert que des caractères majuscules.
la plus grande question Est de savoir si vous restreignez l'entrée des utilisateurs pour n'autoriser que les codes postaux qui existent réellement ou si vous essayez simplement d'empêcher les utilisateurs d'entrer des déchets complets dans les champs de formulaires. Correspondre correctement chaque code postal possible, et l'épreuve future, il est un puzzle plus difficile, et ne vaut probablement pas la peine à moins que vous êtes HMRC.
j'ai récemment posté une réponse à cette question sur les codes postaux Britanniques pour la langue R . J'ai découvert que le modèle regex du gouvernement du Royaume-Uni est incorrect et ne parvient pas à correctement valider certains postcodes. Malheureusement, beaucoup de réponses ici sont basées sur ce modèle incorrect.
je vais vous exposer quelques-unes de ces questions ci-dessous et fournir une version révisée de la norme l'expression en fait .
Note
Ma réponse (et les expressions régulières en général):
- valide seulement le code postal formats .
- ne garantit pas qu'un code postal existe légitimement .
- pour cela, utilisez une API appropriée! Voir Ben la réponse de pour plus d'info.
si vous ne vous souciez pas du bad regex et que vous voulez simplement passer à la réponse, Faites défiler vers le bas à la section réponse .
La Mauvaise Regex
les expressions régulières de cette section ne doivent pas être utilisées.
c'est le regex défaillant que le gouvernement du Royaume-Uni a fourni aux développeurs (pas sûr combien de temps ce lien sera en place, mais vous pouvez le voir dans leur transfert de données en vrac documentation ):
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))[0-9][A-Za-z]{2})$
problèmes
Problème 1-Copier / Coller
comme beaucoup de développeurs le font probablement, ils copient/collent du code (en particulier des expressions régulières) et les collent en s'attendant à ce qu'ils fonctionnent. Bien qu'il s'agisse d'une bonne chose en théorie, elle échoue dans ce cas particulier parce que copier/coller à partir de ce document change en fait l'un des caractères (un espace) en un caractère de nouvelle ligne comme indiqué ci-dessous:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))
[0-9][A-Za-z]{2})$
la première chose que la plupart des développeurs vont faire est d'effacer la nouvelle ligne sans réfléchir à deux fois. Maintenant le regex ne correspondra pas aux codes postaux avec les espaces (autres que le code postal GIR 0AA ).
pour corriger ce problème, le caractère newline doit être remplacé par le caractère space:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^
Problème 2-Limites 15191320920"
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^^ ^ ^ ^^
le code postal regex ancre incorrectement le regex. Toute personne utilisant ce regex pour valider les postcodes peut-être surpris si une valeur comme fooA11 1AA passe à travers. C'est parce qu'ils ont ancré le début de la première option et la fin de la deuxième option (indépendamment l'un de l'autre), comme indiqué dans le regex ci-dessus.
ce que cela signifie est que ^ (affirme position au début de la ligne) ne fonctionne que sur la première option ([Gg][Ii][Rr] 0[Aa]{2}) , de sorte que la deuxième option validera toutes les chaînes que fin dans un code postal (indépendamment de ce que vient avant).
de même, la première option n'est pas ancrée à la fin de la ligne $ , donc GIR 0AAfoo est également acceptée.
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))[0-9][A-Za-z]{2})$
pour régler ce problème, les deux options doivent être enveloppées dans un autre groupe (ou un autre groupe) et les ancres doivent être placées autour de celui-ci:
^(([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2}))$
^^ ^^
Problème 3-Jeu De Caractères Inadéquat
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^^
il manque un - ici pour indiquer une plage de caractères. Tel qu'il est, si un code postal est dans le format ANA NAA (où A représente une lettre et N représente un nombre), et il commence par quelque chose d'autre que A ou Z , il échouera.
cela signifie qu'il correspondra à A1A 1AA et Z1A 1AA , mais pas B1A 1AA .
