Tqdm dans le cahier de Jupyter
j'utilise tqdm pour imprimer le progrès dans un script Je cours dans un carnet Jupyter. J'imprime tous les messages vers la console via tqdm.write(). Cependant, cela me donne encore une sortie asymétrique comme so:
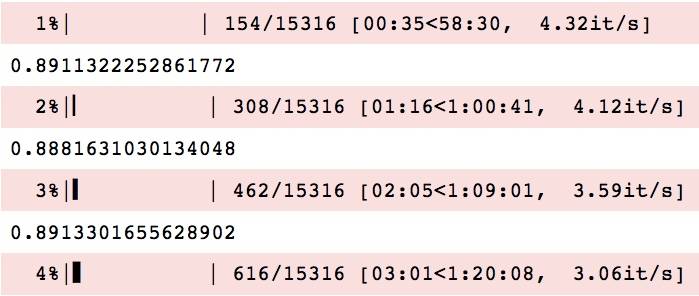
C'est, chaque fois qu'une nouvelle ligne doit être imprimé, une nouvelle barre de progression est imprimé sur la ligne suivante. Cela ne se produit pas lorsque j'exécute le script via le terminal. Comment je peux résoudre ça?
2 réponses
Essayez d'utiliser tqdm_notebook au lieu de tqdm, comme indiqué ici. C'est expérimental à ce stade, mais ça marche plutôt bien dans la plupart des cas.
Cela pourrait être aussi simple que de changer votre importation:
from tqdm import tqdm_notebook as tqdm
Bonne chance!
EDIT: Après test, il semble que tqdm fonctionne très bien en mode texte dans le carnet Jupyter. C'est difficile à dire parce que vous n'avez pas fourni un exemple minimal, mais il semble que votre problème est causé par un énoncé d'impression dans chaque itération. L'instruction print Affiche un nombre (~0.89) entre chaque mise à jour de la barre d'état, ce qui perturbe la sortie. Essayez de supprimer la déclaration d'impression.
il s'agit d'une réponse alternative pour le cas où tqdm_notebook ne fonctionne pas pour vous.
etant Donné l'exemple suivant:
from time import sleep
from tqdm import tqdm
values = range(3)
with tqdm(total=len(values)) as pbar:
for i in values:
pbar.write('processed: %d' %i)
pbar.update(1)
sleep(1)
La sortie devrait ressembler à quelque chose comme ceci (le progrès ne serait-rouge):
0%| | 0/3 [00:00<?, ?it/s]
processed: 1
67%|██████▋ | 2/3 [00:01<00:00, 1.99it/s]
processed: 2
100%|██████████| 3/3 [00:02<00:00, 1.53it/s]
processed: 3
Le problème est que la sortie de stdout et stderr sont traitées de manière asynchrone et séparément en termes de nouvelles lignes.
si say Jupyter reçoit sur stderr le première ligne, puis sortie "traitée" sur stdout. Ensuite, une fois qu'il reçoit une sortie sur stderr pour mettre à jour la progression, il ne va pas revenir en arrière et mettre à jour la première ligne car il ne ferait que mettre à jour la dernière ligne. Au lieu de cela, il devra rédiger une nouvelle ligne.
contourner 1, écrire à stdout
une solution de contournement serait de sortir les deux à la place de stdout:
import sys
from time import sleep
from tqdm import tqdm
values = range(3)
with tqdm(total=len(values), file=sys.stdout) as pbar:
for i in values:
pbar.write('processed: %d' % (1 + i))
pbar.update(1)
sleep(1)
à La sortie de modification (pas de rouge):
processed: 1 | 0/3 [00:00<?, ?it/s]
processed: 2 | 0/3 [00:00<?, ?it/s]
processed: 3 | 2/3 [00:01<00:00, 1.99it/s]
100%|██████████| 3/3 [00:02<00:00, 1.53it/s]
Ici, nous pouvons voir que Jupyter ne semble pas clair jusqu'à la fin de la ligne. Nous pourrions ajouter une autre solution à cela en ajoutant des espaces. Tels que:
import sys
from time import sleep
from tqdm import tqdm
values = range(3)
with tqdm(total=len(values), file=sys.stdout) as pbar:
for i in values:
pbar.write('processed: %d%s' % (1 + i, ' ' * 50))
pbar.update(1)
sleep(1)
ce Qui nous donne:
processed: 1
processed: 2
processed: 3
100%|██████████| 3/3 [00:02<00:00, 1.53it/s]
Solution 2, Définissez la description à la place
il pourrait être en général plus simple de ne pas avoir deux sorties mais de mettre à jour la description à la place, par exemple:
import sys
from time import sleep
from tqdm import tqdm
values = range(3)
with tqdm(total=len(values), file=sys.stdout) as pbar:
for i in values:
pbar.set_description('processed: %d' % (1 + i))
pbar.update(1)
sleep(1)
avec la sortie (description mise à jour pendant qu'il est de traitement):
processed: 3: 100%|██████████| 3/3 [00:02<00:00, 1.53it/s]
Conclusion
vous pouvez généralement faire en sorte qu'il fonctionne bien avec le tqdm ordinaire. Mais si tqdm_notebook fonctionne pour vous, il suffit d'utiliser cela (mais alors vous ne liriez probablement pas si loin).