à correction de cette question, le caractère - doit être placé entre le A et Z dans le jeu de caractères respectif:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^
Problème 4-Mauvais Jeu De Caractères Optionnel
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^
je jure qu'ils n'ont même pas testé cette chose avant de la publier sur le web. Ils ont rendu le mauvais jeu de caractères optionnel. Ils ont fait [0-9] option dans la quatrième sous-option de l'option 2 (groupe 9). Cela permet au regex de correspondre à des postcodes formatés incorrectement comme AAA 1AA .
pour corriger ce problème, optionnez la classe de caractères suivante à la place (et faites ensuite l'ensemble [0-9] correspondre exactement une fois):
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9][A-Za-z]?)))) [0-9][A-Za-z]{2})$
^
Problème 5-Exécution
performances sur ce regex est extrêmement faible. Tout d'abord, ils ont placé le modèle le moins probable possibilité de faire correspondre GIR 0AA au début. Combien d'utilisateurs vont probablement ce code postal rapport à tout autre code postal; probablement jamais? Cela signifie que chaque fois que regex est utilisé, il doit épuiser cette option avant de passer à l'option suivante. Pour voir comment la performance est affectée, vérifiez le nombre d'étapes que le original regex a pris (35) par rapport au même regex après avoir cliqué sur les options (22).
le le deuxième problème avec la performance est dû à la façon dont l'ensemble de regex est structuré. Il est inutile de revenir en arrière sur chaque option si l'une d'elles échoue. La structure actuelle du regex peut être grandement simplifiée. Je fournis une correction pour cela dans la section réponse .
Problème 6-Espaces
cela ne peut pas être considéré comme un problème , en soi, mais elle soulève des préoccupations pour la plupart des développeurs. Les espaces dans le regex ne sont pas optionnels, ce qui signifie que les utilisateurs entrant leurs codes postaux doivent placer un espace dans le code postal. C'est une solution facile en ajoutant simplement ? après les espaces pour les rendre facultatif. Voir la section pour une correction.
réponse
1. La fixation du Gouvernement du royaume-UNI de la Regex
la correction de tous les problèmes décrits dans la section problèmes et la simplification du modèle donne le modèle suivant, plus court, plus concis. Nous pouvons également supprimer la plupart des groupes puisque nous validons le code postal dans son ensemble (pas des parties individuelles):
^([A-Za-z][A-Ha-hJ-Yj-y]?[0-9][A-Za-z0-9]? ?[0-9][A-Za-z]{2}|[Gg][Ii][Rr] ?0[Aa]{2})$
cela peut encore être raccourci en supprimant toutes les gammes de l'un des cas (majuscule ou minuscule) et à l'aide d'un casse drapeau. Note : certaines langues n'en ont pas, utilisez donc la plus longue ci-dessus. Chaque langue implémente le signal d'insensibilité différemment.
^([A-Z][A-HJ-Y]?[0-9][A-Z0-9]? ?[0-9][A-Z]{2}|GIR ?0A{2})$
Shorter remplaçant à nouveau [0-9] par \d (si votre moteur regex le supporte):
^([A-Z][A-HJ-Y]?\d[A-Z\d]? ?\d[A-Z]{2}|GIR ?0A{2})$
2. Simplifiée Des Modèles
sans qu'il soit nécessaire d'utiliser des caractères alphabétiques spécifiques, il est possible d'utiliser ce qui suit (gardez à l'esprit les simplifications de 1. Fixation du gouvernement britannique Regex ont également été appliquées ici):
^([A-Z]{1,2}\d[A-Z\d]? ?\d[A-Z]{2}|GIR ?0A{2})$
et encore plus si vous ne vous souciez pas de la cas particulier GIR 0AA :
^[A-Z]{1,2}\d[A-Z\d]? ?\d[A-Z]{2}$
3. Modèles Complexes
Je ne suggère pas une sur-Vérification d'un code postal car de nouvelles zones, Districts et sous-districts peuvent apparaître à tout moment. Ce que je suggérerai potentiellement faire, c'est un support supplémentaire pour les cas de bord. Certains cas spéciaux existent et sont décrits dans cet article de Wikipedia .
Voici règles complexes qui comprennent les paragraphes 3. (3.1, 3.2, 3.3).
en relation avec les motifs de 1. La fixation du Gouvernement du royaume-UNI de la Regex :
^(([A-Z][A-HJ-Y]?\d[A-Z\d]?|ASCN|STHL|TDCU|BBND|[BFS]IQQ|PCRN|TKCA) ?\d[A-Z]{2}|BFPO ?\d{1,4}|(KY\d|MSR|VG|AI)[ -]?\d{4}|[A-Z]{2} ?\d{2}|GE ?CX|GIR ?0A{2}|SAN ?TA1)$
et par rapport à 2. Modèles Simplifiés :
^(([A-Z]{1,2}\d[A-Z\d]?|ASCN|STHL|TDCU|BBND|[BFS]IQQ|PCRN|TKCA) ?\d[A-Z]{2}|BFPO ?\d{1,4}|(KY\d|MSR|VG|AI)[ -]?\d{4}|[A-Z]{2} ?\d{2}|GE ?CX|GIR ?0A{2}|SAN ?TA1)$
3.1 Territoires Britanniques D'Outre-Mer
L'article de Wikipedia déclare actuellement (certains formats légèrement simplifiés):
-
AI-1111: Anguila -
ASCN 1ZZ: Île De L'Ascension -
STHL 1ZZ: Sainte-Hélène -
TDCU 1ZZ: Tristan da Cunha -
BBND 1ZZ: Britannique De L'Océan Indien Territoire -
BIQQ 1ZZ: Territoire Antarctique Britannique -
FIQQ 1ZZ: Îles Falkland -
GX11 1ZZ: Gibraltar -
PCRN 1ZZ: Îles Pitcairn -
SIQQ 1ZZ: Géorgie du Sud et îles Sandwich du Sud -
TKCA 1ZZ: Îles Turks et Caicos -
BFPO 11: Akrotiri et Dhekelia -
ZZ 11&GE CX: Bermudes (selon ce document ) -
KY1-1111: Îles Caïmans (selon ce document ) -
VG1111: Îles Vierges Britanniques (selon ce document ) -
MSR 1111: Montserrat (selon ce document )
un regex englobant pour égaler seulement les territoires D'outre-mer Britanniques pourrait ressembler à ceci:
^((ASCN|STHL|TDCU|BBND|[BFS]IQQ|GX\d{2}|PCRN|TKCA) ?\d[A-Z]{2}|(KY\d|MSR|VG|AI)[ -]?\d{4}|(BFPO|[A-Z]{2}) ?\d{2}|GE ?CX)$
3.2 Les Forces Britanniques Bureau De Poste
bien qu'ils aient été récemment changés pour mieux s'aligner avec le système de code postal britannique à BF# (où # représente un nombre), ils sont considérés comme optionnel code postal alternatif . Ces codes postaux suivent le format BFPO , suivi de 1 à 4 chiffres:
^BFPO ?\d{1,4}$
3.3 Père Noël?
il y a un autre cas particulier avec le Père Noël (comme mentionné dans d'autres réponses): SAN TA1 est un code postal valide. Un regex pour cela est très simple:
^SAN ?TA1$
règles de base:
^[A-Z]{1,2}[0-9R][0-9A-Z]? [0-9][ABD-HJLNP-UW-Z]{2}$
au Royaume-uni (ou codes postaux, comme on les appelle) sont composés de cinq à sept caractères alphanumériques séparés par un espace. Les règles régissant les caractères qui peuvent apparaître à des positions particulières sont assez compliquées et pleines d'exceptions. L'expression régulière que nous venons de montrer colle donc aux règles de base.
règlement Complet:
si vous avez besoin d'un regex qui coche toutes les cases pour les règles de code postal au détriment de la lisibilité, ici vous allez:
^(?:(?:[A-PR-UWYZ][0-9]{1,2}|[A-PR-UWYZ][A-HK-Y][0-9]{1,2}|[A-PR-UWYZ][0-9][A-HJKSTUW]|[A-PR-UWYZ][A-HK-Y][0-9][ABEHMNPRV-Y]) [0-9][ABD-HJLNP-UW-Z]{2}|GIR 0AA)$
testé sur notre base de données clients et semble parfaitement exact.
première moitié des formats valides de code postal
- [A-Z] [A-Z] [0-9] [A-Z]
- [A-Z] [A-Z] [0-9] [0-9]
- [A-Z] [0-9] [0-9]
- [A-Z] [A-Z] [0-9]
- [A-Z] [A-Z] [A-Z]
- [A-Z] [0-9] [A-Z]
- [A-Z] [0-9]
Exceptions
Position 1-QVX not used
Position 2-IJZ non utilisée sauf dans la RGI 0AA
Position 3-AEHMNPRTVXY utilisée seulement
Position 4-ABEHNPRVWXY
Seconde moitié du code postal
- [0-9][A-Z][A-Z]
Exceptions
Position 2+3-CIKMOV non utilisé
N'oubliez pas que tous les codes possibles ne sont pas utilisés, donc cette liste est nécessaire mais pas la condition suffisante pour un code valide. Il serait peut-être plus facile de faire correspondre une liste de tous les codes valides?
pour vérifier un code postal est dans un format valide selon le Guide du programmeur de Royal Mail :
|----------------------------outward code------------------------------| |------inward code-----|
#special↓ α1 α2 AAN AANA AANN AN ANN ANA (α3) N AA
^(GIR 0AA|[A-PR-UWYZ]([A-HK-Y]([0-9][A-Z]?|[1-9][0-9])|[1-9]([0-9]|[A-HJKPSTUW])?) [0-9][ABD-HJLNP-UW-Z]{2})$
tous les codes postaux sur doogal.co.uk match, à l'exception de ceux qui ne sont plus utilisés.
Ajouter un ? après l'espace et en utilisant case-insensible match pour répondre à cette question:
'se50eg'.match(/^(GIR 0AA|[A-PR-UWYZ]([A-HK-Y]([0-9][A-Z]?|[1-9][0-9])|[1-9]([0-9]|[A-HJKPSTUW])?) ?[0-9][ABD-HJLNP-UW-Z]{2})$/ig);
Array [ "se50eg" ]
j'utilise le regex suivant que j'ai testé par rapport à tous les codes postaux Britanniques valides. Il est fondé sur les règles recommandées, mais il est condensé autant qu'il est raisonnable et ne fait pas appel à des règles spécifiques au langage regex.
([A-PR-UWYZ]([A-HK-Y][0-9]([0-9]|[ABEHMNPRV-Y])?|[0-9]([0-9]|[A-HJKPSTUW])?) ?[0-9][ABD-HJLNP-UW-Z]{2})
il suppose que le code postal a été converti en majuscules et n'a pas de caractères de début ou de fin, mais accepte un espace optionnel entre le code postal et l'incode.
the special" GIR0 0AA" le code postal est exclu et ne sera pas validé car il n'est pas dans la liste officielle des codes postaux du Bureau de poste et pour autant que je sache ne sera pas utilisé comme adresse enregistrée. L'ajout devrait être trivial en tant que Cas spécial si nécessaire.
celui-ci permet des espaces vides et des onglets des deux côtés dans le cas où vous ne voulez pas manquer la validation et ensuite couper côté sever.
^\s*(([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) {0,1}[0-9][A-Za-z]{2})\s*$)
voici comment nous avons traité la question du code postal britannique:
^([A-Za-z]{1,2}[0-9]{1,2}[A-Za-z]?[ ]?)([0-9]{1}[A-Za-z]{2})$
explication:
- s'attendre 1 ou 2 a-z caractères, supérieure ou inférieure à l'amende
- s'attendre 1 ou 2 numéros de
- s'attendre à 0 ou 1 a-z char, supérieure ou inférieure à l'amende
- espace facultatif autorisé
- expect 1 Nombre
- attendre 2 a-z, supérieure ou amende inférieure
cela obtient la plupart des formats, nous utilisons ensuite la base de données pour valider si le code postal est réellement réel, ces données sont pilotées par openpoint https://www.ordnancesurvey.co.uk/opendatadownload/products.html
espérons que cette aide
pour ajouter à cette liste un regex plus pratique que j'utilise qui permet à l'utilisateur d'entrer un empty string est:
^$|^(([gG][iI][rR] {0,}0[aA]{2})|((([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y]?[0-9][0-9]?)|(([a-pr-uwyzA-PR-UWYZ][0-9][a-hjkstuwA-HJKSTUW])|([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y][0-9][abehmnprv-yABEHMNPRV-Y]))) {0,1}[0-9][abd-hjlnp-uw-zABD-HJLNP-UW-Z]{2}))$
ce regex permet les lettres majuscules et minuscules avec un espace optionnel entre
du point de vue des développeurs de logiciels ce regex est utile pour les logiciels où une adresse peut être facultative. Par exemple, si un utilisateur ne voulait pas fournir ses coordonnées
je voulais un simple regex, où c'est bien de permettre trop, mais pas de nier un code postal valide. Je suis allé avec ceci (l'entrée est une chaîne dépouillée/parée):
/^([a-z0-9]\s*){5,7}$/i
longueurs 5 à 7 (sans compter les espaces blancs) signifie que nous permettons les codes postaux les plus courts possibles comme "L1 8JQ" ainsi que les plus longs comme "OL14 5ET".
EDIT: on a changé le 8 en 7 donc on n'autorise pas les codes postaux à 8 caractères.
regardez le code python sur cette page:
http://www.brunningonline.net/simon/blog/archives/001292.html
j'ai des recherches à faire. L'exigence est assez simple; je dois Parser un code postal dans un outcode et (optionnel) incode. La bonne nouvelle est que je n'ai pas à effectuer de validation - je dois juste découper ce que j'ai été fourni avec dans un vaguement intelligent manière. Je ne peux pas faire beaucoup de suppositions sur mon importation en termes de formatage, c'est-à-dire cas et espaces intégrés. Mais ce n'est pas la mauvaise nouvelle; la mauvaise nouvelle, c'est que je dois tout faire dans les RPG. :- (
néanmoins, j'ai lancé une petite fonction Python ensemble pour clarifier ma pensée.
je l'ai utilisé pour traiter les codes postaux pour moi.
nous avons reçu une spécification:
UK postcodes must be in one of the following forms (with one exception, see below):
§ A9 9AA
§ A99 9AA
§ AA9 9AA
§ AA99 9AA
§ A9A 9AA
§ AA9A 9AA
where A represents an alphabetic character and 9 represents a numeric character.
Additional rules apply to alphabetic characters, as follows:
§ The character in position 1 may not be Q, V or X
§ The character in position 2 may not be I, J or Z
§ The character in position 3 may not be I, L, M, N, O, P, Q, R, V, X, Y or Z
§ The character in position 4 may not be C, D, F, G, I, J, K, L, O, Q, S, T, U or Z
§ The characters in the rightmost two positions may not be C, I, K, M, O or V
The one exception that does not follow these general rules is the postcode "GIR 0AA", which is a special valid postcode.
nous avons trouvé ceci:
/^([A-PR-UWYZ][A-HK-Y0-9](?:[A-HJKS-UW0-9][ABEHMNPRV-Y0-9]?)?\s*[0-9][ABD-HJLNP-UW-Z]{2}|GIR\s*0AA)$/i
mais note - Ceci permet n'importe quel nombre d'espaces entre les groupes.
j'ai le regex pour la validation du code postal britannique.
cela fonctionne pour tout type de code postal intérieur ou extérieur
^((([A-PR-UWYZ][0-9])|([A-PR-UWYZ][0-9][0-9])|([A-PR-UWYZ][A-HK-Y][0-9])|([A-PR-UWYZ][A-HK-Y][0-9][0-9])|([A-PR-UWYZ][0-9][A-HJKSTUW])|([A-PR-UWYZ][A-HK-Y][0-9][ABEHMNPRVWXY]))) || ^((GIR)[ ]?(0AA))$|^(([A-PR-UWYZ][0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][0-9][0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][A-HK-Y0-9][0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][A-HK-Y0-9][0-9][0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][0-9][A-HJKS-UW0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][A-HK-Y0-9][0-9][ABEHMNPRVWXY0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$
cela fonctionne pour tout type de format.
exemple:
AB10-------------------->UNIQUEMENT LE CODE POSTAL EXTÉRIEUR
A1 1AA------------------>combinaison du Code Postal (Extérieur et intérieur)
WC2A-------------------->EXTERNE
Les accepté de répondre reflète les règles données par Royal Mail, même s'il y a une faute de frappe dans la regex. Cette faute de frappe semble avoir été faite sur le gov.site du Royaume-Uni ainsi que (comme il est dans la page D'archives XML).
dans le format A9A 9AA les règles permettent un caractère P dans la troisième position, tandis que le regex le refuse. La regex correcte serait:
(GIR 0AA)|((([A-Z-[QVX]][0-9][0-9]?)|(([A-Z-[QVX]][A-Z-[IJZ]][0-9][0-9]?)|(([A-Z-[QVX]][0-9][A-HJKPSTUW])|([A-Z-[QVX]][A-Z-[IJZ]][0-9][ABEHMNPRVWXY])))) [0-9][A-Z-[CIKMOV]]{2})
Raccourcir cette résultats dans la suite de regex (qui utilise Perl/Ruby syntaxe):
(GIR 0AA)|([A-PR-UWYZ](([0-9]([0-9A-HJKPSTUW])?)|([A-HK-Y][0-9]([0-9ABEHMNPRVWXY])?))\s?[0-9][ABD-HJLNP-UW-Z]{2})
comprend également un espace facultatif entre le premier et le deuxième bloc.
vous trouverez ici quelques liens utiles, dépend du langage que vous utilisez:
ce que j'ai trouvé dans presque toutes les variations et le regex du transfert en vrac pdf et ce qui est sur le site wikipedia est ceci, spécifiquement pour le Regex wikipedia est, il doit y avoir un ^ après le premier |(barre verticale). J'ai compris cela en testant pour AA9A 9AA, parce que sinon le contrôle de format pour A9A 9AA le validera. Par exemple, vérifier EC1D 1BB qui devrait être invalide revient valide parce que C1D 1BB est un format valide.
voici ce que J'ai trouvé pour un bon regex:
^([G][I][R] 0[A]{2})|^((([A-Z-[QVX]][0-9]{1,2})|([A-Z-[QVX]][A-HK-Y][0-9]{1,2})|([A-Z-[QVX]][0-9][ABCDEFGHJKPSTUW])|([A-Z-[QVX]][A-HK-Y][0-9][ABEHMNPRVWXY])) [0-9][A-Z-[CIKMOV]]{2})$
j'avais besoin d'une version qui fonctionnerait en SAS avec le PRXMATCH et les fonctions connexes, donc j'ai trouvé ceci:
^[A-PR-UWYZ](([A-HK-Y]?\d\d?)|(\d[A-HJKPSTUW])|([A-HK-Y]\d[ABEHMNPRV-Y]))\s?\d[ABD-HJLNP-UW-Z]{2}$
cas D'essai et notes:
/*
Notes
The letters QVX are not used in the 1st position.
The letters IJZ are not used in the second position.
The only letters to appear in the third position are ABCDEFGHJKPSTUW when the structure starts with A9A.
The only letters to appear in the fourth position are ABEHMNPRVWXY when the structure starts with AA9A.
The final two letters do not use the letters CIKMOV, so as not to resemble digits or each other when hand-written.
*/
/*
Bits and pieces
1st position (any): [A-PR-UWYZ]
2nd position (if letter): [A-HK-Y]
3rd position (A1A format): [A-HJKPSTUW]
4th position (AA1A format): [ABEHMNPRV-Y]
Last 2 positions: [ABD-HJLNP-UW-Z]
*/
data example;
infile cards truncover;
input valid 1. postcode &. Notes &0.;
flag = prxmatch('/^[A-PR-UWYZ](([A-HK-Y]?\d\d?)|(\d[A-HJKPSTUW])|([A-HK-Y]\d[ABEHMNPRV-Y]))\s?\d[ABD-HJLNP-UW-Z]{2}$/',strip(postcode));
cards;
1 EC1A 1BB Special case 1
1 W1A 0AX Special case 2
1 M1 1AE Standard format
1 B33 8TH Standard format
1 CR2 6XH Standard format
1 DN55 1PT Standard format
0 QN55 1PT Bad letter in 1st position
0 DI55 1PT Bad letter in 2nd position
0 W1Z 0AX Bad letter in 3rd position
0 EC1Z 1BB Bad letter in 4th position
0 DN55 1CT Bad letter in 2nd group
0 A11A 1AA Invalid digits in 1st group
0 AA11A 1AA 1st group too long
0 AA11 1AAA 2nd group too long
0 AA11 1AAA 2nd group too long
0 AAA 1AA No digit in 1st group
0 AA 1AA No digit in 1st group
0 A 1AA No digit in 1st group
0 1A 1AA Missing letter in 1st group
0 1 1AA Missing letter in 1st group
0 11 1AA Missing letter in 1st group
0 AA1 1A Missing letter in 2nd group
0 AA1 1 Missing letter in 2nd group
;
run;